こんにちは、Habr! ソーシャルネットワークのユーザーを、人道的または技術的な考え方に基づいて、コメントに従って2つのクラスに分類した経験を共有したいと思います。 この記事では、深層学習の最新の成果を使用しませんが、適切なデータの検索から予測まで、テキストの分類のために完成したプロジェクトを分析します。 最後に、自分でテストできるWebアプリケーションが表示されます。

問題の声明
バイナリ分類の場合のタスクは次のように設定されています。ユーザーがいて、彼のコメントがあり、それらからクラスを決定する必要があります:人道主義者または技術者。 この問題を解決するために、機械学習と自然言語処理の手法を適用します。 最終結果は、たとえばターゲット広告に使用できます。
データ
既存のマークアップされたサンプルはありません。これらの概念は形式化するのが難しく、何らかの理由でユーザーを2つのクラスに分割する必要があります。
ソーシャルネットワーク「VKontakte」のユーザーからのコメントに基づいて、データセットを収集することが決定されました。 公開ページでは、多くの場合、人々は多くのコメントを残して、投稿について議論するか、単にチャットします。 人道主義者と技術者の数がほぼ同じになるように、公開/グループのページは中立でなければなりません。 特定の都市の生活について議論するための専用ページを選びました。 サブスクライバーの数は約30万、パブリケーションの数は約5万、パブリケーションに対するコメントの平均数は20です。
データの取得とマークアップ
すべてのコメントは、VK Open APIを使用してダウンロードできます。これにより、13万人のユーザーから約300万のコメントが寄せられました。 この量は、機械学習のほぼすべてのモデルをトレーニングするのに十分なはずですが、1つの「しかし」があります。このデータのマークアップがなく、誰がヒューマニストで、誰が技術者かわかりません。 もちろん、各ユーザーにメッセージを書いて個人的に尋ねることもできますが、これは疑わしい考えです。 ユーザーのページから取得できる知識を使用する必要があります。
130人中1万1千人だけが教育学部を持っています。 このようなフィルタリングの結果、残りのコメントはわずか170千で、元のボリュームのわずか6%です。 全部で160の学部があり、私はすべての学部を人道的、技術的、その他(音楽や芸術などの自然科学または非科学科学)に分けました。 これらの「他の」学部は廃棄され、実験に参加しませんでした。 各ユーザーには、教員に応じたクラスが割り当てられました。これは、プロファイルに示されています。
人文学部で学んでいるすべての人が人文科学であるとは限らず、技術的にも同じことが言えるかもしれませんが、一般的な背景に対してはそのようなユーザーは少数であるべきです。 この理論を確認または反論するために、私は学部で世論調査を開催しました。 200人のうち、62人(31%)は、学部自体が技術的であるという事実にもかかわらず、彼らのメンタリティは人道的であることを示しています。 同様に、人文科学部では、150人の回答者のうち、14人(9%のみ)が技術者であると認めています。 したがって、受け取った高等教育の種類に応じた分類など、データに応じた分類に名前を付ける方がより正確です。
データ分析
コメントデータを含むテーブルの例:

モデルの構築に進む前に、利用可能なサンプルを分析する必要があります。 これにより、考慮する必要がある機能、それらの機能の分散方法、および最適なモデルを理解するのに役立ちます。 また、特定のサンプルでは一般的ではないデータの異常値や異常を見つけるのにも役立ちます。 それらを削除すると、より一般化できるモデルを作成するのに役立ちます。 両方のクラスでユーザーが分離された後、約4,000人が取得されました。 最初に、非テキストユーザー属性の分布を見てください。
性別
男性ユーザーのサンプルでは、55%が見つかりました。 社会には、男性にはより分析的な考え方があり、女性には人道的または創造的な考え方があるというステレオタイプがあります。 サンプルによれば、この特性の分布を2つのクラスに分けて示すグラフが作成されます。
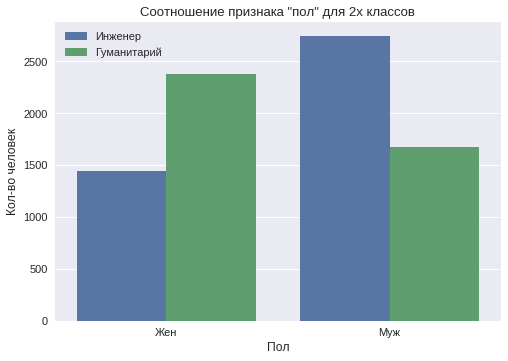
男性ユーザーの間では「技術者」クラスが優勢であり、女性ユーザーの間では「人道主義」クラスが優勢であることがわかります。
アルコールに対する態度
各クラスの約1,500人のユーザーは、アルコールに対する態度と喫煙に対する約1,600人の態度に注目しています。 もちろん、多くの人はソーシャルネットワークでこの項目を記入せず、30%だけがそれを示しました。 ある部分は、最高の光で自分自身を見せたり、クラスメートを感動させるために、故意に誤った情報を示すことができます。 しかし、2つのクラスの違いの一般的な傾向はまだ見えています。
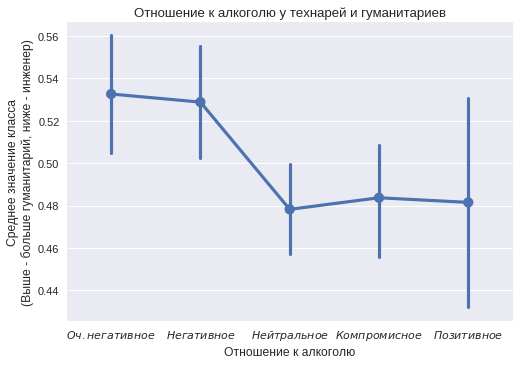
横軸には、アルコールに対する「非常に否定的な」態度から「肯定的な」態度までのカテゴリがあります。 各カテゴリについて、両方のクラスの人数を考慮しました。 縦軸には、グループ内の人文科学の割合が示されています。 垂直バーは信頼区間を示します。 このグラフは、技術者がプロファイルでアルコールに対する積極的な態度を示すことが多いことを示しています。 非常に否定的な態度は、人文科学によってより頻繁に示されます。
喫煙態度
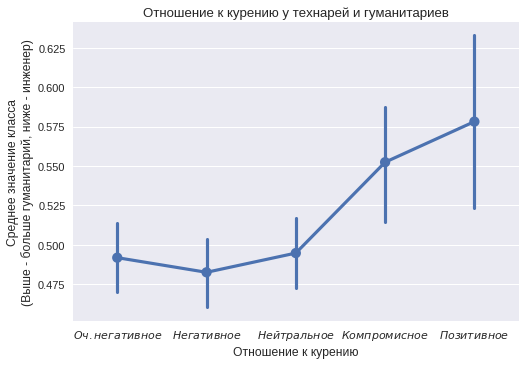
喫煙に関しては、反対の状況が見られます。 人文科学のクラスのユーザーは、喫煙に対する前向きな態度をより頻繁に示します。 すべての値が統計的に有意な値と異なるわけではないことがわかります(一部の信頼区間には値0.5が含まれており、差を示すことができません)が、傾向は依然として興味深いものです。
婚ital状態と人生の主なもの
「婚status状況」に基づいて、「すべてが複雑」と「アクティブな検索」の2つだけに強いバイアスがあります。 どちらも「人文科学」に偏っています。
「人生の主なもの」に基づいて-「美しさと芸術」という1つのことだけに大きな逸脱があり、それは「人文科学」クラスに向けられています。
活動時間
1日のさまざまな時間にユーザーアクティビティの分布を構築します。
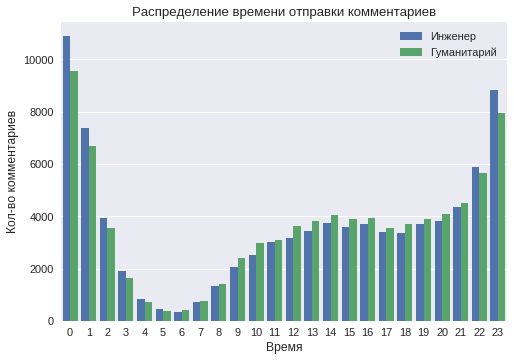
グラフは、夜間(11から2)に「技術者」クラスからのコメントの数がはるかに多いことを示しています。 これは、このクラスのユーザーにとって、より「夜行性」のライフスタイルを示しています。 また、午前5時から6時の間に最も活動が少ないことが確認されています。 それでも、午前4時に始まって、「人道主義」クラスのユーザーからのコメントの数ははるかに多く、立ち上がり時間が早いことを示しています。
コメントの例
さらに分析する前に、コメント自体を確認できます。 以下は、両方のグループのいくつかの例です。
クラス「技術者」:「 アントン、ロックされた車輪の糸を止めたことがありますか?」 停止距離は? 「、」 もちろん、私たちは自分自身をサポートします)21日、労働) 「、」 最初の写真は非常にオリジナルでとても美しいです! 「。
クラス「人文科学」:「 非常にかわいい子猫 '、' =)))) 」、「 私の意見では、すべてのことは子供たちが麻薬についてできる限り知るようにするために行われます。 「、」 あなたの考えの速さに追いついていない))))私は絶望的です。
コメントはさまざまなトピックについて書かれていることがわかります。 カバーされているトピックの違いを見つけることができます。 意味が同じである多くの類似した単語を避けるために、単語を最初の形式に減らす必要があります。 おそらく、使用されている単語の単純な選択でさえ、2つのクラスをうまく分離できます。 また、使用する絵文字、絵文字、句読点にも十分に注意する必要があります。
データの前処理
最初に、長すぎるコメントと短すぎるコメントを選択から削除する必要があります。 それらはモデルの一般化を妨げる可能性があります。 最大長は50ワードに制限され、最小長は3ワードに制限されていました。 次に、スパムを取り除く必要があります。 最初は、サードパーティのサイトへのリンクを含むすべてのコメントが削除されましたが、1%未満でした。 その後、2回以上繰り返されたメッセージは削除されました。これは、スパムでも1%未満であることを意味します。
データには多くのヒットがありました。 コメントでは、彼のページへのリンクを介して特定の人に連絡することができます。 APIを介してダウンロードする場合、名前はユーザーページのIDに置き換えられます。 idに関する情報でモデルを詰まらせないように、また特定の性格の暗記を防ぐために、すべての呼び出しが削除されました。
キャラクター生成
機械学習の問題のデータを分析してクリアした後、機能の構築と選択の段階が始まります。 最終モデルの有用性は、得られる標識の量と質に直接依存します。
テキストの操作を開始する前に、トークン化、つまり単語に分解する必要があります。 これは、 ステミングまたは見出し語化を使用して実行できます。 ステミングは、語の基部の割り当てであり、語尾のリクライニングです。 たとえば、「民主主義」、「民主的」、「民主化」という言葉は、「民主主義」という言葉に与えられています。 語彙化とは、単語を最初の形に還元することです。 前の例の3つの単語はすべて、「民主主義」という単語に還元されます。 この問題では、 pyMorphy2ライブラリーを使用して実行された補題はよりうまく機能しました 。
テキストのベクトル化
ほとんどの機械学習モデルは数値ベクトルを入力として受け入れるため、コメントをベクトルに変換する必要があります。 最も単純なアプローチは単語の袋と呼ばれます。各単語のテキスト内の出現回数をカウントします。 この方法でベクターを取得する前に、ストップワードを削除する必要があります。 これらは非常に一般的で、セマンティックロードを持たない単語です。たとえば、「otherwise」、「this」、「or」などです。
このアプローチでは、文の語順は考慮されません。 「黒猫ではない」と「黒猫ではない」という語句は、同じ単語セットを持っているため、同じベクトルに変換されます。 この問題を解決するには、連続したトークン-N-gramを使用できます。
同じ特徴ベクトルは、シンボルレベルでも構築できます。 テキストはNグラムの文字に分割されます。通常、Nは3に等しいと見なされます。 「森」という言葉は、「森」、「esn」、「夢」、「ノア」に分けられます。 このアプローチには大きな利点があります。トレーニングセットに含まれていない新しい単語に対してより耐性があります。
Tf-Idfは 、テキストのベクトル化にも使用されました。 これは、ドキュメントまたはコーパスのコレクションの一部であるドキュメントのコンテキストで単語の重要性を評価するために使用される統計的尺度です。 特定のドキュメント内で頻度が高く、他のドキュメントで使用される頻度が低い単語には、大きな重みが付きます。 ハブの詳細については、たとえばこちらをご覧ください 。
最近テストされたベクトル化モデルはword2vecです。 ベクトル表現は、コンテキストの近接性に基づいています。ベクトル表現の1つのコンテキストを持つテキストで発生する単語は、座標が近くなります。 インターネットでは、単語をそのベクトルと一致させる大規模なケースで既に訓練されたモデルを見つけることができます。 ハブで動作するword2vecの素晴らしい例
その他の症状
他の証拠源は、コメントの一般的な特性です。 彼らは全体として解説を説明します。
句読点記号:
- 直接のスピーチの存在;
- コンマ、疑問符、感嘆符、ドットの数。
- 「)」、「))」、「((」の形式の笑顔の数。
コンテンツの兆候:
- CapsLockによって書き込まれた単語の割合。
- 英語の単語の割合;
- 文の先頭に大文字が存在する。
一般的な兆候:
- 単語数;
- オファーの数。
- 平均語長;
- 文の平均長。
予測プロセス
標識のベクトルを受け取ったら、モデルのトレーニングに進みます。 1つではなく複数のモデルのアンサンブルを使用することをお勧めします。これにより、精度が向上し、予測の分散が減少します。 いくつかのモデルが構築され、分類する必要のあるオブジェクトごとに調査され、勝者は投票の過半数によって選択されます-単純投票の原則。
ユーザーは80対20の比率で2つの部分に分割されました。最初はトレーニングモデルで、2番目はテストです。 クラスのバランスが取れているため、精度はメトリックとして採用されました。これは、正しく分類された例の数と例の総数の比率です。
最後のタスクはユーザーを分類することですが、分類はテキストコメントに基づいているため、モデルは各コメントを個別に分類します。 ユーザーの予測を行うために、モデルのアンサンブルによってコメントに対して予測される最も頻繁なクラスを発行します。
各モデルは、独自の属性のサブセットでトレーニングされます。 したがって、モデルは外れ値に対してより耐性があり、予測の相関性が低くなり、一般化エラーが最小になります。
中古モデル
線形回帰は、入力フィーチャを線形的に重み付けするモデルです。 線形モデルは、多数のまばらな機能を持つタスクに適しています。テキストのベクトル表現はそれだけです。 記号の前に重みを解釈することもできます。 たとえば、単語のバッグを使用したベクトル化の場合、単語の前にある正の重みは、最初のクラスに属する確率が大きいことを意味します。
多層ニューラルネットワークは、ニューロンを持ついくつかの層で構成されるモデルです。 活性化関数を繰り返し使用するため、ニューラルネットワークは非線形関数であり、理論的にはデータのより複雑な依存関係をキャプチャできます。
リカレントニューラルネットワークは、シーケンス(単語や文字など)をモデリングおよび分析するために特別に作成された一種のニューラルネットワークです。 このモデルを使用すると、特定の兆候の存在だけでなく、その順序も考慮することができます。
ニューラルネットワークの予測は、解釈がはるかに困難です。 良い結果を得るには、ニューロンの数、レイヤーの数、正則化の量など、多くのハイパーパラメーターをソートする必要があります。 ニューラルネットワークのトレーニングには、 Kerasフレームワークが使用されました 。 Habrに関する一連の記事でニューラルネットワークの詳細を読むことができます。
上記の3つのモデルは、さまざまなベクトル化オプションで入力を受け入れます:word bag、Tf-Idf、word2vec。 ワードバッグの技術は、ワードレベルとシンボルレベルの両方で使用されました。 上記のように、モデルが異なるほど、より良いため、異なるハイパーパラメーターを持つ同じモデルの複数のバージョンが選択されました。
最新のモデルは勾配木ブースティングです。 このアルゴリズムは、量的属性とカテゴリ属性を操作するときに良い結果を示します。 以前のモデルとは異なり、彼女は解説の一般的な特性(コンマの数、平均語長、およびその他の統計)を研究しました。 XGBoostライブラリが使用されました 。
検証を使用して、ユーザーレベルで最高の品質を示すモデルが選択されました。 彼らは最終アンサンブルに入りました。 モデル予測間の相関も分析しました。
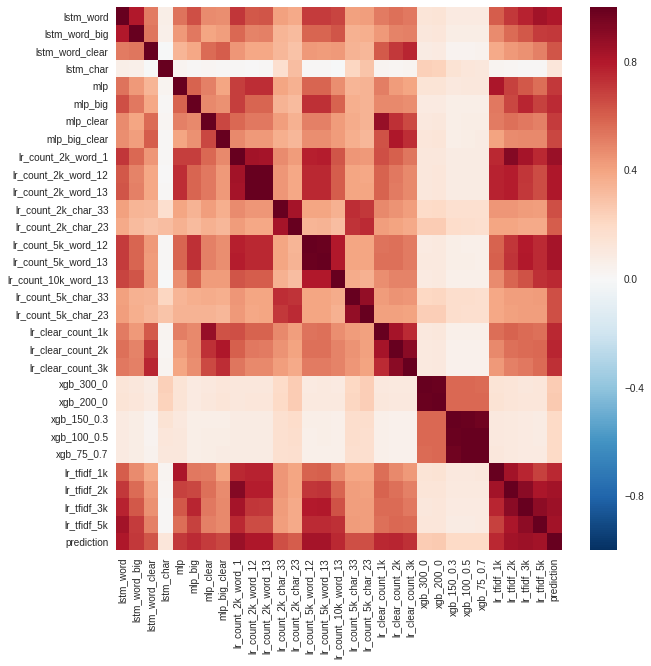
勾配ブースティング(xgb)モデルとシンボルレベルのリカレントネットワーク(lstm_char)の予測が最も異なっていたことにお気づきかもしれません。 文字列予測は、すべてのモデルの集合です。
モデルは、正確さだけでなく、無相関の予測のためにもアンサンブルに選択されました。 2つのモデルの精度が同じで、非常に類似している場合、それらを平均化しても意味がありません。
結果
最終モデルの品質は、単一のユーザーを分類するために使用されるコメントの最小数に依存します。 理論的には、コメントが多いほど良いです。
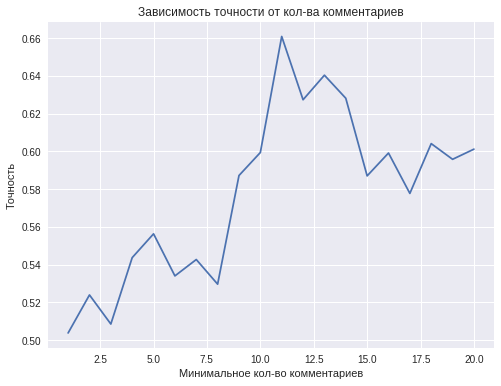
ただし、1人からのコメントの最小数が増えると、一定以上のコメントを持つ人の数、つまり トレーニングサンプルのサイズが縮小されます。 たとえば、約4,000人のユーザーが2つ以上のコメントを持ち、1,000人未満のユーザーが10以上のコメントを持っている場合、1人のユーザーのコメント数が11以上になると分類精度が低下します。
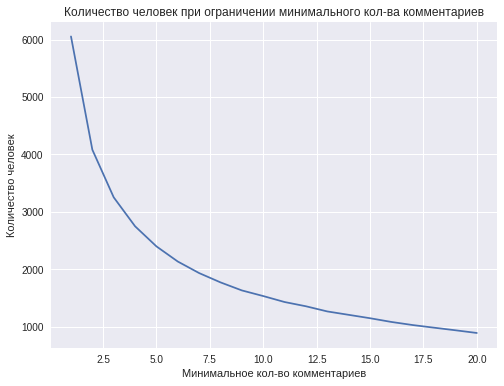
0.66の最高の精度は、1人からの11個のコメントを使用して達成されます。 この結果は、分類問題の成功した解決策について語るのに十分ではありませんが、それにもかかわらず、この精度は、コインを投げることによる予測の品質を超えています。 より多くのデータを収集することで、さらに結果を改善できます。
コメントの単語を直接使用しないグラデーションブースティングモデルの最も重要な機能は次のとおりです。
- 平均語長;
- 単語数;
- コメント内の英単語のシェア;
- 感嘆符の使用。
eli5ライブラリを使用して、テキストの上でワードバッグとして機能する線形モデルの予測を視覚化します。


キャラクターレベル:


予測されたクラスに最大の貢献をする単語と記号は緑色で強調表示され、反対のクラスに貢献する単語と記号は赤色で強調表示されます。 y = 1は、モデルが人文科学クラスを予測することを意味します。y= 0-技術者。
Webサービス
動作を実証するために、モデルをWebサービスとしてデプロイしました。 Flaskはバックエンドとして使用され、Bootstrapを使用してシンプルなデザインが作成され、Herokuはホスティングに使用されました。 www.commentsanalysis.ruで試すことができます。
重要な制限は、1つの予測の形成時間でした。 このため、アンサンブルに最適な5つの線形モデルのみを残すことにしました。
このサイトには4つの主要なブロックがあります。簡単な指示、ランダムなコメントのあるフィールド、ユーザーのコメントを入力するフィールド、分類結果のあるフィールドです。 少なくとも5つのコメントを入力すると、結果を予測できます。
システムが開発および起動されたので、そのアプリケーションについて考えることができます。 たとえば、技術学部の人文科学の学生は、より適切な学部に自動的に転送できます。
GitHubへのリンク。
PS:テキストを編集してくれてありがとう。