この出版の動機は、USENIX会議でのレポート「ログファイル分析のためのRソフトウェアの使用」でした。 印刷された記事全体が書かれているので、トピックが関連していると仮定することは論理的です。 したがって、私はこの種の問題の解決策の例を共有することにしましたが、その解決策はそれほど重要ではありませんでした。 実際、「限界ノート」。
Rは、このようなタスクに本当に適しています。
これは、 以前の出版物の続きです。
Squidの分析
問題の説明は非常に簡単です。 ネットワーク管理者は、誰がどのくらいのダウンリンクトラフィックを消費しているのか、どのサイトがメインシンクであり、誰がそこに行くのかをすばやく知る必要があります。 あなたは大きな話を必要としません、あなたは先週のために、最大のカットを必要とします。 さまざまなオープンソースのアナライザーでの実験は、管理者に喜びをもたらしませんでした(すべてが何かを失っています)。
わかった ファイルaccess.log
(squid)への無料のhttp
アクセスを提供し、Rを取得してインタラクティブなshiny
アプリケーションを作成します。 残念ながら、CRANの特別なwebreadr
パッケージは機能しませんでしたが、これは重要ではありません。 tidyverse
+手は、インポートタスクを5行で解決します。 便宜上、作成されたアプリケーションをshiny
無料サーバーに公開します。
3〜4時間の作業で問題は解決しました。 さらに、ハードコアコマンドラインだけでなく、完全なグラフィカルUIを備えています。 2つのスクリーンコードは、管理者に存在した問題を完全に解決します。
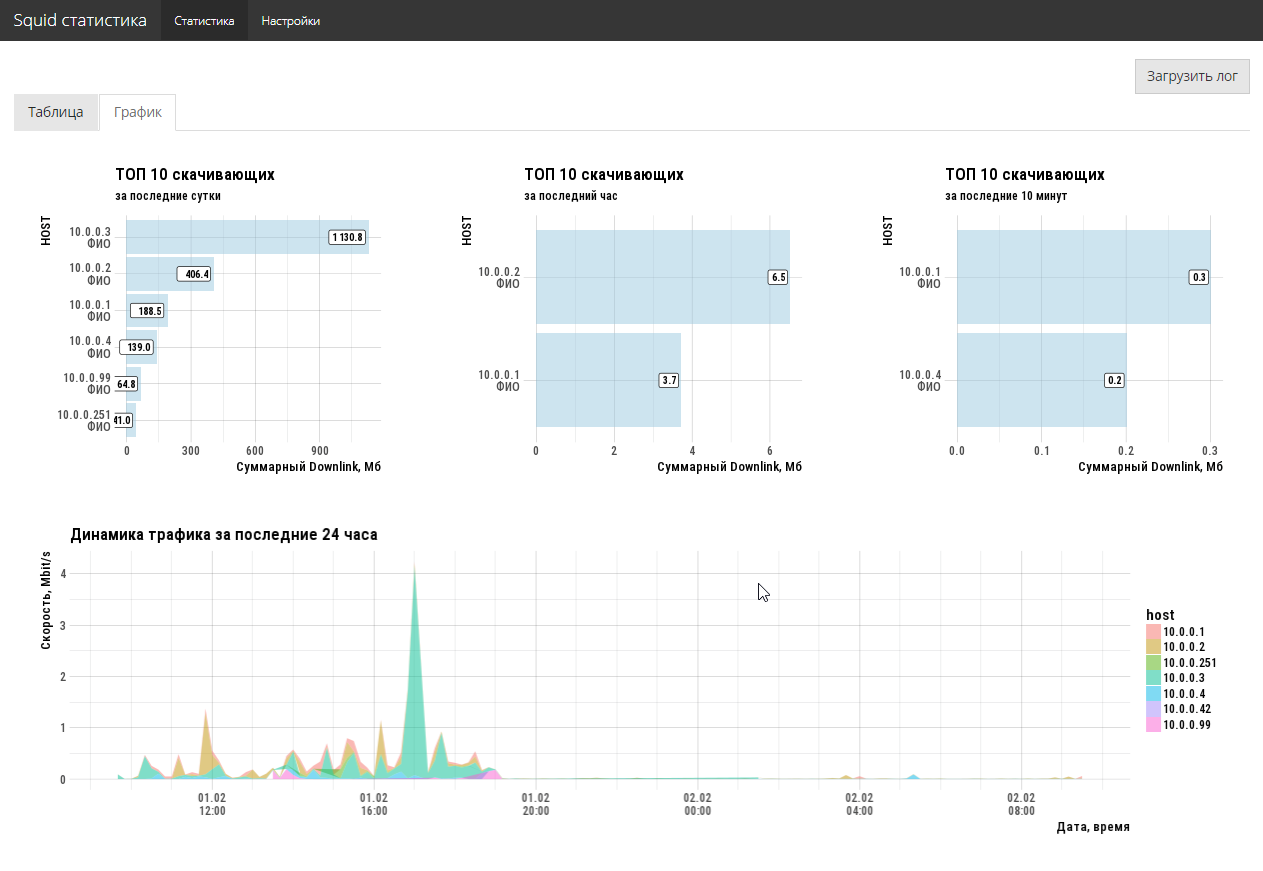
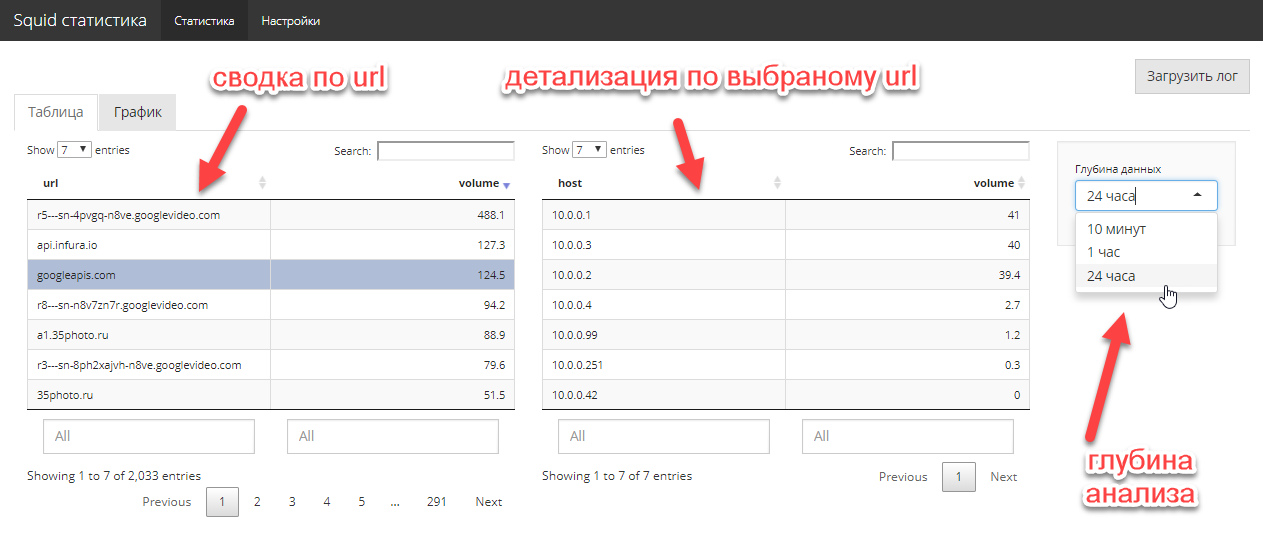
アプリケーションコードはこちらです。 当然、コードは最適ではありませんが、このタスクは設定されておらず、緊急の問題を迅速に解決する必要がありました。
カスタムシステム分析X
いくつかのポイントがある場合、タスクは注意する価値がありません。
- System Xは、いくつかの異なる種類のログファイルを書き込むいくつかのコンポーネントで構成されています。
- データは数万のファイルに散らばっています。
- ログファイルのビューは、正規化されたビューからやや離れており、直接ストリームで食べることは非常に困難です。
これらのファイルのいずれかのコンテンツの断片(一般にノードの数は時間とともに変化します):
2017-12-29 15:00:00;param_1;param_2;param_2;param_4;param_5;param_6;param_7;param_param_8;param_9;param_10;param_11;param_12 Node 1;20645;328;20308;651213;6258;644876;1926;714;1505;541713;75;541697 Node 2;1965;0;1967;89820;236;89605;419;242;396;27714;44;27620 2017-12-29 15:05:00;param_1;param_2;param_2;param_4;param_5;param_6;param_7;param_param_8;param_9;param_10;param_11;param_12 Node 1;20334;1039;19327;590983;2895;588234;1916;3673;1507;498059;347;497720 Node 2;1701;0;1701;89685;259;89417;490;424;419;26013;93;25967
この形式のログファイルの作成者は高い動機に導かれたのでしょうが、通常のツールを使用してコンピューターでそのような創造性を分析することは非常に困難です。
動機を理解し、常連でトリッキーなパーサーを書くのは面倒で、一度はデータサイエンススクラップを使用します。 tidyverse
すべてを原材料でtidyverse
、切断/変換のためにtidyverse
ツールを使用します。 すべてのビジネスを2つのコード画面で行い、数時間の作業(分析、思考、ダウンロード、グラフの作成、結論の作成)を行います。
loadMainData <- function(){ flist <- dir(path="./data/", pattern="stats_component1_.*[.]csv", full.names=TRUE) raw_df <- flist %>% purrr::map_dfr(read_delim, col_names=FALSE, col_types=stri_flatten(rep("c", 13)), delim=";", .id=NULL) df0 <- raw_df %>% # mutate(tms=ifelse(X2=="param_1", X1, NA)) %>% fill(tms, .direction="down") # data_names <- df0 %>% slice(1) %>% unlist(., use.names=FALSE) df1 <- df0 %>% # , , # , , purrr::set_names(c("node", data_names[2:13], "tms")) %>% mutate(idx=row_number() %% 3) %>% filter(idx!=1) df2 <- df1 %>% mutate(timestamp=anytime(tms, tz="Europe/Moscow", asUTC=FALSE)) %>% mutate_at(vars(-node, -timestamp), as.numeric) %>% select(-tms, -idx) %>% select(timestamp, node, everything()) main_df <- df2 %>% tidyr::gather(key="key", value="value", -timestamp, -node) main_df }
出力では、画像が得られます(システムの不均衡がはっきりと見えます)。これに応じて、エンジニアはすでにSystem Xに具体的に対処し始めています。
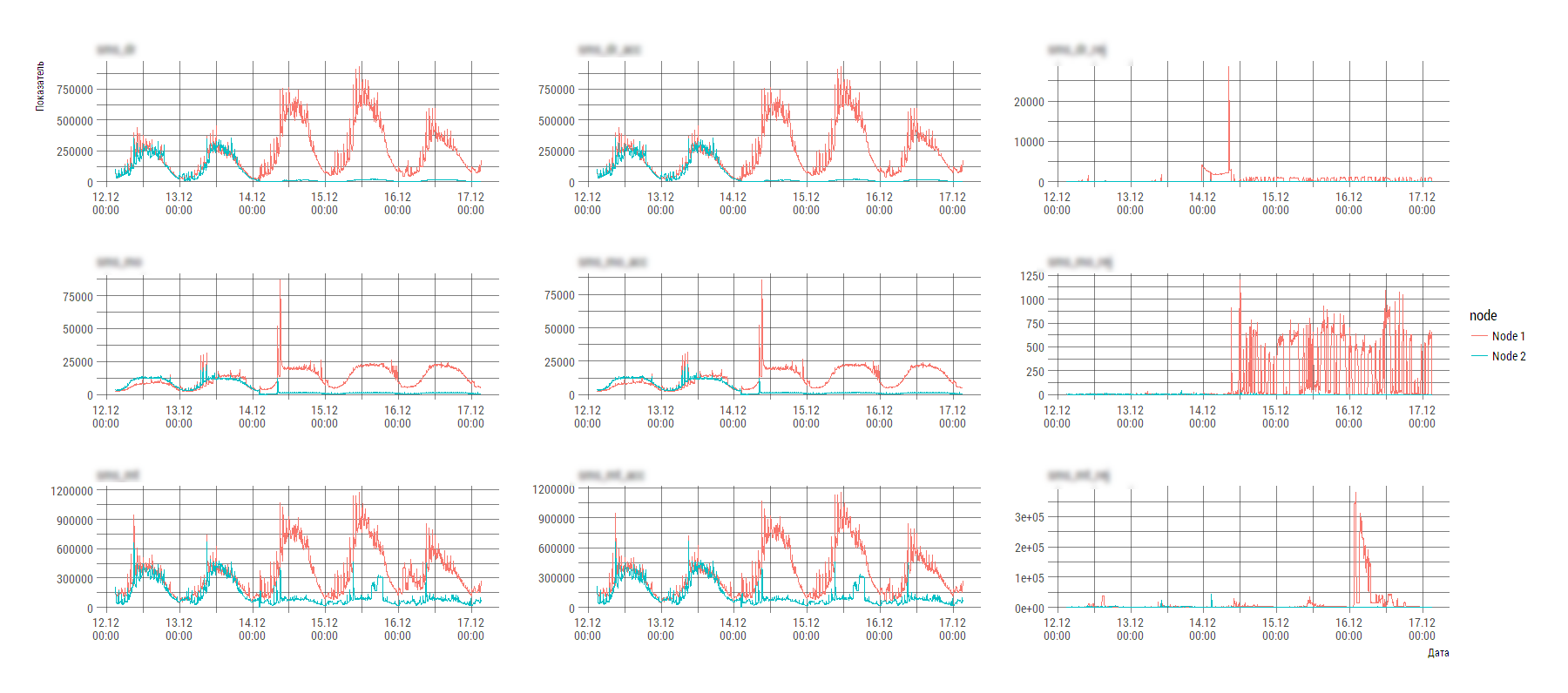
PSこの手法は、初期開発の段階で実行時間の最適化を無視できるようになりました。 合計容量が数ギガバイトのログファイルを操作するには、8GBのRAMを搭載したラップトップで十分で、処理、分析、描画には1〜2分で十分です。
前の出版物-Rによる「HR分析」