Backblaze社は、ハードドライブの障害に関する統計を定期的に公開し、さらに、すべてのドライブのパラメーターのSMART 統計を使用してフルアクセスのフルアーカイブを作成します。
この記事では、 スクラップとある種の母親 科学的な方法を使用して、ドライブの信頼性を計算します。
生存分析
統計では、生存分析セクションは生存分析または信頼性分析を扱います 。
要するに、これはさまざまな要因が平均余命(医学)、MTBF(メカニック)などにどのように影響するかを比較および計算できる一連の方法です。 一般的な場合、これはイベントの発生前の時間の分析です。 つまり、次のような質問に答えることです:「適用された治療技術の後しばらくして患者の生存者の割合はどうなりますか?」または「来年ドライブが故障する割合は?」
さらに、患者(または運転)の状態を監視する時間が限られており、すべての患者の寿命を決定することができない場合、そのような質問への答えを探さなければなりません。
規約
- 「イベント」 -患者の死亡、最初の失敗など、測定できる時間または測定したい時間
- 「時間」 -観察の開始からイベントまで、または監視を継続できない瞬間までの実際の時間(患者が去った、ドライブがオフになったなど)
- 「検閲」 -「イベント」の開始までの患者モニタリングの終了。 情報の内容と普及に関する国家監督のシステムとは関係ありません。
- 通常「 S(t) 」と呼ばれる「生存関数」は、患者が時間tまで生存する確率です。通常、S(0)= 100%であり、時間とともに関数は増加しないと想定されます。
- 「ハザード関数」 -h(t)-患者が単位時間あたりの時間tで死亡する確率。 つまり、マイナス記号付きの生存関数の一次導関数。
データ
backblaze社は、すべてのハードドライブのすべてのSMARTパラメーターを.csv
形式で日ごとにファイルに分割したオープンアクセスデータベースを投稿しました。 これらすべてのファイルがデータベースにインポートされた場合(sqlite3にインポートするための独自のスクリプトを提供します)、90126570レコードのテーブルを取得し、約19GBを占有し、 122619ドライブを記述します。 製造元、モデル、シリアル番号、容量、サービス開始日、観測終了までの動作時間(パラメーターSMART 9)、またはイベントとイベントのサインの前のいずれかで、各ドライブに関する次のデータを1つのテーブルにプルする小さなスクリプトを作成しました。 この情報を含むCSVファイルは、 ここからダウンロードできます 。
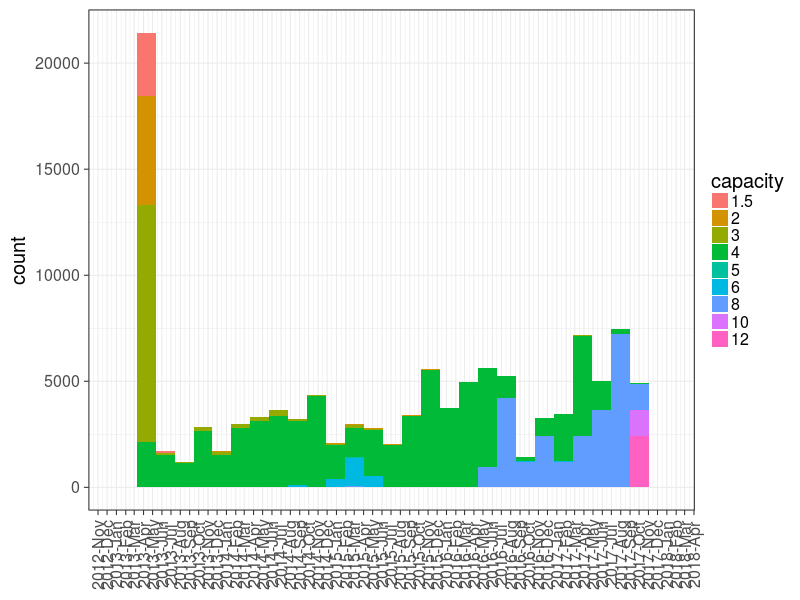
チャート0 :ボリュームと試運転日によるドライブの分布。
統計
処理には、 R
をパッケージtidyverse, survival, survminer, zoo
とともに使用します
まず、サバイバル関数を表す方法の例:
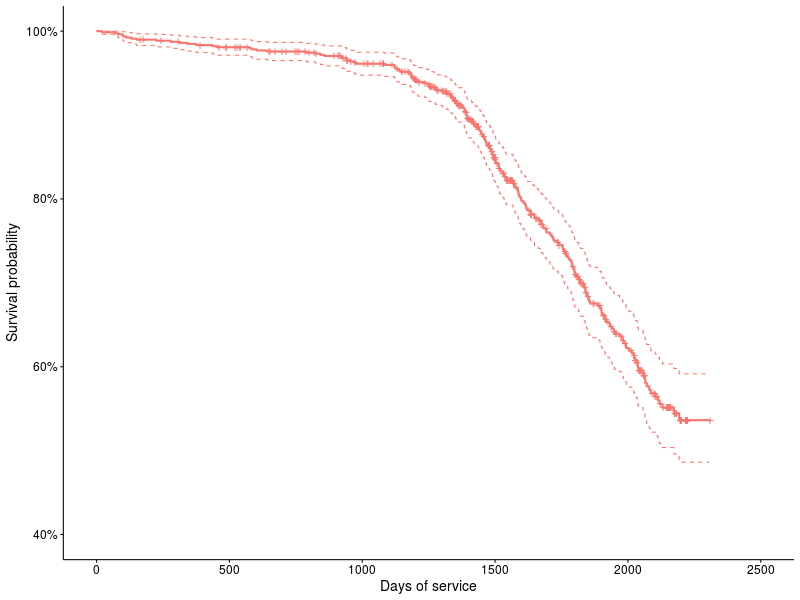
図1 :ST31500341ASドライブのサバイバル機能。
チャート1を見てください:これは、カプラン・マイヤーの方法論によるサバイバルチャートの例です。生き残ったデバイスのパーセント軸は縦軸に、日数は横軸にプロットされています。 十字は検閲されたデバイスを示しています(つまり、少なくともXの瞬間まで生き残った後、トレースは失われます)。 点線は95%の信頼区間を示しています。 Kaplan-Meyer ( KM )の方法論は58年に登場し、その後、生存関数を記述するために積極的に使用されてきたため、これはノンパラメトリックな方法であり、区分関数を使用して生存関数を近似していることに注意する必要があります(つまり、少量のデータで明確に見える手順)。 サバイバルパッケージでは、これは次のように行われます。
survfit(Surv(age_days, status) ~ 1, ...)
引数として、最初に左側に特別なSurv関数がデータとイベントを処理していることを示す式があり、次にデータソース:age_days-時間、ステータス-イベントのコード(1-イベントが発生、0-データが打ち切られます)。 結果はsurvminer
を使用して美しく描画できます。
KMメソッドを使用すると、生存関数を相互に比較して、それらの間に統計的に有意な差があるかどうかを判断できます。たとえば、ST31500341ASとST31500541ASの2つのドライブモデルに関するデータを取得しました。
survfit(Surv(age_days, status) ~ model, ...)
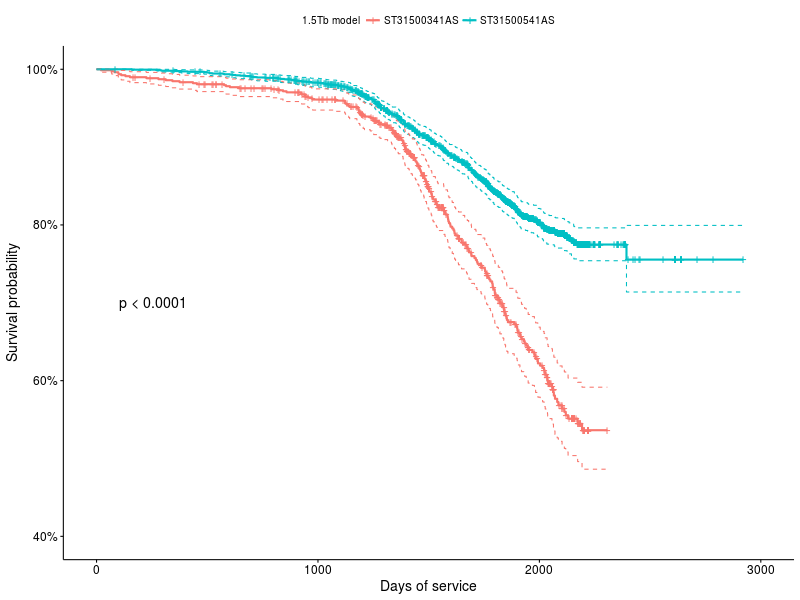
図2 :ST31500341ASおよびST31500541ASドライブのサバイバル機能
分布を比較するには、survdiff関数を使用します。
survdiff(Surv(age_days, status) ~ model, ...) N Observed Expected (OE)^2/E (OE)^2/V model=ST31500341AS 787 216 125 66.4 84.3 model=ST31500541AS 2188 397 488 17.0 84.3 Chisq= 84.3 on 1 degrees of freedom, p= 0
私たちにとって最も重要なことは、p値を持つ最後の行であり、分布に有意差がない確率を示します。この場合、これが不可能であることは目でも明らかです。
このようにして、違いがあるかどうかしかわからない、つまり、層Aが層BよりもXX%早く死亡すると言うことはできないことに注意してください。
別の興味深いチャート、backblaze(ST4000DM000)で最も人気のあるドライブの耐用性がインストール時間によってどのように変化したかを見てみましょう。
survdiff(Surv(age_days, status) ~ start_quarter, ...)
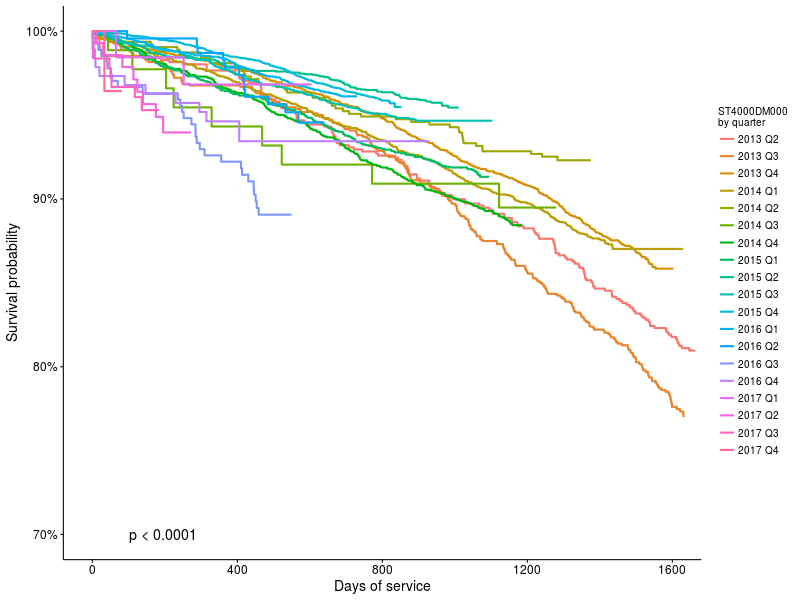
図3 :開始日によるST4000DM000ドライブのサバイバル機能。
違いがあることがわかります(p <0.0001)が、その大きさを知ることは興味深い。
コックスの比例リスクモデル
ここで、Cox比例リスクモデルが役立ちます。異なる階層間の相対リスクを推定できますが、それらはすべて厳密な比率で互いに異なるという仮定に基づいています。
計算には、coxph関数が使用されます。
model_coxph<-coxph(Surv(age_days, status) ~ make + capacity + year, ...)
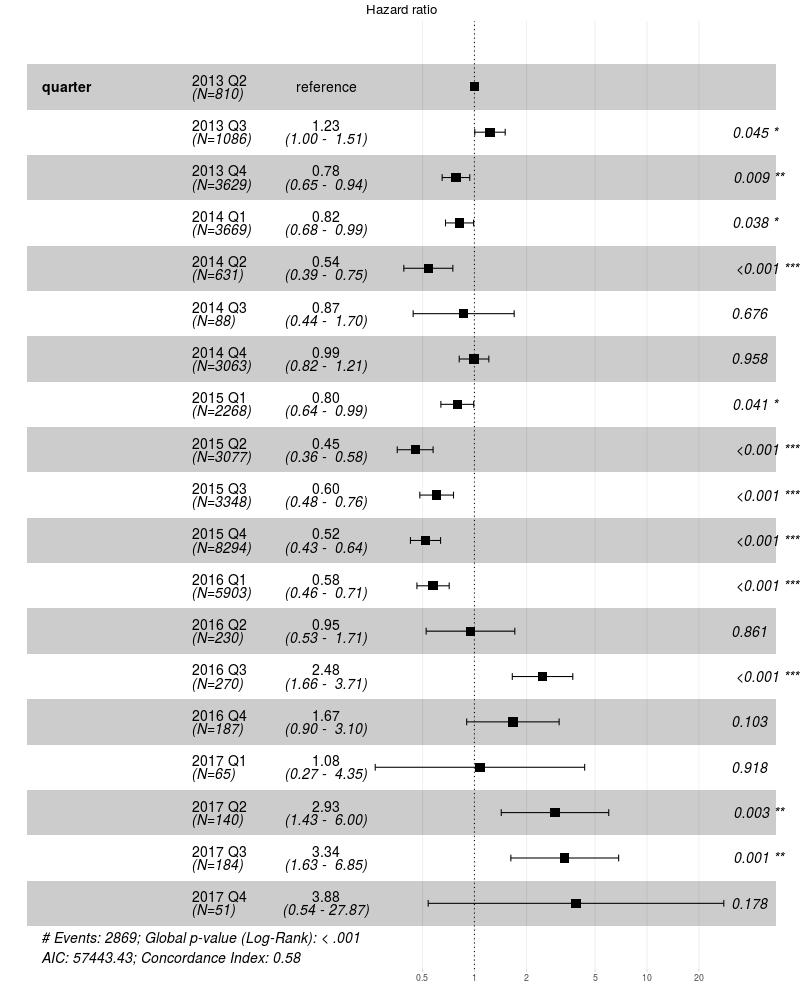
図4 :設置四半期に応じたST4000DM000の相対リスク要因(すなわち、死亡率)。 アスタリスクは、死亡率がベース(2013年の第1四半期)と大幅に異なる場合に四半期を示します。
次に、大容量ドライブの4つの最も人気のあるモデルを比較してください:8TB:ST8000NM0055、ST8000DM002 10TB ST10000NM0086および12TB ST12000NM0007
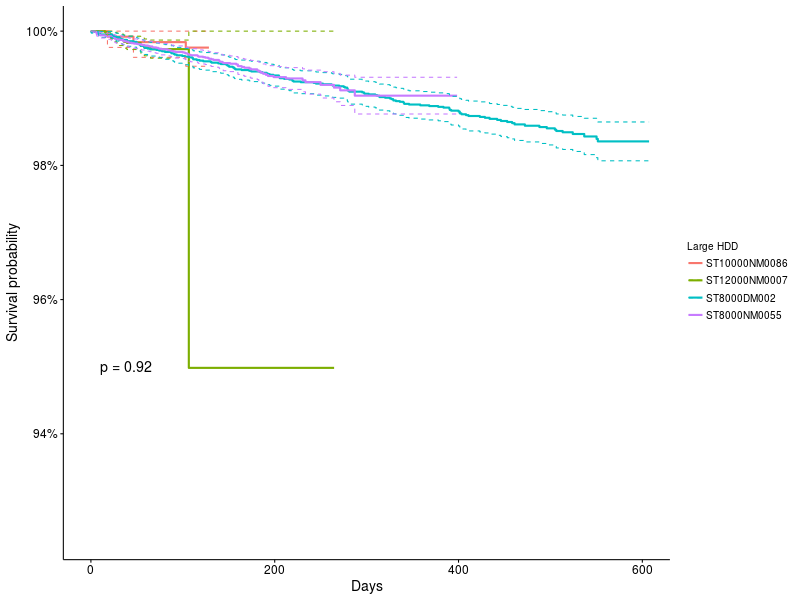
図5 :大容量ドライブのサバイバル機能。
KMメソッドは、ST12000NM0007モデルの奇妙なジャンプにもかかわらず、それらの間に違いがないことを示しています
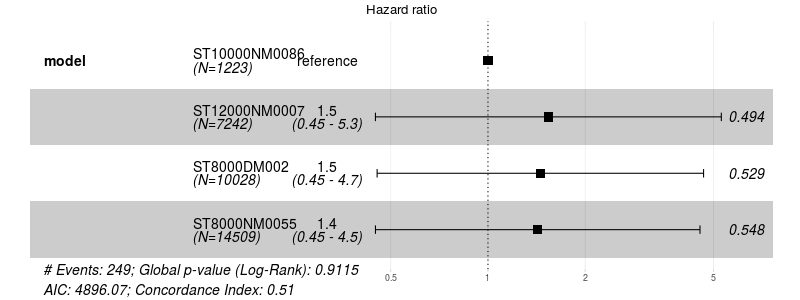
チャート6 :大型ドライブのコークスモデル、統計的差異なし。
最も人気のある10台のドライブを比較する場合、次の図を取得します。

チャート7 :トップ10ドライブのサバイバル機能
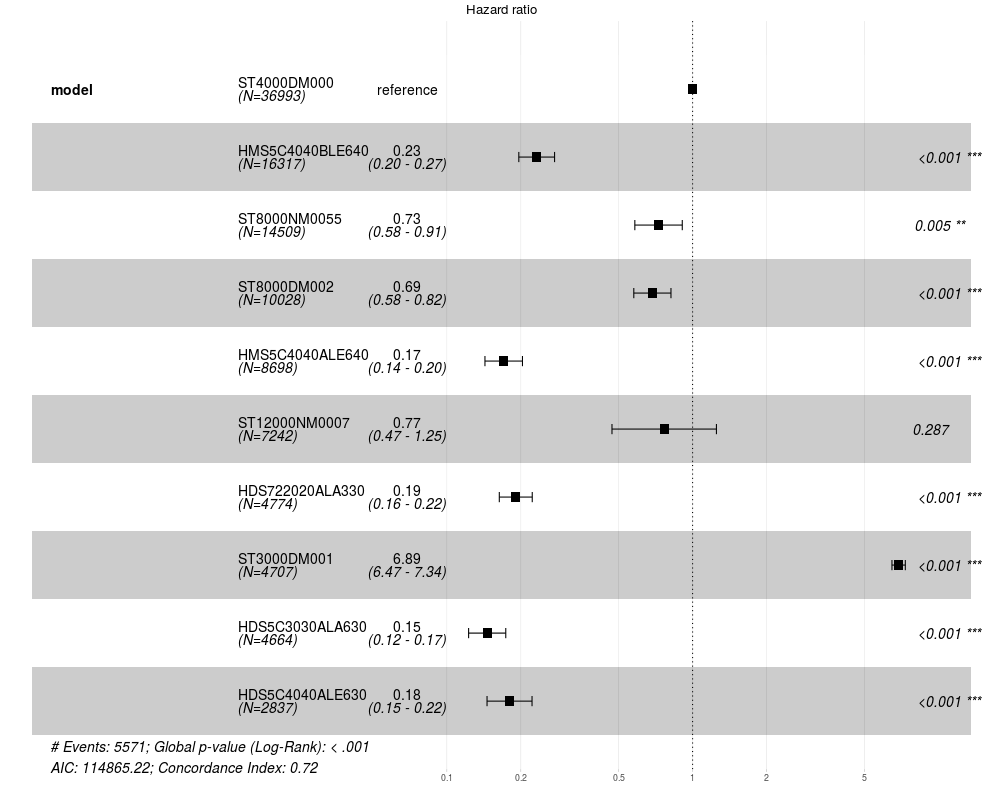
図8 :最も人気のある10台のドライブのコークスモデル
最も信頼性の高いもの:HDS5C3030ALA630、HMS5C4040ALE640、HDS5C4040ALE630、HDS722020ALA330、HMS5C4040BLE640、ペアワイズ比較を行うことができます(違いがあるかどうかに関心がある場合は、pairwise_survdiff関数を使用できます)。
パラメトリックモデル
さまざまなドライブモデルを比較するだけでなく、次のようなより具体的な質問に答えることに興味がある場合は、ファイルサーバーの20個のディスクのうち1つが故障する可能性が高い期間、パラメトリックモデルが助けになります。
最も単純なケースは、一定のリスクを伴うモデルです。ドライブの寿命全体を通じて、一定の期間内に死亡する可能性はほぼ同じであると想定しています。 たとえば、このモデルは放射性同位元素の崩壊を記述しています。 文献では、生存関数は式で記述されるため、指数モデルと呼ばれます。
1年間のドライブの故障率(%)を計算する場合、このモデルを暗黙的に使用します。
実際には、機械システムは、次の式のワイブル関数によってより良く記述されることが知られています。
p <1の場合、失敗の確率は時間とともに減少します。p= 1-指数モデルがあり、p> 1-失敗の確率は時間とともに増加します。
サバイバルパッケージは、 survreg
関数を使用してこのモデルを構築します。
たとえば、10個の一般的なドライブからワイブルモデルを構築してみましょう。
fit_model_weibull<-survreg(Surv(age_days, status) ~ model, data=hdd_common)
指数モデルと比較
fit_model_exp<-survreg(Surv(age_days, status) ~ model, data=hdd_common,dist='exponential')
例としてST4000DM000を使用して、予測分布関数がノンパラメトリックKMとどのように一致するかを見てみましょう。
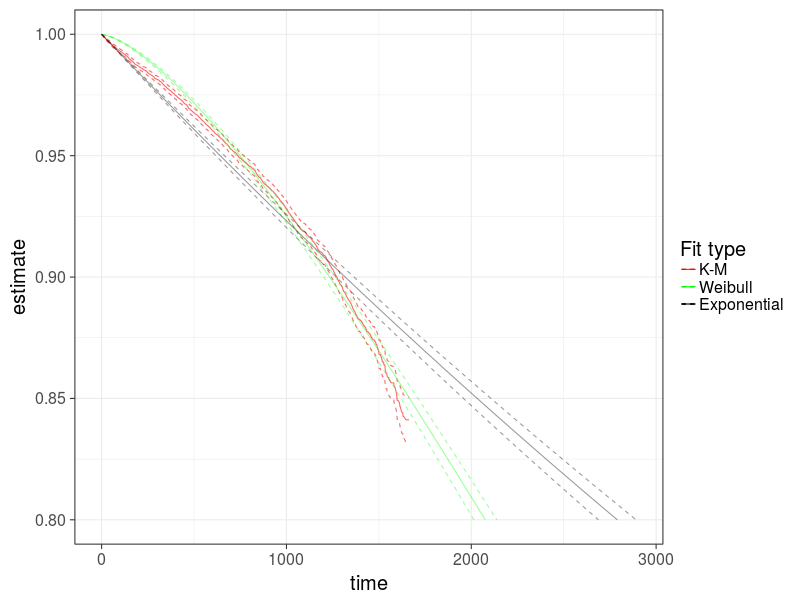
チャート9 : ST4000DM000の例での2つのパラメトリックモデルとノンパラメトリックモデルの比較
ワイブルモデルは、ドライブ障害のプロセスをよりよく表していることがわかります。
赤池情報量基準を使用して、モデルを統計的に比較できます。
AIC(fit_model_weibull,fit_model_exp) df AIC fit_model_weibull 11 112208.8 fit_model_exp 10 112951.3
AIC値が低いモデル-観測されたデータをより適切に説明します。
そして、10%のドライブの予想故障時間を見てみましょう。
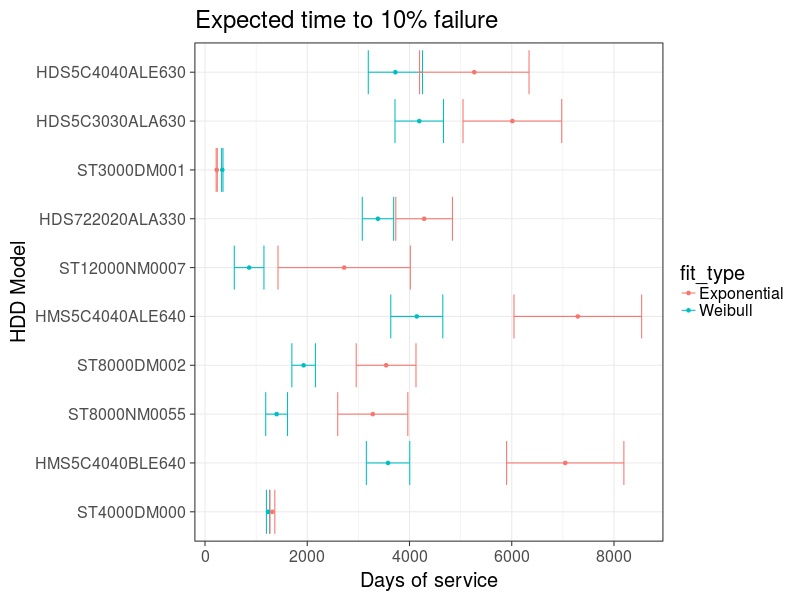
図10 :最も人気のある10台のドライブの故障期間の推定
推定は、Weibulモデルがドライブ障害の以前の推定を提供することを示しています。 ところで、毎年単純にドライブ障害の%%を計算すると、指数モデルの近似が得られます。この場合、過大評価された結果になります。
おわりに
そのため、ドライブの障害に関するデータを自由にレイアウトすることで、ディスク交換の将来のコストを予測できます。
バックブレイズデータセットにはまだ多くの興味深い情報があります。たとえば、ドライブ操作中の温度条件(SMARTパラメーター194)が寿命にどのように影響したか、または書き込みサイクル数(パラメーター241)として確認できます。
計算用のスクリプトと.csvファイルはgithubで入手できます 。
興味があれば、どこかでバックブレイズデータベース全体を含むsqliteデータベースをダウンロードできます(XZパッケージング後2.7GB)
中古文学
- ウィキペディア:生存分析
- survminer: 生存分析と可視化
- マイケル・J・クローリー。 R Book、第2版ISBN:978-0-470-97392-9