プロローグ
私たち一人一人は時々、私たちに休息を与えない質問を持っています。 そして、原則として、そのような質問に対する答えは、多数の人々の経験を分析することによってのみ得られます。 次の質問がありました。「IQに影響を与える要因は何ですか、それは少しでも有利ですか?」 もちろん、読者は誰もが長い間すべてを知っていると叫ぶかもしれません。あなたはこのトピックに関する記事を読むことができます。 ある程度はあなたは正しいでしょうが、悲しいかな、IQに関する記事は非常に物議を醸すことが判明し、私にさらに多くの質問を押し付けました。 したがって、私はこのトピックに関する控えめな研究を実施することにしました。

延滞開発におけるケンブリッジ研究
1962年、イギリスでは反社会的行動に影響を与える要因についての大規模で長期的な研究(20年)が開始されました。 10歳の約500人の少年が回答者として選ばれ、890人のパラメーターが各回答者に付けられ、それは彼の若さ、成長、彼の家族の生活と彼の環境を記述しています。 これらのパラメーターの中にIQレベルがあり、それが他の変数との依存関係を研究するアイデアにつながりました。

ライブラリのインポートとデータのロード:
import pandas as pd import matplotlib.pyplot as plt from sklearn import preprocessing import matplotlib.pyplot as plt import seaborn as sns import numpy as np from sklearn import preprocessing import warnings warnings.filterwarnings('ignore') import random as rn from sklearn.cross_validation import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestRegressor from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn import svm
data = pd.read_stata('/Users/####/Downloads/ICPSR_08488/DS0001/08488-0001-Data.dta')
データ処理
IQ係数がターゲット変数として選択され、少し調整する必要がありました。
data['V288'].replace('IQ75',75,inplace=True ) data['V288'].replace('IQ129',129,inplace=True) data['V288'].replace('IQ128',128,inplace=True)
必要な機能の選択
# , ranks = {} # def ranking(ranks, names, order=1): minmax = MinMaxScaler() ranks = minmax.fit_transform(order*np.array([ranks]).T).T[0] ranks = map(lambda x: round(x,2), ranks) return dict(zip(names, ranks))
# (Y) Y = data['V288'].values # Y IQ = data.drop(['V288'], axis=1) X = data.as_matrix() # colnames = IQ.columns
%matplotlib inline from sklearn.feature_selection import RFE, f_regression from sklearn.linear_model import (LinearRegression, Ridge, Lasso, RandomizedLasso) from sklearn.preprocessing import MinMaxScaler from sklearn.ensemble import RandomForestRegressor # rlasso = RandomizedLasso(alpha=0.04) Y = data['V288'].values rlasso.fit(X, Y) ranks["rlasso/Stability"] = ranking(np.abs(rlasso.scores_), colnames) print('finished')
記事にコードをロードしないようにするために、サインを評価するためのテストを1つだけ断片化しましたが、興味深い場合は、すべてのソースコードを削除できます。
辞書に重要度の値をすべて表示します
r = {} for name in colnames: r[name] = round(np.mean([ranks[method][name] for method in ranks.keys()]), 2) methods = sorted(ranks.keys()) ranks["Mean"] = r methods.append("Mean") print("\t%s" % "\t".join(methods)) for name in colnames: print("%s\t%s" % (name, "\t".join(map(str, [ranks[method][name] for method in methods]))))
結果のマトリックスは次のとおりです。最後の列には、すべてのテストに基づいた重要度の平均値が表示されます。
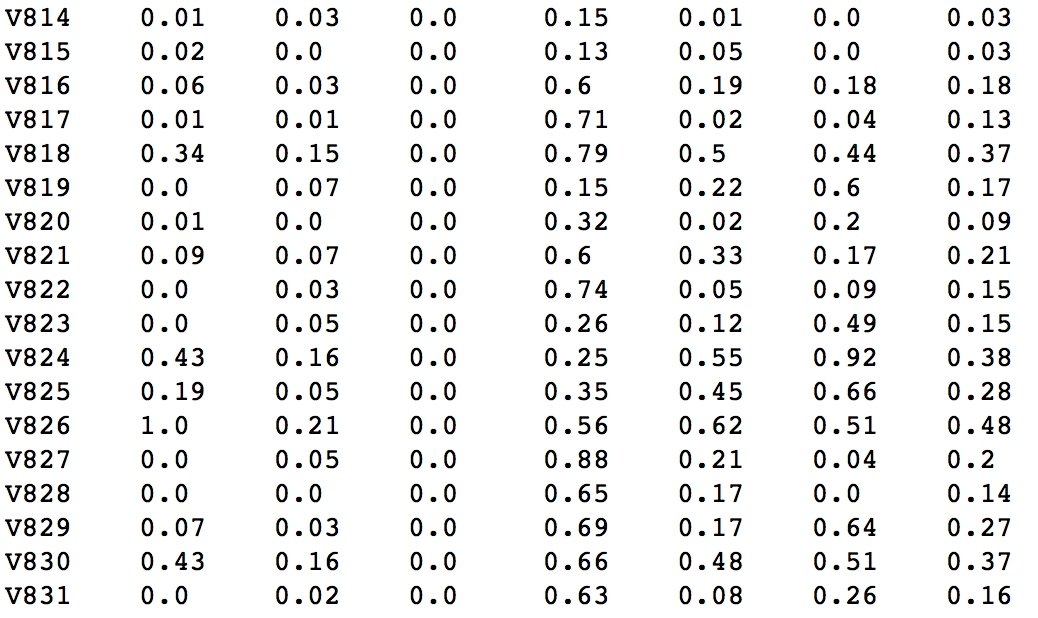
平均で上位100個の変数を選択しましょう。
sorted(r, key=r.get, reverse=True)[:100]
兆候の最も重要な兆候の説明
また、念のため、ピアソン基準を使用してこれらの変数を再確認しました。
1.平均IQおよび生活の状態:
p_value 0.035
通常:98.171533
恐ろしい:103.934307
2.平均IQと動作:
p値0.005
デバウチャー:102.395833
適切:98.286385
3.平均IQと嘘
p値0.004
まれに嘘をつく:94.357895
定期的に嘘をつく:99.627907
しばしば嘘をつく:101.702381
常に嘘をつく:102.204545
4.平均的なIQおよびソーシャルサポート:
補助金と手当が含まれています。
p値0.004
州ではサポートされていません:98.310976
サポート:107.132530
5.平均IQと外観:
p_value 0.011
きちんとした:96.295597
平均:102.608696
乱雑:100.526316
6.平均IQと集中レベル
p_value 0.007
良い濃度:98.732218
濃度が低い:105.186207
7.乳児期の平均IQと発達の問題
p_value 0.012
通常:99.294304
開発遅延:104.562500
結局、子供が学校でどのようなIQを持っているか、30歳でどれだけ稼ぐかという依存関係を見るのは興味深いことでした(平均週収が取られます)
IQおよび給与:
111以降:17.500000
101-110:16.906250
91-100:17.364486
90以下:17.558140
おわりに
IQに実際に影響を与えることができる要因はありますが、一方で、サンプルの場合のIQは収益のレベルに影響を与えることはできません。