
1年半前にこのようなシステムの作成を開始しました。ユーザーに適切な空席を選択するアルゴリズムを機械学習で構築することにしました。 しかし、私たちはすぐに、履歴書に似た欠員と履歴書の所有者が応答したい欠員は同じものとはほど遠いことに気付きました。
この記事では、スマート検索をどのように実行したかを説明します-私たちがしなければならなかったすべての問題、微妙さ、および妥協点について。
推奨システムで開始
hh.ruには、適切な空席のあるニュースレターがあります。 そもそもそれらを取り上げました。まず、求職者に適切な求人を提供する推奨システムを作成することから始めました。
この問題を理解するために、ユーザーに表示される空席と、ユーザーがさらに空いている操作を記録しました。 機械学習を使用して、履歴書/空席ペアの応答確率を予測するために、/ bテストシステムとインフラストラクチャを開発しました。
本番環境では、インデックス作成時の静的特性の計算と一貫したアプリケーションを空室に追加して、リソース消費が増加するいくつかのフィルタリングモデルの概要を追加し、最終ランキングのモデルを追加しました。
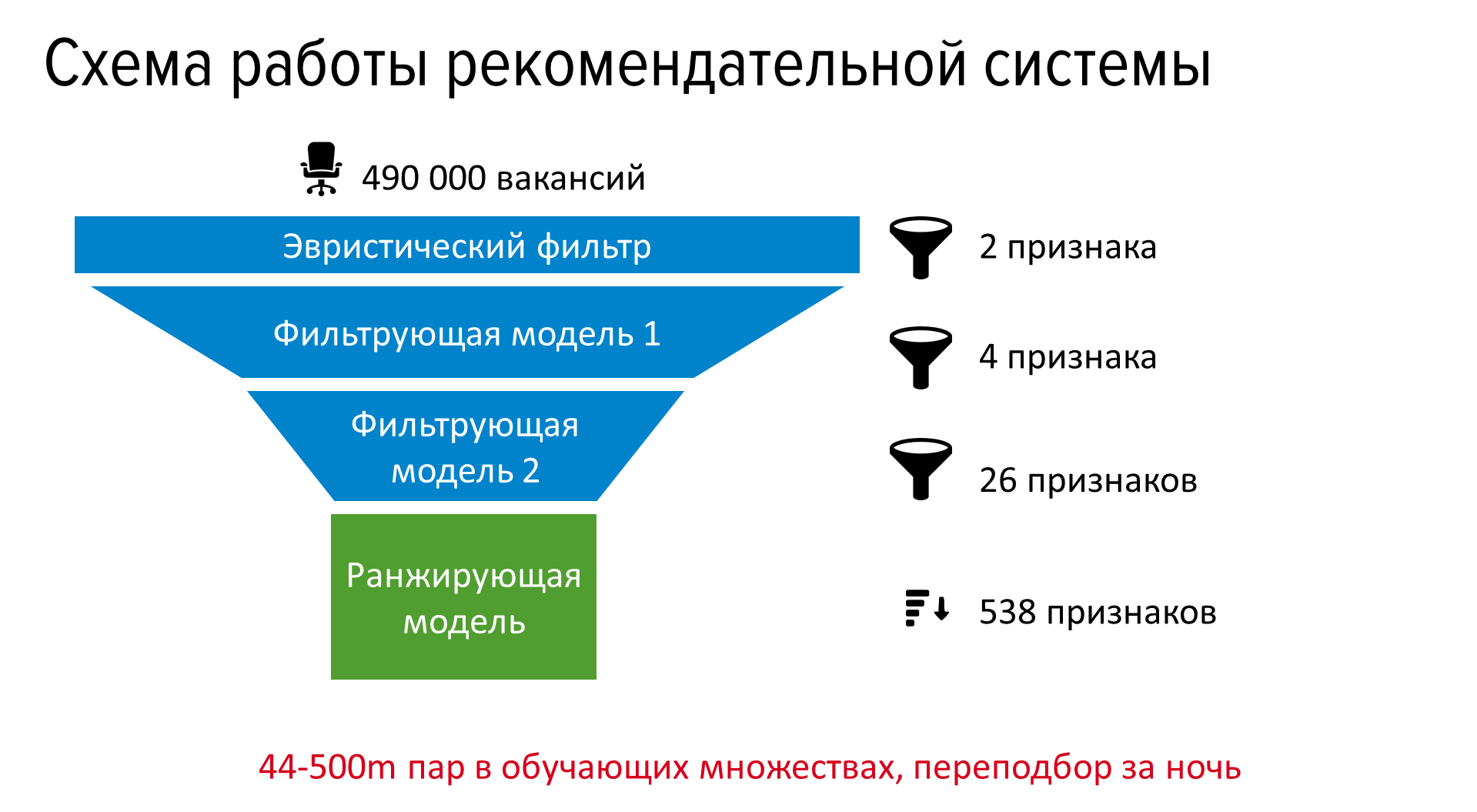
このシステムにより、1か月あたり約120万件の追加の回答が得られるようになりました。これは、約12万人が面接に招待され、2万人が採用されました。 レコメンダーシステムによって選択された空席は、メインのhh.ruのブロック「個人的にお勧めします」に示され、履歴書に適した空席のあるメールで送信されます。
しかし、検索の比較的小さな改善でも、推奨システムの大きな改善よりも有益です。 したがって、次のステップは検索での機械学習の使用でした。
空のリクエストで検索
まず、検索クエリを分析することから始めました。 リクエストの35%で、履歴書を持っているユーザーは検索バーを空のままにしていることが判明しました。 匿名クエリを検討すると、空の検索クエリの数は50%に達します。
ユーザーに履歴書がある場合は、推奨システムを使用することにしました。テキスト対応のランクを推奨システムのランクに置き換えます。 これには大きな変更は必要ありませんでしたが、かなり迅速に行うことができました。
推奨システムのランクを使用すると、1日に数千の追加の応答が得られました。 しかし、その効果は予想より少なかった。 ユーザーは配信の最初の1.5ページだけを平均して表示するため、大都市では、実際には、変更はプレミアム欠員のみです。 システムは、上部に適切な「プレミアム」を表示し、「標準」、「標準+」、無料の空席など、より適切な空席があったとしても不適切でした。
そのため、空席を2つのグループに分割することを確認することにしました:最初に「プレミアム」、「標準+」、「標準」、および無料であり、応答の予測確率が特定の値を超え、次に他のすべてが同じ順序である。
クライアントと雇用主の現在の欠員が悪化しないようにする必要があるため、これらの変更に非常に慎重に取り組みました。実験でも計算と正当化によって5%がサポートされました。 その結果、私たちは実験を行い、すべてのタイプの空席について回答が増加したことを確認しました。
システム性能
モデルを適用する前に、履歴書と欠員によって特性を計算し、それらを組み合わせて組み合わせる必要があります。 推奨システムでは、負荷がそれほど高くなかったため、空席の静的な兆候は、インデックスが作成されて特別なインデックスに入れられたときにすでに考慮され、再開とペアリングはリクエストの処理時に考慮されました。
空のクエリの検索を有効にすると、検索エンジンの負荷が約6倍になることがわかったため、履歴書のサインをキャッシュする必要がありました。 最初に、履歴書のタグを読み取ってCassandraに配置しようとしました。 しかし、それから目的のパフォーマンスを達成するには失敗しました。 したがって、すべてがPostgreSQLのテーブルによって決定されました。
システムから目的のパフォーマンスを得るために追加する必要があったもの:
- 特性が変更されたときのキャッシュの再計算。 履歴書を更新しておらず、サイトに2年以上アクセスしていないユーザーの場合、キャッシュは考慮されず、推奨される空席の分布はテキストで送信されます。 適当な求人があなたのところに来るなら、そうかもしれません:あなたはただ履歴書を更新する必要があります。
- 基本検索の各サーバーが、それが持つインデックス(空席、履歴書、企業)のすべてのオブジェクトに個別にインデックスを付け続ける場合、十分な順序のサーバーがないことに気付きました。 したがって、インデックス作成のシステムを再構築し、「各マスターは自分のマスター」から「メインマスターはスペアマスター-インデックスのセグメントを奪う基本検索」に再開し、マスターのみがインデックス作成に従事し、毎晩データベース全体の最適化と順次ポンピングを行います(モスクワ時間)インデックスの量を減らす。
- フェイルファーストでした-要求の処理中にエラーが発生した場合、基本検索でのHTTP 500の高速応答。 機械学習を使用すると、場合によっては応答時間が大幅に長くなり、そのような要求をキューに入れるのではなく、基本的な検索で平均的なメタ検索にhttp 500という迅速な応答が返されます。 その後、投機的な再試行を行いました。タイムアウトの2/3を超えるベース検索からの応答がない場合、平均メタサーチは事前に別のベース検索を調べます。
簡略化すると、コンポーネントとコンポーネント間のデータフローの観点から、レコメンダー検索システムは次のように配置されます。

システム内のデータストリーム:
- 赤い矢印、(1)-(15)-検索クエリへの応答。各検索リクエストで自動的に開始されます。
- 青い矢印、(16)-(24)-輪郭のインデックス作成、空席、再開、企業の変更時に自動的に開始します。
- 緑の矢印、(25)-(33)-機械学習ループは、モデルの変更(言語、ベクトル化、機能、目的関数、モデルの変更、より関連性の高いデータを使用したモデルの再トレーニング)ごとに手動で開始されます。
- 紫の矢印(34)-(36)-A / Bテストおよびビジネスメトリックのメトリックを計算するための輪郭(1日1回自動的に開始)。
その過程で、クラスターに約10台のサーバーを追加する必要がありました。これは、これまで存在していたサーバーよりも強力です。 彼らの力を合理的に使うことが必要でした。 サーバーの1つが使用できなくなる可能性が高くなりました。 そのため、単純で無条件のラウンドロビンからメタのバランスを再調整して、応答時間と非応答の数を考慮し、それらの数が少ないサーバーに多くの要求を送信するようにしました。
新しいサーバーを使用することに加えて、ユーザーに影響を与えることなく、20%クラスターの突然の障害にも耐えることができました。
単純化すると、アーキテクチャのレイヤーとその中のコンポーネントのインスタンスの観点から、システムは次のように編成されます。
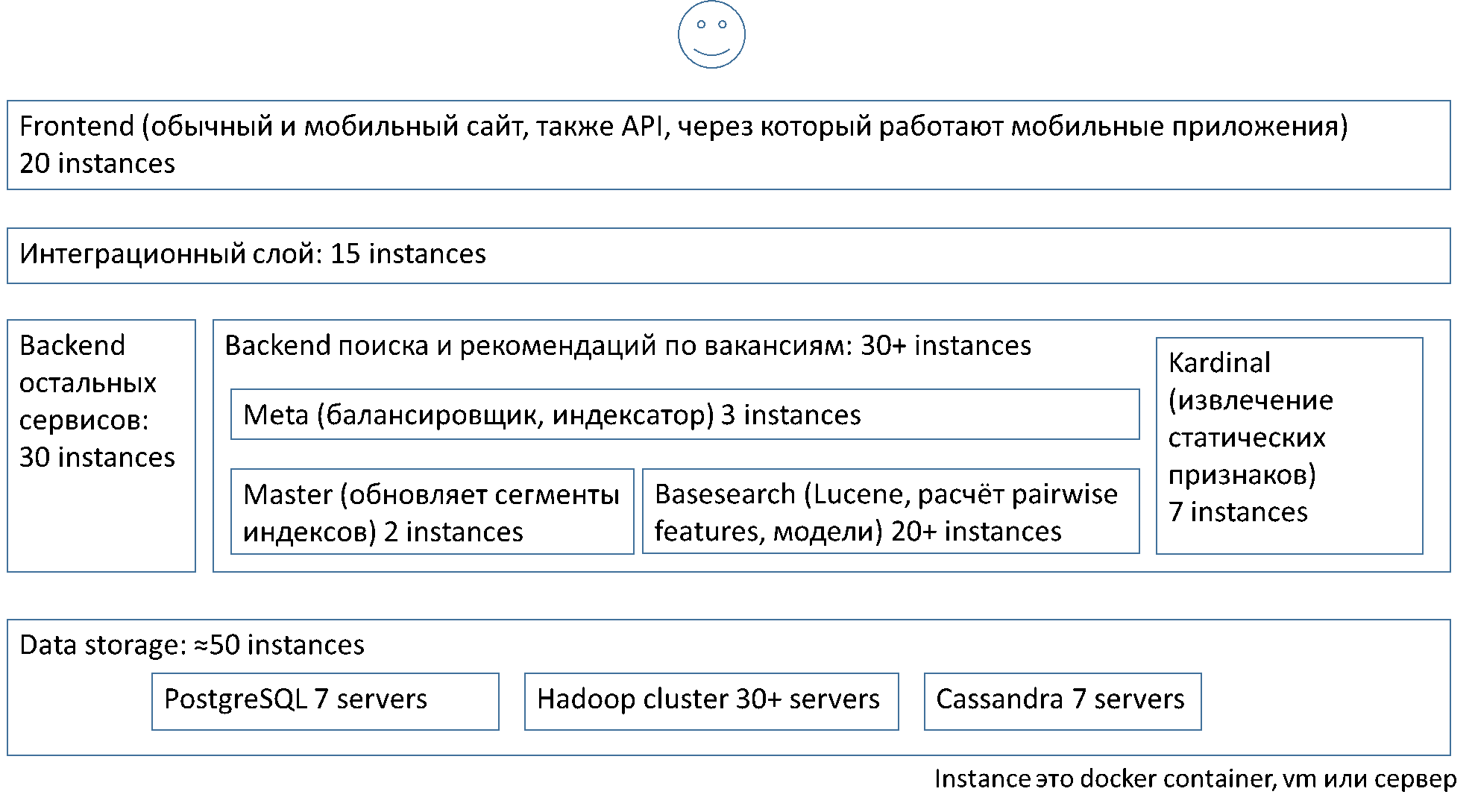
上記のバランスは、平均的なメタ検索(メタ)と基本検索(ベース検索)の間で機能します。
同時に、私たちは、絶えず、推奨システムを改良しました。 テキストの相互作用の属性、段階的な目的関数、テキストの生のsvdベクトルの属性、tf / idfベクトル上の線形回帰のメタ属性が含まれていました。 もう1つの改善がありました。ログとデータベースからの機械学習の初期データのアンロード、クリーニング、結合を繰り返し、1つのコマンドで起動できるようにしました。
空でないクエリによる検索:機械学習
ほぼ同時に、空でないクエリで検索を開始しました。
最初に、Luceneが提供する検索クエリの単語を使用して空席に適用し、レコメンダーシステムからフィルターとランキングを適用しようとしました。 これは統計的に有意な改善をもたらさなかった。 そのため、特別なアンロード「リクエスト-再開-空室-アクション」を作成し、2つのモデルを教えました。
- 線形:適切な欠員を不適切なものから分離し、不適切なものを大まかにランク付けするために、リソースの強度が低く、迅速に使用されます。
- XGBoost:適切なものをより正確にランク付けするために使用されます。
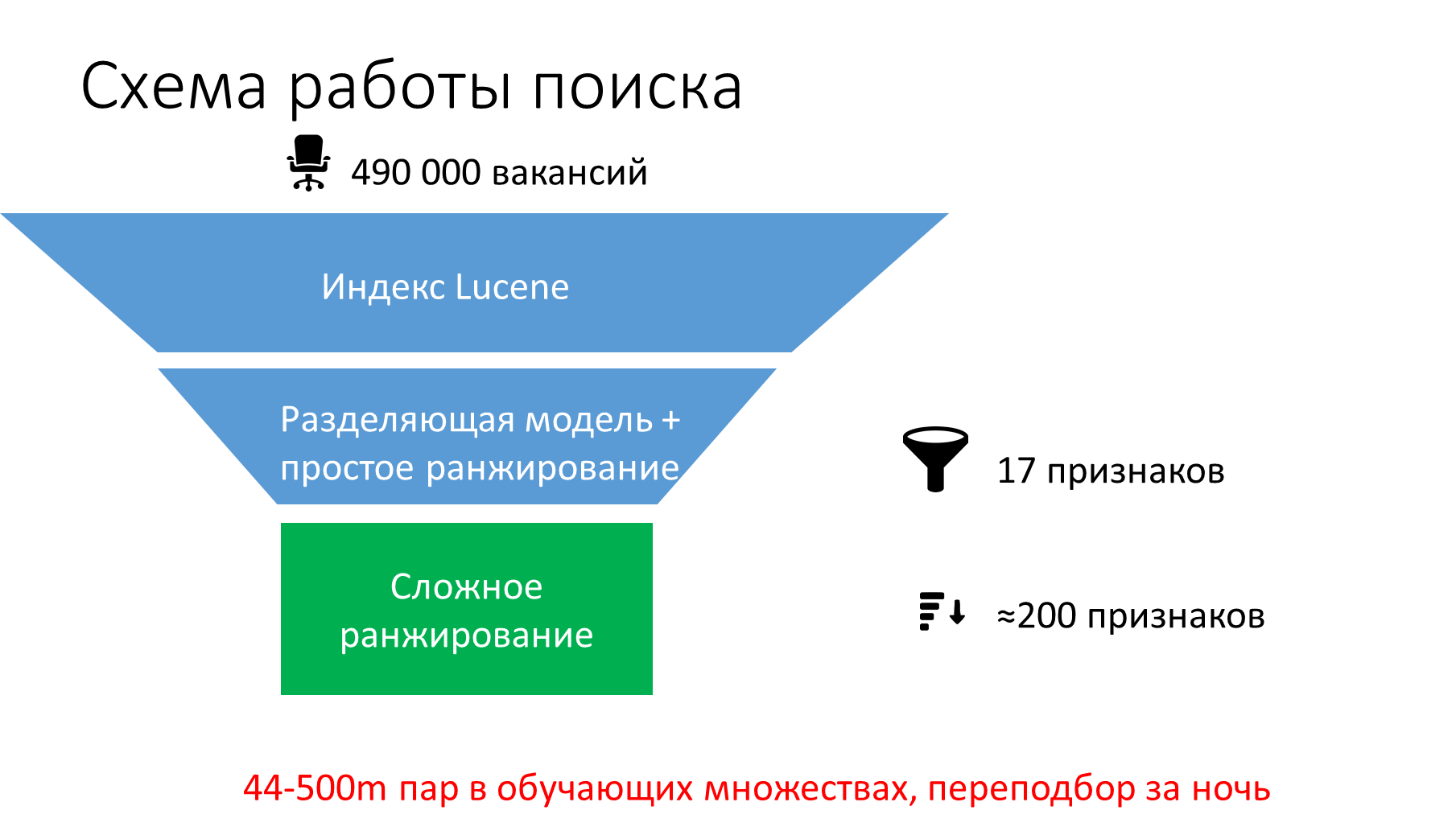
推奨システムからのサインを再利用しました:静的(クエリが実行される前に計算されます)、テキスト、数値、カテゴリ、動的、リクエストの処理時に考慮されます。 テキストの相互作用に関してテキストを比較する通常の標識に追加されました。
概略的に、機械学習の作業は次のように表すことができます。

推奨欠員を計算し、検索クエリを処理する場合、モデル(言語、ベクトル化、記号、目的関数、モデルの変更、より関連性の高いデータを使用したモデルの再トレーニング)を変更すると、緑と青の両方が実行されます。
モデルをトレーニングするときやリクエストを処理するときに多くの記号と計算コードが異なる場所に追加される必要があるため、これには長い時間がかかり、エラーにつながりました。 そのため、フレームワーク、機能グループを作成することにしました。 このフレームワークを初めて便利に作成することは便利ではありませんでした。プロジェクトの条件が少しでも増えました。
モデルの品質を測定し、ローカルメトリックndcgとマップを選択し、すべてのボリューム(@ 10、@ 20)について、ユーザーと時間ベースの検証にkfoldを使用しました。 実際、時間ベースの検証なしで、モデルの複雑さ(たとえば、ツリーの数)の増加がローカルメトリックの改善を示した場合、過剰適合が発生したことが彼に明らかになりました。これにより、合理的なハイパーパラメーターを選択できました。
最初に、個々の組み合わせ「要求-再開-空室」の応答確率を予測するための線形モデルを学習しようとしましたが、線形モデルが2つの空室の確率を比較する場合、a / bテストの結果が優れていることがわかりました。 この構成では、いくつかの実験ですでに統計的に有意な肯定的な結果が得られています。 しかし、まだ予想よりも少ない。
xgboostモデルのランキングを計算するために、適切な通常の空席、適切なClickMe広告の空席、およびプロダクションで考慮する必要があるアンサンブルからの木の数について、個別のしきい値を追加しました。 すべてのオプションをチェックするのに十分な時間がないことを理解したため、最も頻度の高いリクエストとその再編成を行い、それぞれの職業の典型的な履歴書を持つ応募者について、異なる設定で結果の品質をチェックし、空席をマークしました。
どの空室が彼らに適しているか、平均的な空室か、あまり空いていないかを明らかにするために、私は職業の詳細をかなり深く研究しなければなりませんでした。 残り時間はほとんどなかったため、大多数のユーザーは、マークアップ時に最適な設定を展開し、さらに5%のオプションを追加して、機械学習なしでコントロールのみを分割しました。
彼らが正当な理由でマークアウトしていることが判明しました。ほとんどのユーザーに含まれるオプションが本当に最高であることが証明されました!
新しいインターフェースと広告
通常、ユーザーはランキングの変更にあまり気づきません。目立つようにするには、インターフェースを変更する必要があります。 これらの変更では、ノベルティのマイナスの影響が強く現れます。それを打ち消すには、改善が非常に強くなければなりません。 たとえば、最初の画面をもっと便利にする必要があります。 新しいグラフィックデザインを作成しました。広告は、水平方向および垂直方向の右側を占めません。
広告は別の方法で処理できますが、HeadHunterにかなりの利益をもたらします。 この利益を他の広告ネットワークと分かち合うために、HeadHunterは独自のネットワークClickMeを作成しました。 含まれている広告は、空席と空席の広告に分けることができます。 新しいデザインでは、検索および紹介システムで使用されるものと同じテクノロジーとモデルを使用して、広告の最上位ブロックではなく、いくつかの適切な広告空席を表示し始めました。

実験を実行し、やっていることが悪影響を与えるかどうかを時間内に理解するために、非常に小さな部分で設計を変更しました。
結論として
スマート検索を開始した効果をまだ測定していますが、開始後最初の1週間で、応募者の検索セッションの成功が歴史的な最大値に達したことは明らかです。 このクラスのシステムを立ち上げるのは、少なくとも私の経験では、最も速くて静かなプロジェクトの1つでした。 主に最高のチームに感謝します。
残念ながら、検索エンジンを一度だけ作成することはできないため、絶えず変化しているものを完全に検索し、それ自体は完全に変更されません。 そのため、HeadHunterでの検索の改善を続け、ユーザーの利便性を高めています。 また、HeadHunterには、ML、検索技術、メトリックスおよびa / bテストを適用するのに役立つ多くの領域があります。
テクノロジー、機械学習を検索し、手で作業する方法を知っているなら、参加してください。 募集します。