今日でも、メールは依然として企業セグメントの主要なメッセージングツールの1つです。 保管されるメールの量は増加するだけで、時間がたつと数百ギガバイト、または数テラバイトにもなります。 この時点で、ほとんどの場合、ユーザーはメールの操作中、たとえば検索で問題が発生し始めます。 たとえば、同じRoundCubeなどのWebクライアントを使用している場合、すべてのフォルダー内のすべてのメッセージ、さらにはレター自体のコンテンツを検索するとき、結果は数十秒待たなければならないことが多く、これはあまり快適ではありません。 したがって、dovecotでFTSプラグインを設定する時が来ると思いました。
最も深刻で経験豊富な管理者にとって、dovecot-solrバンドルの設定は大きな問題ではありませんが、これが初めての場合、受け入れ可能な検索結果の設定には時間がかかることがあります。 初めてこれに直面する人のために、セットアップを簡素化しようとします。
したがって、最初は次の初期データがあります。
- CentOS 6-問題を解決するために、配布はまったく重要ではありませんが、例で行います
- Dovecot 2.2.32-私たちにとって、バージョンが2.2.19以降であることが重要です。
- Apache Solr 7-バージョン6またはバージョン7があります。
それでは、設定に取り掛かりましょう。
ドコット
このアプリケーションのバージョンは2.2.19よりも高くなければなりません。 これは、不正なクエリ生成につながるfts-solrプラグインのバグを修正したためです。結果は常に404でした。また、アプリケーションはftsおよびfts-solrプラグインのサポートを使用してビルドする必要があります。 どんなに奇妙に聞こえても、実行されると:
dovecot --build-options
ftsおよびfts-solrをサポートするDovecotは見つかりません。 ビルドパラメータに関係なく、これらのプラグインはそこに表示されません。 プラグインが存在し動作することを確認するために、次のコマンドを実行します。
ls /usr/lib64/dovecot/ | grep -E "solr|fts"
結果は次のようになります。
lib20_fts_plugin.so lib21_fts_solr_plugin.so lib21_fts_squat_plugin.so libdovecot-fts.so.0 libdovecot-fts.so.0.0.0
結果が私のものに似ている場合は、すべて正常です。セットアップを続行できます。
これを行うには、10-mail.confファイルの/etc/dovecot/conf.dディレクトリで、最後にプラグインをmail_plugins変数に追加します。
mail_plugins = quota acl expire mail_log notify fts fts_solr
次に、90-fts.confファイルを開き、次の形式にします。
plugin { fts = solr fts_solr = url=http://127.0.0.1:8983/solr/dovecot/ # ! fts_autoindex = yes }
90-fts.confファイルがない場合は、上記の内容で作成できます。 これで、dovecotのセットアップが完了しました。 忘れられない再起動dovecot。 Solrに渡します。
Apache sorl
ここのすべても非常に簡単です。 したがって、すぐにビジネスに取りかかります。
SolrはJavaで記述されているため、openjdkをインストールする必要があります。
yum install java-1.8.0-openjdk lsof
まず、Apache Solrディストリビューションをダウンロードします。執筆時点では、現在のバージョンは7.2.1です。
wget http://apache-mirror.rbc.ru/pub/apache/lucene/solr/7.2.1/solr-7.2.1.tgz -O /usr/src/solr-7.2.1.tgz
アーカイブからインストーラーファイルを解凍します。
tar zxf solr-7.2.1.tgz solr-7.2.1/bin/install_solr_service.sh
Solrをインストールします。
./solr-7.2.1/bin/install_solr_service.sh solr-7.2.1.tgz
その結果、インストールの出力は次のようになります。
We recommend installing the 'lsof' command for more stable start/stop of Solr id: solr: no such user Creating new user: solr Extracting solr-7.2.1.tgz to /opt Installing symlink /opt/solr -> /opt/solr-7.2.1 ... Installing /etc/init.d/solr script ... Installing /etc/default/solr.in.sh ... Service solr installed. Customize Solr startup configuration in /etc/default/solr.in.sh NOTE: Please install lsof as this script needs it to determine if Solr is listening on port 8983. Started Solr server on port 8983 (pid=1647). Happy searching! Found 1 Solr nodes: Solr process 1647 running on port 8983 { "solr_home":"/var/solr/data", "version":"7.2.1 b2b6438b37073bee1fca40374e85bf91aa457c0b - ubuntu - 2018-01-10 00:54:21", "startTime":"2018-03-01T11:22:40.462Z", "uptime":"0 days, 0 hours, 0 minutes, 15 seconds", "memory":"25.6 MB (%5.2) of 490.7 MB"}
ここで、Solrが正常にインストールされたことと、いくつかのインストールデータを確認できます。 Solrには、ポート8983で使用可能なWebインターフェースがあり、統計、エラー、およびその他のことを確認できます。 それを設定しましょう。
最初に行うことは、データディレクトリを転送することです。データディレクトリは非常に急速に成長するため(すべて、インデックスを作成する必要があるデータの量に依存します)、十分なスペースがあることが望ましいです。 / varディレクトリにはあまりスペースがないので、これを修正しましょう。
solrのディレクトリを作成します。
mkdir -p /srv/solr/data
すべてのデータが保存されます。 ファイル/etc/default/solr.in.shを開き、その中のいくつかの設定を修正します。
SOLR_JAVA_MEM="-Xms10240m -Xmx20480m" # Solr SOLR_HOME="/srv/solr/data" # Solr
RAMについては、理解できると思いますが、私のSolrは次のようになります。
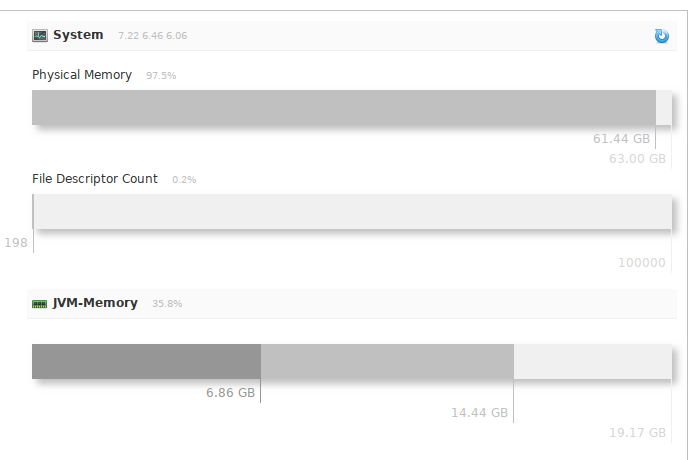
つまり 私は設定のゼロと間違われませんでした、彼はたくさんのデータでたくさん食べます。
また、このファイルでは、他の設定を修正できます。このファイルを見てください。多くの興味深いことがあります。 今のところ、これで十分です。
古いディレクトリの内容を新しいディレクトリにコピーします。
cp /var/solr/data/* /srv/solr/data/
そして、正しい権利を設定します。
chown -R solr:solr /srv/solr
これで、Solrを再始動して、構成ファイルを再読み取りできます。
service solr restart
Solrインストールディレクトリに移動し、solrユーザーとしてログインします。
cd /opt/solr/bin su solr
図を作成し、Solr自体が動作するように構成して、dovecotからの要求を正しく受信および処理できるようにします。
カーネルを作成します。
./solr create_core -c dovecot -n dovecot
新しく作成されたカーネルのディレクトリに移動します。
cd /srv/solr/data/dovecot/conf
これは、カーネルの基本設定が置かれる場所です。 2つのファイルに興味があります。
- schema.xml-インデックス作成ルールとSolrクエリを設定するためのメインファイル
- solrconfig.xml-カーネル自体の構成ファイル。
まず、schema.xmlを把握しましょう。 dovecotに付属しているスキームは、単語からの使用にはまったく受け入れられません。 したがって、より正しいスキームを提供し、そのようなコンテンツにファイルを持ち込みます。
<?xml version="1.0" encoding="UTF-8" ?> <!-- For fts-solr: This is the Solr schema file, place it into solr/conf/schema.xml. You may want to modify the tokenizers and filters. --> <schema name="dovecot" version="1.5"> <types> <!-- IMAP has 32bit unsigned ints but java ints are signed, so use longs --> <fieldType name="string" class="solr.StrField" /> <fieldType name="long" class="solr.TrieLongField" /> <fieldType name="boolean" class="solr.BoolField" /> <fieldType name="text" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.ClassicTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ru.txt"/> <filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="40"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EnglishPossessiveFilterFactory"/> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/> <filter class="solr.EnglishMinimalStemFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.ClassicTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EnglishPossessiveFilterFactory"/> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/> <filter class="solr.EnglishMinimalStemFilterFactory"/> </analyzer> </fieldType> </types> <fields> <field name="id" type="string" indexed="true" stored="true" required="true" /> <field name="uid" type="long" indexed="true" stored="true" required="true" /> <field name="box" type="string" indexed="true" stored="true" required="true" /> <field name="user" type="string" indexed="true" stored="true" required="true" /> <field name="hdr" type="text" indexed="true" stored="false" /> <field name="body" type="text" indexed="true" stored="false" /> <field name="from" type="text" indexed="true" stored="false" /> <field name="to" type="text" indexed="true" stored="false" /> <field name="cc" type="text" indexed="true" stored="false" /> <field name="bcc" type="text" indexed="true" stored="false" /> <field name="subject" type="text" indexed="true" stored="false" /> <!-- Used by Solr internally: --> <field name="_version_" type="long" indexed="true" stored="true"/> </fields> <uniqueKey>id</uniqueKey> </schema>
関心のある主なものは、Solrのインデックス作成とクエリのルールを記述する2つのアナライザーブロックです。 主なポイントについて説明します。
tokenizerクラス Solrが文を単語に分割する方法を説明します。 ドキュメントによると、このスキームはsolr.ClassicTokenizerFactoryを使用し、以下を提供します。
「03-09までにjohn.doe@foo.comにメールしてください。m37-xqです。」
次のように単語に解析します。
「お願い」、「メール」、「john.doe@foo.com」、「by」、「03-09」、「re」、「m37-xq」。
これは私に適していますが、すべての人に適しているわけではないため、システムに最適な独自のクラスを選択できます。 上記のリンクをご覧ください。
フィルタークラストークナイザーから出力される単語の処理を記述します。 ここで、さまざまなパラメーターを指定できます。これらについては、私が持ってきたリンクを読むことができます。 主なものについて説明します。
solr.EdgeNGramFilterFactory-パラメーターminGramSizeおよびmaxGramSizeに従って、単語からトークンを形成します。 1と40があります。つまり、「ドメイン」という単語から次のトークンが形成されます。「d」、「before」、「house」、「house」、「domain」、「domains」。 このようなトークンは、最大40文字のサイズで作成されます。 ここにわずかなニュアンスがあります。単語が40文字より長い場合(たとえば50)、ユーザーがsize> 40および<50で検索クエリを入力すると、結果はゼロになります。 したがって、40文字を超える電子メールには出会わなかったため、このような大きな数字を入力しました。ロシア語では一般的に、最長の単語は25文字です。
solr.LowerCaseFilterFactory-すべての単語を小文字にし、入力した文字の検索で大文字と小文字が区別されないように追加します。
solr.StopFilterFactory-インデックスを作成せずに無視する単語をSolrに伝え、単語をファイルに書き込み、wordsパラメータで指定します。
solr.EnglishMinimalStemFilterFactory-複数の英語の単語を処理するためのフィルター。犬は犬に変換されます。
solr.EnglishPossessiveFilterFactory-英語の単語を処理するためにも、語尾だけでなく所有格を削除し、Man'sはManに変換されます。
solr.KeywordMarkerFilterFactory-言語パラメーター。 ここで詳しく説明します。 私が正しく理解していれば、予備的な修正なしに索引付けを行う一種の例外語は、いわば「そのまま」です。
これらのパラメーターは、インデックスアナライザーとクエリアナライザーの両方で使用できます。 当然、これらのアナライザーは異なるパラメーターを持つことができ、互いに影響しません。 これは回路で行うことができます。
solrconfig.xmlに渡します。 Solrのバージョン7には、デフォルトでjson形式が通信に使用される点がありますが、dovecotプラグインはxmlを使用します。 したがって、ファイル内のいくつかのパラメーターを見つけて修正する必要があります(これはSolr 6には適用されません)
ブロック内(〜745行):
<requestHandler name="/select" class="solr.SearchHandler">
デフォルトブロックは次のように縮小されます。
<lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <str name="wt">xml</str> <!-- <str name="df">text</str> --> </lst>
ブロック内(〜810行):
<requestHandler name="/query" class="solr.SearchHandler">
デフォルトブロックは次のように縮小されます。
<lst name="defaults"> <str name="echoParams">explicit</str> <str name="wt">xml</str> <str name="indent">true</str> </lst>
次に、ブロックを削除する必要があります(コメントアウトするだけです)(Solr 6および7に適用)
<processor class="solr.AddSchemaFieldsUpdateProcessorFactory">
ブロックを追加します(約1190行)
<schemaFactory class="ClassicIndexSchemaFactory"></schemaFactory>
ブロックの前:
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema">
これでSolrのセットアップが完了しました。インデックス作成に進むことができます。 構成ファイルを変更した後は、Solrを再始動する必要があることを忘れないでください。
ユーザーのメールボックスにインデックスを付けるために、dovecotにはいくつかのコマンドがあります。
# , doveadm fts rescan -u s.chistiakov@example.com
# doveadm -vvvvv index -u s.chistiakov@exmample.com "*"
# . doveadm -v index -A "*"
doveadmがユーザーまたはそのようなものを見つけることができないと誓う場合、 iterate_queryパラメーターがあるかどうかを確認します。 このパラメーターがないと、ユーザーとそのメールボックスの検索で問題が発生する場合があります。 私のユーザーはデータベース内にあり、このパラメーターは私にとって次のようになります。
iterate_query = SELECT username as user FROM mailbox
ユーザーデータベースとパスワードへのクエリが記述されているファイルにあります。
dovecotカーネルのSolr統計は、次のようになります。
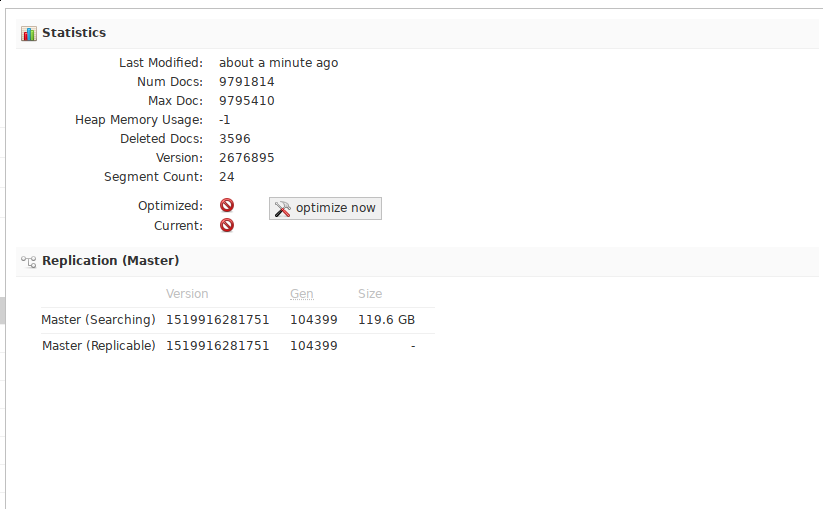
cronでさえ、次のパラメーターを追加しました。
0 6 * * * /usr/bin/doveadm -v index -A "*" 5 */1 * * * curl "http://127.0.0.1:8983/solr/dovecot/update?commit=true"
ベースを最適化するために追加できます。
0 22 * * * curl "http://127.0.0.1:8983/solr/dovecot/update?optimize=true"
合計
メールボックスの完全なインデックス作成後、検索クエリの処理速度が何倍も向上しました。以前は複雑なクエリに数十秒かかっていたが、今では1秒未満になりました。 残念ながら、古いテストはありませんでしたが、この指示を使って自分の言葉を受け入れたり、個人的に確認したりできると思います。
欠点がないわけではありませんが、インデックス作成オプションを変更すると、すべてのメールのインデックスを最初から作成する必要があります。 そして、私のボリュームと鉄の特性上、約3日間、非常に長い時間がかかります。 ただし、一度構成すると、すべてが正常に機能します。
何かを忘れたりめちゃくちゃにした場合、すべてがすでに設定されて機能しているので、ほとんどのことをメモリから書き込んだことで私を責めないでください。