
オブジェクト検出におけるコンテキスト推論のための空間メモリからの突然の馬(ICCV 2017で発表)
ニュースはありますが、自宅でカメラを獲得できるコンテストについて、またはクラウドチームの空き状況について書くのは退屈です。 したがって、私たちは誰にとっても興味深い情報から始めます(ほとんど誰でも-ビデオ分析について話します)。
最近、コンピュータービジョンテクノロジーに関する最大のカンファレンスであるInternational Conference on Computer Vision 2017が終了しました。そこで、科学者のチームとさまざまな企業の研究部門の代表者が、写真の改善、説明による画像の生成、光分析を使用したコーナーの探索などの開発を発表しました。 ビデオ監視の分野でアプリケーションを見つけることができるいくつかの興味深いソリューションについてお話します。
モバイルデバイス上の「DSLR」品質の写真

CCTVカメラとスマートフォンのマトリックスは年々改善されていますが、一眼レフカメラに追いつくことはないようです。 そして、1つの理由があります-モバイルデバイスの物理的な制限。
チューリッヒのスイス連邦工科大学の研究者は、カメラで受信した画像を最高品質ではなく、正確に「直線化」した詳細と色に変換するアルゴリズムを発表しました 。 このアルゴリズムでは、画像にないものを作成することはできませんが、明るさとコントラストを調整するだけでなく、写真を改善するのに役立ちます。
写真処理は、色再現と画像の鮮明さの両方を改善するスキャンニューラルネットワークを使用して実行されます。 グリッドは、スマートフォンカメラとデジタルカメラで同時に撮影されたオブジェクトでトレーニングされました。 グリッドは、条件付きオブジェクトに最適な品質を理解し、「理想的な」画像に最適に一致するように画像のパラメーターを変更しようとします。
洗練された画像エラー知覚機能は、色、階調、テクスチャに関するデータを組み合わせます。 調査によると、強化された画像は一眼レフカメラで撮影した写真に匹敵する品質を示しますが、この方法自体はあらゆるタイプのデジタルカメラに適用できます。
画像品質を改善するためのアルゴリズムの現在のバージョンは、 phancer.comでテストできます。画像をアップロードするだけです。
一からフォトリアリスティックな画像を作成

ラトガーズ大学、リチャイ大学、中国香港大学、バイドゥリサーチの2大陸にいる7人の科学者の大規模なチームは、グリッドを使用してテキスト記述に基づいて写実的な画像を作成する方法を提案しました 。 いくつかの点で、この方法は、頭の中の画像に基づいて絵を作成する実際のアーティストの作品に似ています-最初に大まかなスケッチがキャンバスに表示され、次により正確な詳細が表示されます。
コンピューターはまず、与えられたオブジェクトのテキスト記述(および既知の画像の知識ベース)に基づいて画像を作成する最初の試みを行い、次に別のアルゴリズムが結果の画像を評価し、画像を改善するための提案を行います。 たとえば、入り口には「緑の鳥」、花のベース、有名な鳥のベースがあります。 このテキストの説明に正しく対応する多数の画像があります-これは問題の1つです。
テキスト記述から画像を生成するために、いくつかの折りたたみ生成競合ネットワーク(SGAN)が使用されます。 GAN Stage-Iは、プリミティブスケッチをスケッチし、テキスト記述データに基づいてオブジェクトの原色を追加します。 GAN Stage-IIは、Stage-Iの結果とテキストの説明を入力として受け取り、写真のようにリアルな高解像度の画像を生成します。 GAN Stage-IIは欠陥を修正し、興味深い詳細を追加できます。 StackGANによって作成されたサンプルは、他の既存のアプローチによって生成されたサンプルよりも信頼性が高くなります。
GAN Stage-Iはオブジェクトと背景のスケッチを生成するため、GAN Stage IIは詳細に焦点を合わせ、欠陥を修正するだけです。 GAN Stage-IIは、GAN Stage-Iが取得しなかったテキスト情報の処理を学習し、オブジェクトに関するより詳細な情報を引き出します。
ビデオ内の相互接続された複雑なイベントの処理
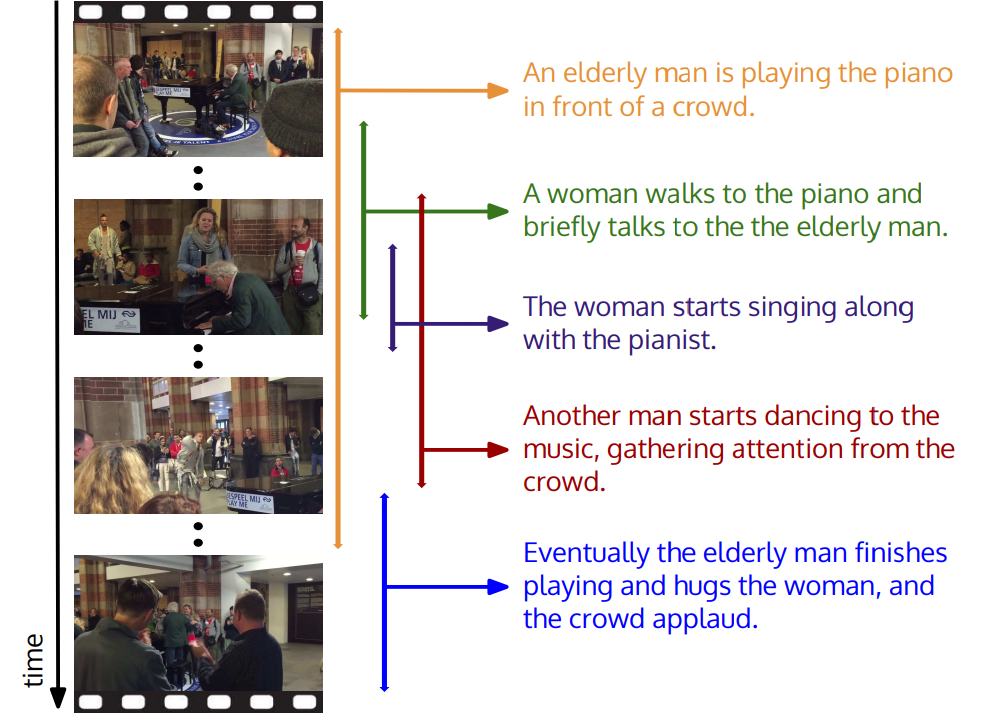
スタンフォード大学では、彼らはコマーシャルであまりにも多くのイベントが起こっていると考えました。 たとえば、「人がピアノを弾いている」というビデオでは、「踊っている人」や「歓声を上げている人」が含まれている場合があります。 新しい研究では、すべてのイベントを識別し、自然言語で説明するモデルを提案しました。
モデルは時空間記述に基づいています 。 実際、コンピューターは詳細なコンテキストの説明を含む数千のビデオで最初にトレーニングされました。
興味深いことに、DeepMindでは、同様の問題を解決するために、 彼らは別の経路を取り 、ビデオシーケンスを音声と相関させて、フレーム内の内容を最初に理解せずにオブジェクトを認識し始めました。 Googleアルゴリズムは3つの部分で構成されています。最初のニューラルネットワークはビデオから取得した画像を処理し、2番目はこれらの画像に対応する音声、3番目は画像と特定の音の相関を学習します。
ビデオ監視の同様の技術を使用して、データアーカイブ内の便利で迅速な検索を行うことができます。
自然言語画像の説明

上の写真の2つの説明のうち、「家のある野原に立っている牛」と「家の前の大きな緑の野原を歩いている灰色の牛」のうち、どちらがより人間的だと思いますか? 最後に、おそらく。 しかし、コンピューターは、人が直感的に正しい(私たちの観点から)オプションを選択する理由を理解していません。
条件付きGANプロジェクトを介したTowards DiverseおよびNatural Image Descriptionsでは、1つのニューラルネットワークが画像内のシーンの説明を作成し、もう1つのニューラルネットワークがこの説明を人間が作成したものと比較し、私たち自身のスピーチスタイルによりよく一致する要素を評価します。
いくつかの生成的競合ニューラルネットワークを含むシステムが提案されました。その1つは画像の説明を選択し、2つ目は説明が視覚的内容にどの程度対応しているかを評価しました。 処理されたイベントのコンテキストが重要ではないオブジェクトとオブジェクト間の関係の認識レベルを達成することが可能でした。 このシステムでは、牛がストローで牛乳を飲んでいるのを見たことはありませんが、牛、牛乳、ストロー、それが「飲む」ことの意味を理解しているため、この画像を認識できます。
カメラは角をのぞきます。

数年前、スコットランドのエンジニアと物理学者がカメラを作成し、文字通り隅を見て、その背後にある人と物体の動きを追跡することができました。
解決策は、科学者が角と反対側にある床と壁に発射する「光子銃」と、単一光子さえも認識できるアバランシェフォトダイオードに基づく特別な感光性マトリックスの2つのデバイスのセットでした。
壁と床の表面で反射した銃のビームからの光子は、壁の後ろにあるすべてのオブジェクトの表面で衝突して反射します。 それらのいくつかは検出器に落ち、もう一度壁から反射され、ビームの時間に基づいて、角の周りに隠れているものの位置、形状、および外観を決定することができます。
システムの動作は非常に遅く、初期イメージの形成には約3分かかりました。 さらに、結果は32 x 32ピクセルの画像の形式で表示されましたが、実際には、画像内の大まかなシルエット以外のものを作成することはできませんでした。
品質を改善するためのいくつかの試みがありましたが、解決策は予想外の角度から来ました。 MITとGoogle Researchのスペシャリストは、反射光を使用してコーナーを見るよう提案しました 。 さまざまな角度から見える光を非常に注意深く見ると、角の周りに隠されたオブジェクトの色と空間配置のアイデアを得ることができます。
それはアメリカの手順からのシーンのように見えます。 新しい画像処理システムは特別な機器を必要とせず、スマートフォンのカメラでも動作し、反射光のみを使用してオブジェクトまたは人物を検出し、速度と軌道をすべてリアルタイムで測定します。
ほとんどのオブジェクトは、視線内の地面で少量の光を反射し、半影と呼ばれるぼやけた影を作成します。 CornerCamerasシステムは、部分的なシェードビデオを使用して、一連の画像をステッチし、過剰なノイズを除去できます。 オブジェクトが実際にカメラに表示されていないという事実にもかかわらず、オブジェクトの動きが半影にどのように影響するかを見て、オブジェクトの位置と方向を判断できます。
***
これらのプロジェクトに興味がある場合は、独自のアイデアを持っているか、私たちの開発に精通したい-自分で来るか、友人を連れて行きます。 クラウドベースのビデオ監視とコンピュータービジョンに基づいた製品に取り組むには、クラウドチームの新しい人々が必要です。
開発者を州に登録した後、iPhone Xに推奨事項を提示し、開発者もペイントボールに参加する場合、推奨事項はiPhoneの保護ガラスにもなります。 ;) 空室についての詳細を読んでください (同じ場所で応答してください)。
そして今日の最後:11月19日まで(包括的) リンクをたどります。 1つの質問に答え、メールを残し、ソーシャルネットワーク上のコンテストへのリンクを投げて待つ必要があります-大気ノイズのエントロピーに基づいた乱数ジェネレーターは、Oco2ホームWi-Fiカメラで報いる複数の参加者を選択します。