両方の基準に影響する重要な要素は、ストレージシステムです。 それらの分類は、機器の種類やブランドに限定されません。 この記事では、ストレージのタイプ(ブロック、ファイル、オブジェクト)を検討し、それぞれの目的に適したストレージを決定します。

/ Flickr / ジェイソンベイカー / cc
ストレージの種類とその違い
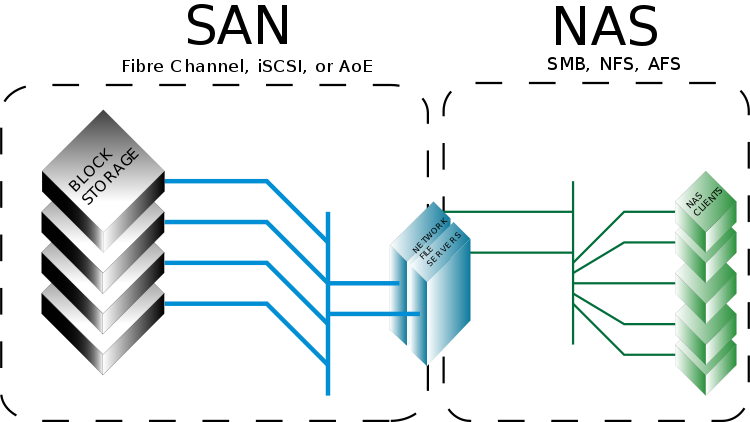
ブロックレベルのストレージは、従来のハードドライブまたはテープの中心です。 ファイルは同じサイズの「ピース」に分割され、それぞれが独自のアドレスを持ちますが、メタデータはありません。 例は、HDDドライバーがフォーマットされたディスクのアドレスにブロックを書き込んだり読み取ったりする状況です。 このようなストレージシステムは、Oracle、DB2などのリストにあるほとんどのリレーショナルDBMSなど、多くのアプリケーションで使用されます。ネットワークでは、ブロックホストへのアクセスは、ファイバーチャネル、iSCSI、またはAoEプロトコルを使用してSANを介して編成されます。
ファイルシステムは、ブロックストレージとアプリケーションI / Oの中間です。 ファイルタイプストレージの最も一般的な例はNASです。 ここでは、データは階層構造で収集されたファイルおよびフォルダーとして保存され、クライアントインターフェイスを介して名前、ディレクトリ名などでアクセスできます。
/ウィキメディア/ メニス / CC
「SANはネットワークドライブのみであり、NASはネットワークファイルシステムである」という分離は人為的なものであることに注意してください。 iSCSIが登場すると、それらの境界がぼやけ始めました。 たとえば、2000年代初頭、NetAppはNASにiSCSIを提供し始め、EMCはNASゲートウェイをSANアレイに「配置」し始めました。 これは、システムの使いやすさを向上させるために行われました。
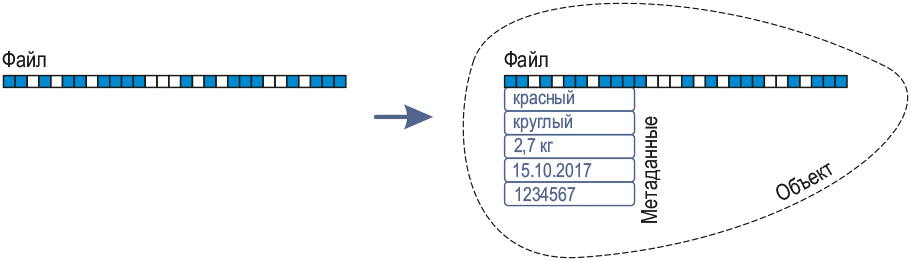
オブジェクトストレージについては、ファイルシステムがない場合のファイルストレージおよびブロックストレージとは異なります。 ファイルストレージツリー構造は、フラットなアドレススペースに置き換えられます。 階層なし-ユーザーまたはクライアントがデータを取得できる一意の識別子を持つオブジェクトのみ。
CarnigoのCEO兼共同設立者であるMark Gorosは、この整理方法を駐車サービスと比較しています。 車を駐車場に連れて行く係員にお任せください。 交通機関を拾いに来るとき、あなたはただチケットを見せます-あなたは車を取り戻します。 あなたは彼が立っていた駐車場を知りません。
ほとんどのオブジェクトストアでは、オブジェクトにメタデータを添付し、コンテナに集約できます。 したがって、システム内の各オブジェクトは、データ、メタデータ、一意の識別子(割り当てられたアドレス)の3つの要素で構成されます。 同時に、オブジェクトストレージは、ブロックストレージとは異なり、メタデータをファイル属性に制限しません -ここでそれらを構成できます。
/ 1 クラウド
さまざまなタイプのストレージシステムの適用性
ブロックストレージ
ブロックストレージには、パフォーマンスを向上させる一連のツールがあります 。ホストバスアダプターは、プロセッサをオフロードし、他のタスクのためにリソースを解放します。 したがって、ブロックストレージシステムは仮想化によく使用されます。 データベースの操作にも適しています。
ブロックストレージの欠点は、管理のコストと複雑さが高いことです。 ブロックストレージの別の欠点(ファイルストレージに適用されます。これについては後述します)は、メタデータの量が限られていることです。 追加情報は、アプリケーションおよびデータベースレベルで処理する必要があります。
ファイルストレージ
ファイルストレージの利点の中で、シンプルさが際立っています。 ファイルには名前が付けられ、メタデータを受け取り、ディレクトリとサブディレクトリ内の場所を「検索」します。 通常、ファイルストレージはブロックシステムに比べて安価であり、階層トポロジは少量のデータを処理する場合に便利です。 したがって、彼らの助けを借りて、ファイル共有システムとローカルアーカイブシステムが編成されます。
おそらく、ファイルストレージの主な欠点は「制限」です。 大量のデータが蓄積されると問題が発生します 。フォルダーや添付ファイルのヒープから必要な情報を見つけるのが難しくなります。 このため、速度が重要なデータセンターではファイルシステムは使用されません。
オブジェクトリポジトリ
オブジェクトストレージについては、拡張性が高いため、ペタバイトの情報を扱うことができます。 統計によると、世界中の非構造化データの量は2020年までに 44ゼタバイトに達します。これは2013年の10倍になります。 FacebookからDropBoxへ。
Haystack Facebookのようなストレージサイトは、毎日3億5000万枚の写真を補充し 、2400億のメディアファイルを保存します。 このデータの合計量は357ペタバイトと推定されます。
データのコピーを保存することも、オブジェクトストレージの優れた機能です。 調査によると、情報の70%はアーカイブ内にあり、めったに変更されません。 たとえば、このような情報は、災害復旧に必要なシステムバックアップです。
しかし、構造化されていないデータを保存するだけでは十分ではありません。解釈して整理する必要がある場合もあります。 ファイルシステムには、この点で制限があります。メタデータの管理、階層、バックアップ-これらすべてが障害になります。 オブジェクトストレージには、ファイルの正確性をチェックするための内部メカニズムと、データの可用性を保証するその他の機能が備わっています。
フラットアドレススペースはオブジェクトストレージの利点でもあります。ローカルサーバーまたはクラウドサーバーにあるデータも同様に簡単に取得できます。 したがって、そのようなリポジトリは、ビッグデータやメディアを扱うためによく使用されます 。 たとえば、 NetflixとSpotifyで使用されます。 ところで、オブジェクトストレージの機能は1cloudサービスで利用できるようになりました。
オブジェクトストレージを使用する組み込みのデータ保護ツールのおかげで、信頼できる地理的に分散したバックアップセンターを作成できます。 API は HTTPベースであるため、たとえばブラウザまたはcURLを介してアクセスできます。 ブラウザーからオブジェクトストアにファイルを送信するには、次を指定できます。
<form action = "[url_storage/account/container/object]" method = "post" enctype = "multipart/form-data"> <input type="hidden" name="redirect" value="[url_result]"> <input type="hidden" name="signature" value="[hmac]"> <input type="file" name="file_name"> <input type="submit"> </form>
送信後、必要なメタデータがファイルに追加されます。 これにはリクエストがあります:
curl -i [url_storage/account/container/object] -X POST -H "X-Auth-Token: [token]" -H "X-Object-Meta-ValueA: [value-a]"
オブジェクトの豊富なメタ情報により、ストレージプロセスが最適化され、コストが最小限に抑えられます。 これらの利点-スケーラビリティ、メタデータの拡張性、情報への高速アクセス-は、オブジェクトストレージシステムをクラウドアプリケーションに最適な選択肢にします。
ただし、トランザクションワークロードの操作などの一部の操作では、ストレージをブロックするソリューションの有効性が劣ることを覚えておくことが重要です。 また、その統合には、アプリケーションロジックとワークフローの変更が必要になる場合があります。
PS 1cloudブログからのデータの保存に関するいくつかの資料: