
Igor Panteleev、ソフトウェア開発者、DataArt
多くのサービスが人間の音声を認識するために発明されました-PocketsphinxまたはGoogle Speech APIを覚えておいてください。 オーディオファイルの形式で記録されたフレーズを、定性的に印刷テキストに変換できます。 ただし、これらのアプリケーションはいずれも、マイクでキャプチャされたさまざまなサウンドをソートできません。 正確に記録されたもの:人間のスピーチ、動物の叫び、音楽? この質問に答える必要に直面しています。 そして、機械学習アルゴリズムを使用して音を分類するためのパイロットプロジェクトを作成することにしました。 この記事では、選択したツール、発生した問題、TensorFlowのモデルのトレーニング方法、オープンソースソリューションの実行方法について説明します。 また、認識結果をDeviceHive IoTプラットフォームにアップロードして、サードパーティアプリケーションのクラウドサービスで使用することもできます。
分類のためのツールとモデルの選択
まず、ニューラルネットワークを操作するためのソフトウェアを選択する必要がありました。 私たちにとって適切だと思われた最初の解決策は、 Python Audio Analysisライブラリーでした。
機械学習の主な問題は、優れたデータセットです。 音声認識と音楽分類には、このようなセットがたくさんあります。 ランダムな音の分類では、物事はそれほど良くありませんが、すぐではないとしても、「都会的な」音のデータセットを見つけました 。
テスト中に、次の問題が発生しました。
- pyAudioAnalysisは十分な柔軟性がありません。 狭い範囲のパラメーターで動作し、それらの一部はオンザフライで計算されます。 たとえば、トレーニングサイクルの数はサンプルの数に基づいており、これは変更できません。
- 選択したデータセットには10個のクラスのみが含まれており、それらはすべて都市の音のグループに含まれています。
次のソリューションは、 Google AudioSetでした 。これは、YouTubeのタグ付きビデオフラグメントに基づいており、2つの形式でダウンロードできます。
- 各フラグメントに関する次の情報を含むCSVファイル:YouTubeに投稿されたビデオのID、フラグメントの開始時間と終了時間、パッセージに割り当てられた1つ以上のタグ。
- TensorFlowファイルとして保存される抽出されたオーディオ機能。
これらのオーディオ機能は、 YouTube-8Mモデルと互換性があります 。 このソリューションでは、 TensorFlow VGGishモデルを使用してオーディオストリームから機能を抽出することも推奨しています。 このソリューションは当社の要件のほとんどを満たしていたため、選択することにしました。
学習モデル
次のタスクは、YouTube-8Mインターフェイスがどのように機能するかを調べることでした。 ビデオで動作するように設計されていますが、幸いなことに、オーディオで動作することができます。 このライブラリは非常に柔軟ですが、クラスの数は固定されています。 そのため、クラスの数をパラメーターとして渡すことができるように、いくつかの変更を加えました。 YouTube-8Mは、集約された機能と各フラグメントの機能の2種類のデータを処理できます。 Google AudioSetは、各フラグメントの機能の形式でデータを提供します。 次に、トレーニング用のモデルを選択する必要がありました。
リソース、時間、精度
グラフィックプロセッサ(GPU)は、中央処理装置(CPU)よりも機械学習に適しています。 詳細についてはこちらをご覧ください。詳細については説明せず、すぐに設定に進みます。 実験には、NVIDIA GTX 970 4GBグラフィックスカードを1枚搭載したPCを使用しました。
私たちの場合、トレーニング時間はそれほど重要ではありませんでした。 選択したモデルとその精度について最初の決定を下すには、1〜2時間のトレーニングで十分でした。
もちろん、可能な限り最高の精度を得たいと思っています。 しかし、より複雑なモデル(より高い精度を提供する必要があります)をトレーニングするには、より多くのRAM(グラフィックプロセッサを使用する場合はビデオカードメモリ)が必要になります。
モデル選択
説明付きのYouTube-8Mモデルの完全なリストについては、 こちらをご覧ください 。 トレーニングデータは断片化された機能として表示されるため、適切なモデルを使用する必要があります。 Google AudioSetには、バランスの取れたトレーニング、バランスの取れていないトレーニング、評価の3つの部分からなるデータセットが含まれています。 詳細についてはこちらをご覧ください 。
トレーニングと評価のために、YouTube-8Mの修正版が使用されました。 こちらにあります 。
バランスの取れた学習
この場合、コマンドは次のとおりです。
python train.py --train_data_pattern = / path_to_data / audioset_v1_embeddings / bal_train / *。tfrecord --num_epochs = 100 --learning_rate_decay_examples = 400000 --feature_names = audio_embedding --feature_sizes = 128 --frame_featuresbatch = patch 527 --train_dir = / path_to_logs --model = ModelName
LstmModelについては、ドキュメントに従って基本学習速度を0.001に変更しました。 また、十分なRAMがなかったため、lstm_cellsの値を256に変更しました。
学習成果を見てみましょう。

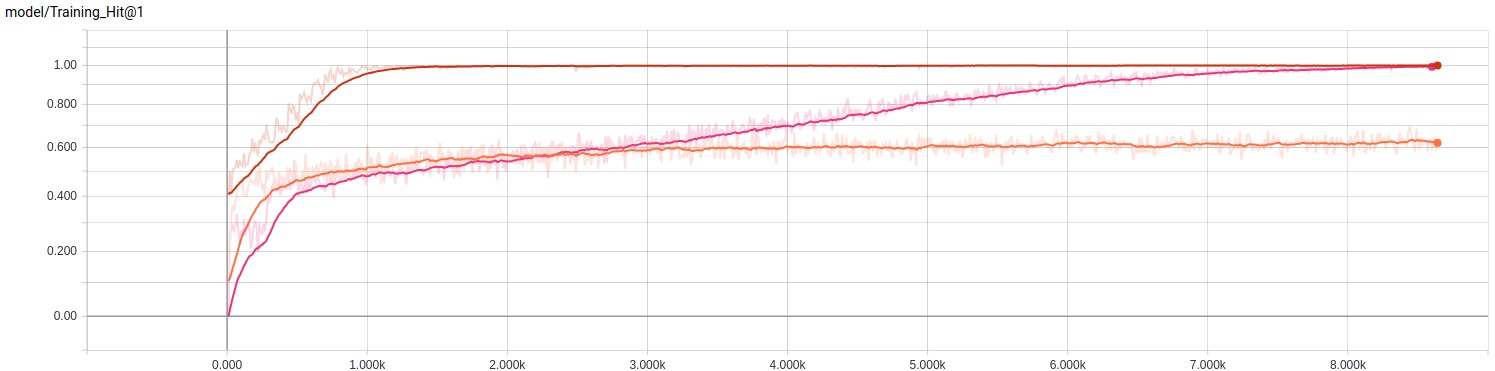
| モデル名 | トレーニング時間 | 最終ステップの評価 | 平均評価 |
|---|---|---|---|
| ロジスティック | 14分3秒 | 0.5859 | 0.5560 |
| Dbof | 31分46秒 | 1,000 | 0.5220 |
| Lstm | 1時間45分53秒 | 0.9883 | 0.4581 |
トレーニング段階で何とか良い結果を得ることができましたが、これは完全な評価で同様の指標を達成するという意味ではありません。
不均衡な学習
不均衡なデータセットにはさらに多くのサンプルがあるため、トレーニングサイクルの数を10に設定します(学習に時間がかかるため、5を設定する必要があります)。
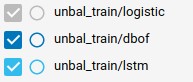
| モデル名 | トレーニング時間 | 最終ステップの評価 | 平均評価 |
|---|---|---|---|
| ロジスティック | 2時間4分14秒 | 0.8750 | 0.5125 |
| Dbof | 4時間39分29秒 | 0.8848 | 0.5605 |
| Lstm | 9時間42分52秒 | 0.8691 | 0.5396 |
トレーニングジャーナル
ログファイルを調べたい場合は、このリンクからダウンロードして抽出できます。 ロード後、 tensorboard --logdir / path_to_train_logs /を実行し、 リンクをたどります。
トレーニングの詳細をご覧ください。
YouTube-8Mは多くのパラメーターを受け入れ、それらの多くは学習プロセスに影響を与えます。
たとえば、学習の速度と時代の数を調整できます。これにより、学習プロセスが大きく変わります。 結果を改善するために調整および変更できる損失およびその他の有用な変数を計算するための3つの関数もあります。
オーディオキャプチャデバイスでトレーニングされたモデルを使用する
モデルをトレーニングしたら、コードを追加してモデルとやり取りします。
マイクオーディオキャプチャ
どういうわけか、マイクから音声データを取得する必要があります。 PyAudioライブラリを使用します。これは、シンプルなインターフェイスを持ち、ほとんどのプラットフォームで動作します。
音の準備
前述のように、機能を抽出するツールとしてTensorFlow VGGishモデルを使用します。 変換プロセスの簡単な説明を次に示します。
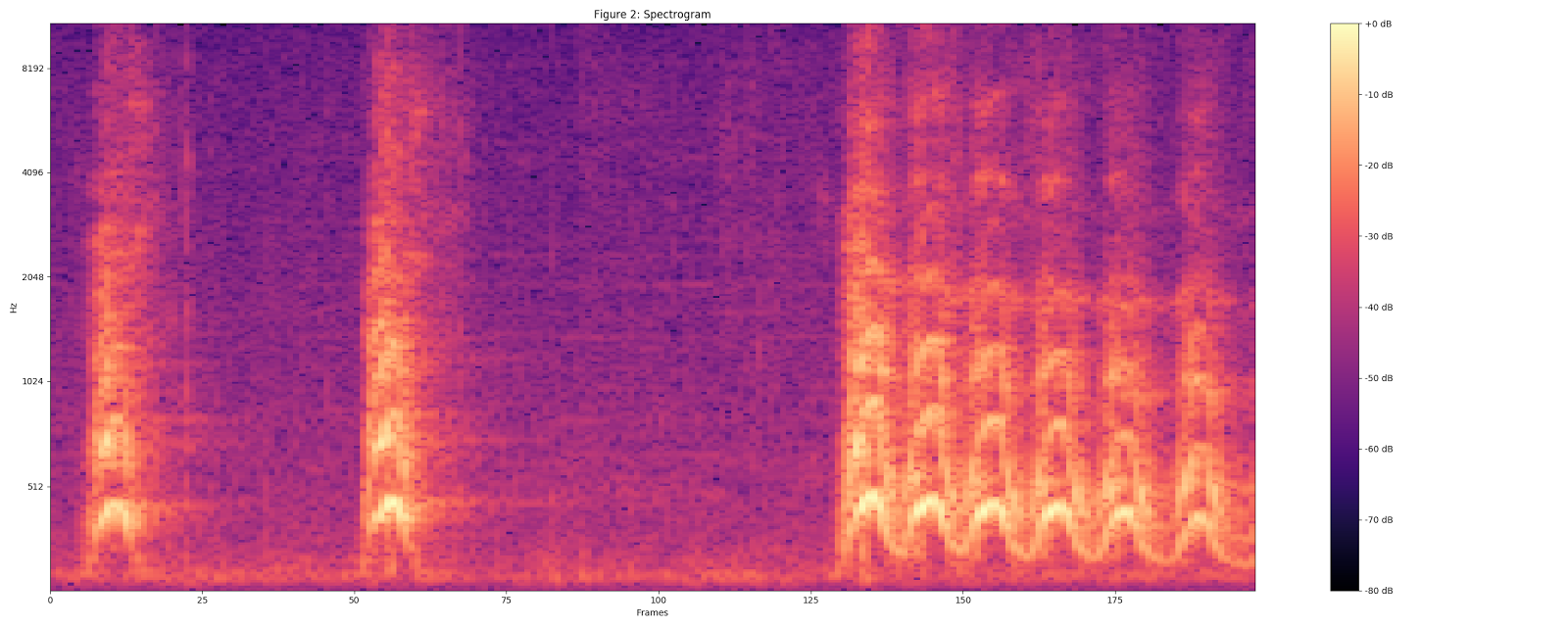
視覚化には、UrbanSoundデータセットのDog barkサンプル(「Dog Barking」)を使用しました。
オーディオを16 kHzモノラル形式に変換します。
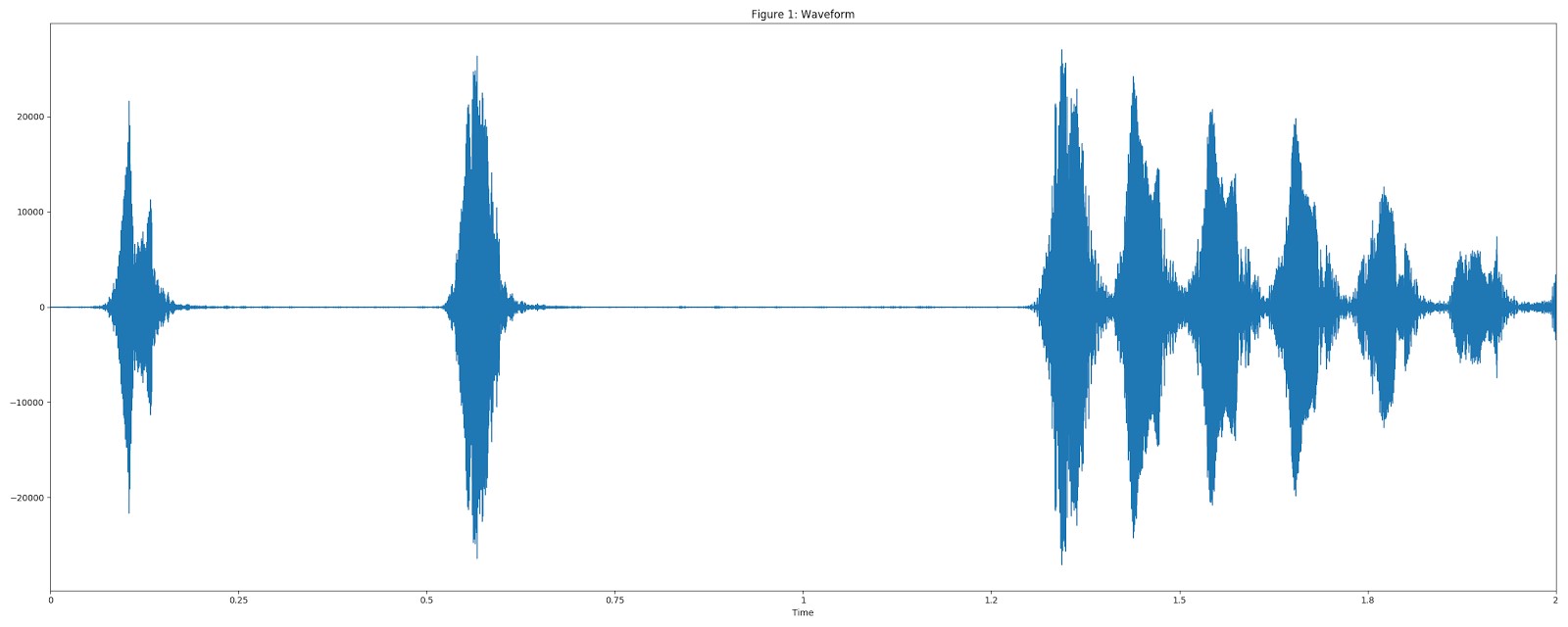
25 msのウィンドウサイズ、10 msのステップ、および周期的なHannウィンドウを使用して、STFT値(短い時間間隔でのフーリエ変換)を使用してスペクトログラムを計算します 。
チョークスペクトログラムを計算し、現在のスペクトログラムを64ビットチョークの範囲にします。
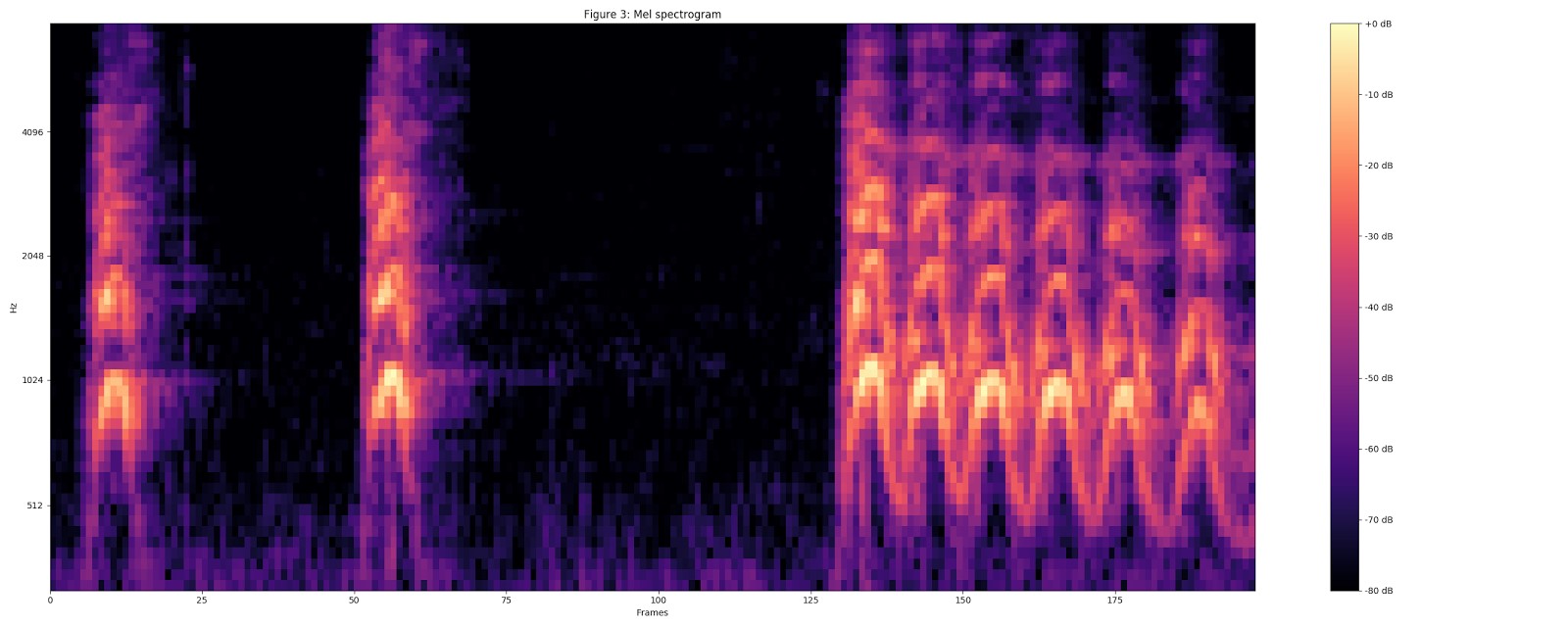
log(mel-spectrum + 0.01)を使用して安定化された対数スペクトログラムを計算します。ここで、オフセットはゼロ対数を回避するために使用されます。

これらの機能は、0.96秒でばらばらのフラグメントに変換されます。各機能は、10ミリ秒の96フレームに対して64チョーク範囲の次元を持ちます。
次に、結果のデータはVGGishモデルに送られ、データがベクトル形式になります。
分類
最後に、データをニューラルネットワークに転送して結果を取得するためのインターフェイスが必要です。
YouTube-8Mのインターフェイスをベースにしていますが、シリアル化/非シリアル化フェーズを削除するように変更します。
ここで 、私たちの仕事の結果を見つけることができます。 この点を詳しく見てみましょう。
設置
PyAudioはlibportaudio2とportaudio19-devを使用するため、これらのパッケージをインストールして動作させる必要があります。
さらに、いくつかのPythonライブラリが必要になります。 これらはpipでインストールできます: pip install -r requirements.txt
また、保存したモデルを含むアーカイブをプロジェクトルートにダウンロードして抽出する必要があります。 ここで見つけることができます。
打ち上げ
このプロジェクトでは、3つのインターフェースのいずれかを使用する可能性を提供しています。
録音済みの音声ファイル
python parse_file.py path_to_your_file.wavを実行すると、ターミナルでSpeechが表示されます:0.75、Music:0.12、Inside、大きな部屋またはホール:0.03
結果はソースデータに依存します。 これらの値は、ニューラルネットワークの予測に基づいて導出されます。 値が大きいほど、入力データがこのクラスに属する可能性が高くなります。
マイクデータのキャプチャと処理
python capture.pyは、マイクからデータを継続的にキャプチャするプロセスを起動します。 5〜7秒ごとに分類用のデータを送信します(デフォルト)。 前の例のように結果が表示されます。 パラメーター--save_path = / path_to_samples_dir /を使用して実行できます。この場合、キャプチャされたデータはすべて、指定されたフォルダーに.WAV形式で保存されます。 この機能は、同じパターンで異なるモデルを試したい場合に便利です。 詳細については、-helpオプションを使用してください。
Webインターフェース
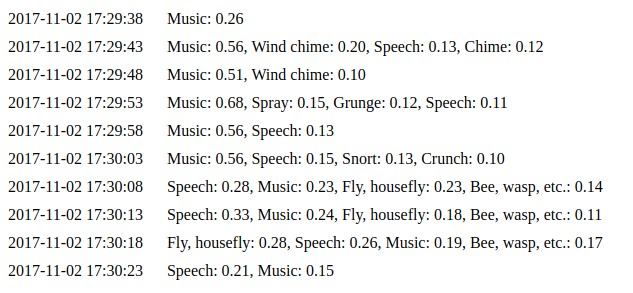
python daemon.pyコマンドは、単純なWebインターフェースを実装します 。これは、デフォルトでhttp://127.0.0.1:8000で利用可能です。 前の例と同じコードを使用します。 イベントページで最新の10個の予測を確認できます 。
IoT統合
最後の非常に重要な点は、IoTインフラストラクチャとの統合です。 前のセクションで説明したWebインターフェースを起動すると、メインページでDeviceHiveクライアント接続とその設定のステータスを確認できます。 クライアントが接続されている間、予測は通知の形式で指定されたデバイスに送信されます。

おわりに
TensorFlowは、画像や音声を認識するための多くの機械学習アプリケーションで役立つ非常に柔軟なツールです。 このようなツールをIoTプラットフォームと連携して使用すると、大きな可能性を秘めたインテリジェントなソリューションを作成できます。 「スマートシティ」では、安全性を確保するために使用できます。たとえば、ガラスやショットを壊す音を認識することができます。 熱帯林でさえ、そのようなソリューションを使用して、野生動物や鳥の声を分析することで、野生動物や鳥のルートを追跡できます。 IoTプラットフォームは、マイクの範囲内で音の通知を送信するように構成できます。 このようなソリューションをローカルデバイスにインストールして(同時にクラウドシステムとして展開することができます)、トラフィックとクラウドコンピューティングのコストを最小限に抑え、未処理の音声付きの添付ファイルなしで通知のみを送信するようにカスタマイズできます。 これはオープンソースプロジェクトであることを忘れないでください。それを使用して独自のサービスを作成できます。