インフォグラフィック:
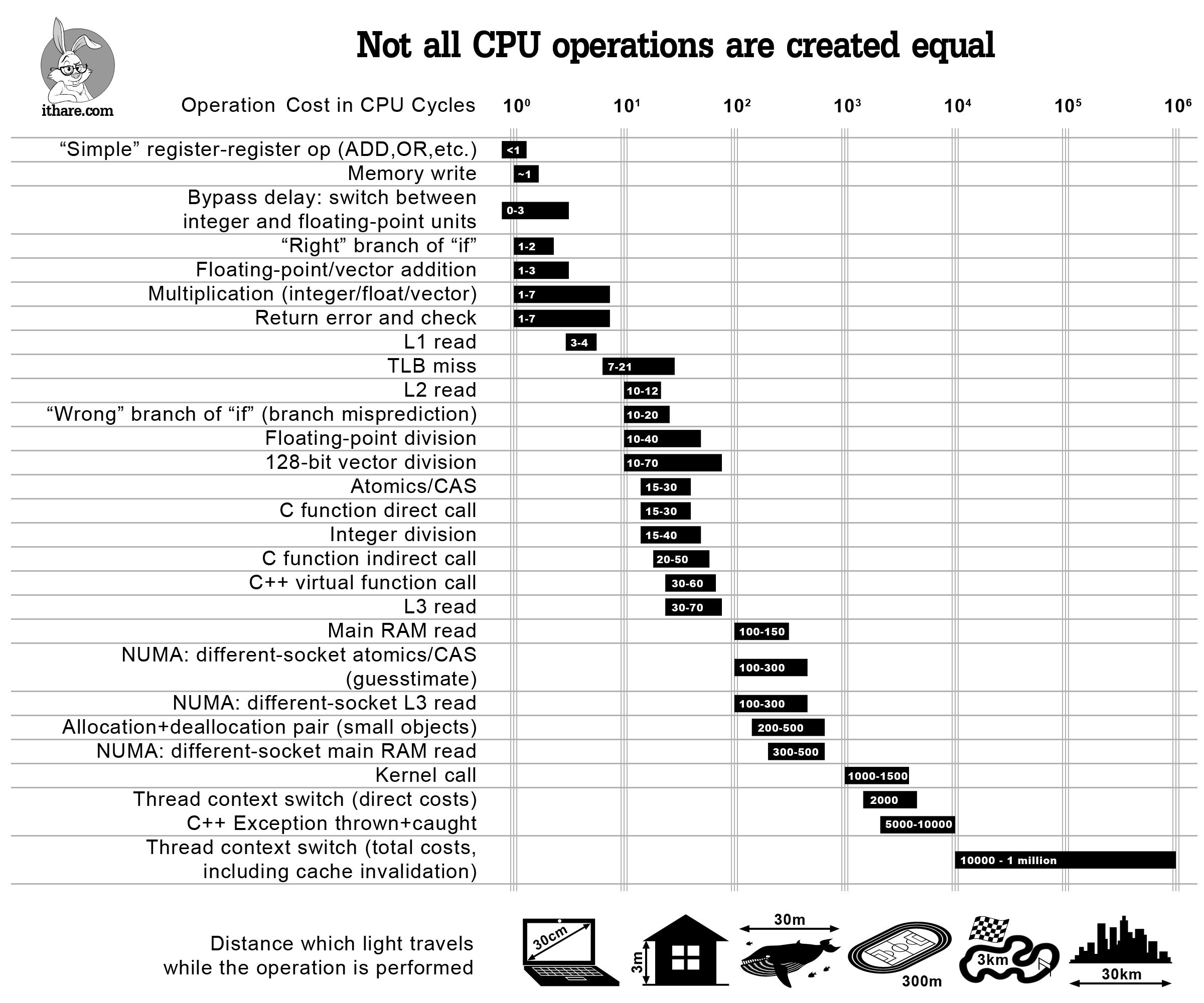
コードを最適化する必要がある場合は、プロファイルを作成して簡素化する必要があります。 ただし、最初から非効率なことをしないように(そして、できればプログラムを後でプロファイリングしないように)、いくつかの一般的な操作の概算コストを単純に見つけることが理にかなっている場合があります。
CPUサイクルでの特定の操作のコストを評価するのに役立つインフォグラフィック-「ちょっと、L2の読み取り操作には通常どれくらいの費用がかかるの?」 これらのすべての質問に対する回答は多かれ少なかれ知られていますが、それらがすべて一覧表示され、遠近法で提示されている単一の場所を知りません。 厳密に言えば、記載されているコストは最新のx86 / x64プロセッサにのみ適用されますが、大規模なマルチレベルキャッシュ(ARM Cortex AやSPARCなど)を備えた他の最新のプロセッサでも同様のコスト比が見られることが予想されます。 一方、MCU(ARM Cortex Mを含む)はまったく異なるため、一部のパターンが適用されない場合があります。
最後に、重要なことですが、警告:ここでのすべての見積もりは順序を示しているだけです。 ただし、さまざまな操作の違いの大きさを考えると、これらの指示は引き続き使用できます(少なくとも「早すぎる悲観化」は避けてください)。
一方で、「ちょっと、仮想関数の呼び出しは何の価値もない」と言わなければ、そのような図は役に立つと確信しています。 代わりに、上記のインフォグラフィックを使用すると、3 GHzの周波数のプロセッサで仮想関数を毎秒100K呼び出すと、おそらくプロセッサの総量の0.2%以上のコストはかかりません。 ただし、同じ仮想関数を毎秒10M呼び出すと、仮想化がプロセッサコアの2桁の割合を吸収することを簡単に意味する可能性があります。
同じ質問に近づくもう1つの方法は、「ちょっと、10,000サイクルのコードごとに仮想関数を1回呼び出すので、仮想化はプログラムの時間の1%以上を消費しません」と言うことですが、それでも何らかの方法が必要です関連するコストの大きさのオーダーを参照してください-上記のチャートは引き続き有用です。
次に、上記のインフォグラフィックのポイントを詳しく見てみましょう。
ALUおよびFPU操作
私たちの目的では、ALU操作といえば、大文字と小文字を区別しない操作のみを考慮します。 メモリが関与している場合、コストはまったく異なる可能性があります。以下に説明するように、メモリにアクセスするときの「キャッシュミスの大きさ」に依存します。
「簡単な」操作
現在(および最新のプロセッサ)、ADD / MOV / OR / ...などの「単純な」操作は、単一のCPUクロックサイクルよりも簡単に高速に実行できます。 これは、操作が文字通り半分のバー内で実行されることを意味しません。 それどころか、すべての操作は整数のメジャーで実行されますが、それらの一部は並行して実行できます 。
[Agner4] (ちなみに、IMHOはプロセッサ操作を評価するための最良のリファレンスガイドです)では、この機能は各操作を特徴付ける2つの量の存在に反映されます。1つは遅延(常に整数のクロックサイクルで表されます)、もう1つはパフォーマンスです。 ただし、現実の世界では、順序の推定範囲を超える場合、正確な時間はプログラムの性質と、コンパイラが一見無関係な命令を提供した順序に大きく依存することに注意してください。 要するに、待機順序よりも優れたものが必要な場合は、特定のコンパイラでコンパイルされた特定のプログラムをプロファイルする必要があります(理想的には、特定のターゲットプロセッサでも)。
このようなメソッドの詳細な説明(「アウトオブオーダー実行」として知られている)は、本当に興味深いものであり、ハードウェア指向すぎます(アウトオブオーダー操作の効率を低下させる依存関係の数を減らすためにプロセッサフードの下で発生する「レジスタの命名」はどうでしょうか?)、そして、明らかに現在の焦点にはありません。
整数の乗算/除算
整数の乗算/除算は、上記の「単純な」操作と比較して非常に高価です。 [ Agner4 ]は、1〜7サイクル(実際には、3〜6サイクルなど、より狭い範囲の値を観測した)で32/64ビット乗算(M86 / x64の世界ではMUL / IMUL)のコスト、および32/64ビットのコストを推定します除算(x86 / 64ではDIV / IDIVとして知られています)-約12-44サイクル。
浮動小数点演算
浮動小数点演算のコストは[ Agner4 ]から取られ、 加算では1〜3 CPUサイクル(FADD / FSUB)、乗算では2-5サイクル(FMUL)から除算では37-39サイクル(FDIV)まで変化します。
スカラーSSE操作(「すべての犬」が今日使用しているようです)を使用すると、インジケーターは乗算で0.5-5サイクル(MULSS / MULSD)、除算で1-40サイクル(DIVSS / DIVSD); ただし、実際には、除算には10〜40サイクルを予想する必要があります(1サイクルは実際にはめったに実現されない「相互帯域幅」です)。
128ビットのベクトル演算
数年間、CPUは「ベクトル」操作(より正確には、単一命令複数データまたはSIMD操作)をサポートしてきました。 Intelの世界ではSSEおよびAVX、ARMの世界ではARM Neonとして知られています。 データの「ベクトル」で機能し、データが同じサイズ(SSE2-SSE4の場合は128ビット、AVXおよびAVX2の場合は256ビット、今後のAVX-512の場合は512ビット)が面白いのは面白いですが、さまざまな方法で解釈できます。 たとえば、128ビットのSSE2レジスタは、(a)2つのdouble、(b)4つのfloat、©2つの64ビット整数、(d)4つの32ビット整数、(e)8つの16ビット整数、(f )16個の8ビット整数。
[ Agner4 ]は、ベクトルが4×32ビット整数として解釈される場合は<1メジャーで、128ビットベクトル上の整数加算を推定し、2×64ビット整数である場合は4メジャーを推定します。 乗算(4×32ビット)は1〜5クロックサイクルと推定されます-最後にチェックしたとき、x86 / x64命令セットには整数ベクトル除算演算はありませんでした。 128ビットベクトルでの浮動小数点演算は、加算で1〜3 CPUサイクル、乗算で1〜7 CPUサイクル、最大17〜69サイクルの除算で推定されます。
遷移遅延
計算のコストに関連する明白なことは、整数命令と浮動命令の切り替えが無料ではないということではありません。 [ Agner3 ]は、プロセッサに応じて0〜3クロックサイクルでこのコスト(「遷移遅延」と呼ばれる)を推定します。 実際、問題はより一般的であり、(CPUに応じて)ベクトル(SSE)整数命令と通常の(スカラー)整数命令を切り替えるとペナルティが生じる場合があります。
最適化のヒント:パフォーマンスが重要なコードでは、浮動小数点と整数の計算を組み合わせないでください。
分岐
次に説明するのは、コードの分岐です。 遷移(プログラム内の場合)は、基本的に比較と命令カウンターの変更です。 これらは両方とも単純ですが、分岐は非常に高価になる可能性があります。 これがなぜそうなのかという議論は、やはりハードウェア指向です(特に、パイプライン処理と投機的実行に影響します)が、ソフトウェア開発者の観点からは、次のようになります。
- プロセッサが実行先を正しく推測する場合(これはif条件の実際の計算の前です)、遷移コストは約1〜2 CPUサイクルです
- ただし、プロセッサが誤った仮定を行うと、CPUが「停止」するという事実につながります。
この遅延の持続時間は、最新のIntelプロセッサーの場合、10〜20クロックサイクルと推定されます-約15〜20クロックサイクル[ Agner3 ]。
GCC __builtin_expect()マクロは分岐予測に影響を与えると考えられていますが、15年前にはそのように機能していましたが、少なくともIntelプロセッサー(Core 2以降から)その)。
[ Agner3 ]で説明されているように、最新のIntelプロセッサでは、分岐予測は常に動的です(または少なくとも動的な決定が支配的です)。 これは、__ builtin_expect()コードからの予想される逸脱が遷移の予測に影響を与えないことを意味します(最新のIntelプロセッサー上)。 ただし、以下の「メモリへのアクセス」セクションで説明するように、__ builtin_expect()は依然としてコードの生成方法に影響します。
メモリアクセス
80年代、プロセッサ速度はメモリレイテンシに匹敵しました(たとえば、4 MHzで動作するZ80プロセッサは、レジスタ間命令で4クロックサイクル、レジスタとメモリ間命令で6クロックサイクルを費やしました)。 当時は、アセンブリを見るだけでプログラムの速度を計算することができました。
それ以降、プロセッサの速度は3桁向上し、メモリのレイテンシは10〜30倍程度しか向上していません。 残りの30を超える不整合に対処するために、これらのタイプのキャッシュはすべて導入されました。 最新のプロセッサには通常、3つのキャッシュレベルがあります。 その結果、メモリへのアクセス速度は、「読み取ろうとしているデータはどこにあるのか?」という質問に対する答えに大きく依存します。 リクエストが見つかったキャッシュレベルが低いほど、速く取得できます。
L1およびL2キャッシュアクセス時間は、[Intel.Skylake]などの公式ドキュメントに記載されています。 それぞれ4/12/44プロセッササイクルでのL1 / L2 / L3へのアクセス時間を推定します(注:これらの数値は、プロセッサモデルごとにわずかに異なります)。 一般的に、[ Levinthal ]で述べたように、キャッシュが別のコアと共有されている場合、L3へのアクセス時間は75クロックサイクルに達する可能性があります。
ただし、見つけにくいのは、メインRAMへのアクセス時間に関する情報です。 [ Levinthal ]は、60ns(プロセッサが3GHzで動作している場合、約180クロックサイクル)と推定しています。
最適化のヒント :データの局所性を改善します。 詳細については、たとえば[ NoBugs ]を参照してください。
メモリからの読み取りに加えて、書き込みもあります。 直観的には、書くことは読むことよりも高価であると認識されていますが、たいていはそうではありません。 この理由は簡単です。プロセッサは、記録が完了するのを待ってから先に進む必要はありません(代わりに、書き込みを開始するだけで、すぐに他のものに進みます)。 これは、ほとんどの場合、プロセッサが1クロックサイクルで記録できることを意味します。 これは私の経験と一致しており、[ Agner4 ]と非常によく相関しているようです。 一方、システムがメモリ帯域幅に関連付けられている場合、数値は非常に大きくなる可能性があります。 それにもかかわらず、私が見たものから、書き込み操作でバスをオーバーロードすることは非常にまれなことなので、ダイアグラムに反映しませんでした。
データに加えて、コードがあります。
もう1つの最適化のヒント:コードの局所性も改善してください。 これはそれほど明白ではありません(原則として、データのローカリゼーションが不十分な場合よりもパフォーマンスへの影響は少なくなります)。 コードの局所性を改善する方法の議論は[ Drepper ]にあります。 これらのメソッドには、インライン化、__ builtin_expect()などが含まれます。
上記のように__builtin_expect()はIntelプロセッサでの遷移の予測には影響しませんが、コードのマークアップには影響し、コードの空間的局所性に影響することに注意してください。 その結果、__ builtin_expect()は、最新のIntelプロセッサ(ARMでは-正直なところ、わかりません)ではあまりにも顕著な効果はありませんが、それでもパフォーマンスにある程度影響する可能性があります。 MSVCでは、条件演算子のif遷移とelse遷移が__builtin_expect()に似た効果をもたらすことも報告されています(提案された遷移が2つの遷移を持つ条件演算子のif遷移である場合)が、これは疑わしいはずです。
NUMA(不均等なメモリアーキテクチャ)
メモリアクセスとパフォーマンスに関連するもう1つのことは、デスクトップコンピューターではめったに見られません(これにはマルチプロセッサマシンが必要です-マルチコアマシンと混同しないでください)。 したがって、主にサーバーのパラフィです。 ただし、これはメモリアクセス時間に大きく影響します。
複数のソケットが関係する場合、現代のプロセッサはいわゆるNUMAアーキテクチャを実装する傾向があり、各プロセッサ(「プロセッサ」=「ソケットに挿入される」)には独自のRAMがあります(以前のFSBアーキテクチャとは異なり、フロントサイドバスと共有RAM)。 各プロセッサは独自のRAMを持っているという事実にもかかわらず、CPUはRAMアドレス空間を共有します-そして、物理的に別のRAMにアクセスする必要があるときはいつでも、QPIやHypertransportなどの超高速プロトコルを介して別のソケットにリクエストを送信することで行われます。
驚いたことに、あなたが予想するほど長くはありません-データがリモートプロセッサのL3キャッシュにある場合、[ レビンタル ]は100-300 CPUサイクルを提供し、データが存在しない場合は100ns(〜= 300サイクル)とリモートプロセッサを提供しますこのデータのためにメインRAMにアクセスする必要がありました。
CAS(交換との比較)
時々(特に、非ブロッキングアルゴリズムで、ミューテックスを実装するとき)、いわゆるアトミック操作を使用することがあります。 通常、CAS(Compare-And-Swap)として知られる1つのアトミック操作のみが学術的に考慮されます(他のすべてがCASを介して実装できるという理由で)。 通常、実際にはもっと多くあります(たとえば、C ++ 11のstd :: atomic、WindowsではInterlocked *()、GCC / Linuxでは__sync _ * _および_ *()を参照してください)。 これらの操作はかなり奇妙な動物です。特に、適切な操作のためには特別なCPUサポートが必要です。 x86 / x64では、対応するASM命令はLOCKプレフィックスによって特徴付けられるため、x86 / x64上のCASは通常LOCK CMPXCHGと記述されます。
現在の観点から、CASなどのこれらの操作は、通常のメモリアクセスよりもはるかに長く実行されることが重要です(原子性を保証するために、プロセッサは、少なくとも異なるコア間、またはマルチソケット構成の場合、異なるメモリ間でもプロセスを同期する必要がありますソケット)。
[ AlBahra ]は、CAS操作のコストを約15〜30サイクル(x86とIBM Powerファミリーでわずかに異なる)で見積もっています。 この数は、2つの仮定が満たされた場合にのみ正当化されることに注意する価値があります。(a)シングルコア構成で作業していること、および(b)比較するメモリがすでにL1にあること。
マルチソケットNUMA構成でのCASのコストに関しては、CASでデータを見つけることができなかったので、推測なしではできません。 一方で、「リモート」メモリのCAS遅延をソケット間のHyperTransport回路よりも小さくすることはほとんど不可能であり、これはNUMA L3キャッシュを読み取るコストに匹敵します。
一方、これらの指標を超える理由は本当にありません:-)。 その結果、100〜300 CPUサイクルでのNUMAの個別のCAS(およびCASに類似した)操作のコストを見積もります。
TLB(連想翻訳バッファー)
最新のプロセッサと最新のOSを使用する場合は常に、アプリケーションレベルで通常「仮想」アドレススペースを扱います。 つまり、10個のプロセスを実行すると、これらの各プロセスは独自のアドレス0x00000000を持つことができます(おそらくそうなります)。 この分離をサポートするために、プロセッサはいわゆる「仮想メモリ」を実装しています。 x86の世界では、1982年に80286で導入された「保護モード」によって最初に実装されました。
通常、「仮想メモリ」はページごとに機能します(x86の場合、各ページのサイズは4Kまたは2M、または少なくとも理論的には1Gでも(!))、CPUが実行中のプロセスを認識している場合(!)すべてのメモリアクセスのアドレス。 すべてのプロセッサレジスタ(マークアップを処理するものを除く)が「仮想メモリ」形式のすべてのポインタを含むという意味で、この再マーキングは完全に舞台裏で行われることに注意してください。
そして、「マークアップ」について話し始めたので、このマークアップに関する情報はどこかに保存する必要があります。 さらに、このマークアップ(仮想アドレスから物理アドレスへ)はすべてのメモリアクセスで発生するため、高速である必要があります。 通常、これには特別な種類のキャッシュが使用されます。これは、Associative Translation Buffer(TLB)と呼ばれます。
他のタイプのキャッシュと同様に、TLBミスコストがあります。 x64の場合、7〜21 CPUサイクル[ 7cpu ]の範囲です。 一般に、TLBの影響は非常に困難です。 ただし、いくつかの推奨事項を引き続き提供できます。
- 繰り返しますが、全体的なメモリの局所性を改善すると、TLBミスを減らすことができます。 データのローカル性が高いほど、TLBを終了する可能性は低くなります。
- 「ラージページ」(x64の2 MBページ)の使用を検討してください。 ページが大きいほど、必要なTLBのエントリが少なくなります。 一方、「より大きなページ」は注意して使用してください。これは両刃の剣です。 これは、特定のアプリケーションに対してテストする必要があることを意味します。
- ASLR(=「アドレス空間割り当てのランダム化」)を無効にすることを検討してください。 [ Drepper ]で説明したように、ASLRを有効にすることはセキュリティには適していますが、TLBミスなどを含むパフォーマンスを低下させます。
ソフトウェアプリミティブ
これで、ハードウェアに直接関連することは完了しました。ソフトウェアに関連するいくつかのことについて説明します。 それらは本当にどこにでもあるので、使用するたびにどれだけ使うかを見てみましょう。
C / C ++での関数呼び出し
最初に、C / C ++で関数を呼び出すコストを見てみましょう。 実際、C / C ++で関数を呼び出すものは、呼び出す前に多くのことを地獄で行い、呼び出し先も黙って座っていません。
[ Efficient C ++ ]は、パラメーターの数に応じて25〜250クロックサイクルで関数を呼び出すためのCPUコストを推定します。 しかし、これはかなり古い本であり、私は同じ口径のより良い参照を持っていません。 一方、私の経験では、パラメーターの数がかなり少ない関数の場合、これはおそらく15〜30サイクルになります。 [ eruskin ]が発見したように、これはIntel以外のプロセッサーにも当てはまるようです。
最適化のヒント:必要に応じてインライン関数を使用します。 ただし、最近では、コンパイラはほとんどの場合、組み込み仕様を無視します。 したがって、非常に重要なコードスニペットの場合、GCCには__attribute __((always_inline))を使用し、MSVCには__forceinlineを使用して必要な処理を実行できます。 ただし、それほど重要ではないコードスニペットにこれらの強制インラインを使用しないでください。これにより、さらに悪化する可能性があります。
ところで、多くの場合、埋め込みから得られる利益は、単に通話を削除するコストを超える場合があります。 これは、埋め込みによりかなりの数の追加の最適化(ハードウェアパイプラインの適切な使用を保証するための並べ替えに関連するものを含む)が提供されるという事実によるものです。 また、埋め込みによりコードの空間的局所性が向上することを忘れないでください。これは少し役立ちます(たとえば[ Drepper ]を参照)。
間接呼び出しと仮想呼び出し
上記の説明は、通常の(「直接」)関数呼び出しに関連していました。 間接呼び出しと仮想呼び出しのコストは高いことが知られており、多くの人は間接呼び出しが分岐を引き起こすことに同意します(ただし、同じコードポイントから同じ関数を呼び出す限り、[ Agner1 ]で示されているように、最新のプロセッサの遷移予測メカニズムはこれを非常によく予測できます。そうしないと、10〜30クロックサイクルの誤った予測に対してペナルティが発生します)。 仮想呼び出しに関しては、これは1回の追加読み取り(VMTポインターの読み取り)であるため、その時点ですべてが(通常どおり)キャッシュされる場合、さらに4プロセッサーサイクル程度について話します。
一方、実用的な測定[ eruskin ]は、仮想関数のコストが小さな関数の直接呼び出しのコストの約半分であることを示しています。 誤差範囲(「順序」)内で、これは上記の分析と一致しています。
最適化のヒント :仮想呼び出しが高価な場合は、代わりにC ++でテンプレートの使用(いわゆるコンパイル時ポリモーフィズムの実装)を検討できます。 CRTPは、これを行う唯一の方法です(唯一の方法ではありません)。
配分
今日、アロケーターは非常に高速です。 特に、tcmallocとptmalloc2アロケーターは、小さなオブジェクト[ TCMalloc ]の割り当て/解放に200〜500 CPUサイクルしか使用できません。
ただし、割り当てに関連する重要な警告があり、割り当てを使用する間接的なコストに追加されます:割り当ては、古き良き経験則のように、メモリの局所性の低下を意味し、それがパフォーマンスに悪影響を及ぼします(相互作用のため)上記の非キャッシュメモリを使用)。 これが実際にどれほど悪いかを説明するために、[ NoBugs ]の20行のプログラムを見てみましょう。 このプログラムは、ベクター<>を使用する場合、リスト<>を使用する同等のプログラムよりも100から780倍高速に実行されます(コンパイラーと特定のフィールドに依存します)。
最適化のヒント :プログラムの割り当て数を減らすことを検討してください。特に、ほとんどの作業が読み取り専用データで行われる段階がある場合は考えてください。 場合によっては、データ構造の平滑化(つまり、選択したオブジェクトをパックされたオブジェクトに置き換える)により、プログラムを最大5倍高速化できます。
トピックに関する実際のストーリー。 昔々、ギガバイトのRAMを使用するプログラムがありましたが、これは大きすぎると考えられていました。 わかりました、私はそれを「フラット化」バージョンに書き直しました(つまり、各ノードは最初に動的に構築され、次に同等の読み取り専用「フラット化」オブジェクトがメモリに作成されました)。 「スムージング」のアイデアは、メモリの量を減らすことでした。 プログラムを開始すると、メモリ量が2倍減少しただけでなく(予想どおり)、非常に良い副作用のように、実行速度が5倍増加したことがわかりました。
OSカーネル呼び出し
私たちのプログラムがオペレーティングシステムで動作する場合(はい、それなしでも動作するプログラムがまだあります)、システムAPIのグループ全体があります。 実際には(少なくとも通常のOSについて話している場合)、これらのシステムコールの多くはカーネルコールにつながります。これには、カーネルモードへの切り替えやその逆も含まれます。 これには、異なる「保護リング」間の切り替え(Intelプロセッサーでは、通常「リング3」と「リング0」の間)が含まれます。 プロセッサレベルの切り替えには約100クロックサイクルしかかかりませんが、これに関連する他のオーバーヘッドは通常カーネルコールをはるかに高価にするため、通常のカーネルコールには少なくとも1000-1500プロセッササイクルかかります[ Wikipedia.ProtectionRing ]。
C ++例外
現在、C ++例外は、機能するまで価値がないと言われています。 それは本当に何もありません-それはまだ100%明確ではありません(IMOはそのような質問がまったく尋ねられるかどうかさえ明確ではありません)が、それは確かに非常に近いです。
ただし、これらの「コストがかからずまだ作業を行わない」実装は、例外が発生するたびに実行する必要がある膨大な作業の背後にあります。 スローされた例外のコストは莫大であることに誰もが同意しますが、(いつものように)実験データはほとんどありません。 ただし、[ Ongaro ]実験では、約5,000プロセッササイクル(ペスト!)のおおよその数が得られます。 さらに、より複雑なケースでは、この数値はさらに大きくなると予想されます。
エラーの返却と検証
例外の一時的な代替方法は、エラーコードを返し、各レベルでチェックすることです。 この種のパフォーマンス測定については言及していませんが、合理的な実験を行うのに十分なことはすでにわかっています。 それを詳しく見てみましょう(エラーが発生した場合のパフォーマンスについてはあまり気にしませんので、すべてが正常である場合は評価に集中します)。
原則として、返品および確認費用は3つの個別の費用で構成されます。 これらの最初のものは条件付き遷移自体のコストであり、99 +%の場合に正しく予測されると安全に仮定できます。 つまり、この場合の条件付きジャンプのコストは約1〜2サイクルです。 2番目のコストはエラーコードをコピーするコストであり、それがレジスタ内にある限り、これは単純なMOVです。これらの状況では、0〜1クロックサイクルです(0クロックサイクルは、MOVに追加コストがないことを意味します。他の操作と並行して実行されます)。 3番目のコストはそれほど明白ではありません-これは、エラーコードを運ぶために必要な追加のレジスタのコストです。 — PUSH/POP ( ), , + L1 1 + 4 . , , PUSH/POP , ; , x86 ; x64 ( ) , PUSH/POP , ( , , , PUSH/POP).
, ---- ( ) 1 7 . , , , 10000 , , , ; , 100 , , , . , — « ».
, , , , . , . , « » (, , nginx Apache), « »?
10000 ; , . , , , « ». [ LiEtAl ], .
- — , 2000 (3 , )
- ; ; [ LiEtAl ], 3M . , , 12M L3 ( 50 ) 10M ; , 1M [LiEtAl] . « » x64 ( 4000, Windows/x64): 4000 ( , , 15-20 . , 40-50K , ), ----- — , , 4000 , , — , , --------------.
, , .
, , ( ), , , , - — , .
終わり
,