年末年始は、居心地の良い家庭環境で美しく装飾され、心に大切な2k17ミームを思い出し、エレクトロニックアーツの良心のように永遠に残す素晴らしい機会です。
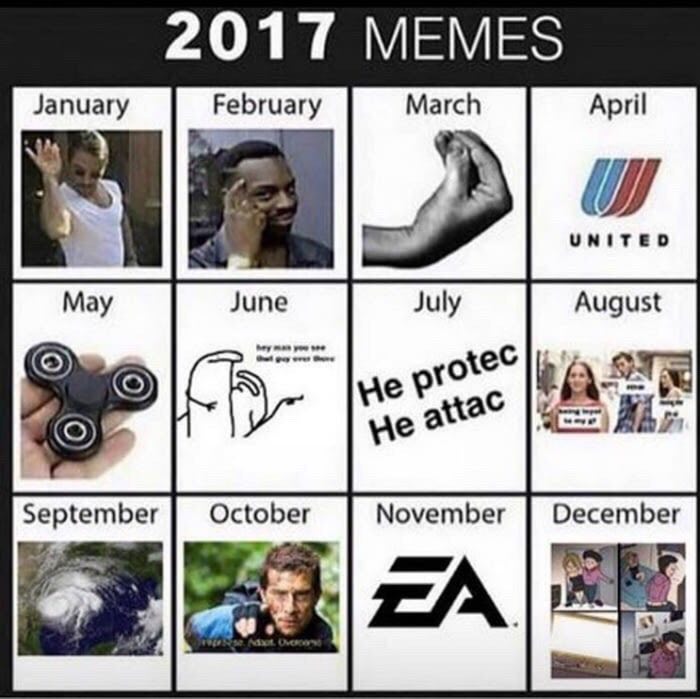
しかし、サラダで十分に味付けされた良心でさえ、目が覚め、自分自身をまとめて有益な活動に従事することを少なくとも少し要求しました。 したがって、ビジネスと喜びを組み合わせて、お気に入りのミームを例として使用して、小さなベースに自分を解析する方法を検討しました。
データ、すべての種類のロック、トラップ、および途中でサーバーによって設定された制限をバイパスします。 興味のある方はすべて猫に招待されます。
機械学習、計量経済学、統計、および他の多くのデータサイエンスがパターンを探しています。 勇敢なインクイジターアナリストは毎日、さまざまな方法で自然を拷問し、宇宙を作成したデータを生成するすばらしいプロセスがどのように機能するかについての情報を引き出します。 スペインの審問官は、日々の活動で被害者の肉体を直接使用していました。 しかし、自然は遍在し、明確な物理的外観を持ちません。 このため、現代の異端審問官の職業には奇妙な特徴があります。自然の拷問は、どこかから取らなければならないデータの分析を通して起こります。 通常、平和コレクターはデータを審問官に持ち込みます。 この記事は、データがどこから来て、どのようにそれを少し収集することができるかについての秘密のベールをわずかに開くように設計されています。
私たちのモットーは、キャプテンのジャック・スパロウの有名なフレーズでした:「すべてを手に入れ、何も与えない」。 時々、ミームを収集するためにかなりギャングの方法を使用する必要があります。 しかし、私たちは平和なデータ収集者のままであり、決してギャングになることはありません。 メインストレージからミームを取得します。

1.追Break式
1.1。 何を手に入れたいですか
したがって、 knowyourmeme.comを解析して 、さまざまな変数を取得します。
- 名前 -ミームの名前、
- Origin_year-作成年、
- ビュー - ビューの数
- About-ミームの説明文、
- 他の多くの
さらに、これをすべて行わずにこれを実行したい:
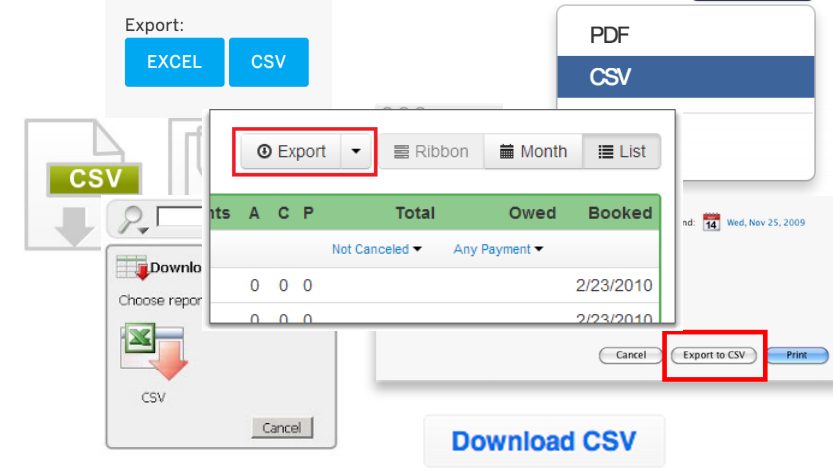
データをダウンロードしてゴミから消去した後、モデルの構築を開始できます。 たとえば、パラメータによってミームの人気を予測してみてください。 しかし、これはすべて後のものであり、ここでいくつかの定義に精通します。
- パーサーは、サイトから情報を奪うスクリプトです
- クローラーは、リンクをローミングするパーサーの一部です
- クローリングはページとリンクを介した移行です
- スクレイピングは、ページからのデータの収集です。
- 解析はすぐにクロールおよびスクレイピングです!
1.2。 HTMLとは何ですか?
HTML(HyperText Markup Language)は、MarkdownまたはLaTeXと同じマークアップ言語です。 さまざまなサイトを記述するための標準です。 この言語のコマンドはタグと呼ばれます 。 絶対に任意のサイトを開いた場合、マウスの右ボタンをクリックし、 View page source
]をクリックすると、このサイトのHTMLスケルトンが表示されます。
HTMLページは、ネストされたタグのセットにすぎないことがわかります。 たとえば、次のタグに気付くかもしれません。
-
<title>
-ページのタイトル -
<h1>…<h6>
-さまざまなレベルのヘッダー -
<p>
-段落(段落) -
<div>
-コンテンツの外観を変更するためのドキュメントフラグメントの選択 -
<table>
-<table>
描画 -
<tr>
-テーブル内の行の区切り文字 -
<td>
-テーブル内の列の区切り文字 -
<b>
-太字を設定します
通常、 <...>
コマンドはタグを開き、 </...>
はタグを閉じます。 これら2つのチームの間にあるすべてのものは、タグが指示する規則に従います。 たとえば、 <p>
と</p>
間にあるものはすべて独立した段落です。
タグは、 <html>
ルートを持つ一種のツリーを形成し、ページをさまざまな論理部分に分割します。 各タグには、独自の子孫(子)を含めることができます-埋め込まれているタグとその親。
たとえば、HTMLページツリーは次のようになります。
<html> <head> </head> <body> <div> </div> <div> <b> , </b> </div> </body> </html>

テキストと同様にこのhtmlを使用することも、ツリーを使用することもできます。 このツリーをバイパスすると、Webページが解析されます。 この多様性の中から必要なノードだけを見つけて、そこから情報を取得します!
これらのツリーを手動でトラバースすることはあまり良くないので、ツリーをトラバースするための特別な言語があります。
- CSSセレクター (これは、キーと値のペアでページ要素を探すときです)
- XPath (これは、次のようにツリーに沿ってパスを記述するときです:/ html / body / div [1] / div [3] / div / div [2] / div)
- たとえば、BeautifulSoup for pythonなど、あらゆる種類の異なる言語に対応するあらゆる種類のライブラリ。 使用するのはこのライブラリです。
1.3。 最初のリクエスト
Webページにアクセスすると、 requests
モジュールを受信できます。 アップロードしてください。 会社向けに、より効率的なパッケージをいくつかアップロードします。
import requests # import numpy as np # , import pandas as pd # import time # -
高貴な研究目的のために、対応するページから各ミームのデータを収集する必要があります。 ただし、最初にこれらのページのアドレスを取得する必要があります。 したがって、すべてのミームがレイアウトされたメインページを開きます。 次のようになります。

ここから、リストされた各ミームにリンクをドラッグします。 メインページのアドレスを変数page_link
し、 requests
ライブラリを使用して開きます。
page_link = 'http://knowyourmeme.com/memes/all/page/1' response = requests.get(page_link) response
Out: <Response [403]>
そして、これが最初の問題です! に向ける  また、サーバーが利用可能でリクエストを処理できる場合、403rdエラーがサーバーによって発行されますが、個人的な理由でこれを拒否しています。
また、サーバーが利用可能でリクエストを処理できる場合、403rdエラーがサーバーによって発行されますが、個人的な理由でこれを拒否しています。
理由を調べてみましょう。 これを行うために、サーバーに送信された最終リクエストがどのように見えたか、より具体的には、サーバーの目にはユーザーエージェントがどのように見えたかを確認します。
for key, value in response.request.headers.items(): print(key+": "+value)
Out: User-Agent: python-requests/2.14.2 Accept-Encoding: gzip, deflate Accept: */* Connection: keep-alive
python上に座っており、バージョン2.14.2で要求ライブラリを使用していることをサーバーに明らかにしたようです。 おそらく、これがサーバーに私たちの善意に関するいくつかの疑念を引き起こし、彼は容赦なく私たちを拒否することにしました。 比較のために、健康な人のリクエストヘッダーがどのように見えるかを確認できます。

当然のことながら、控えめなリクエストは、通常のブラウザからのリクエスト中に送信されるこのような豊富なメタ情報と競合しません。 幸いなことに、だれも私たちが人間のふりをして、偽のユーザーエージェントの生成を使用してサーバーの目にちりを投げることを気にしません。 このタスクに対処するライブラリはたくさんありますが、個人的にはfake-useragent
一番好きです。 さまざまな部分からメソッドを呼び出すと、オペレーティングシステム、仕様、ブラウザバージョンのランダムな組み合わせが生成され、リクエストに渡すことができます。
# from fake_useragent import UserAgent UserAgent().chrome
Out: 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36'
生成されたエージェントを使用して、リクエストを再度実行してみましょう
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome}) response
Out: <Response [200]>
素晴らしい、私たちの小さな変装  それは機能し、ceivされたサーバーは祝福された200応答を忠実に発行しました-接続が確立され、データが受信され、すべてが素晴らしいです! 結局のところ、何を得たのか見てみましょう。
それは機能し、ceivされたサーバーは祝福された200応答を忠実に発行しました-接続が確立され、データが受信され、すべてが素晴らしいです! 結局のところ、何を得たのか見てみましょう。
html = response.content html[:1000]
Out: b'<!DOCTYPE html>\n<html xmlns:fb=\'http://www.facebook.com/2008/fbml\' xmlns=\'http://www.w3.org/1999/xhtml\'>\n<head>\n<meta content=\'text/html; charset=utf-8\' http-equiv=\'Content-Type\'>\n<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHlcJWg==","queueTime":0,"applicationTime":59,"agent":""}</script>\n<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,t,n){function r(n){if(!t[n]){var o=t[n]={exports:{}};e[n][0].call(o.exports,function(t){var o=e[n][1][t];return r(o||t)},o,o.exports)}return t[n].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<n.length;o++)r(n[o]);return r}({1:[function(e,t,n){function r(){}function o(e,t,n){return function(){return i(e,[f.now()].concat(u(arguments)),t?null:this,n),t?void 0:this}}var i=e("handle"),a=e(2),u=e(3),c=e("ee").get("tracer")'
消化できないように見えますが、このケースからもっときれいなものを溶接するのはどうですか? たとえば、素晴らしいスープ。
1.4。 素晴らしいスープ

bs4パッケージ、別名BeautifulSoup (その人の親友-ドキュメントへのハイパーリンクがあります)は、不思議の国のアリスの美しいスープに関する詩にちなんで命名されました。
Wonderful Soupは、ページの生の未処理のHTMLコードから、Webページの必要なタグ、クラス、属性、テキスト、およびその他の要素を検索するのに非常に便利な構造化されたデータ配列を提供する完全に魔法のライブラリです。
BeautifulSoup
と呼ばれるパッケージは、おそらく私たちが必要とするものではありません。 これは3番目のバージョン( Beautiful Soup 3 )であり、4番目を使用します。beautifulsoup4
パッケージをインストールする必要があります。 完全に楽しいものにするためには、インポートする際に別のパッケージ名bs4
を指定し、BeautifulSoup
という関数をインポートする必要があります。 一般に、最初は混乱しやすいですが、これらの困難を克服する必要があります。
このパッケージは、ページの生のXMLコードでも機能します(XMLはワープされ、コマンドであるHTMLを使用して方言に変換されます)。 パッケージがXMLマークアップで正しく機能するためには、武器庫全体に加えてxml
パッケージをインストールする必要があります。
from bs4 import BeautifulSoup
BeautifulSoup
関数に、最近受け取ったWebページのテキストを渡します。
soup = BeautifulSoup(html,'html.parser') # lxml, #
次のようなものが得られます。
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml"> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHkUNWUU=","queueTime":0,"applicationTime":24,"agent":""}</script> <script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,n,t){function r(t){if(!n[t]){var o=n[t]={exports:{}};e[t][0].call(o.exports,function(n){var o=e[t][1][n];return r(o||n)},o,o.exports)}return n[t].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<t.length;o++)r(t[o]);return r}({1:[function(e,n,t){function r(){}function o(e,n,t){return function(){return i(e,[c.now()].concat(u(arguments)),n?null:this,t),n?void 0:this}}var i=e("handle"),a=e(2),u=e(3),f=e("ee").get("tracer"),c=e("loader"),s=NREUM;"undefined"==typeof window.newrelic&&(newrelic=s);var p=
ずっと良くなりましたよね? soup
変数には何がありますか? 不注意なユーザーは、ほとんど何も変わっていないと言うでしょう。 しかし、これはそうではありません。 これで、ページのHTMLツリーを自由にローミングし、子供、親を探してそれらを取り出すことができます!
たとえば、タグからのパスを指定して、ピークを移動できます。
soup.html.head.title
Out: <title>All Entries | Know Your Meme</title>
text
メソッドを使用して、さまよう場所からテキストを取得できtext
。
soup.html.head.title.text
Out: 'All Entries | Know Your Meme'
さらに、要素のアドレスがわかれば、すぐに見つけることができます。 たとえば、クラスでこれを行うことができます。 次のコマンドは、タグ内にあり、クラスのphoto
を持つ要素を見つけることです。
obj = soup.find('a', attrs = {'class':'photo'}) obj
Out: <a class="photo left" href="/memes/nu-male-smile" target="_self"><img alt='The "Nu-Male Smile" Is Duck Face for Men' data-src="http://i0.kym-cdn.com/featured_items/icons/wide/000/007/585/7a2.jpg" height="112" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title='The "Nu-Male Smile" Is Duck Face for Men' width="198"/> <div class="info abs"> <div class="c"> The "Nu-Male Smile" Is Duck Face for Men </div> </div> </a>
しかし、私たちの予想に反して、引き出されたオブジェクトには"photo left"
クラスがあります。 BeautifulSoup4
はclass
属性を個別の値のセットと見なすため、ライブラリの"photo left"
は["photo", "left"]
に相当し["photo", "left"]
指定したこのクラス"photo"
値はこのリストに含まれます。 このような不快な状況を避け、不要なリンクをクリックするには、独自の機能を使用して完全一致を設定する必要があります。
obj = soup.find(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) obj
Out: <a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>
検索後に取得されたオブジェクトもbs4構造を持っています。 したがって、すでに必要なオブジェクトを引き続き検索できます! このミームへのリンクを取得します。 これは、リンクが含まれているhref
属性によって実行できます。
obj.attrs['href']
Out: '/memes/people/mf-doom'
これらすべてのクレイジーな変換の後、データ型が変更されていることに注意してください。 今、彼らはstr
です。 これは、テキストのようにそれらを操作し、正規表現を使用して不要な情報を除外できることを意味します。
print(" :", type(obj)) print(" :", type(obj.attrs['href']))
Out: : <class 'bs4.element.Tag'> : <class 'str'>
ページ上の複数の要素に指定されたアドレスがある場合、 find
メソッドは最初の要素のみを返します。 このアドレスを持つすべての要素を検索するには、 findAll
メソッドを使用する必要があります。リストがfindAll
ます。 したがって、ミームのあるページへのリンクを含むすべてのオブジェクトを一度の検索で取得できます。
meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) meme_links[:3]
Out: [<a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>, <a class="photo" href="/memes/here-lies-beavis-he-never-scored"><img alt="Here Lies Beavis. He Never Scored." data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/148/maxresdefault.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="Here Lies Beavis. He Never Scored."/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> </div> </a>, <a class="photo" href="/memes/people/vanossgaming"><img alt="VanossGaming" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/147/Evan-Fong-e1501621844732.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="VanossGaming"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>]
ゴミからリストをクリアすることは残っています:
meme_links = [link.attrs['href'] for link in meme_links] meme_links[:10]
Out: ['/memes/people/mf-doom', '/memes/here-lies-beavis-he-never-scored', '/memes/people/vanossgaming', '/memes/stream-sniping', '/memes/kids-describe-god-to-an-illustrator', '/memes/bad-teacher', '/memes/people/adam-the-creator', '/memes/but-can-you-do-this', '/memes/people/ken-ashcorp', '/memes/heartbroken-cowboy']
完了しました。1つの検索ページで、ミームの数で正確に16個のリンクを取得しました。
もちろん、その住所でアイテムを検索できるというのは素晴らしいことですが、この住所はどこで入手できますか? セレクターガジェットなど、ページから必要なタグをプルできるブラウザーに何らかの種類のユーティリティをインストールできます。
ただし、このパスは真のサムライには適していません。 Bushidoのフォロワーには、別の方法があります。必要な各要素のタグを手動で検索します。 これを行うには、ブラウザウィンドウを右クリックして、[ 検査 ]ボタンを押す必要があります。 これらすべての操作の後、ブラウザは次のようになります。

選択したオブジェクトのアドレスを含むポップアップHTMLピースは、コードに簡単にコピーして、残虐行為を楽しむことができます。
最後の瞬間が残っています。 現在のページからすべてのミームをダウンロードしたら、どういうわけか次のページに移動する必要があります。 サイトでは、ミームを使用してページを下にスクロールするだけでこれを行うことができます。javascript関数は新しいミームを現在のウィンドウに表示しますが、これらの機能には触れないようにします。
通常、検索用にサイトに設定したすべてのパラメーターは、hrefの構造に表示されます。 ミームも例外ではありません。 ミームの最初の部分を取得する場合は、リンクでサイトを参照する必要があります
http://knowyourmeme.com/memes/all/page/1
16個のミームで2番目の位置を取得する場合、リンクをわずかに変更する必要があります。つまり、ページ番号を2に置き換えます。
http://knowyourmeme.com/memes/all/page/2
このような簡単な方法で、すべてのページを閲覧してメモリアルを奪うことができます。 最後に、上記のすべての操作を含む美しい関数をラップします。
def getPageLinks(page_number): """ , page_number: int/string """ # page_link = 'http://knowyourmeme.com/memes/all/page/{}'.format(page_number) # response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome}) if not response.ok: # , return [] # html = response.content soup = BeautifulSoup(html,'html.parser') # , meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) meme_links = ['http://knowyourmeme.com' + link.attrs['href'] for link in meme_links] return meme_links
機能をテストし、すべてが正常であることを確認します
meme_links = getPageLinks(1) meme_links[:2]
Out: ['http://knowyourmeme.com/memes/people/mf-doom', 'http://knowyourmeme.com/memes/here-lies-beavis-he-never-scored']
さて、この関数は機能し、理論的には17171のすべてのミームへのリンクを取得できます。そのためには17171/16〜1074ページを通過する必要があります。 非常に多くのリクエストでサーバーを混乱させる前に、特定のミームに関するすべての必要な情報を取得する方法を見てみましょう。
1.5強盗の最終準備
リンクとの類推により、何でも引き出すことができます。 これを行うには、いくつかの手順を実行する必要があります。
- ミームでページを開く
- 必要な情報のタグを探します
- すべてを美しいスープに入れます
- ......
- 利益
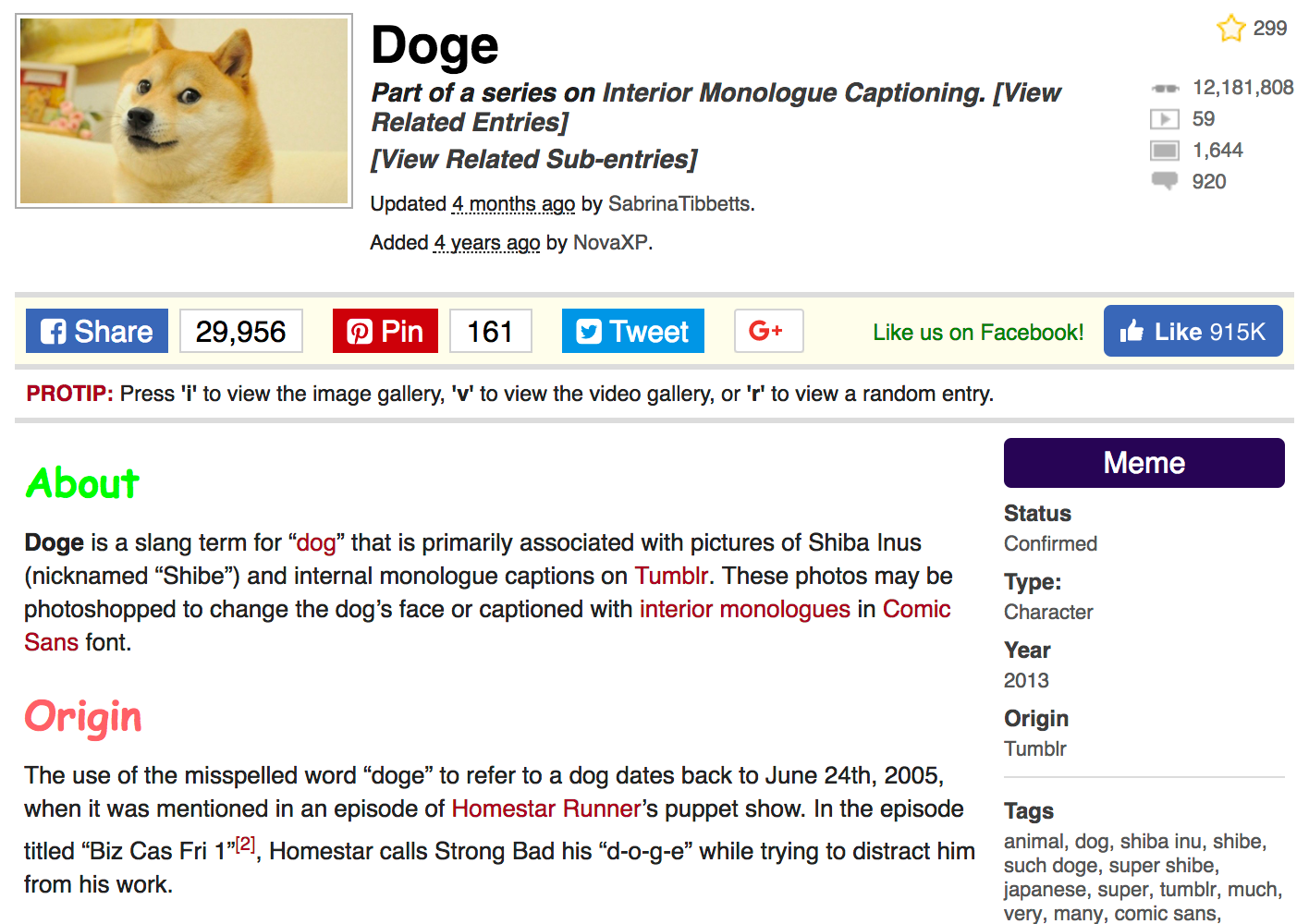
好奇心reader盛な読者の頭の中で情報を統合するには、ミームのビューの数を引き出します。
そして、例として、このサイトで最も人気のあるミーム、Dogeを取り上げましょう。Dogeは、2018年1月1日時点で1,200万回を超えています。
私たちの研究の心にとって大切な情報を得るページ自体は、次のようになります。
前と同じように、最初に、ページへのリンクを変数に保存し、そのコンテンツを引き出します。
meme_page = 'http://knowyourmeme.com/memes/doge' response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome}) html = response.content soup = BeautifulSoup(html,'html.parser')
ミームに関連するダウンロードされたビデオや写真の数だけでなく、ビュー、コメントの統計を取得する方法を見てみましょう。 これらはすべて、右上のタグ"dd"
下に、クラス"views"
、 "videos"
、 "photos"
、および"comments"
とともに保存され"comments"
views = soup.find('dd', attrs={'class':'views'}) print(views)
Out: <dd class="views" title="12,318,185 Views"> <a href="/memes/doge" rel="nofollow">12,318,185</a> </dd>
タグと句読点をクリアする
views = views.find('a').text views = int(views.replace(',', '')) print(views)
Out: 12318185
繰り返しますが、すべてを小さな関数に詰め込みます。
def getStats(soup, stats): """ //... soup: bs4.BeautifulSoup stats: string views/videos/photos/comments """ obj = soup.find('dd', attrs={'class':stats}) obj = obj.find('a').text obj = int(obj.replace(',', '')) return obj
すべて準備完了です!
views = getStats(soup, stats='views') videos = getStats(soup, stats='videos') photos = getStats(soup, stats='photos') comments = getStats(soup, stats='comments') print(": {}\n: {}\n: {}\n: {}".format(views, videos, photos, comments))
Out: : 12318185 : 59 : 1645 : 918
別の興味深い研究-ミームを追加した日付と時刻を取得します。 ブラウザでページを見ると、引き出すことができる最大の情報は、発行からAdded 4 years ago by NovaXP
れてから経過した年数であると考えるでしょう。 ただし、あきらめることはあまりありません。htmlの根底に登り、この碑文の原因となっている部分を掘り下げます。
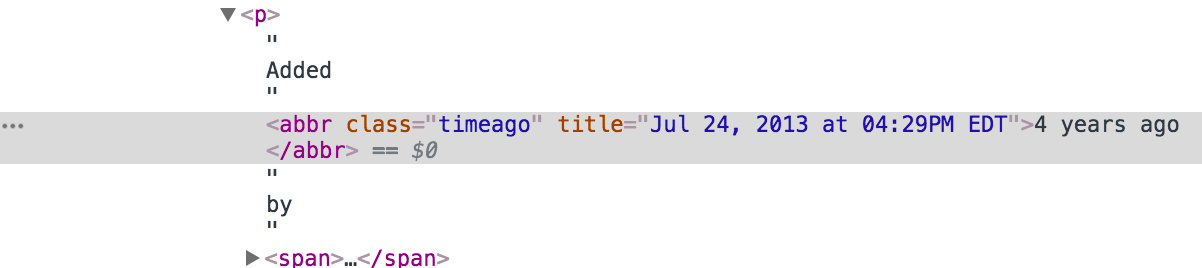
うん! 追加日に関する詳細は、分単位で正確です。 小学生

date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title'] date
Out: '2017-12-31T01:59:14-05:00'
実際、パーサーは予測不能です。 多くの場合、解析するページは非常に異種の構造を持っています。 たとえば、ミームを解析している場合、説明はページの一部に表示される場合がありますが、一部には表示されない場合があります。 コードが最初に説明の欠如に遭遇するとすぐに、エラーをスローして停止します。 すべてのデータを適切に収集するには、例外を登録する必要があります。 ミームストアには設備が整っており、緊急事態は発生しないはずです。
それにもかかわらず、私は本当に朝起きて、コードが20回繰り返され、エラーにぶつかり、切り落とされたのを見たくありません。 これを防ぐには、たとえば、 try - except
コンストラクトを使用し、 try - except
エラーを単純に処理します。 インターネットで例外について読むことができます。 この場合、間違いを犯すことはできませんが、ページに必要な要素があるかどうかを事前にチェックし、通常のif - else
を使用せずに、解析を試みます。
たとえば、ミームのステータスを引き出したいので、これを取り巻くタグを見つけます。
properties = soup.find('aside', attrs={'class':'left'}) meme_status = properties.find("dd") meme_status
Out: <dd> Confirmed </dd>
次に、タグからテキストを抽出し、余分なスペースをすべて切り取る必要があります。
meme_status.text.strip()
Out: 'Confirmed'
ただし、ミームにステータスがないことが突然判明した場合、 find
メソッドはvoidを返します。 一方、 text
メソッドはタグ内のテキストを見つけることができず、エラーをスローします。 このようなボイドから身を守るために、例外を登録するかif - else
登録できif - else
。 現在のミームはまだステータスを持っているため、意図的に空のオブジェクトとして設定し、両方のケースでエラーがキャッチされることを確認します
# ! , meme_status = None # ! ... # ... try: print(meme_status.text.strip()) # , , . except: print("Exception") # ... if meme_status: print(meme_status.text.strip()) else: print("Empty")
Out: Exception Empty
このコードにより、エラーから身を守ることができます。 この場合、 if - else
を1つの便利な文字列として使用して、構造全体を書き換えることができます。 この行は、 meme_status
かどうかを確認し、 meme_status
ない場合は無効になります。
# properties = soup.find('aside', attrs={'class':'left'}) meme_status = properties.find("dd") meme_status = "" if not meme_status else meme_status.text.strip() print(meme_status)
Out: Confirmed
類推により、ページから残りの情報を引き出すことができます。そのために、再び関数を書きます。
def getProperties(soup): """ (tuple) , , , soup: bs4.BeautifulSoup """ # - h1, meme_name = soup.find('section', attrs={'class':'info'}).find('h1').text.strip() # properties = soup.find('aside', attrs={'class':'left'}) # - meme_status = properties.find("dd") # oneliner, try-except: properties, NoneType, # text , meme_status = "" if not meme_status else meme_status.text.strip() # - meme_type = properties.find('a', attrs={'class':'entry-type-link'}) meme_type = "" if not meme_type else meme_type.text # Year, # , - meme_origin_year = properties.find(text='\nYear\n') meme_origin_year = "" if not meme_origin_year else meme_origin_year.parent.find_next() meme_origin_year = meme_origin_year.text.strip() # meme_origin_place = properties.find('dd', attrs={'class':'entry_origin_link'}) meme_origin_place = "" if not meme_origin_place else meme_origin_place.text.strip() # , meme_tags = properties.find('dl', attrs={'id':'entry_tags'}).find('dd') meme_tags = "" if not meme_tags else meme_tags.text.strip() return meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags
getProperties(soup)
Out: ('Doge', 'Confirmed', 'Animal', '2013', 'Tumblr', 'animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme, hacked, bitcoin, dogecoin, shitposting, stare, canine')
ミームプロパティがコンパイルされます。 今、そのテキストの説明を類推して収集します。
def getText(soup): """ soup: bs4.BeautifulSoup """ # body = soup.find('section', attrs={'class':'bodycopy'}) # about ( ), , meme_about = body.find('p') meme_about = "" if not meme_about else meme_about.text # origin Origin History, # , - meme_origin = body.find(text='Origin') or body.find(text='History') meme_origin = "" if not meme_origin else meme_origin.parent.find_next().text # ( ) if body.text: other_text = body.text.strip().split('\n')[4:] other_text = " ".join(other_text).strip() else: other_text = "" return meme_about, meme_origin, other_text
meme_about, meme_origin, other_text = getText(soup) print(" :\n{}\n\n:\n{}\n\n :\n{}...\n"\ .format(meme_about, meme_origin, other_text[:200]))
Out: : Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr. These photos may be photoshopped to change the dog's face or captioned with interior monologues in Comic Sans font. : The use of the misspelled word “doge” to refer to a dog dates back to June 24th, 2005, when it was mentioned in an episode of Homestar Runner's puppet show. In the episode titled “Biz Cas Fri 1”[2], Homestar calls Strong Bad his “doge” while trying to distract him from his work. : Identity On February 23rd, 2010, Japanese kindergarten teacher Atsuko Sato posted several photos of her rescue-adopted Shiba Inu dog Kabosu to her personal blog.[38] Among the photos included a peculi...
, ,
def getMemeData(meme_page): """ , meme_page: string """ # response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome}) if not response.ok: # , return response.status_code # html = response.content soup = BeautifulSoup(html,'html.parser') # views = getStats(soup=soup, stats='views') videos = getStats(soup=soup, stats='videos') photos = getStats(soup=soup, stats='photos') comments = getStats(soup=soup, stats='comments') # date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title'] # , , .. meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags =\ getProperties(soup=soup) # meme_about, meme_origin, other_text = getText(soup=soup) # , data_row = {"name":meme_name, "status":meme_status, "type":meme_type, "origin_year":meme_origin_year, "origin_place":meme_origin_place, "date_added":date, "views":views, "videos":videos, "photos":photos, "comments":comments, "tags":meme_tags, "about":meme_about, "origin":meme_origin, "other_text":other_text} return data_row
, ,
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) data_row = getMemeData('http://knowyourmeme.com/memes/doge') final_df = final_df.append(data_row, ignore_index=True) final_df
Out:
| お名前 | 状態 | type | origin_year | ... |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | ... |
. — , meme_links
.
for meme_link in meme_links: data_row = getMemeData(meme_link) final_df = final_df.append(data_row, ignore_index=True)
Out:
| お名前 | 状態 | type | origin_year | ... |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | ... |
| Charles C. Johnson | Submission | Activist | 2013 | ... |
| Bat- (Prefix) | Submission | Snowclone | 2018 | ... |
| The Eric Andre Show | Deadpool | TV Show | 2012 | ... |
| Hopsin | Submission | Musician | 2003 | ... |
いいね! , , , — , , .
2.
2.1
彼がいる! , , , , — . , . . try-except
. .
# . # tqdm_notebook from tqdm import tqdm_notebook final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) for page_number in tqdm_notebook(range(1075), desc='Pages'): # meme_links = getPageLinks(page_number) for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False): # for i in range(5): try: # data_row = getMemeData(meme_link) # final_df = final_df.append(data_row, ignore_index=True) # - break except: # , , print('AHTUNG! parsing once again:', meme_link) continue
! - - , , .

, , , . .
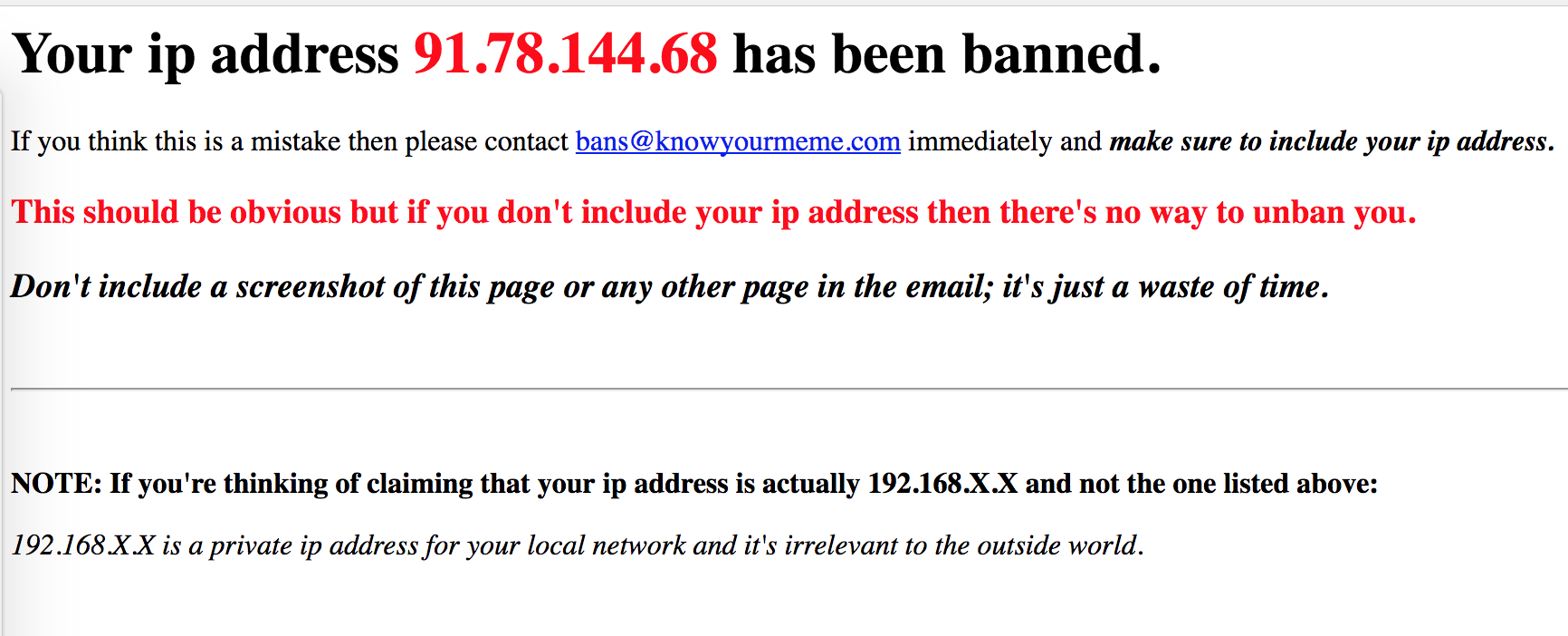
2.2 —
, . , .
. , , , request-header
. , IP, , IP . , -, IP , "". : — - , — ?
Tor . , Tor , . , , , , , . , Tor, , . :
, , , Tor . ip-. get- , IP
def checkIP(): ip = requests.get('http://checkip.dyndns.org').content soup = BeautifulSoup(ip, 'html.parser') print(soup.find('body').text) checkIP()
Out: Current IP Address: 82.198.191.130
ip Tor . — , — .
tor , . tor .
- Linux —
apt-get install tor
, - Mac — brew ,
brew install tor
. - Windows — .
2.3
. ip PySocks
. , , pip3 install PySocks
.
9150. socks socket . , – - .
import socks import socket socks.set_default_proxy(socks.SOCKS5, "localhost", 9150) socket.socket = socks.socksocket
ip-a.
checkIP()
Out: Current IP Address: 51.15.92.24
… !

ip-.
data_row = getMemeData('http://knowyourmeme.com/memes/doge') for key, value in data_row.items(): print(key.capitalize()+":", str(value)[:200], end='\n\n')
Out: Name: Doge Status: Confirmed Type: Animal Origin_year: 2013 Origin_place: Tumblr Date_added: 2017-12-31T01:59:14-05:00 Views: 12318185 Videos: 59 Photos: 1645 Comments: 918 Tags: animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme About: Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr...
. . . .
, : , - ip 10 . , ? , , Tor torrc ( ~/Library/Application Support/TorBrowser-Data/torrc
, — ) . :
CircuitBuildTimeout 10 LearnCircuitBuildTimeout 0 MaxCircuitDirtiness 10
ip 10 . .
for i in range(10): checkIP() time.sleep(5)
Out: Current IP Address: 89.31.57.5 Current IP Address: 93.174.93.71 Current IP Address: 62.210.207.52 Current IP Address: 209.141.43.42 Current IP Address: 209.141.43.42 Current IP Address: 162.247.72.216 Current IP Address: 185.220.101.17 Current IP Address: 193.171.202.150 Current IP Address: 128.31.0.13 Current IP Address: 185.163.1.11
, ip 10 . . 20 .
- ;
- ;
- .....
- 利益
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) for page_number in tqdm_notebook(range(1075), desc='Pages'): # meme_links = getPageLinks(page_number) for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False): # for i in range(5): try: # data_row = getMemeData(meme_link) # final_df = final_df.append(data_row, ignore_index=True) # - break except: # , , continue final_df.to_csv('MEMES.csv')
. . . : , ip ?
2.4
ip . Github - TorCrawler.py
. , , . . . , .
, torrc . /usr/local/etc/tor/
, /etc/tor/
. .
-
tor --hash-password mypassword
- torrc vim , nano atom
- torrc- , HashedControlPassword
- , HashedControlPassword
- ( ) ControlPort 9051
- .
tor . : service tor start
, : tor
.
.
from TorCrawler import TorCrawler # , crawler = TorCrawler(ctrl_pass='mypassword')
get- , bs4.
meme_page = 'http://knowyourmeme.com/memes/doge' response = crawler.get(meme_page, headers={'User-Agent': UserAgent().chrome}) type(response)
Out: bs4.BeautifulSoup
- .
views = response.find('dd', attrs={'class':'views'}) views
Out: <dd class="views" title="12,318,185 Views"> <a href="/memes/doge" rel="nofollow">12,318,185</a> </dd>
IP
crawler.ip
Out: '51.15.40.23'
ip 25 . n_requests
. , .
crawler.n_requests
Out: 25
, ip .
crawler.rotate()
IP successfully rotated. New IP: 62.176.4.1
, , IP . .
. .
おわりに
, . — , , , , - , , , . , , , , , DDoS-. , , — , — .
— - , . time.sleep()
request-header
— .
!
: filfonul , Skolopendriy