
スパイダーからの生データを処理し、データを強化し、インデックスを付け、さらに検索するシステムの主要コンポーネントは、メッセージ処理システムです。 このようなシステムのみが、入力データのピーク負荷、特定の種類のリソースの不足に適切に対応でき、簡単に水平にスケーリングできます。
要求または着信データを処理するシステムの将来の使用を分析するとき、次の要件が強調されました。
- メッセージ処理の低遅延。
- さまざまなソース(DB、メッセージミドルウェア)からデータを受信する機能。
- 複数のノードでデータを処理する機能。
- ノードの障害の状況に対するフォールトトレランス。
- 保証されたメッセージ処理レベルの「少なくとも1回」のサポート。
- クラスターの状態を監視し、それを管理する(少なくとも部分的に)インターフェイスの可用性。
Apache Stormフレームワークが最終ソリューションとして選択されました。 Apache Sparkのファンの場合:このフレームワークの広範な使用(Spark Streamingまたは現在のSpark Structured Streamingを使用)を考慮すると、Apache Sparkの機能と比較して、さらにすべてのナレーションが作成されます。
ただし、両方のシステムが強く交差する機能セットを持っていることを考えると、選択は簡単ではありませんでした。 Apache Stormでは、各メッセージの処理をより詳細に制御できます。選択が優先されました。 次に、違いが何であるか、フレームワークの類似性が何であるか、および「各メッセージの処理をさらに制御する」ことの意味を説明しようとします。
基本的な概念
次に、コードをクラスターに配置して実行する基本的な手順について簡単に説明します。
各システムの完成したコードは、特別なユーティリティ(各フレームワークに固有)を使用してクラスターにロードされますが、どちらの場合も完成したコードはuberjar / shadowJar(フレームワーク自体を除く必要な依存関係をすべて含むjarファイル)です。 さらに、どちらの場合も、エントリポイントのクラスとコード操作パラメーターが(可能なユーティリティキーの1つとして)示されます。
次に、コードはApache StormのトポロジーとApache Sparkのアプリケーションに変換されます。
Apache Stormトポロジ
この方法で、エントリポイントでトポロジを宣言します。
public class HeatmapTopologyBuilder { public StormTopology build() { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("checkins", new Checkins()); builder.setBolt("geocode-lookup", new GeocodeLookup()).shuffleGrouping("checkins"); builder.setBolt("heatmap-builder", new HeatMapBuilder()).globalGrouping("geocode-lookup"); builder.setBolt("persistor", new Persistor()).shuffleGrouping("heatmap-builder"); return builder.createTopology(); } }
すべてが類似したものに変換されます(Apache Sparkトポロジ):
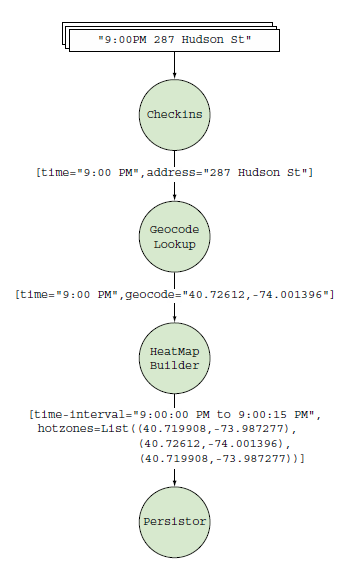
その結果、グラフ(おそらくループを含む)があり、そのタプルが実行されるブランチ(データパケットまたはメッセージがグラフに示されます)で、各ノードはタプルソース-Spout、またはそれらのBoltハンドラのいずれかです。
トポロジを作成するときは、作業に参加するSpout / Bolt、相互接続方法、キーに基づいてクラスタ内でメッセージをグループ化する方法(またはグループ化しない方法)を決定します。 その結果、メッセージをマージ、分離、変換(外部対話の有無)、飲み込み、ループで実行、名前付きスレッドで実行(クラスター要素間の接続にはデフォルトのスレッドがありますが、独自の名前付きスレッドを作成できます) 、たとえば、長時間の処理が必要なパッケージの場合)。
同時に、このすべての動きは、クラスターステータスを監視するためのWebアプリケーションである「Storm UI」の統計とメトリックに反映され、考慮されます。 以下は、いくつかのスクリーンショットです。

Apache Sparkアプリ
同様の方法でエントリポイントでアプリケーションを宣言します(ここでは、Sparkストリーミングについてのみ説明します)。
// Create a StreamingContext with a 1-second batch size from a SparkConf val ssc = new StreamingContext(conf, Seconds(1)) // Create a DStream using data received after connecting to port 7777 on the // local machine val lines = ssc.socketTextStream("localhost", 7777) // Filter our DStream for lines with "error" val errorLines = lines.filter(_.contains("error")) // Print out the lines with errors errorLines.print()
これはすべて、「レシーバー+ Apache Sparkコード+出力操作」のようなものに変換されます。
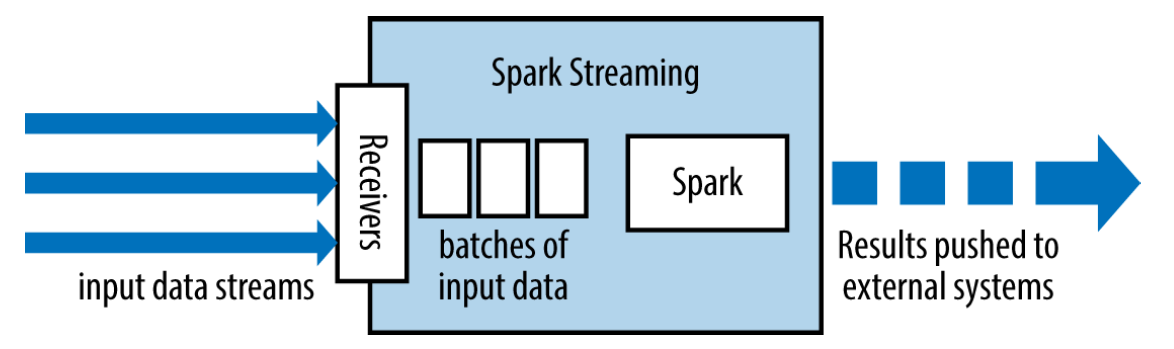
その結果、次のことができます。
- Apache Sparkアプリケーションの実行を調整する制御コード(ドライバー)。
- レシーバー(Spark Streamingの場合)、ソースからデータを読み取り、RDDシリーズを形成します。
- 新しいRDDの処理および生成スキームであるクラスターノード上で実行される非周期グラフ(ドライバーコードによって生成)。
同時に、これらはすべて、クラスターステータスを監視するためのWebアプリケーションであるSpark UIの統計とメトリックに反映され、考慮されます。 以下は、いくつかのスクリーンショットです。
ご覧のとおり、共通の目標にもかかわらず、処理パスと結果の構造の形成方法はイデオロギーがまったく異なり、最終的には実行の差がさらに大きくなります。
クラスタでのApache StormトポロジとApache Sparkアプリケーションの実行
Apache Stormクラスター
Apache Stormクラスターコントロールマシン(Cluster Managerの類似物であるnimbus)にコードをアップロードした後、APache Storm APIを使用して、エントリーポイントのJavaコードからトポロジとその実行に関する情報が形成されます。
- タスクの数。
- 並行性のレベル。
- メッセージハンドラー間で行われる通信。
- 特定のトポロジに固有のクラスター操作パラメーター。
- 作成するワーカーの数など。
このすべての情報とコード(jarファイル)は他のノードに送信され、そこでトポロジの必要な要素(メッセージジェネレーター(Spout)とハンドラー(Bolt)を実装するクラスのインスタンス)が作成され、ノードの追加構成が実行されます。 この後、トポロジーは拡張されたと見なされ、指定されたクラスター構成とトポロジーに従って作業が開始されます。
Storm UIの動作トポロジのスクリーンショット:

クラスター/トポロジーをセットアップするためのレバーのうち、次のものに影響するオプションがあります。
- Apache Stormトポロジ(ワーカー/実行者/タスク)の条件内でクラスターで実行されるSpout / Boltインスタンスの数。
- ノード間でそれらをどのように分散できるか(もちろん直接ではなく、抽象化によって)。
- 要素内のバッファのサイズは何ですか。
- 未処理のメッセージの数と、クラスター内を「歩く」ことができる時間。
- クラスターブレーキは、「バックプレッシャー」メッセージで突然いっぱいになったときにオプションを有効にします。
- デバッグレベル制御。
- 統計収集の頻度(1秒あたり100,000メッセージの着信ストリームで、それぞれを考慮してください-追加の負荷)
Apache Sparkクラスター
コードをクラスターに読み込んだ後、ドライバー(ドライバー)によって実行されるアプリケーションが作成され、多数のRDD処理グラフ(有向非巡回グラフ、DAG)を形成します-> DAGはジョブ(「collect」、「saveAsText」の形式のアクション、など)->ジョブはステージ(ステージ)を形成します(大部分の変換(変換))->ステージはタスク(パーティション(パーティション)の最小作業単位)に分割されます。
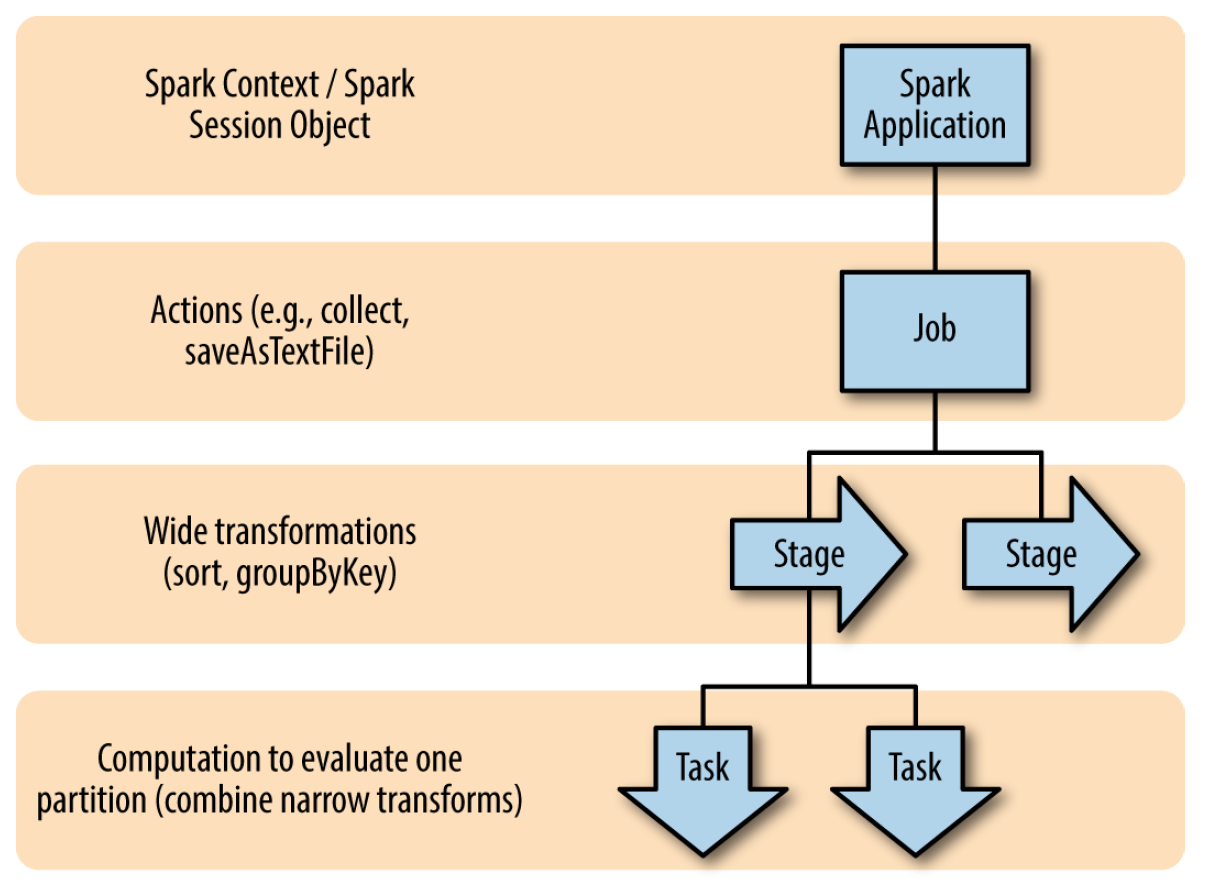
次に、スケジューラはケースに入り、クラスタノード間でタスクとデータを分散します。 アプリケーションコードは、変換とアクションを実行するためにノードに渡されるドライバーとコードフラグメントに存在します。
クラスタ/トポロジを設定するためのレバーのうち、次のものがあります。
- メモリ使用制限;
- コアの数;
- データローカリティのタイムアウト。
- スケジューリングアルゴリズム(FIFO / FAIR)など
もちろん、クラスターのタイプによっては、リソースを操作する機能がリソースマネージャーと異なる場合があります。
その結果、Apache Sparkは、セットとしての考慮事項を考慮したデータストリームの処理に焦点を当てており、一定期間、または処理中に受信したすべての他のメッセージのコンテキストでそれらを分析および処理します。 Apache Stormは各メッセージを個別のエンティティとして扱い、同じ方法で処理します。 マイクロバッチが実行されるトライデントトポロジの場合、このステートメントはあまり変更されません。 バッチ処理は、各メッセージのサービストラフィックと不要な接続を最小限に抑える手段です。 ここから、異なるクラスターアーキテクチャ、異なるメッセージ処理エンティティ、およびApache StormとApache Sparkでのそれらの動作を取得します。
その結果、クラスター内のリソースを管理するアプローチは、処理プロセスに対する抽象化のレベルを反映していることがわかります(「抽象化が高い-影響が少ない」)。
現在のプロジェクトトポロジ

ご覧のとおり、現在のトポロジも線形(アルゴリズムは非常に単純)であり、クラスターのトポロジの管理と更新を容易にするために、「個別のソース-個別のトポロジ」という原則に従って分割されています。
Apache Stormの追加機能
DPRC(分散RPC)
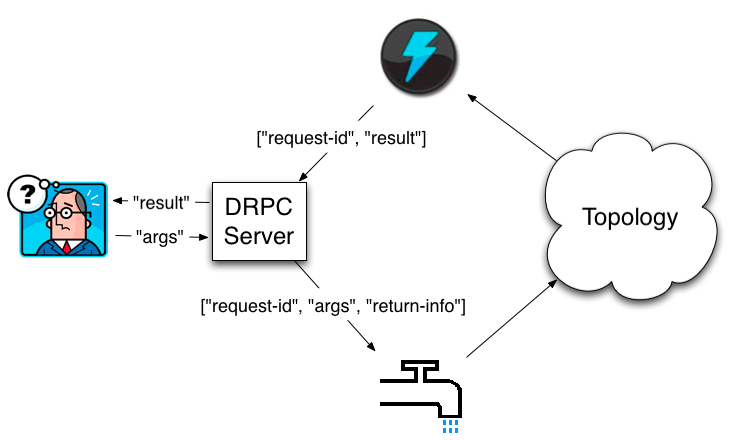
Apache Stormの興味深い機能はDPRC(Distributed RPC)です。これは、実際にクラスターで処理されるメソッド呼び出しを行う機能です。 指定された機能は、RESTクライアントを実装するときに使用され、その応答はその後Nginxによってキャッシュされます。
作業のスキームは簡単です。デーモンがリクエストを受信してバッファリングする->トポロジにリクエストを送信する特別なSpout->データを送信し、入力バッファからリクエストを削除する非表示のコレクター。 その結果、クラスターで要求処理を実行できるため、シンプルだが強力なツールが得られますが、呼び出し側にとってはこれは単なるRPC呼び出しです。
Apache Sparkにはこのようなソリューションはありませんが(私は知っています)、実装はそれほど複雑ではないと思います。
トライデント
Tridentは、Apache Stormプリミティブを使用してリアルタイムの計算を実行するための高レベルの抽象化です。 これにより、高スループット(1秒あたり数百万のメッセージ)、ストリーム処理、および分散リクエストの低レイテンシを伴う状態監視を簡単に組み合わせることができます。 PigやCascadingなどの高度なバッチ処理ツールに精通している場合、Tridentの概念は非常によく知られています-Tridentには、接続、集約、グループ化、関数、およびフィルターがあります(基本的にApache Spark RDDと同じ抽象化) これに加えて、トライデントは、任意のデータベースまたはストレージ上で増分ステートフル処理を実行するためのプリミティブを追加します。 トライデントには一貫性のある正確に1回のセマンティクスがあるため、それに実装されたトポロジを理解するのは非常に簡単です。
Tridentの欠点は、トポロジのコードと作成されるSpout / Boltの関係が複雑になることだけです。
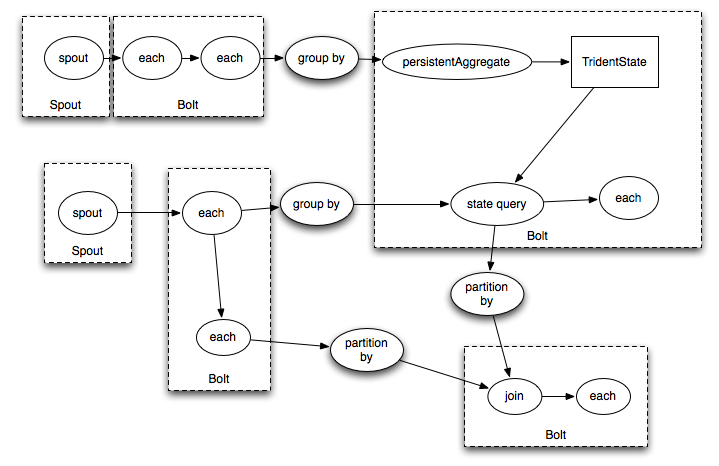
Tridentを使用すると、次のように記述できます。
TridentState urlToTweeters = topology.newStaticState(getUrlToTweetersState()); TridentState tweetersToFollowers = topology.newStaticState(getTweeterToFollowersState()); topology.newDRPCStream("reach") .stateQuery(urlToTweeters, new Fields("args"), new MapGet(), new Fields("tweeters")) .each(new Fields("tweeters"), new ExpandList(), new Fields("tweeter")) .shuffle() .stateQuery(tweetersToFollowers, new Fields("tweeter"), new MapGet(), new Fields("followers")) .parallelismHint(200) .each(new Fields("followers"), new ExpandList(), new Fields("follower")) .groupBy(new Fields("follower")) .aggregate(new One(), new Fields("one")) .parallelismHint(20) .aggregate(new Count(), new Fields("reach"));
このトポロジのようなものを取得します。
Apache Stormの利点:
- 多数のデータソース(データベース、メッセージブローカー-Kafka、HBase、HDFS、Hive、Solr、Cassandra、JDBC、JMS、Dredis、Elasticsearch、Kinesis、Kestrel、MongoDBなど)との統合;
- メッセージを処理するための高レベル関数を備えた特別な言語の存在(Trident);
- 負荷制御用ツールの利用可能性(リソース認識スケジューラ);
- 並列性のレベルを詳細に制御します(一方で、トポロジ要素の作業を理解し、着信データ量の急激な増加に対するシステムの反応を必要とします)。
- 処理されたデータのSQLクエリのサポート(Apache Spark SQLに似た実験機能)。
- 他の非JVM言語のサポート。
- クラスター展開のサポート(YARN、Mesos、Docker、Kubernetes)。
Apache Stormの欠点:
- Clojureでの実装(これはこの側面のプラスとマイナスの両方だと思います)。 ただし、Apache Stormのさらなる開発計画では、バージョン2.0からJavaの実装への移行計画について説明しています。 まず第一に、コミッターのベースを増やすため(各バージョンが良いほど、製品の開発が速くなります);
- フレームワークに関する情報の不足-情報(記事、書籍、ビデオ)は、Apache Sparkよりもはるかに少ないです。
- 私の観点から見てより複雑なアーキテクチャは、結果として、開発者をトレーニングするための曲線が急勾配になっています。間違いを犯す可能性が高いため、フレームワークを克服するための知識/忍耐がまったくない場合があります。
Apache SparkとApache Stormの比較結果
すでに明らかになっているように、Apache Spark(Spark Streaming)とApache Stormは異なるものであり、主に処理のための入力データを生成する方法の側面の質量の違いにより、Apache Spark(マイクロバッチ)とApache Storm Core(メッセージごと)(Apache SparkとApache StormのTridentの比較がここでより適切です)。
- 反応速度(スループットではなく待ち時間):両者によって認識される公式のパフォーマンス比較はありませんが、ほとんどの場合、Apache Sparkの場合は秒、Apache Stormの場合は数分の一です。
- 処理の原則: Apache Storm-マイクロバッチ処理も実行するストリーミング処理のフレームワーク(Apache Stormのトライデント)、Apache Spark-マイクロバッチ処理も実行するバッチ処理のフレームワーク(Spark Streaming)。
- 言語: Apache Storm-Apache Sparkの場合のように、JVMベース、Python、Rだけでなく、ハンドラーを実装するための言語の数がより多様です。
- メッセージ処理の保証: 「最大1回」、「最小1回」、「正確に1回」の3つのセマンティクスのうち、Apache Sparkはすぐに「完全に1回」をサポートします。
- フォールトトレランス:すべてのソースのメッセージをスキップすることに対して100%の保証を提供するフレームワークはありません(このため、ソースは一連の条件を満たし、Kafkaなどの信頼性と耐久性が必要です。HDFSのチェックポイントも考慮する必要があります。独自の遅延を導入する-レイテンシーを削減します。これにより、いくつかのシナリオでそれらを無効にする決定につながる可能性があります。
一番下の行には、独自の特性を持つ2つのフレームワークがあります。正しい決定を行うには、その詳細を考慮する必要があります。
ご清聴ありがとうございました!