約1年前、たまたまある会社で働いていたところ、興味深い問題に出会いました。 モバイルアプリケーションの使用に関する大量のデータストリーム(1日あたり数百億イベント)を想像してください。これには、アプリケーションのインストール日や、このインストールにつながった広告キャンペーンなどの興味深い情報が含まれています。 このようなデータを使用すると、インストールの日付とプロモーションに従ってユーザーをグループに簡単に分類し、ROI(投資収益率)の観点で最も成功したものを把握できます。
視覚的な例を考えてみましょう(インターネット上で写真が見つかりました):
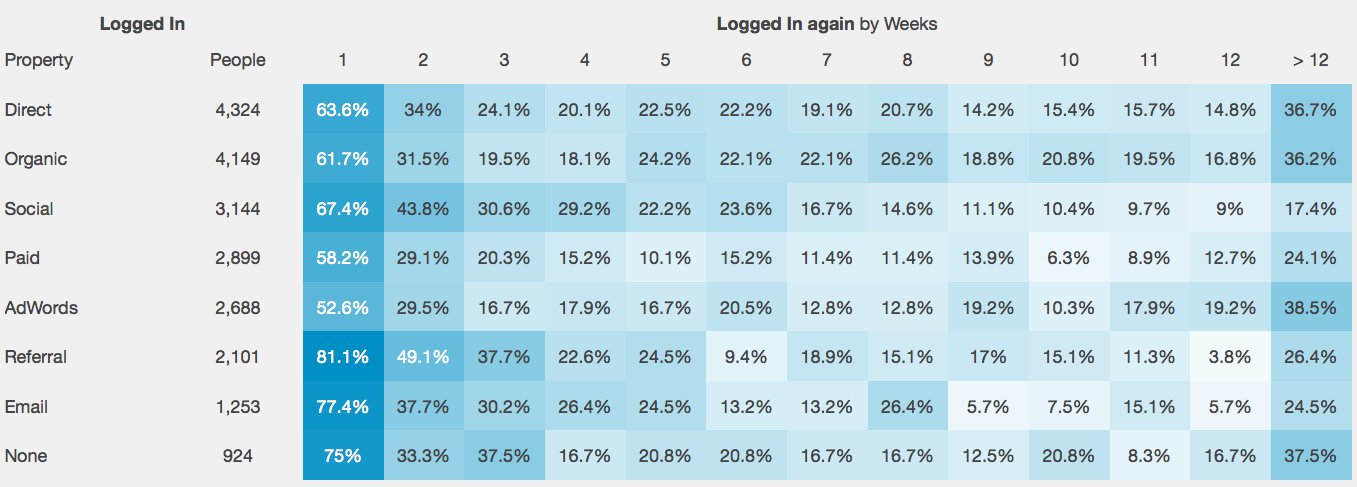
ご覧のとおり、AdWordsの「ビルボード」から来たユーザーは、この特定のアプリケーションに最も忠実であることがわかりました(彼らはアプリケーションを積極的に使用し続けました)。
マーケティングの最適化に関しては、こうした方法を過大評価できないことは間違いありませんが、データエンジニアの観点からこの問題を検討します。
そのような計画のすべての要求には、原則として、時系列ではないアプリケーションのインストール日付に関連する条件が含まれます。データストリームには、昨日インストールされたアプリケーションと2年前にインストールされたアプリケーションの両方のイベントがあります。 データベース言語に変換すると、これは、特定の時点から現在までのデータの完全スキャンを意味します。
決定の進化
この問題は、選択したソリューションが多くの並列クエリをサポートするために必要であるという事実によって悪化しました。そのため、当社のダッシュボードで同時に作業する数百人のユーザー向けに設計されていない分析データベースを最初に除外する必要がありました
当初、MongoDBはそのようなデータを保存するために使用されていましたが、クエリと記録の両方で、すぐにこのすばらしいデータベースの限界に達しました。 もちろん、このすべての不名誉を「解明」することは可能でしたが、MongoDBのシャーディングの運用上の複雑さのために、他のソリューションを試すことが決定されました。
2番目の試みはDruidでしたが、このデータベースは時間でソートされたデータを処理するため、少し役立ちました。 実際、リアルタイムで受信する情報を無視し、インストール日でデータを並べ替えて毎日データベースを再構築する場合、これは非常にうまく機能します。
クエリフィールドのリストがユーザーごとに異なる場合、いわゆるアドホッククエリをサポートする必要があるため、クエリ用のテーブルの構築を必要とするCassandraなどのデータベースも無視する必要がありました。
その結果、MemSQL(新世代データベース( NewSQL ))の選択ですべてが終了しました。最新のアーキテクチャのおかげで、またデータがメモリ内にあるため、OLTPとOLAPロードの両方のサポートを組み合わせています。 しかし、私たちが理解しているように、理想的な解決策は存在しないため、2つの問題がありました。
1)WAL(先行書き込みログ)の使用により、書き込み速度が望まれていましたが、データはS3に保存されていたため、実際には必要ありませんでした。 。
2)価格
車輪の発明
それから、私はもっと簡単なものを書くことを考えました...例えば、静的なサイズの連続したレコードのベクトルをメモリに保持し、それによってそれらを素早く通過させ、与えられた基準に従ってフィルタリングするようにします。 また、すべてをプロセスに分解し、各プロセスには独自のデータパーティションがあります。 ViyaDBが生まれました 。 実際、これは集約されたデータを列形式でメモリに保存する分析データベースであり、これを使用してすばやく「実行」できます。 要求はマシンコードに変換されるため、不必要な分岐が回避され、同様のタイプの要求が繰り返される場合にプロセッサキャッシュを使用する方が正確です。
これは、ViyaDBアーキテクチャが鳥瞰的にどのように見えるかです。

以下は、この単純なデータベースの使用例です。
試乗
最初のステップは、ViyaDBクラスターのコンポーネントを調整するConsulをインストールすることです。 次に、必要なクラスター構成をConsulに追加します。
キー「viyadb / clusters / cluster001 / config」に次のように記述します。
{ "replication_factor": 1, "workers": 32, "tables": ["events"] }
キー「viyadb / tables / events / config」に次のように記述します。
{ "name": "events", "dimensions": [ {"name": "app_id"}, {"name": "user_id", "type": "uint"}, { "name": "event_time", "type": "time", "format": "millis", "granularity": "day" }, {"name": "country"}, {"name": "city"}, {"name": "device_type"}, {"name": "device_vendor"}, {"name": "ad_network"}, {"name": "campaign"}, {"name": "site_id"}, {"name": "event_type"}, {"name": "event_name"}, {"name": "organic", "cardinality": 2}, {"name": "days_from_install", "type": "ushort"} ], "metrics": [ {"name": "revenue" , "type": "double_sum"}, {"name": "users", "type": "bitset", "field": "user_id", "max": 4294967295}, {"name": "count" , "type": "count"} ], "partitioning": { "columns": [ "app_id" ] } }
(最後の値はテーブルのDDLです)
ViyaDBをr4.2xlargeタイプの4台のAmazonian車にインストールします(CanonicalのUbuntu Artfulイメージに基づく):
apt-get update apt-get install g++-7 update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7 cd /opt curl -sS -L https://github.com/viyadb/viyadb/releases/download/v1.0.0-beta/viyadb-1.0.0-beta-linux-x86_64.tgz | tar -zxf -
各マシンで構成ファイルを作成します(/etc/viyadb/store.json):
{ "supervise": true, "workers": 8, "cluster_id": "cluster001", "consul_url": "http://consul-host:8500", "state_dir": "/var/lib/viyadb" }
( consul-host
は、Consulがインストールされているマシンのアドレスです)
すべてのマシンでデータベースを開始します。
cd /opt/viyadb-1.0.0-beta-linux-x86_64 ./bin/viyadb /etc/viyadb/store.json
データの読み込み
データベースには、SQL言語の基本的なサポートが含まれています。 SQLクエリをデータベースに送信できるユーティリティを実行します。
/opt/viyadb-1.0.0-beta-linux-x86_64/bin/vsql viyadb-host 5555
( viyadb-host
は、ViyaDBをインストールした4つのホストの1つです)
TS3形式のS3には10億のイベントがあります。 それらをロードするには、次のコマンドを実行します:
COPY events ( app_id, user_id, event_time, country, city, device_type, device_vendor, ad_network, campaign, site_id, event_type, event_name, organic, days_from_install, revenue, count ) FROM 's3://viyadb-test/events/input/'
お問い合わせ
公平を期して、後続のすべてのリクエストは、リクエストの合計時間でのコンパイルの時間を考慮しないように、2回目に起動されました。
1)特定のアプリケーションのメッセージタイプとその番号:
ViyaDB> SELECT event_type,count FROM events WHERE app_id IN ('com.skype.raider', 'com.adobe.psmobile', 'com.dropbox.android', 'com.ego360.flatstomach') ORDER BY event_type DESC event_type count ---------- ----- session 117927202 install 263444 inappevent 200466796 impression 58431 click 297 Time taken: 0.530 secs
2)アプリケーションのインストール数による州内の最もアクティブな5つの都市:
ViyaDB> SELECT city,count FROM events WHERE app_id='com.dropbox.android' AND country='US' AND event_type='install' ORDER BY count DESC LIMIT 5; city count ---- ----- Clinton 28 Farmington 20 Madison 18 Oxford 18 Highland Park 18 Time taken: 0.171 secs
3)設置数の点で最も活発な10の広告代理店、再び:
ViyaDB> SELECT ad_network, count FROM events WHERE app_id='kik.android' AND event_type='install' AND ad_network <> '' ORDER BY count DESC LIMIT 10; ad_network count ---------- ----- Twitter 1257 Facebook 1089 Google 904 jiva_network 96 yieldlove 79 i-movad 66 barons_media 57 cpmob 50 branovate 35 somimedia 34 Time taken: 0.089 secs
4)さて、そして最も重要なことは、このすべてのチーズが開始されたために、これは個々のユーザーセッションに基づくユーザーの忠誠心に関するレポートです。
ViyaDB> SELECT ad_network, days_from_install, users FROM events WHERE app_id='kik.android' AND event_time BETWEEN '2015-01-01' AND '2015-01-31' AND event_type='session' AND ad_network IN('Facebook', 'Google', 'Twitter') AND days_from_install < 8 ORDER BY days_from_install, users DESC ad_network days_from_install users ---------- ----------------- ----- Twitter 0 33 Google 0 20 Facebook 0 14 Twitter 1 31 Google 1 18 Facebook 1 13 Twitter 2 30 Google 2 17 Facebook 2 12 Twitter 3 29 Google 3 14 Facebook 3 11 Twitter 4 27 Google 4 13 Facebook 4 10 Twitter 5 26 Google 5 13 Facebook 5 10 Twitter 6 23 Google 6 12 Facebook 6 9 Twitter 7 22 Google 7 12 Facebook 7 9 Time taken: 0.033 secs
おわりに
時には、非常に具体的な問題を解決するために、車輪の発明が正当化される場合があります。 同様のソリューションをテストしたところ、データベースの機能から何も失わずに、MemSQLに比べてコストを約4倍削減できることがわかりました。 もちろん、数百万ドルの事業を一人の人が書いたデータベースに移して転送することは、この段階では完全に不当であるため、MemSQLとの契約を中断しないことが決定されました。 Githubに投稿されたコードは、上記の会社を辞めた後、私がゼロから始めたプロジェクトです。