機械学習と自然言語処理がどのように急速に発展しているかを見て、私は考えていました:地獄が冗談ではないもの、間違った情報でニュースコンテンツを明らかにし、それによってもたらす壊滅的な結果を少なくともわずかに軽減するモデルを作成できるかもしれません偽のニュースを広めています。

これに反論することはできますが、私の意見では、独自の機械学習モデルを作成する上で最も難しい段階は、トレーニング用の資料を収集することです。 モデルに顔認識のトレーニングを行ったとき 、2017/2018年シーズンの各NBAリーグプレーヤーの写真を数日間収集する必要がありました。 今、私はこのプロセスに没頭して数ヶ月の苦痛を過ごし、人々が本当のニュースと信頼できる情報として偽装しようとしている非常に不快で恐ろしいことに直面しなければならないとは思いませんでした。
偽の定義
最初の障害は私にとって驚きでした。 偽のニュースを含むサイトをさらに詳しく調べてみると、誤った情報が含まれている可能性のあるさまざまなカテゴリがあることがすぐにわかりました。 率直な嘘のある記事があります、本当の事実を引用する記事がありますが、それらは誤解され、偽科学的なテキストがあり、ニュースノートに偽装された著者の意見を含むエッセイがあります、風刺があります、主に他の人のつぶやきから成るコンパイラー記事があります引用符。 私は少しグーグルで検索し、人々がそのようなサイトをグループに分類しようとするさまざまな分類を見つけました-「風刺」、「偽物」、「誤解を招く」など。
私は、それらを基礎として同様に利用できると判断し、リストされたサイトのリストに沿って、そこから例を取得しました。 すぐに問題が発生しました。「偽物」または「誤解を招く」とマークされたサイトの一部には、実際に信頼できる記事が含まれていました。 些細なエラーをチェックせずにそれらからデータを収集すると失敗することに気付きました。
それから私は疑問に思い始めました:風刺と主観的なテキストは考慮されるべきであり、もしそうなら、それらは信頼できる素材、偽物または別のカテゴリーにどこに割り当てられるべきですか?
キー分析
偽のニュースサイトで1週間過ごした後、問題を複雑にしすぎているのではないかと考えました。 おそらく、既存のトレーニングモデルの一部を使用して調性を分析し、パターンを特定してみてください。 データを収集する簡単なツールを作成することにしました。見出し、説明、著者とテキスト自体に関する情報、調性の分析のためのモデルを送信します。 後者の場合、 Textboxを使用しました。ローカルで、マシン上で実行でき、すぐに結果を得ることができるので便利でした。
Textboxは、正または負として解釈できる調性スコアを提供します。 それから、アップロードされた各種データ(タイトル、著者、テキストなど)の調性をある程度の重要性があると考え、システム全体をまとめてニュース記事の一般的な評価を取得できるかどうかを確認するアルゴリズムを打ち上げました。
最初は、すべてが順調に進んでいるように見えましたが、7回目または8回目のロード後、システムは低下し始めました。 一般に、これらすべては、私が作成したい偽のニュースを識別するためのツールに近づいていませんでした。
それは完全な失敗でした。
自然言語処理
この段階で、友人のデビッド・ヘルナンデスは、自分でテキストを処理するようにモデルを訓練するように勧めました。 これを行うには、さまざまなカテゴリのテキストから可能な限り多くの例を必要としました。これは、モデルによるとモデルが認識できるはずです。
偽サイトのパターンを特定する試みですでに苦しんでいたので、データベースをすばやく構築するために、カテゴリが確実にわかっているドメインからデータを取得して収集することにしました。 ほんの数日で、下のツールが、モデルをトレーニングするのに十分だと考えた大量のコンテンツを収集しました。
結果は悪かった。 トレーニング資料をさらに掘り下げた後、必要に応じて、明確に制限されたカテゴリに正確にパッケージ化できないことがわかりました。 どこかで偽のニュースが通常と混ざり合い、どこかでサードパーティのブログからの完全な投稿があり、90%の記事がトランプのツイートで構成されていました。 ベース全体を最初から処理する必要があることが明らかになりました。
そして、楽しみが始まりました。
すばらしい土曜日に、私はこの無限のプロセスに乗り出しました。各記事を手動で閲覧し、どのカテゴリに該当するかを判断してから、それを巨大なテーブルに不器用にコピーします。 これらの記事は、私が最初に無視しようとした真に嫌な、悪意のある、人種差別的な発言に出会いました。 しかし、最初の数百人の後、彼らは私に圧力をかけ始めました。 すべてが私の目の前に波紋し、色の知覚が誤作動し始め、私の心の状態は非常に落ち込んだ。 私たちの文明はどうやってこれに来ましたか? なぜ人々は情報を批判的に受け取れないのですか? まだ希望はありますか? これはさらに数日間続きましたが、モデルを重要なものにするために十分な材料を集めようとしました。
「偽のニュース」が何を意味するのかわからない、自分が同意しない意見を見ると怒っている、自分の考えだけをとる誘惑に打ち勝つことができない本当。 結局のところ、何が真実とみなされ、何がそうではないのでしょうか?
しかし、結局、私はそれでも自分が目指していた魔法の数に到達し、大いに安心して資料をデビッドに送りました。
翌日、彼は再び教えた。 結果を楽しみにしていました。
約70%の精度を達成しました。 最初の数分で、これは素晴らしい結果であるように思われました。 しかし、その後、Webからのいくつかのランダムな記事を選択的にチェックしてシステムをテストしたところ、誰も実際にその恩恵を受けないことに気付きました。
それは完全な失敗でした。
フェイクボックス
ボードに描画する段階に戻ります。 何が悪いの? デビッドは、おそらくメカニズムを簡素化することがより高い精度の鍵であると示唆しました。 彼のアドバイスに従って、私は自分が解決しようとしている問題について真剣に考えました。 そして、それは私に夜明けを告げました:おそらく解決策は、偽のニュースではなく、信頼できるものを識別することです。 信頼できるニュースは、簡単に1つのカテゴリにまとめることができます。 それらは事実に基づいており、簡潔かつ明確に述べ、最小限の主観的な解釈を含んでいます。 そして、資料を収集する場所から十分な信頼できるリソースがあります。
それで、私はインターネットに戻り、もう一度トレーニングのために新しいデータベースの収集を始めました。 私は資料を2つのグループに分けて配布することにしました。真と偽です。 虚偽の記事には、風刺ノート、主観的な意見のある記事、偽のニュース、および厳密に事実に基づく情報を含まず、AP通信の基準に適合しないその他すべてのものが含まれていました。
さらに数週間かかりました。 毎日、 The OnionからReutersまで、想像できるすべてのサイトから新しいコンテンツを収集するのに数時間費やしました。 私は数千の真と偽のテキストの例を巨大なテーブルにロードしましたが、その数は毎日数百に増えました。 最後に、再試行するのに十分な資料があると判断しました。 私はテーブルをデイビッドに送りましたが、結果を待つことができませんでした。
95%を超える精度を見て、私はほとんど喜びに飛びついた。 ですから、信頼できるニュースを真剣に受け止めてはならないものと区別する記事の執筆パターンを特定することができました。
それは成功でした(ある意味では)。
偽のニュース-戦い
これらの詐欺の主な目的は、誤った情報の拡散を防ぐことでした。その結果を皆さんと共有できることを非常に嬉しく思います。 Fakeboxシステムと呼ばれ、それを使用することは非常に簡単です。 疑わしい記事のテキストを挿入し、「Ananlyze」ボタンをクリックするだけです。
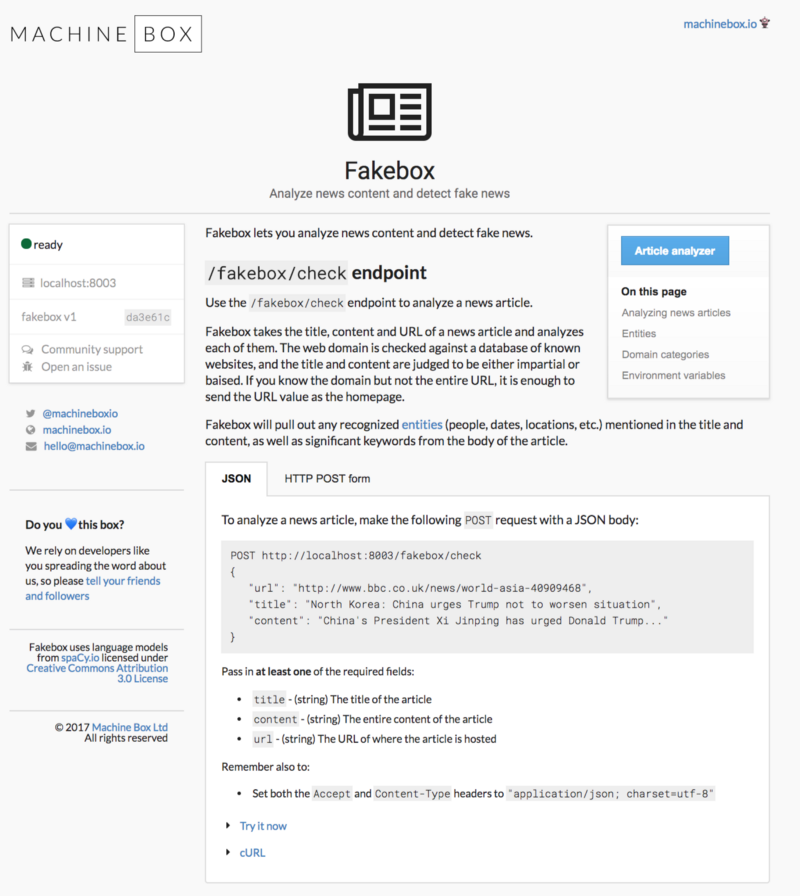
REST APIを使用すると、Fakeboxをあらゆる環境に統合できます。 これはDockerコンテナであるため、いつでもどこでも必要に応じて展開およびスケーリングできます。 必要な速度で無制限の量のコンテンツをシャベルし、注意が必要なすべてを自動的にタグ付けします。
要確認:システムは、テキストが信頼できるニュース記事に特有の言語で書かれているかどうかを判断します。 格付けが非常に低い場合、これはテキストが古典的な形式の事実上のニュース記事ではないことを意味します。誤報、風刺、著者の主観的な意見、または他の何かである可能性があります。
要約すると、テキストの記述方法を分析し、評価語彙、著者の判断、感情的な色付けやわいせつな表現が含まれているかどうかを判断するためのモデルを教えました。 テキストが非常に短いか、主に他の人からの引用(またはツイート)で構成されている場合、失敗する可能性があります。 もちろん、Fakeboxは偽のニュースの問題を完全に解決するわけではありませんが、懐疑的に扱う必要のある素材を特定するのに役立ちます。 お楽しみください!