
ネットワークの認識品質を改善するために、研究者はネットワークにレイヤーを追加しようとしましたが、時間が経つにつれて、パフォーマンスの制限により、このような深いネットワークをトレーニングして使用できない場合があることがわかりました。 これが、深さ方向に分離可能な畳み込みを使用し、Xceptionアーキテクチャを作成する動機でした。
それが何であるかを知り、実際にそのようなネットワークを使用して猫と犬を区別する方法を学ぶ方法を知りたい場合は、猫にようこそ。
モジュールの開始
畳み込みネットワークに別のレイヤーを追加するたびに、その特性について戦略的な決定を下す必要があります。 どのサイズの畳み込みコアを使用する必要がありますか? 3x3? 5x5? それとも、最大プールを入れますか?

2015年にInceptionアーキテクチャが提案されました。その考え方は次のとおりです。カーネルサイズを選択する代わりに、一度にいくつかのオプションを選択し、それらをすべて同時に使用して結果を連結します。 ただし、これにより、1つのレイヤーのアクティベーションを計算するために実行する必要がある操作の数が大幅に増加するため、 元の記事の著者はこのトリックを提供します。各畳み込みブロックの前で1x1のコアサイズで畳み込みを行い、より大きなコアサイズの畳み込みに供給される信号の次元を減らしましょう。
以下の結果の設計は、完全なInceptionモジュールです。
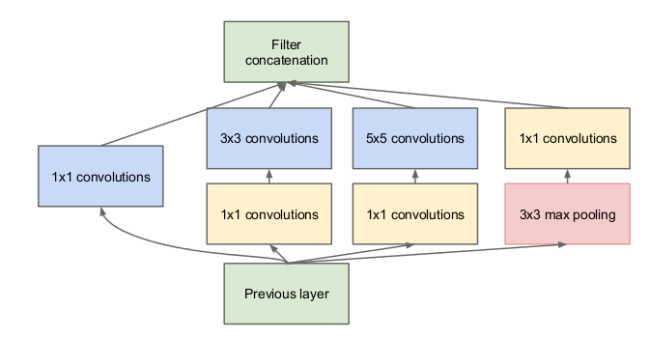
しかし、ネットワークをよりコンパクトにするためにこれは何をする必要がありますか?
2016年、Kerasフレームワークの作成者であり開発者であるFrançoisCholletは、深さ方向に分離可能な畳み込みとしても知られる、いわゆるExtreme Inceptionモジュールの使用を推奨する記事を公開しました 。
深さ方向に分離可能な畳み込み
標準の畳み込み層を使って 入力に次元テンソルが提供される3x3フィルター どこで テンソルの幅と高さ -チャネルの数。
そのような層を作るものは何ですか? 元の信号のすべてのチャンネルを同時に折りたたみます。 さまざまな畳み込み。 そのような層の出力で、次元テンソルが取得されます 。
代わりに、2つの手順を順番に実行してみましょう。

- Inceptionブロックで行ったのと同様に、元の1x1テンソルを畳み込みで折りたたみ、テンソルを取得します 。 この操作は、ポイントワイズコンボリューションと呼ばれます。
- 3x3の畳み込みで各チャネルを個別に折り畳みます(この場合、従来の畳み込み層のようにすべてのチャネルをまとめて折り畳まないため、次元は変化しません)。 この操作は、深さ方向の空間畳み込みと呼ばれます。
用語に関する退屈さ。
実際、通常、深さ方向に分離可能な畳み込みになると、最初にチャネルに沿って畳み込み、次に1x1畳み込みが行われることが暗示されますが、元の記事に示されている操作の順序を正確に示します。 一般に、著者によると、これらの操作の順序は最終結果に影響しません。
これによりネットワークがよりコンパクトになるのはなぜですか?
特定の例を見てみましょう。 32個のフィルターを備えた畳み込み層を備えた16チャンネルの画像を折りたたみます。 合計すると、この畳み込み層は
 重みがあります。 3x3ロール。
重みがあります。 3x3ロール。
同様の深さ方向に分離可能な畳み込みブロックにいくつの重みがありますか? まず、 点ごとの畳み込みの重み。 第二に、
 深さ方向の畳み込みからの重み。 合計で、800個の重みが得られます。これは、従来の畳み込み層よりもはるかに少ないものです。
深さ方向の畳み込みからの重み。 合計で、800個の重みが得られます。これは、従来の畳み込み層よりもはるかに少ないものです。
なぜこれでも機能するのですか?
通常の畳み込み層は、畳み込みがすべてのチャネルに一度に適用されるため、空間情報(1つのチャネル内の隣接ポイントの相関)とチャネル間情報の両方を同時に処理します。 Xceptionアーキテクチャは、これら2種類の情報をネットワークパフォーマンスを損なうことなく連続して処理できるという前提に基づいており、通常の畳み込みをポイントワイズ畳み込み(チャネル間相関のみを処理する)と空間畳み込み(個別のチャネル内の空間相関のみを処理する)に分解します。
実際の効果を見てみましょう。 比較のために、ResNet50とInceptionResNetV2の2つの真に深い畳み込みネットワークアーキテクチャを取り上げます。
ResNet50の重量は25,636,712で、Kerasの事前トレーニングモデルの重量は99 MBです。 ImageNetデータセットでこのモデルによって達成される精度は75.9%です。
InceptionResNetV2には55,873,736個の学習パラメーターがあり、重量は215 MBで、80.4%の精度を達成しています。
Xceptionアーキテクチャはどうですか? ネットワークには、22,910,480の重みがあり、88 MBの重量があります。 同時に、ImageNetの分類精度は79%です。
したがって、ResNet50よりも精度が高く、InceptionResNetV2よりもわずかに劣るだけでなく、トレーニングとこのモデルの使用の両方に必要なリソースの面で大幅に向上したネットワークアーキテクチャが得られます 。
単語を減らし、コードを増やします。
このアーキテクチャを実際のタスクに適用する方法の簡単な例を見てみましょう。 これらの目的のために、KaggleでDogs vs Catsデータセットを取得し、30分でネットワークを教えて猫と犬を区別します。
データセットを3つの部分に分割します:トレーニング(4000イメージ)、検証(2000イメージ)、テスト(10000イメージ)。

Xceptionアーキテクチャの作成者であるFrancois SchollもKerasの作成者であるため、ImageNetでトレーニングされたこのネットワークの重みをフレームワークで提供しました。これを使用して、転送学習を使用してネットワークをタスクに適合させます。
ImageNetからXceptionにウェイトをロードします。Xceptionから、最後に完全に接続されたレイヤーが削除されます。 データセットをこのネットワークに渡して、畳み込みネットワークが画像から抽出できる機能(いわゆるボトルネック機能)を取得します。
input_tensor = Input(shape=(img_height,img_width,3)) base_model = xception.Xception(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg') data_generator = image.ImageDataGenerator(rescale=1. / 255) train_generator = data_generator.flow_from_directory( train_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode=None, shuffle=False) bottleneck_features_train = base_model.predict_generator( train_generator, nb_train_samples // batch_size) np.save(open('bottleneck_features_train.npy', 'wb'), bottleneck_features_train)
完全に接続されたネットワークを作成し、検証のために初期データセットの特別に据え置かれた部分を使用して、畳み込み層から得られたサインでトレーニングします:
model = Sequential() model.add(Dense(256, activation='relu', input_shape=base_model.output_shape[1:])) model.add(Dropout(0.5)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=SGD(lr=0.01), loss='binary_crossentropy', metrics=['accuracy']) checkpointer = ModelCheckpoint(filepath='top-weights.hdf5', verbose=1, save_best_only=True) history = model.fit(train_data, train_labels, epochs=epochs, batch_size=batch_size, callbacks=[checkpointer], validation_data=(validation_data, validation_labels))
GeForce GTX 1060で数分かかるこの段階の後、検証データセットで約99.4%の精度が得られます。
ここで、ImageNetから畳み込み層に重みをロードし、ネットワークが学習したばかりの完全に接続された層に重みをロードすることにより、入力データの増強によりネットワークの再トレーニングを試みます。
input_tensor = Input(shape=(img_height,img_width,3)) base_model = xception.Xception(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg') top_model = Sequential() top_model.add(Dense(256, activation='relu', input_shape=base_model.output_shape[1:])) top_model.add(Dropout(0.5)) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(1, activation='sigmoid')) top_model.load_weights('top-weights.hdf5') model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) model.compile(optimizer=SGD(lr=0.005, momentum=0.1, nesterov=True), loss='binary_crossentropy', metrics=['accuracy'])
このモードでネットワークをトレーニングした後、さらに5つの時代(約20分)に、検証データセットで99.5%の精度を達成します。
一度も見たことがなく、ハイパーパラメーター(テストデータセット)の構成に使用されなかったデータでモデルを確認すると、約96.9%の精度が得られます。

この実験の完全なコードはGitHubにあります 。
次は?
2017年、GoogleはXceptionと同様の原理を使用して、事前に訓練されたMobileNetアーキテクチャネットワークをTensorFlowに追加し、モデルをさらに小さくしました。 これらのモデルは、メモリが非常に限られ、プロセッサが弱い携帯電話またはIoTデバイスでコンピュータービジョンタスクを直接実行するのに適しています。
このように、15分以内に鳥が写真に表示されるかどうかを判断するアプリケーションを作成でき、このアプリケーションがスマートフォンで直接実行されるときに、コンピューターサイエンスの歴史のポイントにいつの間にか近づきました。