
顧客の解約を予測する問題は、データサイエンスの実践において最も一般的なものの1つです(現在、統計や機械学習をビジネスの問題に適用することを誰もが知っていますか?)。 問題は非常に普遍的です。通信、銀行、ゲーム、ストリーミングサービス、小売など、多くの業界に関連しています。それを解決する必要性は、経済的な観点から実証するのは非常に簡単です。ビジネスマガジンには、新しいクライアントを引き付ける方法に関する多くの記事があります古いものを保持するよりもN倍高価です。 また、基本的な設定は理解しやすいため、機械学習の基本はその例でよく説明されています。
Plarium-Southの私たちにとって、他のゲーム会社と同様に、この問題も関連しています。 私たちは、さまざまな設定やモデルを長い道のりを経て、かなり独創的なソリューションに到達しました。 すべてが見た目と同じくらい簡単で、流出を正しく判断する方法と、ここでニューラルネットワークがなぜ必要なのか、カットの下で説明します。
流出? いいえ、聞いていません...
予想どおり、定義から始めます。 いくつかのサービスを使用し、商品を購入し、この場合はゲームをプレイする顧客のデータベースがあります。 ある時点で、個々の顧客はサービスの使用をやめて、去ります。 これが流出です。 クライアントが出発の最初の兆候を示した時点で、彼はまだ確信できると仮定されます。抱擁し、彼がどれほど重要であるかを伝え、割引を提供し、贈り物をします。 したがって、最優先事項は、クライアントが去ろうとしていることを正確かつタイムリーに予測することです。
ターゲット変数には2つの可能な値があるように見えるかもしれません:患者は生きているか死んでいます。 実際、流出予測の競合( crack 、 peaks 、 fex )を探しており、バイナリ分類の問題が見られます:オブジェクトはユーザーであり、ターゲット変数はバイナリです。 ここでは、スポーツデータ分析と実際の分析の違いを明確に見ることができます。 実際の分析では、問題を解決する前に、その解決策から利益を得ることができるように問題を提起する必要があります。 何をしますか。
流出流出不和
綿密な検査で、2種類の流出-契約(契約)と非契約(非契約)を区別できることがわかります。 最初のケースでは、クライアントは彼が疲れていると明示的に言って、彼は去ります。 多くの場合、これには契約を終了するなどの正式なアクションが伴います。この場合、実際に、その人がいつクライアントであるか、そうでないかを明確に判断できます。 非契約の場合、クライアントは何も言わず、いかなる方法でも通知せず、単にあなたのサービスの使用、サービス、あなたのゲームをして、あなたの商品を買うのをやめます。 そして、ご想像のとおり、2番目のケースはより一般的です。
つまり、CRM /データベースに特定のユーザーアクティビティ(購入、サイトへの訪問、携帯電話ネットワークでの呼び出し)があり、ある時点で減少します。 必ずしも停止するわけではありませんが、強度が大幅に変化することに注意してください。
ワンサイズですべてに対応
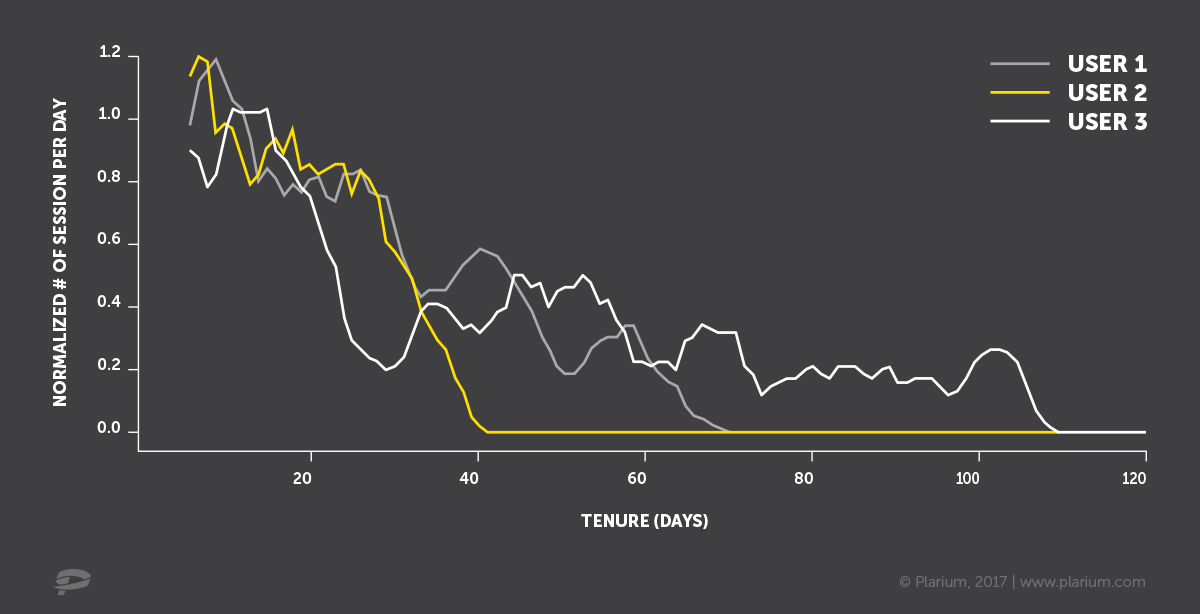
3つの仮想クライアントの訪問日を、時間軸に青い十字で示します。 最初の考えは、特定の期間を修正することです(ここでは、ターゲット定義と呼びます)。 この期間中の特定の活動は、生命の現れであり、引きこもりなどの活動の欠如と見なされます。 次に、流出予測モデルの入力データとして、対象となるモデルの前の期間のデータ(入力データ)を取得できます。

また、これらの2つの期間の間に、たとえば1〜2週間のバッファを慎重に残して、事前に流出を予測する方法を学習
このアプローチの何が問題になっていますか? パラメータを正しく設定する方法は明確ではありません。 ターゲット変数を決定するのにかかる期間。 あるクライアントにとっては、3日間の欠席は無条件の逸脱であり、別のクライアントにとっては標準的な行動です。 「大きなギャップを取りましょう。1か月、1年、2年、そしてすべてが確実に落ちます」。 すべての履歴データが長期間保存されているわけではないため、履歴データに問題がある可能性があります。 さらに、1年前のデータに基づいてモデルを構築すると、現在の状況に適さない可能性があります。 また、現在のデータでモデルの結果を確認するには、1年待つ必要があります。 歴史に深く入り込まないようにすることはできますか?
確率50/50-残っているかどうか
ユーザーのログイン履歴がわかっている場合:平均して彼が以前どのように行動していたか、現在どれくらいの期間不在であるか、正しい統計分布を見つけて、ユーザーが現在生きている確率を計算することは可能ですか? それは可能であり、1987年にパレート/ NBDモデルですでに行われていました。パレート分布(指数とガンマ重みの混合)によって離れるまでの時間が記述されており、訪問/購入の分布は負の二項分布でした。 2003年に、パレート分布を使用してベータ幾何モデルを使用する代わりにアイデアが生まれ、 BG / NBDモデルが登場しました。 両方のモデルは注目に値し、 PythonとRの両方の優れた実装があります。 入力では、これらのモデルは各ユーザーの3つの値のみを取得します。訪問数/購入数、クライアントの年齢(最初の購入から現在までの経過時間)、および最後の購入からの経過時間です。 入力データのこのような貧弱なセットでは、モデルは非常にうまく機能します。これは、Theorverを忘れるのは時期尚早であり、「 stack xgboosts 」の時間の間でも使用できることを示唆しています 。
ただし、まだ改善の余地があります。 たとえば、季節性、通話の統計に影響するプロモーションがあります-これらのモデルはそれらを考慮しません。 ケアへの近さを示す可能性のあるユーザーアクティビティの他の証拠があります。 そのため、最終的には、ゲームに失望したユーザーはリソースを浪費し(善を失うことはありません)、軍隊を解散できます。 この行動の証拠は、実際の出発と一時的な不在(インターネットのないジャングルでの休暇)を区別するのに役立ちます。 このデータをすべて、上記の確率モデルに「供給する」ことはできません(ただし、 これを行おうとしている尊敬されている人々がいます)。
ニューラルネットワークと呼ぶ
しかし、出力に分布パラメーターがあるニューラルネットワークを取得して構築するとどうなりますか? これについては、ヨーテボリ大学の卒業生の修士論文と、その中に書かれた美しく説明されたPythonパッケージ-WTTE-RNNがあります。
著者は、ワイブル分布とリカレントニューラルネットワークのすべての能力を使用して、次の呼び出しまでの時間(イベントまでの時間)を予測することにしました。 アプローチの理論的な美しさに加えて、重要な実用的なポイントもあります:リカレントニューラルネットワークを使用する場合、時系列からのサインの構築で庭をフェンスする必要はありません(一連の行と一連の関数を一連の期間と一連のラグ)にフラットテーブル(オブジェクト-サイン)。 時系列をそのままネットワーク入力に適用できます。 最近、PiterPyでの講演の中で、これについて詳しく説明しました。 これにより、コンピューティングと時間のリソースが大幅に節約されます。 1つのタイプの行(たとえば、日ごと)に加えて、別のタイプまたは長さ(たとえば、最終日の1時間ごと)の行、およびユーザーの静的特性(性別、国)、少なくともポートレートの写真(突然はげる)も入力できますより頻繁に?)、ニューラルネットワークなどが可能です。
しかし、ワイブルで構築された学習損失関数はしばしばNaNに行くことが判明しました。 また、次の呼び出しまでの時間はそれほど簡単ではありません。 それを知っていても、日没が大きすぎると見なされるまでの時間、各ユーザーのしきい値を個別に計算し、すべての季節性を考慮に入れる方法、アクティビティの一時的な中断を除外する方法などの質問に答える必要はありません。
どうする?
決定の明確な正確性を装うことなく、Plarium-Southで最終的に選択した経路を説明します。 バイナリターゲットに戻り、unningな方法で計算し、RNNをモデルとして採用しました。
なぜバイナリにするのですか?
- 結局、ビジネスにはそれが必要だからです。保持活動を行う時期と、そうでない時期を知る必要があります。
- バイナリ分類メトリック(精度、再現率、精度)は、結果を説明するのに使いやすいためです。
- 保持コストと返された顧客からの潜在的な利益を知っているので、保持キャンペーンからの総利益を最大化するという観点からカットオフしきい値を選択できます。
ターゲットをどのように計算しますか?
- 平均的なアクティビティを考慮してユーザーアクティビティの正規化されたインジケータを構築し、ゲーム業界に固有の非アクティブな初期期間を切り取ります(広告に行って、少し突いて、数週間後に活発にプレイを始めたときなど)。
- 2値化のしきい値と正規化パラメーターを選択し、長期流出との一致を最大化します。つまり、2年化の結果が、たとえば来年の活動の欠如と最も一致するようにします。
- 少し未来を見るために、トレーニングと目標の計算の期間を設定します。
- したがって、バイナリターゲットを取得しますが、以前に表明された欠陥はありません(すべてのゲームに一定の統一された期間はなく、さまざまな種類のゲームやその他の特定の機能が考慮されます)。
なぜRNNなのか?
- 時系列に基づいて機能を操作する方が簡単だからです。
- 精度が非常に良いため(ROC-AUC約0.97)。
投稿に関心がある場合、次のシリーズでは、モデル、そのアーキテクチャ、データ準備、および使用するテクノロジーについて詳しく説明します。
もう一つ
ところで、そのようなことをすることに興味のある方は、クラスノダールオフィスのデータサイエンティストとデータエンジニアのポジションの専門家を探しています。 流出に加えて、他の興味深いタスク(詐欺行為、推奨者、ソーシャルグラフ)、大量のデータ、すべてのリソースもあります。 クラスノダールでの生活は暖かく快適です。 :)履歴書をhr.team@plarium.comに送信します 。