さて、約束したとおり、 PHPコースの準備で学習した別の資料を共有しています。 私たちはあなたにとってそれが興味深く有用なものになることを願っています。
エントリー
最近、誰もが機械学習について話しているようです。 ソーシャルメディアフィードには、ML、Python、TensorFlow、Spark、Scala、Goなどに関する投稿が詰まっています。 そして、あなたと私に共通点があるなら、PHPについてはどうですか?
はい、機械学習とPHPはどうですか? 幸いなことに、誰かがこの質問をするだけでなく、次のプロジェクトで使用できる汎用機械学習ライブラリを開発するのに夢中になりました。 この投稿では、 PHPの機械学習ライブラリであるPHP-MLを見て、後で独自のチャットまたはツイートボットに使用できる調性分析クラスを作成します。 この投稿の主な目的は次のとおりです。
- 機械学習とテキスト感情分析に関連する一般概念の学習
- PHP-MLの機能と欠点の概要
- 解決するタスクの定義。
- PHPで機械学習を試みることは絶対にクレイジーな目標ではないという証拠(オプション)

機械学習とは何ですか?
機械学習は、人工知能研究の分野のサブセットであり、「コンピューターに正確にプログラミングされなくても学習する機会」を提供することに焦点を当てています。 これは、特定のデータセットから「学習」できる一般的なアルゴリズムを使用して実現されます。
たとえば、機械学習を使用する一般的な方法の1つは分類です。 分類アルゴリズムは、異なるグループまたはカテゴリにデータを配置するために使用されます。 分類アプリケーションの例:
- メールスパムフィルター
- 市場セグメンテーションパッケージ
- 詐欺防止システム
機械学習は、さまざまなタスク用の多くの汎用アルゴリズムを含む一般的な用語です。 アルゴリズムには、学習方法で分類された2つの主要なタイプがあります。教師との学習と教師なしの学習です。
教員養成
教師との指導では、入力オブジェクト(ベクトル)の形式のトレーニングデータと目的の出力値を使用してアルゴリズムをトレーニングします。 アルゴリズムはトレーニングデータを分析し、いわゆる目的関数を作成します。これは、新しいマークのないデータセットに適用できます。
この投稿の残りの部分では、より視覚的で関係を確認しやすいという理由だけで、教師との授業に焦点を当てます。 両方のアルゴリズムが同様に重要で興味深いことに注意してください。 他の人は、教師なしで学習することは、トレーニングデータの必要性を排除するため、より有用であると主張します。
教師なし学習
対照的に、このタイプのトレーニングは、最初からトレーニングデータがなくても機能します。 データセットの望ましい結果値がわからないため、アルゴリズムがサンプルからのみ結論を引き出すことを許可します。 教師なしで学習することは、データの隠れたパターンを明らかにするのに特に便利です。
PHP-ML
PHPでの機械学習への新しいアプローチであると主張するライブラリであるPHP-MLを紹介します。 このライブラリは、アルゴリズム、ニューラルネットワーク、およびデータの前処理、相互検証、特徴抽出のためのツールを実装しています。
言語の長所は機械学習の実装にはあまり適していないため、PHPは機械学習にとって珍しい選択であることに最初に気付くでしょう。 ただし、すべての機械学習アプリケーションがペタバイトのデータを処理して大規模な計算を行う必要があるわけではありません-単純なアプリケーションの場合、十分なPHPとPHP-MLが必要です
私が今このライブラリで想像できる最良のユースケースは、スパムフィルタのようなものであれ、テキストの調性の分析であれ、分類器を実装することです。 プロジェクトでPHP-MLを使用する方法を見つけるために、分類の問題を特定し、段階的に解決策を考えていきます。
挑戦する
PHP-MLの実装プロセスを説明し、アプリケーションに機械学習を追加するために、解決すべき興味深い問題を見つけたいと思っていました。分類子を実証する最良の方法は、ツイートトーン分析クラスを作成することです。
機械学習プロジェクトを成功させるために必要な重要な要件の1つは、信頼できるソースデータセットです。 データセットは、すでに分類された例で分類器をトレーニングできるため、重要です。 最近、航空会社を取り巻くメディアで大きな話題が出ているので、航空会社の顧客からのツイートよりも良いものはないでしょうか?
幸いなことに、 Kaggle.ioのおかげで、一連のツイートとしてのデータをすでに利用できます。 このリンクを使用して、ウェブサイトからUS Airline Sentiment twitterデータベースをダウンロードできます。
解決策
作業中のデータセットを調べることから始めましょう。 生データセットには次の列があります。
- tweet_id
- Airlines_Sentiment
- Airlines_sentiment_confidence
- 否定的な理由
- negativereason_confidence
- 航空会社
- Airlines_sentiment_gold
- お名前
- negativereason_gold
- retweet_count
- テキスト
- tweet_coord
- tweet_created
- tweet_location
- user_timezone
そして、 例のように見えます:
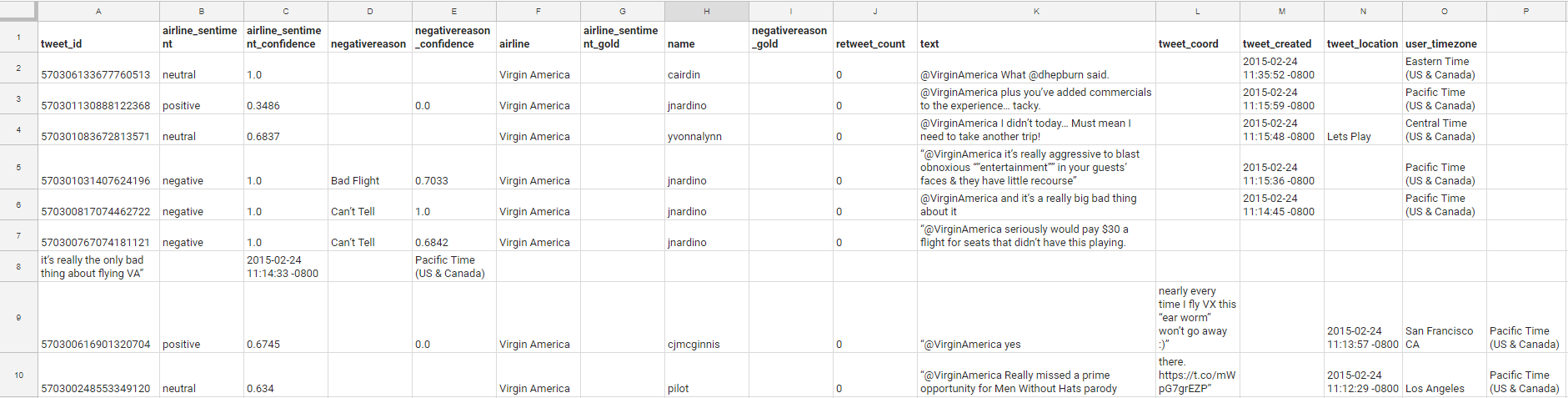
このファイルには14,640個のツイートが含まれています-これは十分なデータセットです。 これで、非常に多くの列を使用できるようになり、例に必要なデータよりも多くのデータが得られました。 実用的な目的のために、私たちは次の列にのみ興味があります。
- テキスト
- Airlines_sentim
text
はプロパティで、
airline_sentiment
はターゲットです。 残りの列は演習に使用されないため、削除できます。 プロジェクトを作成し、次のファイルを使用してコレクターを初期化することから始めます。
{ "name": "amacgregor/phpml-exercise", "description": "Example implementation of a Tweet sentiment analysis with PHP-ML", "type": "project", "require": { "php-ai/php-ml": "^0.4.1" }, "license": "Apache License 2.0", "authors": [ { "name": "Allan MacGregor", "email": "amacgregor@allanmacgregor.com" } ], "autoload": { "psr-4": {"PhpmlExercise\\": "src/"} }, "minimum-stability": "dev" }
composer install
Composerの概要が必要な場合は、 こちらをご覧ください 。
すべてを正しくインストールしたことを確認するために、
Tweets.csv
データ
Tweets.csv
を読み込むクイックスクリプトを作成し、必要なデータが含まれていることを確認します。 次のコードを
reviewDataset.php
としてプロジェクトのルートにコピーします。
<?php namespace PhpmlExercise; require __DIR__ . '/vendor/autoload.php'; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('datasets/raw/Tweets.csv',1); foreach ($dataset->getSamples() as $sample) { print_r($sample); }
次に、
reviewDataset.php
スクリプトを実行して、結果を確認します。
Array( [0] => 569587371693355008 ) Array( [0] => 569587242672398336 ) Array( [0] => 569587188687634433 ) Array( [0] => 569587140490866689 )
今のところ便利に見えませんか?
CsvDataset
クラスを見て、内部で何が起こっているかをよりよく理解しましょう。
<?php public function __construct(string $filepath, int $features, bool $headingRow = true) { if (!file_exists($filepath)) { throw FileException::missingFile(basename($filepath)); } if (false === $handle = fopen($filepath, 'rb')) { throw FileException::cantOpenFile(basename($filepath)); } if ($headingRow) { $data = fgetcsv($handle, 1000, ','); $this->columnNames = array_slice($data, 0, $features); } else { $this->columnNames = range(0, $features - 1); } while (($data = fgetcsv($handle, 1000, ',')) !== false) { $this->samples[] = array_slice($data, 0, $features); $this->targets[] = $data[$features]; } fclose($handle); }
CsvDataset
コンストラクターは、3つの引数を取ります。
- ソースCSVファイルへのパス
- ファイル内のプロパティの数を指定する整数
- 最初の行がヘッダーかどうかを示すブール
もう少し詳しく見てみると、クラスがCSVファイルを2つの内部配列(サンプルとターゲット)に分割していることがわかります。 サンプルにはファイルによって提供されるすべての関数が含まれ、ターゲットには既知の値(負、正、または中立)が含まれます。
上記に基づいて、CSVファイルの形式は次のとおりであることがわかります。
| feature_1 | feature_2 | feature_n | target |
作業を継続する必要がある列のみを使用して、クリーンなデータセットを作成する必要があります。 このスクリプトを
generateCleanDataset.php
と呼びましょう:
<?php namespace PhpmlExercise; require __DIR__ . '/vendor/autoload.php'; use Phpml\Exception\FileException; $sourceFilepath = __DIR__ . '/datasets/raw/Tweets.csv'; $destinationFilepath = __DIR__ . '/datasets/clean_tweets.csv'; $rows =[]; $rows = getRows($sourceFilepath, $rows); writeRows($destinationFilepath, $rows); /** * @param $filepath * @param $rows * @return array */ function getRows($filepath, $rows) { $handle = checkFilePermissions($filepath); while (($data = fgetcsv($handle, 1000, ',')) !== false) { $rows[] = [$data[10], $data[1]]; } fclose($handle); return $rows; } /** * @param $filepath * @param string $mode * @return bool|resource * @throws FileException */ function checkFilePermissions($filepath, $mode = 'rb') { if (!file_exists($filepath)) { throw FileException::missingFile(basename($filepath)); } if (false === $handle = fopen($filepath, $mode)) { throw FileException::cantOpenFile(basename($filepath)); } return $handle; } /** * @param $filepath * @param $rows * @internal param $list */ function writeRows($filepath, $rows) { $handle = checkFilePermissions($filepath, 'wb'); foreach ($rows as $row) { fputcsv($handle, $row); } fclose($handle); }
仕事をするのに十分な複雑さはありません。
phpgenerateCleanDataset.php
実行してみましょう。
それでは、次に進み、reviewDataset.phpスクリプトをクリーンなデータセットに向けます。
Array ( [0] => @AmericanAir That will be the third time I have been called by 800-433-7300 an hung on before anyone speaks. What do I do now??? ) Array ( [0] => @AmericanAir How clueless is AA. Been waiting to hear for 2.5 weeks about a refund from a Cancelled Flightled flight & been on hold now for 1hr 49min )
バム! これが私たちが扱うことができるデータです! これまで、データを管理するための簡単なスクリプトを作成しました。 次に、
src/class/SentimentAnalysis.php
新しいクラスを作成します。
<?php namespace PhpmlExercise\Classification; /** * Class SentimentAnalysis * @package PhpmlExercise\Classification */ class SentimentAnalysis { public function train() {} public function predict() {} }
Sentimentクラスには、調性分析クラスの2つの関数が必要です。
- データセットのサンプルとラベル、およびいくつかの追加パラメーターを取得する学習機能。
- ラベル付けされていないデータセットを受け取り、トレーニングデータに基づいてラベルのセットを割り当てる予測関数。
プロジェクトのルートで、
classifyTweets.php
スクリプトを作成します。 これを使用して、主要な分析クラスを作成およびテストします。 使用するテンプレートは次のとおりです。
<?php namespace PhpmlExercise; use PhpmlExercise\Classification\SentimentAnalysis; require __DIR__ . '/vendor/autoload.php'; // Step 1: Load the Dataset // Step 2: Prepare the Dataset // Step 3: Generate the training/testing Dataset // Step 4: Train the classifier // Step 5: Test the classifier accuracy
ステップ1.データセットをダウンロードする
前の例からCSVをデータオブジェクトにロードするために使用できる基本的なコードは既に用意されています。 いくつかの小さな変更を加えて同じコードを使用します。
<?php ... use Phpml\Dataset\CsvDataset; ... $dataset = new CsvDataset('datasets/clean_tweets.csv',1); $samples = []; foreach ($dataset->getSamples() as $sample) { $samples[] = $sample[0]; }
これにより、プロパティのみを含む配列が作成されます。この場合、分類子のトレーニングに使用するツイートテキストです。
ステップ2:データセットの準備
ツイートは互いに大きく異なるため、生のテキストを分類子に渡すと、利益と正確さが失われます。 幸いなことに、分類アルゴリズムまたは機械学習アルゴリズムを適用しようとするときにテキストを操作する方法があります。 この例では、次の2つのクラスを使用します。
- トークンカウントベクトライザー:このクラスは、テキストサンプルのコレクションをトークンカウントベクトルに変換します。 実際、ツイート内の各単語は一意の番号になり、特定のテキストサンプル内の単語の出現回数が追跡されます。
- Tf-idfトランスフォーマー:用語頻度の略語-逆文書頻度は、文書のコレクションまたはコーパスの一部である文書のコンテキストで単語の重要性を評価するために使用される数値統計です。
テキストベクトライザーから始めましょう:
<?php ... use Phpml\FeatureExtraction\TokenCountVectorizer; use Phpml\Tokenization\WordTokenizer; ... $vectorizer = new TokenCountVectorizer(new WordTokenizer()); $vectorizer->fit($samples); $vectorizer->transform($samples);
次に、Tf-idfトランスフォーマーを適用します。
<?php ... use Phpml\FeatureExtraction\TfIdfTransformer; ... $tfIdfTransformer = new TfIdfTransformer(); $tfIdfTransformer->fit($samples); $tfIdfTransformer->transform($samples);
サンプルの配列は、分類器が理解できる形式になりました。 まだ終了していません。適切なムードで各サンプルをマークする必要があります。
ステップ3.トレーニングキットを作成する
幸いなことに、PHP-MLは既にこれを行う方法を知っており、コードは非常に単純です。
<?php ... use Phpml\Dataset\ArrayDataset; ... $dataset = new ArrayDataset($samples, $dataset->getTargets());
このデータセットを使用して、分類器をトレーニングできます。 ただし、テストとして使用するのに十分なテストデータセットがないため、初期データセットを「測定」して2つに分割します:トレーニング資料のセットと、モデルの精度を検証するために使用されるはるかに小さなデータセットです。
<?php ... use Phpml\CrossValidation\StratifiedRandomSplit; ... $randomSplit = new StratifiedRandomSplit($dataset, 0.1); $trainingSamples = $randomSplit->getTrainSamples(); $trainingLabels = $randomSplit->getTrainLabels(); $testSamples = $randomSplit->getTestSamples(); $testLabels = $randomSplit->getTestLabels();
このアプローチは、相互検証と呼ばれます。 この用語は統計に基づいており、次のように定義できます。
相互検証(相互検証、ローリング制御、英語の相互検証)-独立したデータでの分析モデルとその動作を評価する方法。 モデルを評価するとき、利用可能なデータはk個の部分に分割されます。 次に、データのk-1部分でモデルトレーニングが実行され、残りのデータがテストに使用されます。 手順はk回繰り返されます。 最終的に、k個のデータのそれぞれがテストに使用されます。 その結果、選択したモデルの有効性が評価され、利用可能なデータが最も均一に使用されます。-Wikipedia.com
ステップ4:分類器のトレーニング
最後に、SentimentAnalysisクラスに戻って実装する準備が整いました。 気づいていない場合、機械学習の大部分はデータの収集と処理に関連しています。 機械学習モデルの実際の実装は、それほど複雑ではない傾向があります。
ムード分析クラスを実装する3つの分類アルゴリズムがあります。
- サポートベクター法
- K-Nearest Neighborメソッド(KNearestNeighbors)
- Naive Bayes Classifier(NaiveBayes)
この演習では、最も単純なNaiveBayes分類子を使用します。そのため、学習機能を実装するためにクラスを継続して変更します。
<?php namespace PhpmlExercise\Classification; use Phpml\Classification\NaiveBayes; class SentimentAnalysis { protected $classifier; public function __construct() { $this->classifier = new NaiveBayes(); } public function train($samples, $labels) { $this->classifier->train($samples, $labels); } }
ご覧のとおり、PHP-MLにすべてのハードワークを任せます。 私たちは私たちのプロジェクトのために少し抽象化するだけです。 しかし、分類器が本当に訓練されて機能するかどうかをどのようにして知るのでしょうか?
testSamples
と
testLabels
を使用する時間。
ステップ5:分類器の精度の検証
分類子のテストを続行する前に、予測メソッドを実装する必要があります。
<?php ... class SentimentAnalysis { ... public function predict($samples) { return $this->classifier->predict($samples); } }
また、PHP-MLが役立ちます。 classifyTweetsクラスを次のように変更しましょう。
<?php ... $predictedLabels = $classifier->predict($testSamples);
最後に、訓練されたモデルの精度をテストする方法が必要です。 幸いなことに、PHP-MLもこれをカバーしており、いくつかのメトリッククラスがあります。 この場合、モデルの精度に関心があります。 コードを見てみましょう:
<?php ... use Phpml\Metric\Accuracy; ... echo 'Accuracy: '.Accuracy::score($testLabels, $predictedLabels);
次のようなものが表示されるはずです。
Accuracy: 0.73651877133106%
おわりに
この記事は大きすぎることがわかったので、学んだことを繰り返しましょう。
- 機械学習アルゴリズムの実装には、最初から適切なデータセットを用意することが重要です。
- 教師ありと教師なしの学習の違い。
- 機械学習における相互検証の意味と使用。
- そのベクトル化と変換は、機械学習用のテキストデータセットの準備に必要です。
- NaiveBayes PHP-ML分類子を使用してツイート感情分析を実装する方法。
この投稿は、PHP-MLライブラリの紹介でもあり、ライブラリができることと、ライブラリをプロジェクトに統合する方法についてのアイデアを提供してくれることを願っています。
最後に、この投稿は決して包括的なものではなく、学び、改善し、実験する多くの機会があります。 方向性の開発方法について話し始めるためのアイデアをいくつか紹介します。
- NaiveBayesアルゴリズムをサポートベクターメソッドに置き換えます。
- 完全なデータセット(14,000行)を実行しようとすると、おそらくメモリの負荷がどれだけ増加するかがわかります。 各実行でトレーニングする必要がないように、モデルの不変性を実現してください。
- データセット生成を独自のヘルパークラスに移動します。
終わり
いつものように、私たちはあなたのコメントや意見を待っています。