すべてがいつものように、リンギングが聞こえますが、それがどこにあるかはわかりません
ネットワークでは、最新のプロセッサのハードウェアにある2つの脆弱性に関する情報がさらに流出していました。 実際、この脆弱性は公開ディスカッションだけで公開されていましたが、その悪用のためにSpecterおよびMeltdownという名前で2つの方法が発見されました。
専門家にとって、この機器の問題は長い間知られており、「静かに」操作され、誰もが幸せでした...
何らかの未知の理由で、それについて大騒ぎすることが決定され、アマチュアのように、公式のプレスリリース( specter.pdfおよびmeltdown.pdf )を発行した人々は、それがすべてどのように機能し、問題がどこにあるのか、 ほとんど分かりませんでした。
そして、ソース情報プロバイダーは問題を詳細に説明することを気にしませんでした、明らかに彼らはアマチュアのために働くエクスプロイトと簡単な説明を引き渡しました...
自家製のコメンテーターとアセンブラーの専門家は、すべてがどのように機能するかをスマートに説明し始めました。
たくさんのコメントがある記事の例を次に示します。 これは特に感動的です:

「素朴なチュクチの男」は、なぜ1000時間シフトしたのか、実際にそれがどのように機能するのかを理解していません。
説明しなければなりません。
ハードウェアの脆弱性の実際の場所
脆弱性はここにあり、赤い丸で強調表示されています。
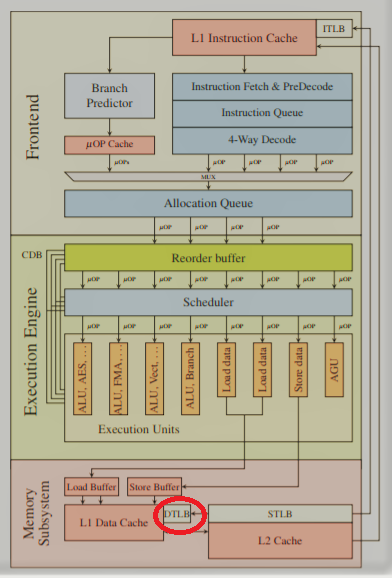
問題は、RAMのページングアドレッシングで使用されるTLBブロックにあります。 これは、アプリケーションが使用する仮想物理アドレス値のペアをRAMに保存する連想バッファです。 これはデータキャッシュではありません....
Intelのドキュメントでの説明は次のとおりです。

TLBブロックは、メモリアドレスを変換する手順を排除することでOPにアクセスする時間を短縮するために必要です。 このような変換は、ページ全体に対して1回だけ実行されます(最新のOSの場合、サイズはわずか4K)。 このページの他のすべてのプログラムメモリアクセスは、このバッファに格納された値を使用して、すでに強制的に発生しています。 これらのブロックはすべての最新のプロセッサに存在するため、それらすべてが現在SpecterおよびMeltdownと呼ばれる脆弱性の影響を受けやすくなっています。
ところで、コマンドの投機的実行がこれらの脆弱性を悪用する唯一の方法ではないので、OPからフォワードデータロードメカニズムを使用できます。
TLBには、通常のキャッシュのようなソフトウェア(ファームウェア)制御はありません。 レコードを削除したり、レコードを強制/変更することはできません。
これはハードウェアの脆弱性が存在する場所であり、アドレスのすべての翻訳された翻訳はこの連想バッファに格納されます。
したがって、実行された投機的操作では、TLBブロック内にトレースがレコードとして残されます。このレコードを見つけて識別するだけで済みます。 そして、これはすでに「技術の問題」であり、その技術は長い間知られており、応用されており、「一時的な呼び出しの方法による機器の状態の調査」と呼ばれています。 インターネット上でこの名前を探してはいけません。この方法は完全に非公開の専門家の非常に狭いサークルで知られていました。
そして今、誰もが彼を知っています...
TLBブロックに対するプログラムによる影響の唯一の可能性は、そのすべての値を完全にリセットすることです(ここでは、理解を容易にするためだけに少し不誠実です)。 ソフトウェアベンダーが提案するすべてのSpectreおよびMeltdownの脆弱性パッチは、GP例外ハンドラーのCR3レジスタをリロードすることでこれを行います。
TLBをリセットした後、プロセッサは仮想メモリの使用済みページをすべて再変換する必要があるため、システムのパフォーマンスが低下します。
それが実際にどのように悪用されるか
まず、プログラムに2メガバイトのバッファーを作成する必要があります。攻撃の前にこのバッファーに書き込み/読み取りを行うことはできません。4Kブロックの境界に配置する必要があります。 このサイズは基本的なものであり、バッファーは正確に256個の4Kページ(ページングアドレッシングの仕様)に対応する必要があります。
次に、次のようなコマンド:

コマンドMov alの後のプログラムでは、[OS kernel address]; 割り込みが発生し、レジスタalの値は変化しません(ゼロのままです)。
ただし、TLBバッファーでは、操作を実行するための転送要求のため、計算された仮想アドレスと物理アドレス[ebx + eax]の対応関係が記憶されます。
通常のキャッシュ、TLBブロックで行われているように、この特定のエントリを破棄することは不可能であり、残ります...
したがって、TLBブロックに格納されている2Mバッファーで4Kページのアドレスを見つけた場合、OSカーネルからalレジスタに読み込まれた値も学習します。
これはすでに技術的な問題であり、TLBブロックを「リング」します。 これを行うには、すべての4Kページを1回読み取る必要があります。正確には256個あり、256個の読み取り操作を実行します(4Kブロックごとに1つ)。 この場合、読み取り操作の時間を測定します。 残りのページよりも速く読み取られるページ。OSカーネルから読み取られたバイト値に対応する2Mバッファーに番号があります。
これは、仮想アドレスと物理アドレスの対応がこのページのTLBバッファーで既に計算されており、他のすべてのページではこの操作がまだ実行されていないために発生します。
「リンギング」では、もちろん、すべてがそれほど単純ではなく、多くのニュアンスがありますが、それはかなり可能です。
彼らがやった、私たちは知っている...
それだけです。