 -天使が一斉に舞い上がると......
-天使が一斉に舞い上がると......
-友好的、友好的...
-頭を上げてください! そして彼らは飛ぶ! そして彼らは飛ぶ!..
サーテリープラチェットナイトウォッチ
遅かれ早かれ、量が必然的に品質に移行する瞬間が必ずあります。 理解する必要がある新しいゲームが蓄積され、 プロジェクトは新しい機会で大きくなりすぎ、機会は互いに組み合わされています。 すべてが自重で崩壊しない場合、結果は最も大きな期待を超える可能性があります。 殺さないものは私たちを強くします!
そのような「技術の合計」の例を次に示します。 一般的に、ゲームはそれほど複雑ではありませんが、非常に予想外です。 黙示録 -フィールドには4人の騎手とそれらをサポートする歩兵がいます。 チェスの駒の通常の動き。 最終行に到達するポーンはライダーになると予想されますが、各サイドのライダーの数は2を超えることはできません。 最初にすべてのライダーを失ったプレーヤーが負けます。 悪魔は、いつものように、細部に隠れています。 フィギュアは同時に歩きます!
これはプロジェクトの観点からどういう意味ですか?
まず第一に、パズルのように、これは「1対1のゲーム」です。プレーヤーは動きをし、ボットは自分の動きを「ミックス」します。 これは情報が不完全なゲームですが、私たちにとっては非常に珍しい形式です。 ここにはサイコロや「戦争の霧」はありませんが、移動を実行する各プレイヤーは、相手が同時にどのようにダウンするかを知りません。
もちろん、衝突は可能です。 たとえば、両方のプレイヤーが同時に同じ空のフィールドに移動したり、ポーンが同じ動きで打撃から離れる部分を食べようとする場合があります。 ゲームのルールはこれらのニュアンスをうまく説明しています。 ポーンは、ピースがこの位置を離れたとしても、誰かを倒そうとしている場合、斜めの動きをすることができ、空のフィールドでの競合の結果はピースのランクによって決定されます。 騎手は常にポーンを殺しますが、ピースが等しい場合、それらは両方とも破壊されます(ところで、ドローが可能になります)。
タスクは簡単ではありませんが、「動きの拡大」のメカニズムは完全にそれに対処します。 実際、前に何度か言ったように、後処理段階では、移動を禁止する(たとえば、ゲームの不変条件に違反する)だけでなく、ボットによって形成された移動から取得したアクションを含む任意のアクションを追加することもできます。
微妙な点が1つあります。通常、生成されたすべての動きに対して、生成後すぐに後処理が実行されます。 この場合、これは実行できません。これは必然的に「組み合わせ爆発」につながるためです(ゲームは小さいですが、それでも十分に快適ではありません)。 最も重要なことは、これは必要ないことです。 もっと簡単な方法があります。 コントローラーを書き換えることができないと言う人はいません。 モジュール性には利点があります。
もちろん、衝突は可能です。 たとえば、両方のプレイヤーが同時に同じ空のフィールドに移動したり、ポーンが同じ動きで打撃から離れる部分を食べようとする場合があります。 ゲームのルールはこれらのニュアンスをうまく説明しています。 ポーンは、ピースがこの位置を離れたとしても、誰かを倒そうとしている場合、斜めの動きをすることができ、空のフィールドでの競合の結果はピースのランクによって決定されます。 騎手は常にポーンを殺しますが、ピースが等しい場合、それらは両方とも破壊されます(ところで、ドローが可能になります)。
移動をマージ
Dagaz.Model.join = function(design, board, a, b) { var x = getPiece(design, board, a); var y = getPiece(design, board, b); if ((x !== null) && (y !== null)) { var r = Dagaz.Model.createMove(); r.protected = []; checkPromotion(design, board, a, x, b); checkPromotion(design, board, b, y, a); var p = a.actions[0][1][0]; var q = b.actions[0][1][0]; if ((p == q) && (x.type > y.type)) { r.actions.push(b.actions[0]); r.actions.push(a.actions[0]); } else { r.actions.push(a.actions[0]); r.actions.push(b.actions[0]); } if (p == q) { if (x.type > y.type) { r.actions[0][2] = [ Dagaz.Model.createPiece(2, 2) ]; r.protected.push(x.player); r.captured = p; } else { if (x.type == y.type) { r.actions[0][2] = [ Dagaz.Model.createPiece(2, 1) ]; r.actions[1][2] = [ Dagaz.Model.createPiece(2, 1) ]; r.capturePiece(p); } else { r.actions[0][2] = [ Dagaz.Model.createPiece(2, 1) ]; r.protected.push(y.player); r.captured = p; } } } return r; } else { return a; } }
タスクは簡単ではありませんが、「動きの拡大」のメカニズムは完全にそれに対処します。 実際、前に何度か言ったように、後処理段階では、移動を禁止する(たとえば、ゲームの不変条件に違反する)だけでなく、ボットによって形成された移動から取得したアクションを含む任意のアクションを追加することもできます。
微妙な点が1つあります。通常、生成されたすべての動きに対して、生成後すぐに後処理が実行されます。 この場合、これは実行できません。これは必然的に「組み合わせ爆発」につながるためです(ゲームは小さいですが、それでも十分に快適ではありません)。 最も重要なことは、これは必要ないことです。 もっと簡単な方法があります。 コントローラーを書き換えることができないと言う人はいません。 モジュール性には利点があります。
AIボットの観点から見ると、ゲームはさまざまな意味で「あることが判明」しています。 多数の動きを詳細に表示する必要はありません。 敵がどのように歩くかを推測することが重要です! ゲームの戦術は変化しています。 「戦闘中」のライダーを攻撃しようとすることは事実上無意味です-彼らはおそらく逃げます。 「フォーク」はより有望ですが、どのライダーを倒すかを選択する必要があります。 敵に1人のライダーしかいない場合(そして、あなたが完全なセットを持っている場合)、選択したフィールドに移動することで、敵を「見る」ことができます。 ポーンにしないでください! 数字の変換に関連するニュアンスがありますが、一般的には...
それはすべて、一連のヒューリスティックに帰着します
... var isCovered = function(design, board, pos, player, type) { var r = false; _.each(Dagaz.Model.GetCover(design, board)[pos], function(pos) { var piece = board.getPiece(pos); if ((piece !== null) && (piece.player == player)) { if (_.isUndefined(type) || (piece.type == type)) { r = true; } } }); return r; } Ai.prototype.getMove = function(ctx) { var moves = Dagaz.AI.generate(ctx, ctx.board); if (moves.length == 0) { return { done: true, ai: "nothing" }; } timestamp = Date.now(); var enemies = 0; var friends = 0; _.each(ctx.design.allPositions(), function(pos) { var piece = ctx.board.getPiece(pos); if ((piece !== null) && (piece.type == 1)) { if (piece.player == 1) { enemies++; } else { friends++ } } }); var eval = -MAXVALUE; var best = null; _.each(moves, function(move) { var e = _.random(0, NOISE_FACTOR); if (move.isSimpleMove()) { var pos = move.actions[0][0][0]; var trg = move.actions[0][1][0]; var piece = ctx.board.getPiece(pos); if (piece !== null) { var target = ctx.board.getPiece(trg); if (piece.type == 1) { if (isCovered(ctx.design, ctx.board, pos, 1)) e += MAXVALUE; if (target === null) { if (isCovered(ctx.design, ctx.board, trg, 1, 0)) e += LARGE_BONUS; if (isCovered(ctx.design, ctx.board, trg, 1, 1)) { if ((enemies == 1) && (friends == 2)) { e += BONUS; } else { e -= MAXVALUE; } } } else { if (target.type == 1) { e += SMALL_BONUS; } else { e += BONUS; } } } else { if (isCovered(ctx.design, ctx.board, pos, 1)) e += SMALL_BONUS; if ((target === null) && isCovered(ctx.design, ctx.board, trg, 1)) e -= MAXVALUE; if (friends == 1) e += BONUS; if (target !== null) e += SMALL_BONUS; if ((move.actions[0][2] !== null) && (move.actions[0][2][0].type != piece.type)) { if (friends == 1) { e += MAXVALUE; } else { e -= MAXVALUE; } } } } } if ((best === null) || (eval < e)) { console.log("Move: " + move.toString() + ", eval = " + e); best = move; eval = e; } }); return { done: true, move: best, time: Date.now() - timestamp, ai: "aggressive" }; }

もう1つの極端な点は、ゲームが大きく複雑であるため、ゲームを少し詳しく見ることが技術的に不可能なことです。 ここでは、よりカジュアルなAI を使用することを余儀なくされており、1〜2移動だけ先の位置を表示しています。この深さまで、使用可能なすべての移動を表示することはできません。 いずれにせよ、人がボットの動きを2〜3秒間検索する快適な時間です。
パフォーマンスについてもう少し
大規模で複雑なゲームでは、すべてのパフォーマンスの問題が明らかになります。 通常、コードの実行速度はAI作業の品質に関連します(割り当てられた時間内に考慮する位置が多くなればなるほど、動作が向上します)が、パフォーマンスの問題がより明らかになる場合があります。 天ji将giに取り組んでいる過程で、ある位置ではユーザーインターフェースの反応時間が単純に不当に長くなっていることに気づきました(約10〜15秒)。

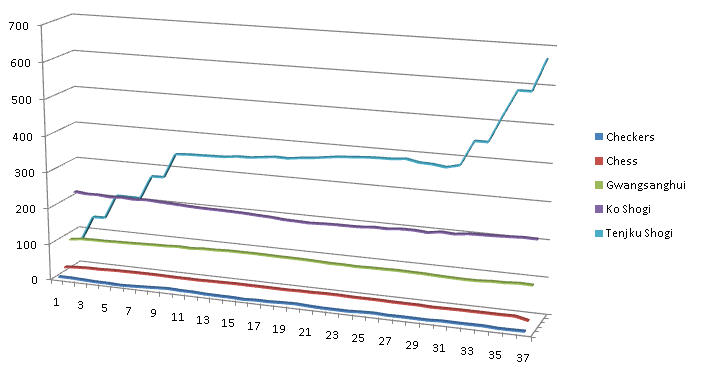
それはすべて「燃えるような悪魔」(および同様の数字)についてです。 右側の図に注意してください。 通常の「範囲」攻撃に加えて、「悪魔」はいつでも、任意の方向に最大3つのワンステップ移動を実行する権利があり、以前に完了したフィールドに戻ることができます。 これは本当の「組み合わせキラー」パフォーマンスです! 初期位置では、このようなすべてのピースが「絞られた」とき、この効果はそれほど顕著ではありませんが、運用スペースに到達すると...希望する人は自分で可能な動きの数を計算できます(下の図は、ゲーム中の許可された動きの平均数の変化のグラフを示しています、いくつかの有名なゲーム用)。
ここでは、Dagazのアーキテクチャについて少しお話しする必要があります。 主なアイデアは、ユーザーまたはボットに制御を渡す前に、ゲームモデルが現在の位置から可能なすべての動きを生成することです。 これにより、一連の動き全体を「完全に」検討することができ、複合的な動きに関連する何十億ものゲームの問題の解決に役立ちます。 さらに、このアプローチはボットの開発に非常に便利です。 しかし、1つの問題があります。
ユーザーにとって、複雑な複合移動とは、 一連の異なるアクション(移動、キャプチャー、および場合によってはボードへの新しいピースのリセット)です。 ユーザーの「クリック」のシーケンスに従って、以前に作成された、場合によっては大きなリストから単一の動きを選択できるようにするコードが必要です。 そしてもちろん、Dagazのこのようなコードはです。
問題は何ですか? getStops関数は、各移動のすべての最終フィールドのリストを作成し、このため、サイクル内のすべての移動を繰り返しますが、 smartFromまたはsmartToオプションを有効にすると(代替オプションがない場合、最初の「クリック」で移動をすぐに実行するオプション)、すべての移動のネストされた検索が実行されます。 多くの動きが形成されます!
チェッカーやチェスなどの小さなゲームでは、エラーは発生しませんでした。 天ji将giの初期の位置でさえ、彼女は目立ちませんでした。 それを特定するには、「生産性を下げる殺人者」が必要でした。 また、エラーの場所を特定するために、 KPIモジュールは非常に役立ちました。これがないと、どこで問題を探すべきかわかりません。 これでバグが修正され、その結果、すべてのコードが改善されました。
それはすべて「燃えるような悪魔」(および同様の数字)についてです。 右側の図に注意してください。 通常の「範囲」攻撃に加えて、「悪魔」はいつでも、任意の方向に最大3つのワンステップ移動を実行する権利があり、以前に完了したフィールドに戻ることができます。 これは本当の「組み合わせキラー」パフォーマンスです! 初期位置では、このようなすべてのピースが「絞られた」とき、この効果はそれほど顕著ではありませんが、運用スペースに到達すると...希望する人は自分で可能な動きの数を計算できます(下の図は、ゲーム中の許可された動きの平均数の変化のグラフを示しています、いくつかの有名なゲーム用)。
ここでは、Dagazのアーキテクチャについて少しお話しする必要があります。 主なアイデアは、ユーザーまたはボットに制御を渡す前に、ゲームモデルが現在の位置から可能なすべての動きを生成することです。 これにより、一連の動き全体を「完全に」検討することができ、複合的な動きに関連する何十億ものゲームの問題の解決に役立ちます。 さらに、このアプローチはボットの開発に非常に便利です。 しかし、1つの問題があります。
ユーザーにとって、複雑な複合移動とは、 一連の異なるアクション(移動、キャプチャー、および場合によってはボードへの新しいピースのリセット)です。 ユーザーの「クリック」のシーケンスに従って、以前に作成された、場合によっては大きなリストから単一の動きを選択できるようにするコードが必要です。 そしてもちろん、Dagazのこのようなコードはです。
それに間違いがありました
MoveList.prototype.isUniqueFrom = function(pos) { var c = 0; _.each(this.moves, function(move) { _.each(this.getActions(move), function(action) { if ((action[0] !== null) && (_.indexOf(action[0], pos) >= 0)) c++; }); }, this); return c == 1; } MoveList.prototype.isUniqueTo = function(pos) { var c = 0; _.each(this.moves, function(move) { _.each(this.getActions(move), function(action) { if ((action[1] !== null) && (_.indexOf(action[1], pos) >= 0)) c++; }); }, this); return c == 1; } ... MoveList.prototype.getStops = function() { var result = this.getTargets(); _.each(this.moves, function(move) { var actions = _.filter(this.getActions(move), isMove); if ((actions.length > 0) && (actions[0][0].length == 1) && (actions[0][1].length == 1)) { if (Dagaz.Model.smartFrom) { if (this.isUniqueFrom(actions[0][0][0]) && !this.canPass()) { result.push(actions[0][0][0]); } } if (Dagaz.Model.smartTo) { if (this.isUniqueTo(actions[0][1][0])) { result.push(actions[0][1][0]); } } } else { ... } }, this); return _.uniq(result); }
問題は何ですか? getStops関数は、各移動のすべての最終フィールドのリストを作成し、このため、サイクル内のすべての移動を繰り返しますが、 smartFromまたはsmartToオプションを有効にすると(代替オプションがない場合、最初の「クリック」で移動をすぐに実行するオプション)、すべての移動のネストされた検索が実行されます。 多くの動きが形成されます!
チェッカーやチェスなどの小さなゲームでは、エラーは発生しませんでした。 天ji将giの初期の位置でさえ、彼女は目立ちませんでした。 それを特定するには、「生産性を下げる殺人者」が必要でした。 また、エラーの場所を特定するために、 KPIモジュールは非常に役立ちました。これがないと、どこで問題を探すべきかわかりません。 これでバグが修正され、その結果、すべてのコードが改善されました。
そのため、表示の深さは制限されており、限られた時間内に正しい(または少なくとも壊滅的ではない)判断を下す必要があります。 この場合、次の原則が保証されることが非常に望ましいです。
- もちろん、即座の勝利につながる動きを選択する必要があります。
- 即座の勝利につながる答えがある動きを選択してはいけません
- 選択された動きは、位置の最大の改善を提供する必要があります
ポジションを評価するには?
最も簡単な方法は、物質収支を評価することです。 数字の各タイプには値が割り当てられ、数字の値を加算して、相手の数字の値を減算します。 概算は大まかなものですが、本当に複雑なゲームの場合は、おそらく唯一のゲームです。 改善された評価では、数値の流動性とそれらの相互の脅威を考慮する必要があります(これについては以下で説明します)。 複雑なルールを持つ「大きな」ゲームの場合、相互の脅威を評価するのは費用がかかりすぎる場合があります。
2番目のツールはヒューリスティックです。 これは、位置ではなく、単なる動きの数値評価であり、「悪い」動きと「良い」動きを区別することができます。 もちろん、まず第一に、「良い」動きが考慮され、「悪い」動きを考慮する時間がないかもしれません。 最も単純なヒューリスティックには、取得した数値の値を含めることができますが、さらに、移動、可能な変換、脅威などを実行する数値の値を推定することをお勧めします。
ヒューリスティックの最大値は、この特定の動きが選択されることを意味するものではないことを理解することが重要です。 ヒューリスティックは、表示の移動の順序のみを設定します。 この順序の枠組み内で、評価関数の値を最大化する動き(最大のヒューリスティックで相手の報復移動を完了した後)が選択されます。 負のヒューリスティック値を設定することで、移動の一部を強制的に考慮から除外することができますが、このツールは、問題の移動が単に役に立たないだけでなく有害であるという100%の確実性がある場合にのみ注意して使用する必要があります
上記の3つの原則について話したことを覚えていますか? ロイヤルフィギュア(ゲームにはこのようなフィギュアのいくつかのタイプが存在する可能性があります)は、非常に高いコストをかけるのに意味があります。 これにより、1石で2羽の鳥を殺します:最初に、ロイヤルピースをとる動きは、可能な限り最高のヒューリスティックを受け取ります(そして、常に最初に考慮されます)。さらに、ボードにロイヤルピースがないことは、評価関数の値に著しく影響し、これも非常に便利です。 残念なことに、 チェスに適用されるように、このトリックは関係がありません。なぜなら、 王は決してそれらに取り込まれないからです。
最も単純な評価関数
Dagaz.AI.eval = function(design, params, board, player) { var r = 0; _.each(design.allPositions(), function(pos) { var piece = board.getPiece(pos); if (piece !== null) { var v = design.price[piece.type]; if (piece.player != player) { v = -v; } r += v; } }); return r; }
2番目のツールはヒューリスティックです。 これは、位置ではなく、単なる動きの数値評価であり、「悪い」動きと「良い」動きを区別することができます。 もちろん、まず第一に、「良い」動きが考慮され、「悪い」動きを考慮する時間がないかもしれません。 最も単純なヒューリスティックには、取得した数値の値を含めることができますが、さらに、移動、可能な変換、脅威などを実行する数値の値を推定することをお勧めします。
発見的例
Dagaz.AI.heuristic = function(ai, design, board, move) { var r = 0; var player = board.player; var start = null; var stop = null; var captures = []; _.each(move.actions, function(a) { if ((a[0] !== null) && (a[1] === null)) { var pos = a[0][0]; var piece = board.getPiece(pos); if ((piece !== null) && (piece.player != player)) { r += design.price[piece.type] * ai.params.CAPTURING_FACTOR; if (!_.isUndefined(board.bonus) && (board.bonus[pos] < 0)) { r -= board.bonus[pos]; } } captures.push(pos); } if ((a[0] !== null) && (a[1] !== null)) { if (start === null) { start = a[0][0]; if (!_.isUndefined(board.bonus)) { r += board.bonus[start]; } } stop = a[1][0]; } }); var price = 0; if (start !== null) { var piece = board.getPiece(start); if (piece !== null) { price = design.price[piece.type]; } } _.each(move.actions, function(a) { if ((a[0] !== null) && (a[1] !== null)) { var pos = a[1][0]; var piece = board.getPiece(pos); if (_.indexOf(captures, pos) < 0) { if ((piece !== null) && (piece.player != player)) { r += design.price[piece.type] * ai.params.CAPTURING_FACTOR; if (!_.isUndefined(board.bonus)) { r += Math.abs(board.bonus[pos]); } } if (a[2] !== null) { var promoted = a[2][0]; r -= price * ai.params.SUICIDE_FACTOR; if (promoted.player == player) { r += design.price[promoted.type] * ai.params.PROMOTING_FACTOR; } } } else { r -= price * ai.params.SUICIDE_FACTOR; } } if ((a[0] === null) && (a[1] !== null) && (a[2] !== null) && (_.indexOf(captures, a[1][0]) < 0)) { var pos = a[1][0]; var piece = board.getPiece(pos); if (piece !== null) { if (piece.player != player) { r += design.price[piece.type] * ai.params.CAPTURING_FACTOR; } } piece = a[2][0]; if (piece.player == player) { r += design.price[piece.type] * ai.params.CREATING_FACTOR; } } }); if (!_.isUndefined(board.cover) && (start !== null) && (stop !== null)) { if (isAttacked(design, board, board.player, stop, start, price)) { r -= price * ai.params.SUICIDE_FACTOR; } } return r; }
ヒューリスティックの最大値は、この特定の動きが選択されることを意味するものではないことを理解することが重要です。 ヒューリスティックは、表示の移動の順序のみを設定します。 この順序の枠組み内で、評価関数の値を最大化する動き(最大のヒューリスティックで相手の報復移動を完了した後)が選択されます。 負のヒューリスティック値を設定することで、移動の一部を強制的に考慮から除外することができますが、このツールは、問題の移動が単に役に立たないだけでなく有害であるという100%の確実性がある場合にのみ注意して使用する必要があります
コスト数値
... design.addPiece("King", 32, 10000); design.addPiece("Prince", 33, 10000); design.addPiece("Blind-Tiger", 34, 3); design.addPiece("Drunk-Elephant", 35, 3); design.addPiece("Ferocious-Leopard", 36, 3); design.addPiece("Gold-General", 37, 3); design.addPiece("Silver-General", 39, 2); design.addPiece("Copper-General", 40, 2); design.addPiece("Chariot-Soldier", 41, 18); design.addPiece("Dog", 43, 1); design.addPiece("Bishop-General", 44, 21); design.addPiece("Rook-General", 46, 23); design.addPiece("Vice-General", 48, 39); design.addPiece("Great-General", 49, 45); ...
上記の3つの原則について話したことを覚えていますか? ロイヤルフィギュア(ゲームにはこのようなフィギュアのいくつかのタイプが存在する可能性があります)は、非常に高いコストをかけるのに意味があります。 これにより、1石で2羽の鳥を殺します:最初に、ロイヤルピースをとる動きは、可能な限り最高のヒューリスティックを受け取ります(そして、常に最初に考慮されます)。さらに、ボードにロイヤルピースがないことは、評価関数の値に著しく影響し、これも非常に便利です。 残念なことに、 チェスに適用されるように、このトリックは関係がありません。なぜなら、 王は決してそれらに取り込まれないからです。
位置は常に相手の報復移動の終了時にのみ評価されることに注意してください! 一連の交換がある場合は、最後まで表示する必要があります。それ以外の場合は、攻撃ピースが価値の低いものとして提供される可能性があります。
3人以上のプレイヤーのゲームは、カジュアルな「一方向」のAIの別のアプリケーションです。 それはすべて評価関数についてです。 Minimaxアルゴリズムは、一方のプレーヤーの視点からのスコアが、反対の符号で撮影された他方のプレーヤーのスコアと一致する場合にのみ機能します。 一方を失ったものが他方を獲得します。 3人( またはそれ以上 )のプレイヤーがいる場合、すべてが壊れます。 もちろん、 モンテカルロ法に基づいたアルゴリズムを適用することもできますが、他の困難がそれらに関連付けられています。

Yonin Shogi -4人のプレイヤーのための「 日本のチェス 」の変形。 このゲームのルールのほとんどは変更されていませんが、ゲームの目的は変わります。 「マット」の概念は、ある程度までその意味を失います。 実際、「東」が「南」の王を脅かすなら、これは「西」と「北」が彼らの言葉を言うまで「シャー」に対して防御する理由ではない。 一方、脅威がまだ除去されていない場合、次の動き、「東」は王を食べるでしょう。 したがって、与人将giは王を奪うことができます(これがゲームの目的です)。
さらに、ゲームはキングのキャプチャで終了しません(同様の結果は、残りの3人のプレイヤーにとっては混雑しすぎます)。 キングを失ったプレイヤーはゲームから除外され、移動する権利を失います。 王は捕まることができるので、他のすべての駒と同様に、予備に落ち、いつでもボードに置くことができます。 ボードにキングが残っていない場合、プレイヤーはキングをリザーブから外さなければなりません 。 このすべての後、ゲームの目標は明白になります-4人の王をすべて集めた人が勝ちます( Zillions of Gamesでゲームを作ったとき、 ハワードマッケイはこのニュアンスを実現するのを助けてくれました)。
上記のすべてが単純な思考につながります。
複雑で詳細な検索アルゴリズムを適用できないゲームがあり、評価関数の概念そのものを再考する必要があります。 AIアルゴリズムの作業の品質を許容範囲に保つには、おそらくその複雑さのために、推定値とヒューリスティックを改善する必要があります。 明らかな方法は、機動性を導入することです-プレイヤーが行ったすべての可能な動きの数から、相手の動きを引いたものです。
「一方向」のアルゴリズムを使用する場合、モビリティ評価は驚くほど効果的です。 ボットの愚かなゲームはより「意味のある」ものになります。 実際にはマイナスが1つあります。機動性を評価するためには、各プレーヤーのすべての可能な動きを構築(または少なくとも再集計)する必要があり、これは非常に高価な操作です。 とにかくこれを行うことを余儀なくされているので、ムーブの生成から可能な限りすべてを「絞り込み」、さらにそのような操作の数を最小限に抑えたいと思います。
そこで、「カバー」のアイデアを思いつきました。 これは単なる配列の配列です。 各フィールド(およびDagazのすべてのフィールドは常に整数としてエンコードされます)については、このフィールドに勝てる数字を含む位置の空のリストが保持される可能性があります。 同時に(そしてこれは重要です)空のフィールドと占有されたフィールド、および「ビート」フィギュアの所有者を区別しません。 可能な動きのリストは、すべてのプレイヤーに対して同時に計算され、キャッシュのために一度も計算されます。
もちろん、「カバー」を構築するための普遍的なアルゴリズムは、すべてのゲームに適したものではありません。 ChessとCheckersでは機能しますが、 Spockでは機能しなくなりました(このゲームでは、ピースは自由に他の色のピースを通過できるため)。 これは混乱するべきではありません。 評価関数とヒューリスティックに加えて、「カバー」を構築するためのアルゴリズムは、 Dagaz.Model.GetCoverという名前を使用して再定義できます。 さらに、ユニバーサルアルゴリズムが機能する場合でも、カスタマイズを検討することは有用です。 原則として、特殊なアルゴリズムはより生産的です。
eval = A * material-balance + B * mobility; A >= 0, B >= 0, A + B = 1
「一方向」のアルゴリズムを使用する場合、モビリティ評価は驚くほど効果的です。 ボットの愚かなゲームはより「意味のある」ものになります。 実際にはマイナスが1つあります。機動性を評価するためには、各プレーヤーのすべての可能な動きを構築(または少なくとも再集計)する必要があり、これは非常に高価な操作です。 とにかくこれを行うことを余儀なくされているので、ムーブの生成から可能な限りすべてを「絞り込み」、さらにそのような操作の数を最小限に抑えたいと思います。
カバレッジ
Dagaz.AI.eval = function(design, params, board, player) { var r = 0; var cover = board.getCover(design); _.each(design.allPositions(), function(pos) { var defended = _.filter(cover[pos], function(p) { var piece = board.getPiece(p); if (piece === null) return false; return piece.player == player; }); if (defended.length > 0) r++; }); return r; }
そこで、「カバー」のアイデアを思いつきました。 これは単なる配列の配列です。 各フィールド(およびDagazのすべてのフィールドは常に整数としてエンコードされます)については、このフィールドに勝てる数字を含む位置の空のリストが保持される可能性があります。 同時に(そしてこれは重要です)空のフィールドと占有されたフィールド、および「ビート」フィギュアの所有者を区別しません。 可能な動きのリストは、すべてのプレイヤーに対して同時に計算され、キャッシュのために一度も計算されます。
もちろん、「カバー」を構築するための普遍的なアルゴリズムは、すべてのゲームに適したものではありません。 ChessとCheckersでは機能しますが、 Spockでは機能しなくなりました(このゲームでは、ピースは自由に他の色のピースを通過できるため)。 これは混乱するべきではありません。 評価関数とヒューリスティックに加えて、「カバー」を構築するためのアルゴリズムは、 Dagaz.Model.GetCoverという名前を使用して再定義できます。 さらに、ユニバーサルアルゴリズムが機能する場合でも、カスタマイズを検討することは有用です。 原則として、特殊なアルゴリズムはより生産的です。
実際のゲームで「カバレッジ」 を使用する例を次に示します。 これは依然として最も単純な「ワンステップ」アルゴリズムであり、非常に簡単に欺くことができますが、ボットのアクションは有意義に思えます! カバレッジを分析することにより、AIはピースを保護されたままにせず、ボード上でそれらを「最大化」して、戦闘中のフィールドの数を最大化しようとします。 これは優れた戦術であり、1つの「 マハラジャ 」と対戦するとき、確実に勝利につながります。 このアルゴリズムは、「 Light Brigadeの突撃 」、「 Dunsany's Chess 」、「 Horde Chess 」、「 Weak! 」、およびその他の「小さな」チェスゲームでもうまく機能します。 「カバレッジ」を使用すると、より複雑なアルゴリズムの改善に役立つことは明らかですが、それらに進む前に練習する必要があります。
5時39分ごろ、すべての動きが急激に加速されることに注意してください。 これについて簡単に説明します。 サイコロの動きのアニメーションと並行して(人が退屈しないように)、ボットは目標位置を検索し、それを見つけた後、追加の計算に時間を浪費することなく、直線でその位置に移動します。
ちなみに
FireFox 52.6.0ではこの効果を観察できませんでした。 ChromeでもIEでも、アルゴリズムは約5分で解決策を見つけました。FireFoxでは、彼は私がそれをノックアウトするまで(メモリがそれ自体に食い込んでいる間)約15分間ダイスをゆっくりと動かし続けました。 この現象の説明はまだ見つかっていません。
私にとって、これは以前のバージョンと比較して重要な一歩です。 アルゴリズムは単純な幅優先探索です ( 深さではありません!これは重要です。最短の解決策に関心があるのでしょうか?)。 繰り返される位置はZobrist hashの助けを借りて切り取られます。Zobristhashは、衝突の結果として解決策が見つからないという状況を(非常にまれですが)可能にします。 さらに、現在のアニメーションノードの子孫であるノードに検索の優先順位が与えられます(ソリューションを見つけた後に必要なリターンの数を最小限に抑えるため)。
途中でもう一つやった
実際、Zillions of Gamesには、私が決して理解していない目的のオプションがあります。 「プログレッシブレベル」と呼ばれます。 ゲームの1つのレベルを完了するとすぐに、次のレベルがすぐにロードされます。 今、私は、ポイントを得たと思います。 これらの電球をオフにしてみてください:

同意して、これは中毒性があります。 そして、あなたは誰かがあなたのためにパズルを無限に解決する方法を見ることができます。 しかし、これは戦いの半分に過ぎません! ほとんどすべてのDagazオプションと同様に、 「プログレッシブレベル」はカスタマイズできます。

このパズルは、 ジョージワシントンの大統領選に捧げられたものであり、当初はまったく正しく実装されていませんでした。 正しい決定のためには、四隅すべてに順番に赤い正方形を描く必要がありますが、ダガズでは1つの目標しか設定できません。 ここで、 カスタムの 「プログレッシブレベル」が機能します。
次の目標に到達するとすぐに、次のレベルが読み込まれますが、数字の配置は同時に前のレベルから取られます! 中断したところから続けます。 レベル間で位置を転送するために使用されるモジュールは、それ自体で価値があります。ブラウザのログイン時間を有効にすると、ほとんどすべてのゲームで、以前に渡された位置に戻ることができます。ログの「Setup:」という表記の後に続く行をURLにコピーするだけで十分です。デバッグに大いに役立ちます!
カスタム「プログレッシブレベル」は、神様などの複雑なライフサイクルゲームに適用できます。最後の行の数字の1つに達しても、このゲームは終了しません!ルールにより , «» , , . , Dagaz ! , . , , .
同意して、これは中毒性があります。 そして、あなたは誰かがあなたのためにパズルを無限に解決する方法を見ることができます。 しかし、これは戦いの半分に過ぎません! ほとんどすべてのDagazオプションと同様に、 「プログレッシブレベル」はカスタマイズできます。
このパズルは、 ジョージワシントンの大統領選に捧げられたものであり、当初はまったく正しく実装されていませんでした。 正しい決定のためには、四隅すべてに順番に赤い正方形を描く必要がありますが、ダガズでは1つの目標しか設定できません。 ここで、 カスタムの 「プログレッシブレベル」が機能します。
次の目標に到達するとすぐに、次のレベルが読み込まれますが、数字の配置は同時に前のレベルから取られます! 中断したところから続けます。 レベル間で位置を転送するために使用されるモジュールは、それ自体で価値があります。ブラウザのログイン時間を有効にすると、ほとんどすべてのゲームで、以前に渡された位置に戻ることができます。ログの「Setup:」という表記の後に続く行をURLにコピーするだけで十分です。デバッグに大いに役立ちます!
カスタム「プログレッシブレベル」は、神様などの複雑なライフサイクルゲームに適用できます。最後の行の数字の1つに達しても、このゲームは終了しません!ルールにより , «» , , . , Dagaz ! , . , , .
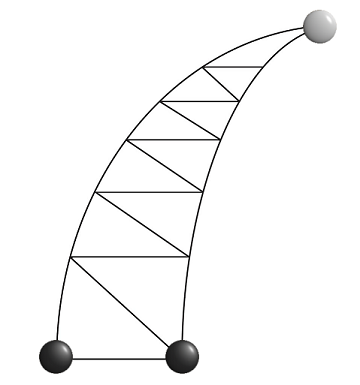
これはもともと中国の子供向けのゲームです。黒い石は下に移動できず、白い石はどの方向にも移動できます。さらに読む前に、「ホーン」の上部にある白い石を「クランプ」してみてください。うまくいかない場合は大丈夫です:
ヒントを与える
フランスの戦争ゲームやドワーフのゲームに多少似ていますが、私の意見では、ホーンチェスはこれらのゲームよりもはるかに深く複雑です。あなたが私を信じていない場合は、これを処理してみてください。すべての外見が気取らないため、ゲームはまったく単純ではありません。私は彼女に捧げられたいくつかの科学記事(中国語)を見ました。そして、これはより複雑なAIのデバッグに適した資料です。
主なことは、標識を台無しにしないことです!
Dagaz.AI.eval = function(design, params, board, player) { var r = 0; var white = null; var black = []; for (var pos = 0; pos < design.positions.length - 3; pos++) { var piece = board.getPiece(pos); if (piece !== null) { if (piece.player == 1) { if (white === null) { black.push(pos); } else { r += MAXVAL / 2; } } else { white = pos; } } } if (white !== null) { r += white; } if (black.length == 2) { if ((black[0] + 1 == black[1]) && (black[1] + 1 == white)) { if (board.player == 1) { r = MAXVAL; } else { r = -MAXVAL; } if (player == 1) { r = -r; } } } return r; } Dagaz.AI.heuristic = function(ai, design, board, move) { var b = board.apply(move); return design.positions.length + Dagaz.AI.eval(design, ai.params, b, board.player) - Dagaz.AI.eval(design, ai.params, board, board.player); } ... AbAi.prototype.ab = function(ctx, node, a, b, deep) { node.loss = 0; this.expand(ctx, node); if (node.goal !== null) { return -node.goal * MAXVALUE; } if (deep <= 0) { return -this.eval(ctx, node); } node.ix = 0; node.m = a; while ((node.ix < node.cache.length) && (node.m <= b) && (Date.now() - ctx.timestamp < this.params.AI_FRAME)) { var n = node.cache[node.ix]; if (_.isUndefined(n.win)) { var t = -this.ab(ctx, n, -b, -node.m, deep - 1); if ((t !== null) && (t > node.m)) { node.m = t; node.best = node.ix; } } else { node.loss++; } node.ix++; } return node.m; }
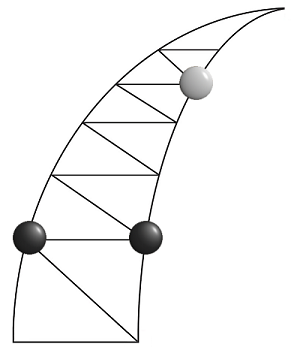
これが重要なポイントの1つです。右の黒い石を上に移動します。弱い「ワンステップ」アルゴリズムは停止し、その後ブラックは簡単にそれをコーナーに追い込みます。ミニマックスの実装-正しい動きをした後、ブラックがミスを犯した場合に勝つことができます。これは、白人を捕まえることが不可能であることを意味するものではありませんが、いくつかの動きを先読みすると、彼らのゲームが大幅に改善されます!
上記では、天ji将giの例を使用して、さまざまなボードゲームが互いに非常に異なる可能性があることをすでに示しました。まず、これは変動性に適用されます-ゲームの特定の段階で許容される動きの平均数。このパラメーターは、ボットを開発するときのAIアルゴリズムの適用可能性を決定します。ホーンチェスで使用したミニマックスアルゴリズムは明らかにKo ShogiやGwangsanghuiのような本当に大きなゲームではうまく動作しません。一方、それらで使用される「攻撃的な」アルゴリズムは、チェスなどのゲームであまりにも弱く再生されます。しかし、これは問題の一部にすぎません。
主な違いはメカニズムにあります。幸いなことに、これは評価関数とヒューリスティックによってカスタマイズできるものです。悪いニュースは、それらがどのように構築されるべきかを考えることは、単にそうではないということです。「カストディアン」キャプチャ(チベット語「明マング」など)を使用したゲームは、私のポイントを完全に示しています。
ここでは、物質収支の単純な評価だけでは十分ではありません!
var eval = Dagaz.AI.eval; Dagaz.AI.eval = function(design, params, board, player) { var r = eval(design, params, board, board.player); var cover = board.getCover(design); var cnt = null; _.each(cover, function(list) { var cn = 0; _.each(list, function(pos) { var piece = board.getPiece(pos); if (piece !== null) { if (piece.player == board.player) { r--; } else { cn++; } } }); if ((cnt === null) || (cnt < cn)) { cnt = cn; } }); r += cnt * 3; if (board.player != player) { return -r; } else { return r; } } var done = function(design, board, player, pos, dir, trace, captured) { var p = design.navigate(player, pos, dir); if (p !== null) { var piece = board.getPiece(p); if (piece !== null) { if (piece.player == player) { _.each(trace, function(pos) { if (_.indexOf(captured, pos) < 0) { captured.push(pos); } }); } else { trace.push(p); done(design, board, player, p, dir, trace, captured); trace.pop(); } } } } var capture = function(design, board, player, pos, dir, dirs, trace, captured) { var p = design.navigate(player, pos, dir); if (p !== null) { var piece = board.getPiece(p); if (piece !== null) { if (piece.player == player) { _.each(trace, function(pos) { if (_.indexOf(captured, pos) < 0) { captured.push(pos); } }); } else { trace.push(p); capture(design, board, player, p, dir, dirs, trace, captured); if (trace.length > 1) { _.each(dirs, function(dir) { var pos = design.navigate(player, p, dir); if (pos !== null) { var piece = board.getPiece(pos); if ((piece !== null) && (piece.player != player)) { trace.push(pos); done(design, board, player, pos, dir, trace, captured); trace.pop(); } } }); } trace.pop(); } } } } var checkCapturing = function(design, board, pos, player, captured) { var trace = []; capture(design, board, player, pos, 3, [0, 1], trace, captured); capture(design, board, player, pos, 1, [3, 2], trace, captured); capture(design, board, player, pos, 2, [0, 1], trace, captured); capture(design, board, player, pos, 0, [3, 2], trace, captured); } Dagaz.Model.GetCover = function(design, board) { if (_.isUndefined(board.cover)) { board.cover = []; _.each(design.allPositions(), function(pos) { board.cover[pos] = []; if (board.getPiece(pos) === null) { var neighbors = []; var attackers = []; _.each(design.allDirections(), function(dir) { var p = design.navigate(1, pos, dir); if (p !== null) { var piece = board.getPiece(p); if (piece !== null) { neighbors.push(piece.player); attackers.push(piece.player); } else { while (p !== null) { piece = board.getPiece(p); if (piece !== null) { attackers.push(piece.player); break; } p = design.navigate(1, p, dir); } } } }); if (neighbors.length > 1) { var captured = []; if ((_.indexOf(attackers, 1) >= 0) && (_.indexOf(neighbors, 2) >= 0)) { checkCapturing(design, board, pos, 1, captured); } if ((_.indexOf(attackers, 2) >= 0) && (_.indexOf(neighbors, 1) >= 0)) { checkCapturing(design, board, pos, 2, captured); } if (captured.length > 0) { board.cover[pos] = _.uniq(captured); } } } }); } return board.cover; }
評価関数では、「カバレッジ」を使用するだけでなく、それを計算するアルゴリズムを真剣に作り直す必要がありました。ヒューリスティックに関しては、このゲームでは完全に初歩的です:
Dagaz.AI.heuristic = function(ai, design, board, move) { return move.actions.length; }
移動する部分が多いほど(サイズはそれに依存します)-より良いです!評価機能に一生懸命取り組む必要がありましたが、結果は間違いなく価値がありました。
このビデオは、最も単純な「一方向」アルゴリズムの動作を示していることに注意してください(「安全な」動きがない場合、必ずしも非常に効率的に再生されるとは限りません)。上で述べたように、モビリティと「カバレッジ」を評価する際の会計処理は驚くべきことです!
そして最後に、カストディアンをキャプチャした別の非常に珍しいゲームのビデオ:
そして、私はこれからの休日を祝福するために急いでいます!