
記事「 ニューラルネットワークによる白黒写真の色付け」の翻訳。
少し前まで、Amir Avniはニューラルネットワークを使用して、/ r / ColorizationブランチをRedditにトローリングしました。 誰もがニューラルネットワークの品質に驚きました。 最大1か月の手作業が数秒で完了します。
Amirの画像処理プロセスを再現して文書化しましょう。 最初に、いくつかの成果と失敗(一番下-最新バージョン)を見てください。

Unsplashから撮影したオリジナルの白黒写真 。
現在、白黒写真は通常、Photoshopで手動でペイントされます。 このビデオを見て、このような作業の膨大な複雑さを理解してください。
1つの画像を色付けするのに1か月かかる場合があります。 私たちはその時代にさかのぼる多くの歴史的な資料を研究しなければなりません。 最大20層のピンク、緑、青の影が顔だけに重ねられ、適切な陰影が得られます。
この記事は初心者向けです。 ニューラルネットワークの深層学習の用語に慣れていない場合は、以前の記事( 1、2 )を読んで、Andrey Karpaty による講義を見ることができます。
この記事では、画像を3段階で着色するための独自のニューラルネットワークを構築する方法を学習します。
最初の部分では、基本的なロジックを扱います。 40行のニューラルネットワークフレームワークを構築しましょう。これはカラーリングボットの「アルファ版」になります。 このコードにはほとんど謎がありません;構文に慣れるのに役立ちます。
次のステップでは、一般化ニューラルネットワーク(「ベータ版」)を作成します。 彼女はすでに彼女に馴染みのない画像を色付けすることができます。
「最終」バージョンでは、ニューラルネットワークと分類器を組み合わせます。 これを行うには、120万枚の画像でトレーニングされたInception Resnet V2を使用します。 そして、ニューラルネットワークにUnsplashで画像を色付けする方法を教えます。
待ちきれない場合は、ボットのアルファ版を含むJupyterノートブックをご覧ください 。 FloydHubとGitHubには3つのバージョンがあり、FloydHubサービスのクラウドビデオカードで行われたすべての実験で使用されたコードも確認できます。
基本的なロジック
このセクションでは、画像のレンダリングを検討し、デジタルカラーの理論とニューラルネットワークの基本ロジックについて説明します。
白黒画像は、ピクセルのグリッドとして表すことができます。 各ピクセルには、黒から白まで、0から255の範囲の輝度値があります。

カラー画像は、赤、緑、青の3つのレイヤーで構成されています。 3つのチャネルで、白い背景に緑の葉のある画像を広げたいとします。 葉は緑のレイヤーでのみ表示されると思うかもしれません。 しかし、ご覧のように、レイヤーは色だけでなく輝度も決定するため、3つのレイヤーすべてにあります。

たとえば、白を取得するには、すべての色の均等な分布を取得する必要があります。 同じ量の赤と青を追加すると、緑が明るくなります。 つまり、3つのレイヤーを使用するカラー画像では、色とコントラストがエンコードされます。

白黒画像の場合と同様に、カラー画像の各レイヤーのピクセルには0〜255の値が含まれます。ゼロは、このレイヤーでこのピクセルに色がないことを意味します。 3つのチャネルすべてにゼロがある場合、結果は画像の黒いピクセルになります。
ご存じのとおり、ニューラルネットワークは入力値と出力値の関係を確立します。 この場合、ニューラルネットワークは、白黒画像とカラー画像の間の接続機能を見つける必要があります。 つまり、白黒グリッドの値と3色のグリッドの値を比較できるプロパティを探しています。

f()はニューラルネットワーク、[B&W]は入力データ、[R]、[G]、[B]は出力データです。
アルファ版
最初に、女性の顔を着色するニューラルネットワークの簡単なバージョンを作成します。 新しい機能を追加すると、モデルの基本的な構文に慣れることができます。
40行のコードの場合、左の画像(白黒)から、ニューラルネットワークによって作成された中央の画像に移動します。 右の写真は、白黒を作成した元の写真です。 ニューラルネットワークは1つの画像でトレーニングおよびテストされました。これについてはベータセクションで説明します。

色空間
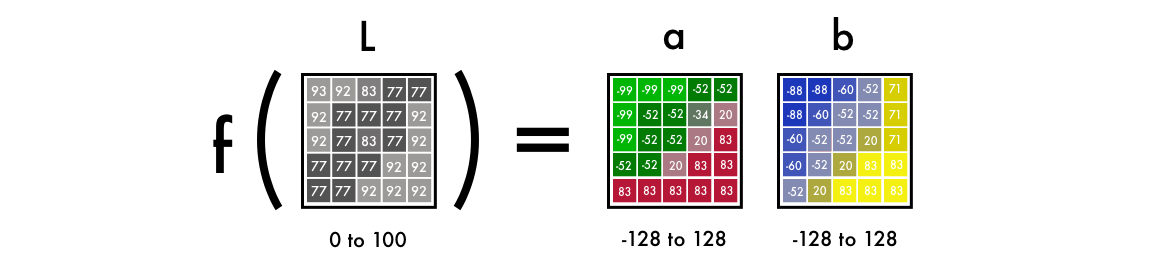
まず、カラーチャンネルをRGBからLabに変更するアルゴリズムを使用します。 Lは明度を意味し、 aとbはそれぞれ緑から赤、青から黄色の範囲の色の位置を決定するデカルト座標です。
ご覧のとおり、Labスペースの画像にはグレースケールの1つのレイヤーが含まれており、3つのカラーレイヤーは2つにまとめられています。 したがって、最終イメージでは元の白黒バージョンを使用できます。 さらに2つのチャネルを計算する必要があります。

科学的事実:目の網膜受容体の94%が明るさの決定に関与しています。 また、色を認識する受容体はわずか6%です。 したがって、あなたにとっては、白黒画像はカラーレイヤーよりもはるかにはっきりと見えます。 これが、最終バージョンでこの画像を使用するもう1つの理由です。
グレースケールからカラーへ
入力として、グレースケールを持つレイヤーを取得し、それに基づいてLabカラースペースでカラーレイヤーaおよびbを生成します。 最終画像のLレイヤーとして使用します。
1つのレイヤーから2つのレイヤーを取得するには、畳み込みフィルターを使用します。 これらは、3Dメガネで青と赤のメガネとして表すことができます。 フィルターは、写真に表示されるものを決定します。 私たちの目が必要な情報を抽出できるように、画像の一部に下線を引くか隠すことができます。 ニューラルネットワークはフィルターを使用して、新しい画像を作成したり、複数のフィルターを1つの画像に組み合わせたりすることもできます。
畳み込みニューラルネットワークでは、各フィルターは自動的に調整され、目的の出力を取得しやすくなります。 数百のフィルターを追加し、それらをまとめてレイヤーaおよびbを取得します。
コードの仕組みの詳細に入る前に、それを実行しましょう。
FloydHubにコードをデプロイする
FloydHubを使用したことがない場合でも、 インストールを開始して、 5分間のビデオチュートリアルまたは詳細な手順をご覧ください。 FloydHubは、クラウドグラフィックスカードを深くモデル化するための最良かつ最も簡単な方法です。
アルファ版
FloydHubをインストールしたら、次のコマンドを入力します。
git clone https://github.com/emilwallner/Coloring-greyscale-images-in-Keras
次に、フォルダーを開き、FloydHubを初期化します。
cd Coloring-greyscale-images-in-Keras/floydhub
floyd init colornet
FloydHub Webパネルがブラウザーで開きます。 colornetという新しいFloydHubプロジェクトを作成するように求められます。 作成したら、ターミナルに戻り、同じ初期化コマンドを発行します。
floyd init colornet
タスクを実行します。
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
いくつかの説明:
- このコマンドを使用して、FloydHubにパブリックデータセットをマウントしました。
--dataemilwallner/datasets/colornet/2:data
FloydHubでは、 これや他の多くのパブリックデータセットを表示して使用できます。 - --tensorboardで
--tensorboard
有効にする - コマンドを使用してJupyter Notebookモードでタスクを起動しました
--mode jupyter
ビデオカードをタスクに接続できる場合は、
–gpu
フラグを追加します。 約50倍速くなります。
Jupyter Notebookに移動します。 FloydHub Webサイトの[ジョブ]タブで、Jupyter Notebookリンクをクリックしてファイルを見つけます。
floydhub/Alpha version/working_floyd_pink_light_full.ipynb
ファイルを開き、すべてのセルでShift + Enterを押します。
エポック値を徐々に増やして、ニューラルネットワークがどのように学習しているかを理解します。
model.fit(x=X, y=Y, batch_size=1, epochs=1)
エポック= 1から始めて、10、100、500、1000、および3000に増やします。この値は、ニューラルネットワークが画像でトレーニングされた回数を示します。 ニューラルネットワークをトレーニングするとすぐに、メインフォルダーにimg_result.pngファイルが見つかります。
# Get images
image = img_to_array(load_img('woman.png'))
image = np.array(image, dtype=float)
# Import map images into the lab colorspace
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
Y = Y / 128
X = X.reshape(1, 400, 400, 1)
Y = Y.reshape(1, 400, 400, 2)
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
# Building the neural network
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
# Finish model
model.compile(optimizer='rmsprop',loss='mse')
#Train the neural network
model.fit(x=X, y=Y, batch_size=1, epochs=3000)
print(model.evaluate(X, Y, batch_size=1))
# Output colorizations
output = model.predict(X)
output = output * 128
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
imsave("img_result.png", lab2rgb(canvas))
imsave("img_gray_scale.png", rgb2gray(lab2rgb(canvas)))
このネットワークを実行するFloydHubコマンド:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技術的な説明
入り口に、白黒の画像を表すグリッドがあることを思い出してください。 出力には、色の値を持つ2つのグリッドがあります。 入力値と出力値の間で、リンクフィルターを作成しました。 畳み込みニューラルネットワークがあります。
ネットワークをトレーニングするために、カラー画像が使用されます。 RGBからLabに変換しました。 白黒レイヤーが入力に送られ、出力により2つのカラーレイヤーが生成されます。

1つの範囲で、計算された値を実際の値と比較(マップ)し、それによって互いに比較します。 範囲の境界は-1〜1です。計算値を比較するには、tanhアクティベーション関数(双曲線タンジェンシャル)を使用します。 値に適用すると、関数は-1〜1の範囲の値を返します。
実際の色の値は、-128〜128です。ラボスペースでは、これがデフォルトの範囲です。 各値を128で除算すると、それらはすべて–1〜1の範囲になります。この「正規化」により、計算の誤差を比較できます。
結果の誤差を計算した後、ニューラルネットワークはフィルターを更新して、次の反復の結果を調整します。 エラーが最小になるまで、手順全体が周期的に繰り返されます。
このコードの構文を見てみましょう。
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
1.0 / 255は、24ビットRGB色空間を使用することを意味します。 つまり、各カラーチャネルに対して、0〜255の範囲の値を使用します。これにより、1670万色が得られます。
しかし、人間の目は200〜1000万色しか認識できないため、より広い色空間を使用しても意味がありません。
Y = Y / 128
ラボの色空間は異なる範囲を使用します。 カラースペクトルabは-128〜128の範囲で変化します。出力レイヤーのすべての値を128で除算すると、-1〜1の範囲に収まり、これらの値をニューラルネットワークで計算された値と比較できます。
rgb2lab()
関数を使用して色空間を変換した後、 [:、:、0]を使用して白黒レイヤーを選択します。 これは、ニューラルネットワークへの入力です。 [:、:、1:]は、赤緑と青黄色の2つのカラーレイヤーを選択します。
ニューラルネットワークをトレーニングした後、最後の計算を実行し、それを画像に変換します。
output = model.predict(X)
output = output * 128
ここでは、白黒画像をフィードし、訓練されたニューラルネットワークを介してそれを駆動します。 -1から1までのすべての出力値を取得し、128で乗算します。したがって、Labシステムで正しい色を取得します。
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
黒のRGBキャンバスを作成し、3つのレイヤーすべてをゼロで埋めます。 次に、テスト画像から白黒レイヤーをコピーし、2つのカラーレイヤーを追加します。 結果のピクセル値の配列は画像に変換されます。
アルファ版に取り組んでいるときに学んだこと
- 研究論文を読むのは大変です。 しかし、記事の主要な規定を要約する価値があり、それらを研究するのが容易になりました。 また、この記事にいくつかの詳細を含めるのに役立ちました。
- あなたは小さく始める必要があります。 ネットワークで見つかった実装のほとんどは、2〜1万行のコードで構成されていました。 これにより、基本的なロジックを理解することが非常に難しくなります。 しかし、手元に単純化された基本バージョンがある場合は、実装と研究論文の両方を読む方が簡単です。
- 他の人のプロジェクトを理解するのを怠らないでください 。 コードの内容を判断するには、Githubで多数の画像カラーリングプロジェクトを検討する必要がありました。
- すべてが意図したとおりに機能するとは限りません 。 おそらく最初は、ネットワークで作成できるのは赤と黄色のみです。 初めて、最終的なアクティベーションにReluのアクティベーション機能を使用しました。 しかし、それは正の値のみを生成するため、青と緑のスペクトルにはアクセスできません。 Y軸に沿って値を変換するtanhアクティベーション機能を追加することにより、この欠点を解決することができました。
- 理解>スピード 。 私たちが見た実装の多くはすぐに実行されましたが、それらを操作することは困難でした。 そのため、実行ではなく、新しい機能を追加する速度についてコードを最適化することにしました。
ベータ版
彼女が訓練されていない画像を色付けするアルファ版を提供し、このバージョンの主な欠点が何であるかをすぐに理解してください。 彼女はそれを処理できません。 実際、ニューラルネットワークは情報を記憶していました。 彼女は、なじみのない画像に色を付ける方法を学びませんでした。 そして、ベータ版で修正します-ニューラルネットワークに一般化を教えます。
以下は、ベータ版がどのようにテスト画像を着色したかを示しています。
Imagenetを使用する代わりに、FloydHub上に、より優れた画像を含むパブリックデータセットを作成しました 。 それらは、プロの写真家の写真がレイアウトされているUnsplashから取得されます。 データセットには9500のトレーニング画像と500のテスト画像があります。

機能ハイライター
ニューラルネットワークは、白黒画像とカラーバージョンを接続する特性を探しています。
白黒の写真を色付けする必要があると想像してください。ただし、画面上で一度に表示できるのは9ピクセルだけです。 各画像を左から右、上から下に表示して、各ピクセルの色を計算できます。

これらの9つのピクセルを女性の鼻孔の端に置きます。 ご理解のとおり、ここで適切な色を選択することはほとんど不可能であるため、問題の解決策を段階的に分割する必要があります。
まず、単純な特徴的な構造を探しています:斜めの線、黒いピクセルのみなど。 9ピクセルの各正方形で、同じ構造を探し、それに対応しないものをすべて削除します。 その結果、64個のミニフィルターから64個の新しい画像を作成しました。

各段階で処理された画像フィルターの数。
もう一度画像を見ると、すでに特定した同じ小さな繰り返し構造が見つかります。 画像をよりよく分析するには、サイズを半分に減らします。

3段階でサイズを縮小します。
各画像をスキャンする必要がある3x3フィルターがまだあります。 しかし、単純なフィルターを新しい9ピクセルの正方形に適用すると、より複雑な構造を検出できます。 たとえば、半円、小さな点、または線。 繰り返しますが、画像に同じ繰り返し構造があります。 今回は、フィルターで処理された128の新しい画像を生成します。
いくつかの手順を実行すると、フィルターによって処理される画像は次のようになります。

繰り返すには、エッジなどの単純なプロパティを探すことから始めます。 処理すると、レイヤーは構造に、さらに複雑な機能に結合され、最終的には顔が得られます。 詳細については、このビデオで説明しています。
説明されているプロセスは、コンピュータービジョンアルゴリズムに非常に似ています。 ここでは、いくつかの処理された画像を組み合わせて画像全体の内容を理解する、いわゆる畳み込みニューラルネットワークを使用します。
プロパティの抽出から色へ
ニューラルネットワークは試行錯誤の原則に基づいて動作します。 まず、彼女はランダムに各ピクセルに色を割り当てます。 次に、ピクセルごとにエラーを計算し、フィルターを調整して、次の試行で結果を改善しようとします。
ニューラルネットワークは、最大のエラー値を持つ結果から開始して、フィルターを調整します。 この場合、ニューラルネットワークは、色を付けるかどうか、および画像内のさまざまなオブジェクトをどのように配置するかを決定します。 最初に、彼女はすべてのオブジェクトを茶色でペイントします。 この色は他のすべての色に最も似ているため、使用するとエラーが最小になります。
トレーニングデータの均一性により、ニューラルネットワークはさまざまなオブジェクト間の違いを理解しようとしています。 彼女はまだより正確な色合いを計算することはできません。ニューラルネットワークのフルバージョンを作成するときにこれに対処します。
ベータコードは次のとおりです。
# Get images
X = []
for filename in os.listdir('../Train/'):
X.append(img_to_array(load_img('../Train/'+filename)))
X = np.array(X, dtype=float)
# Set up training and test data
split = int(0.95*len(X))
Xtrain = X[:split]
Xtrain = 1.0/255*Xtrain
#Design the neural network
model = Sequential()
model.add(InputLayer(input_shape=(256, 256, 1)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
model.add(UpSampling2D((2, 2)))
# Finish model
model.compile(optimizer='rmsprop', loss='mse')
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
# Generate training data
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
# Train model
TensorBoard(log_dir='/output')
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=10000, epochs=1)
# Test images
Xtest = rgb2lab(1.0/255*X[split:])[:,:,:,0]
Xtest = Xtest.reshape(Xtest.shape+(1,))
Ytest = rgb2lab(1.0/255*X[split:])[:,:,:,1:]
Ytest = Ytest / 128
print model.evaluate(Xtest, Ytest, batch_size=batch_size)
# Load black and white images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = rgb2lab(1.0/255*color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict(color_me)
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))
ニューラルネットワークのベータ版を起動するFloydHubコマンド:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技術的な説明
画像を処理する他のニューラルネットワークとは異なり、ピクセルの位置が重要です。 カラーニューラルネットワークでは、画像サイズまたはアスペクト比は変更されません。 また、他のタイプのネットワークでは、最終バージョンに近づくにつれて画像がゆがみます。
分類ネットワークで使用される最大機能を備えたプーリング層は、情報の密度を高めますが、同時に画像を歪めます。 画像レイアウトではなく、情報のみを評価します。 また、カラーネットでは、幅と高さを半分に減らすために、ステップ2(2のストライド)を使用します。 情報の密度も増加していますが、画像は歪んでいません。

また、ニューラルネットワークは、画像のアスペクト比をアップサンプリングおよび維持する他のレイヤーとは異なります。 分類ネットワークは最終分類のみを対象とするため、ニューラルネットワークを通過する画像のサイズと品質が徐々に低下します。
カラーリングニューラルネットワークは、画像のアスペクト比を変更しません。 これを行うには、上の図のように、
*padding='same'*
パラメーターを使用して白いフィールドを追加します。 そうしないと、各畳み込みレイヤーが画像をトリミングします。
画像のサイズを2倍にするために、カラーリングニューラルネットワークはアップサンプリングレイヤーを使用します。
for filename in os.listdir('/Color_300/Train/'):
X.append(img_to_array(load_img('/Color_300/Test'+filename)))
この
for-loop
最初にディレクトリ内のすべてのファイルの名前を計算し、ディレクトリを通過してすべての画像をピクセルの配列に変換し、最後にそれらを巨大なベクトルに結合します。
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
ImageDataGeneratorを使用して、イメージジェネレーターを有効にできます。 その後、各画像は前の画像とは異なるため、ニューラルネットワークのトレーニングが高速化されます。
shear_range
は、画像を左または右に傾ける
shear_range
ます。また、ズームイン、回転、または水平方向に反転することもできます。
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
これらの設定をXtrainフォルダー内の画像に適用し、新しい画像を生成します。 次に、
X_batch
白黒レイヤーと2色のレイヤーの2色を抽出します。
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=1, epochs=1000)
ビデオカードが強力であればあるほど、より多くの写真を同時に処理できます。 たとえば、説明したシステムは50〜100個の画像を処理できます。 steps_per_epochパラメーターの値は、トレーニングイメージの数をバッチサイズで除算することによって取得されます。
たとえば、100枚の写真があり、シリーズサイズが50の場合、期間内に2つのステージがあります。 期間の数によって、すべての画像でニューラルネットワークをトレーニングする回数が決まります。 1万枚の写真と21の期間がある場合、Tesla K80グラフィックカードでは約11時間かかります。
学んだこと
- 最初に、小さなシリーズでさらに実験を行い、次に大規模な実行に進むことができます 。 20〜30回の実験の後でもエラーが発生しました。 何かが実行されている場合、それが機能しているという意味ではありません。 通常、ニューラルネットワークのバグは、従来のプログラミングエラーよりも目立ちません。 たとえば、最も奇妙なバグの1つはAdam hiccupでした。
- データセットが多様であるほど、画像の茶色が多くなります 。 データセットに非常に類似した画像がある場合、ニューラルネットワークは、より複雑なアーキテクチャを使用しなくてもかなりうまく機能します。 しかし、そのようなニューラルネットワークはさらに一般化されます。
- フォーム、フォーム、もう一度フォーム 。 画像のサイズは、ニューラルネットワークの作業全体にわたって正確で、互いに比例している必要があります。 最初に、300ピクセルの画像を使用し、次にそれを半分、つまり150、75、35.5ピクセルに数回縮小しました。 後者のバージョンでは、2ピクセル、4ピクセル、8ピクセル、16ピクセル、32ピクセル、64ピクセル、256ピクセルなどを使用する方が良いという結論に達するまで、松葉杖の束を置き換える必要があったため、半分のピクセルが失われました。
- データセットの作成 :a).DS_Storeファイルを無効にします。そうしないと、夢中になります。 b)発明を表現してください。 ファイルをダウンロードするために、Chromeのコンソールスクリプトと拡張機能を使用しました。 c) クリーニング用のスクリプトを処理および編成するソースファイルのコピーを作成します。
ニューラルネットワークのフルバージョン
カラーリングニューラルネットワークの最終バージョンには、4つのコンポーネントが含まれています。 以前のネットワークをエンコーダーとデコーダーに分割し、それらの間にフュージョンレイヤーを配置しました。 ニューラルネットワークの分類に慣れていない場合は、 http : //cs231n.github.io/classification/のガイドを読むことをお勧めします。
入力データは、エンコーダーと最も強力な最新の分類器であるInception ResNet v2を同時に通過します。 これは120万枚の画像で訓練されたニューラルネットワークです。 分類レイヤーを抽出し、エンコーダーの出力と結合します。
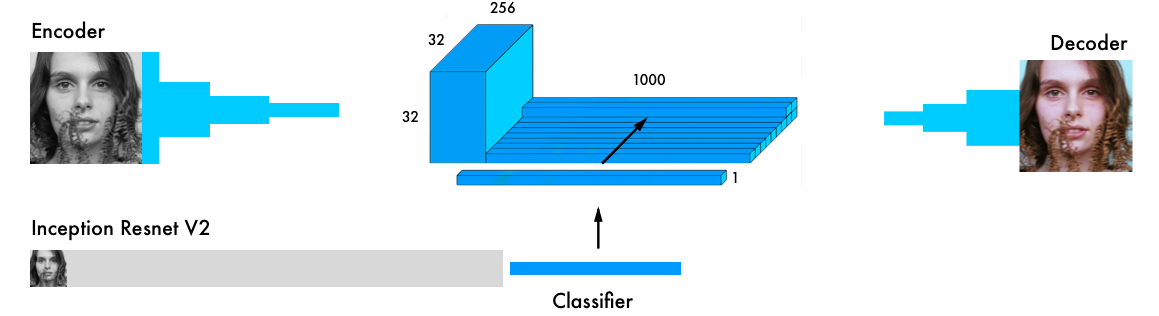
より詳細な視覚的説明: https : //github.com/baldassarreFe/deep-koalarization
分類器からカラーリングネットワークにトレーニングを転送すると、写真に示されている内容を理解できるため、オブジェクトの表現をカラーリングスキームと比較できます。
ここにいくつかのテスト画像がありますが、ネットワークのトレーニングには20枚の写真しか使用されていません。

ほとんどの写真は曲がって描かれています。 しかし、大きなテストセット(2500個の画像)のおかげで、いくつかのまともなものがあります。 より大きなサンプルでネットワークをトレーニングすると、より安定した結果が得られますが、それでも写真の大部分は茶色になっています。 以下に、 実験とテスト画像の完全なリストを示します。
さまざまな研究からの最も一般的なアーキテクチャ:
- ネットワークにヒント( リンク )を与えるために、画像に小さな色のドットを手動で追加します。
- 同様の画像を見つけて、そこから色を転送します(詳細はこちらとこちら )。
- 残差エンコーダー層とマージ分類層( リンク )。
- 分類ネットワークのハイパーカラムを組み合わせます(詳細はこちらとこちら )。
- エンコーダーとデコーダーの最終的な分類を組み合わせます (詳細はこちらとこちら )。
色空間 :ラボ、YUV、HSV、およびLUV(詳細はこちらとこちら )
損失 :標準誤差、分類、加重分類( 参照 )。
最良の結果が得られるため、「マージレイヤー」(リストの5番目)を持つアーキテクチャを選択しました。 また、 Kerasで理解しやすく、再現しやすくなっています。 これは最強のアーキテクチャではありませんが、最初は十分でしょう。
ニューラルネットワークの構造は、 Federico Baldasarreと彼の同僚の研究から借用されており、Kerasと連携するようになっています。 注:このコードはKerasシーケンシャルモデルの代わりに機能APIを使用します。 [ ドキュメント ]
# Get images
X = []
for filename in os.listdir('/data/images/Train/'):
X.append(img_to_array(load_img('/data/images/Train/'+filename)))
X = np.array(X, dtype=float)
Xtrain = 1.0/255*X
#Load weights
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()
embed_input = Input(shape=(1000,))
#Encoder
encoder_input = Input(shape=(256, 256, 1,))
encoder_output = Conv2D(64, (3,3), activation='relu', padding='same', strides=2)(encoder_input)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
#Fusion
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([encoder_output, fusion_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu', padding='same')(fusion_output)
#Decoder
decoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(fusion_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(64, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(32, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(16, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(2, (3, 3), activation='tanh', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)
#Create embedding
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.4,
zoom_range=0.4,
rotation_range=40,
horizontal_flip=True)
#Generate training data
batch_size = 20
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
X_batch = X_batch.reshape(X_batch.shape+(1,))
Y_batch = lab_batch[:,:,:,1:] / 128
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
#Train model
tensorboard = TensorBoard(log_dir="/output")
model.compile(optimizer='adam', loss='mse')
model.fit_generator(image_a_b_gen(batch_size), callbacks=[tensorboard], epochs=1000, steps_per_epoch=20)
#Make a prediction on the unseen images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = 1.0/255*color_me
color_me = gray2rgb(rgb2gray(color_me))
color_me_embed = create_inception_embedding(color_me)
color_me = rgb2lab(color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict([color_me, color_me_embed])
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))
ニューラルネットワークのフルバージョンを実行するFloydHubコマンド:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboard
技術的な説明
Keras機能APIは 、複数のモデルを連結または結合するのに最適です。
最初に、 Inception ResNet v2ニューラルネットワークをダウンロードし、ウェイトをロードします。 2つのモデルを同時に使用するため、どちらを決定する必要があります。 これは、 Tensorflow 、Kerasバックエンドで行われます。
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()
補正された画像からシリーズ(バッチ)を作成しましょう。 それらをb / wに変換し、Inception ResNetモデルで実行します。
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)
最初に、写真をサイズ変更してモデルをフィードする必要があります。 次に、プリプロセッサを使用して、ピクセルと値の色を目的の形式にします。 最後に、Inceptionネットワークを介して画像を駆動し、モデルの最終層を抽出します。
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed
ジェネレーターに戻りましょう。 各シリーズについて、以下に説明する形式の20個の画像を生成します。 Tesla K80 GPUには約1時間かかりました。 このモデルを使用すると、このビデオカードはメモリの問題なしに一度に最大50個の画像を生成できます。
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
これは、カラーネットモデルの形式と一致します。
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)
encoder_inputis
Encoderモデルに渡され、その出力は
embed_inputin
マージレイヤーに
embed_inputin
ます。 マージ出力はDecoderモデルの入力に送られ、Decoderモデルは最終データである
decoder_output
を返します。
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([fusion_output, encoder_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu')(fusion_output)
マージレイヤーでは、最初に1000カテゴリのレイヤー(1000カテゴリーレイヤー)に1024(32 * 32)を掛けます。 したがって、Inceptionモデルから最終層の1024行を取得します。 32 x 32グリッドは、2次元から3次元の表現に変換され、1000列のカテゴリー(カテゴリーの柱)があります。 その後、列はエンコーダモデルの出力にリンクされます。 254個のフィルターと1x1コアを含む畳み込みネットワークをマージレイヤーの最終結果に適用します。
学んだこと
- 研究用語は威圧的でした。 Kerasで「合併モデル」を実装する方法を探すために3日間を費やしました。 とても複雑に聞こえるので、単純にこのタスクを引き受けたくありませんでした。作業を促進するアドバイスを見つけようとしました。
- ネットに関する質問 。 Keras Slackチャンネルにはコメントが1つもありませんでした。StackOverflowでは、質問が削除されました。 しかし、簡単な答えを探して問題を公に分析し始めたとき、この問題を解決する方法が明らかになりました。
- メーリングリスト 。 あなたはフォーラムで無視されるかもしれませんが、あなたが人々に直接連絡すれば、彼らはより敏感になります。 Skypeの研究者と色空間を扱うことについての議論に励まされました!
- マージの問題を解決するのが困難だったため、最初にすべてのコンポーネントを記述し、次にそれらを互いに組み合わせることにしました。ここにいくつかのマージレイヤー分割実験があります。
- 一部のコンポーネントが動作するように思われる場合、それについて確実性はありませんでした。基本的なロジックが完全に揃っていることは知っていましたが、機能するとは信じていませんでした。レモンティーと長い散歩の後、私たちは始めることにしました。モデルの最初の行にエラーが表示されました。しかし、4日後、数百のバグとGoogleへの数千のリクエストにより、モデルの動作中に切望されていた「エポック1/22」が登場しました。
次は何ですか
— . , . , . :
- .
- .
- , .
- (amplifier) RGB. , , .
- .
- . , . «».
- FloydHub.
- - woman.jpg ( 400x400 ).
- - Test, FloydHub-. Notebook Test, . 256x256 . , -.