
あなたが知っているように、美しさは犠牲を必要としますが、世界は救うことを約束します。 Googleのかなり最近(2015年)のビジュアライザーは、ディープラーニングネットワークで行われているプロセスに対処できるように設計されています。 魅力的ですね。
カラフルなインターフェイスと大声での約束は、このデザイナーのシャイタンの分析に引きずり込まれ、直感的にはグリッチをデバッグしませんでした。 APIは異常に少なく、頻繁に更新されます。ネットワーク上の例は同じです(目は、 ハッキングされたMNISTを見ることができなくなりました)。
実験が無駄にならないように、ロシア語を話すガイドはほとんどなく、英語を話すガイドはすべて同じであるため、洞察の可能な限り簡単な説明をHabrachiansと共有することにしました。 たぶん、この紹介は、Tensorboardに慣れるのに必要な時間と、冒頭の虐待的な言葉の数を減らすのに役立つでしょう。 また、彼があなたのプロジェクトでどのような結果を出したのか、そして彼が実際の仕事を助けたのかどうかも知りたいです。
もう二度と繰り返さないために、Tensorflowでの作業というトピックは取り上げません。たとえば、 ここで読むことができます。最後に、Tensorboardの使用例を見てみましょう。 Tensorflowで使用される操作グラフの概念はおなじみのものであるという前提でナレーションを行います。
公式のGuide Tensorboardには、実際に必要なものがすべて含まれているため、簡単な説明を使用してその場でアイデアをピックアップすることに慣れている場合は、リンクをたどって開発者の指示を使用できます。 それらをすぐに認識して適用することができませんでした。
ロギングの一般原則
TensorFlow(TF)で構築されたネットワークのパラメーターを取得することは非常に困難です。 TensorBoard(TB)は、このタスクのツールとして機能します。
TFは、「ボックス」- 要約 、TBが表示するデータを収集できます。 さらに、これらの「ボックス」には、さまざまなタイプのデータ用のいくつかのタイプがあります。
-tf.summary.scalarここには、トレーニングの各時代(またはすべてではない)での損失関数など、任意の数値を入力できます。 TB単位の表示は、通常のグラフx(n)の形式になります。
-tf.summary.image画像を収集します。
-tf.summary.audio音声ファイルを収集します。
-tf.summary.textテキストデータを収集します。
-tf.summary.histogram一連の値を収集し、各記録ステップのこれらの値の分布のTB「階層化」ヒストグラムに表示します。 重みデータを保存するのに適しています。トレーニングの各時代の値の変化を追跡できます。
「ボックス」の名前と値を取得する変数は、引数として設定されます。 例:
tf.summary.scalar('loss_op', loss_op)
私のタスクでは、スカラーとヒストグラムのタイプが関連していました。
スカラーとヒストグラムはどのように見えますか
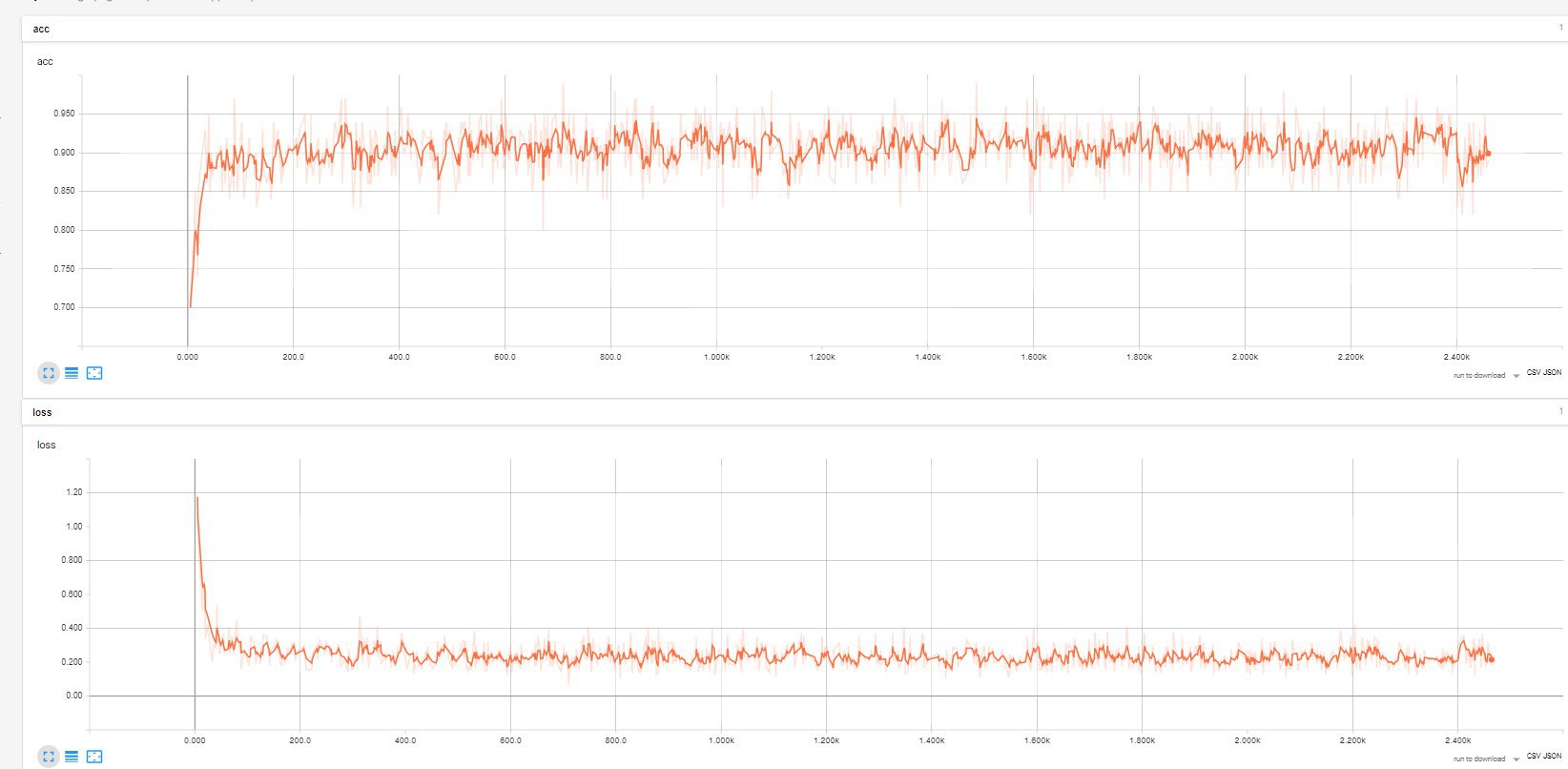
トレーニングセットと損失関数の精度。 平滑化されたグラフは太字で描かれ(平滑化の程度はユーザーがスライダーで設定します)、淡い-元のデータです。
2つの学習率値(0.001および0.0001)の3つのレイヤーの重みのヒストグラム。
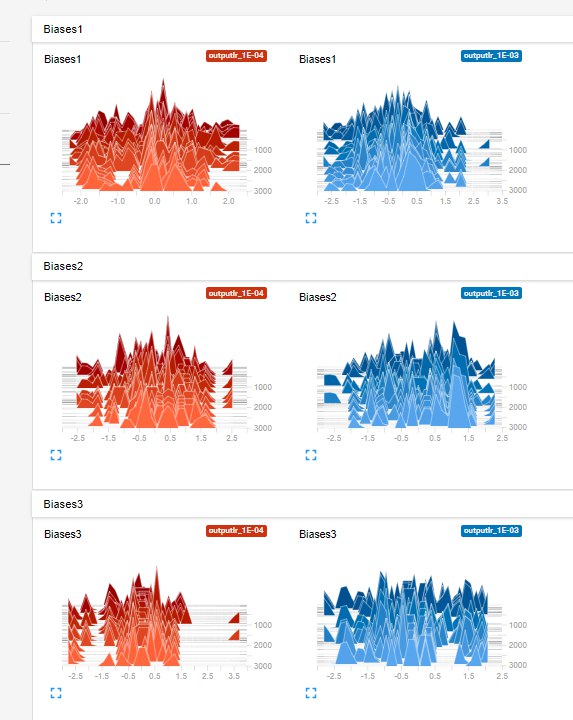
2つの学習率値(0.001および0.0001)の3つのレイヤーの重みのヒストグラム。
各「ボックス」を個別に明示的に補充しないようにするには、 merge_all()を使用して、1つのヒープでこれらを収集し、一度にすべての「ボックス」に必要なデータを取得します。
tf.summary.scalar('loss_op', loss_op) # "" . tf.summary.scalar('accuracy', accuracy) # tf.summary.histogram('Biases1',biases['h1']) # ( h1) tf.summary.histogram('Weights1',weights['h1']) # """ ... , summaries ... """ merged_summary_op = tf.summary.merge_all() # ""
当然、前述のprecision 、 loss_op 、 biasおよびweightsは、現在の操作グラフの参加者として個別に宣言されます。
さらに、 merged_summary_opは 、セッションの実行中の適切なタイミングでアクティブ化されるだけです。 たとえば、トレーニングを開始する場合:
[_, _, sum_result] = sess.run([train_op, loss_op,merged_summary_op], feed_dict={X: batch_x_norm, Y: batch_y}) # , , "", sum_result summary_writer.add_summary(sum_result, i) # , i-
お気づきのように、結果は「レコーダー」のsummary_writerとそのadd_summary関数を使用して( ちっぽけなことに申し訳ありませんが、別の方法は思いつきませんでした)ファイルに書き込まれます。 「レコーダー」は事前に宣言されており、ログのあるフォルダーへのパスが引数に示されています。 テストおよびトレーニングサンプルに結果を投稿するために複数のライターを作成すると便利です。これについては次の記事で説明します。 さらに、使用したハイパーパラメーターの値をログに追加できます(学習率、アクティベーション関数のタイプ、レイヤー数など。ハイパーパラメーターの設定方法の詳細については、 こちらをご覧ください )。短いものもTBで表示されます。
Log_Dir="logs/outputNew/myNet" # hparam= "LR_%s,h1_%s,h2_%s,h3_%s" % (learning_rate,n_hidden_1,n_hidden_2,n_hidden_3) # summary_writer= tf.summary.FileWriter(Log_Dir+hparam) summary_writer_train.add_graph(sess.graph)# writer TB
TBビジュアライザーは、次のコマンドを使用して(もちろん、コンソールから)起動されます。
tensorboard --logdir='Log_Dir'
したがって、セッションを実行し、ネットワークをトレーニングし、ログに必要なすべてのデータを収集したら、localhost:6006に移動して、最終的にブラウザでそれらを見ることができます。 あなた自身がさまざまな表示形式を扱うことになると思います:少なくともこれはTBにとって本当に直感的です。 グループでグラフを便利に表示する方法(ハイパーパラメーターなど)について説明し、次の記事でタグを使用します。
したがって、一般に、 TBの土壌を準備するプロセス (もちろん、TFを使用して操作のグラフを構築する機能を省略するプロセスは 、今ではそれについてではありません)は次のようになります。
- TFでの作業の原則に従って、 操作のグラフを作成します
- 「ボックス」を作成します-ログに収集するデータの要約
- merge_all()ですべてのボックスをマージします
- 「record」 summary_writerを設定します。ここで、ログのパスを示し、すぐにグラフを追加します
- セッション中に、run-eで連続したボックスを呼び出し、 summary_writerを使用して結果を書き込みます
- 結果をTBで見て 、指を交差させた
発生する可能性のある3つの問題
TBはログを見ません
それらに示されたパスを確認してください! 再び表示されない場合は、もう一度確認してください。 そしてそれが機能するまで。 ログフォルダーにファイルがある場合、TBはディレクトリが正しくない場合にのみそれらを見ることができません。
チャートの更新を大幅に禁止
グラフをTBで表示するには、最大15分待つ必要があります。 最初は、これらはロギングの問題だと思っていましたが、TBを再起動しても、新しいデータの読み込みが遅れるという問題の解決には役立ちませんでした。 「ログを書き込む-10分待つ-TBをロードしたものを確認する」モードで作業する必要がありました。 コンピューターがブレーキを非難する必要はなかったため、問題の原因はどこかにあります。 他の誰かがこのグリッチに遭遇したかどうかを聞くのは興味深いでしょう。
名前とデータの重複
定期的に、データの複製がクロールされました。 たとえば、いくつかのタイプの精度または重みが発生する可能性があります。 または、このようなもので、重複の原因が明確でないため、この問題を解決できませんでした。 命名にはもっと注意することをお勧めします-これは時々(操作のグラフと要約で)最終グラフの分析に役立ちます。 時々私が望むものがありません。
次に、テストサンプルとトレーニングサンプルでライターを分離する問題と、ヒープログヒープを表示するためのオプションについて説明します。
時系列のセクションの分類に関するワーキングドラフトでは、結果は単純なロジスティック回帰よりも優れています。さまざまな構成をどのように試行しようとしても、ニューロンは与えませんでした。 しかし、このツールはマスターされているため、将来的に実を結ぶことができます。
お楽しみに!
PS私たちの会社「Inkart」には、勇敢なプログラマーと電子技術者のための空席があり、料理人、クールな企業のパーティー、湖のオフィスもあります。 ロシアのほとんどの心臓専門医が使用している心肺モニターを設計および製造しています。 私たちは常に処理アルゴリズムと問題の鉄の部分を改善しています。 サンクトペテルブルクからの自由な心-詳細については、プライベートメッセージを書いてください。