どうしてですか。 理由がありました:TopConfカンファレンスのオープニングで小さなパフォーマンスをすること。
こんにちは、私の名前はAlexander Tavgenです。 私はPlaytechのアーキテクトであり、今でもDesignerをプレイしています。 確かに、デザイナーはもう少し複雑です。
私は音楽と車を、ロシアのエストニア劇場の作曲家および音楽プロデューサーであるアレクサンダー・ゼデレフ、別名フェールシュテインに接続することを提案しました。 むしろ、 MODULSHTEINプロジェクト(Alexander Zhedelev、Martin AltrovおよびAlexei Seminikhin) 。 長い間、MIDIとcharベースのモデルを組み合わせようとすることは私の心に暗黙のうちに考えられてきました。 私たちはPlaytechから非常によく支えられました。彼女はとても感謝しています。 その試みを実現するのに約2か月かかりました。 そして、これは私たちがさまざまな都市に住んでいて、主な職業で働いていることを考えると、ごくわずかです。
この点で、Andrej Karpathy による有名な記事は、リカレントニューラルネットワークの背後にある原理の優れた紹介であり、優れた例があります。 Linuxソースコードでトレーニングされた唯一のネットワークは何ですか? または、私が春に書いたドナルド・トランプのスピーチで訓練されたモデル 。
一般的に、リカレントニューラルネットワークは、特定の構造を持つ時間データに対して非常に満足のいく結果を示します。
言語を取る。 言語の構造にはいくつかの次元があります。 それらの1つはセマンティックであり、これに対してマシンのみが選択されます。 たとえば、 Searleの「中国の部屋」の議論は、 マルチモーダル学習に関してそれほど説得力がないように見えます。
別の次元である構文は、すでに非常に優れています。 再帰的ニューラルネットワークは、以前のコンテキストを考慮して状態を保存できます。 そして、実際に観察するのは楽しかったですが、それについては以下で詳しく説明します。 モデルに大量のテキストをフィードし、次の文字を受け取る可能性を予測するように依頼することができます。 たとえば、「I lov」という文字の後には「e」が存在する可能性が非常に高いが、「I love」という文字の後には、もはや明らかではない-「y」、「h」など
原則として、音楽には特定の構造があります。 これは、リズム、間隔、ダイナミクスです。 特定のシンボルのセットとして音楽シーケンスをシミュレートする場合、リカレントニューラルネットワークはこれに最適です。 MIDIファイル形式はこれに最適です。 これを行う方法を考えていて、PythonのMIDIライブラリに注目していると、Magentaプロジェクトに出会いました。
本質的に、マゼンタはTensorFlowモデル用のMIDIインターフェイスを提供します。 仮想MIDIポートは、大まかに言えば、入力と出力の呼び出し応答用に作成されます。 複数のパラレルポートを実行できます。 TensorFlowモデルをポートの各ペアに接続できます。 いわゆるバンドルファイルは、TensorFlowのトレーニングチェックポイントとグラフメタデータです。 簡単に説明すると、対話プロセスは次のように説明できます。
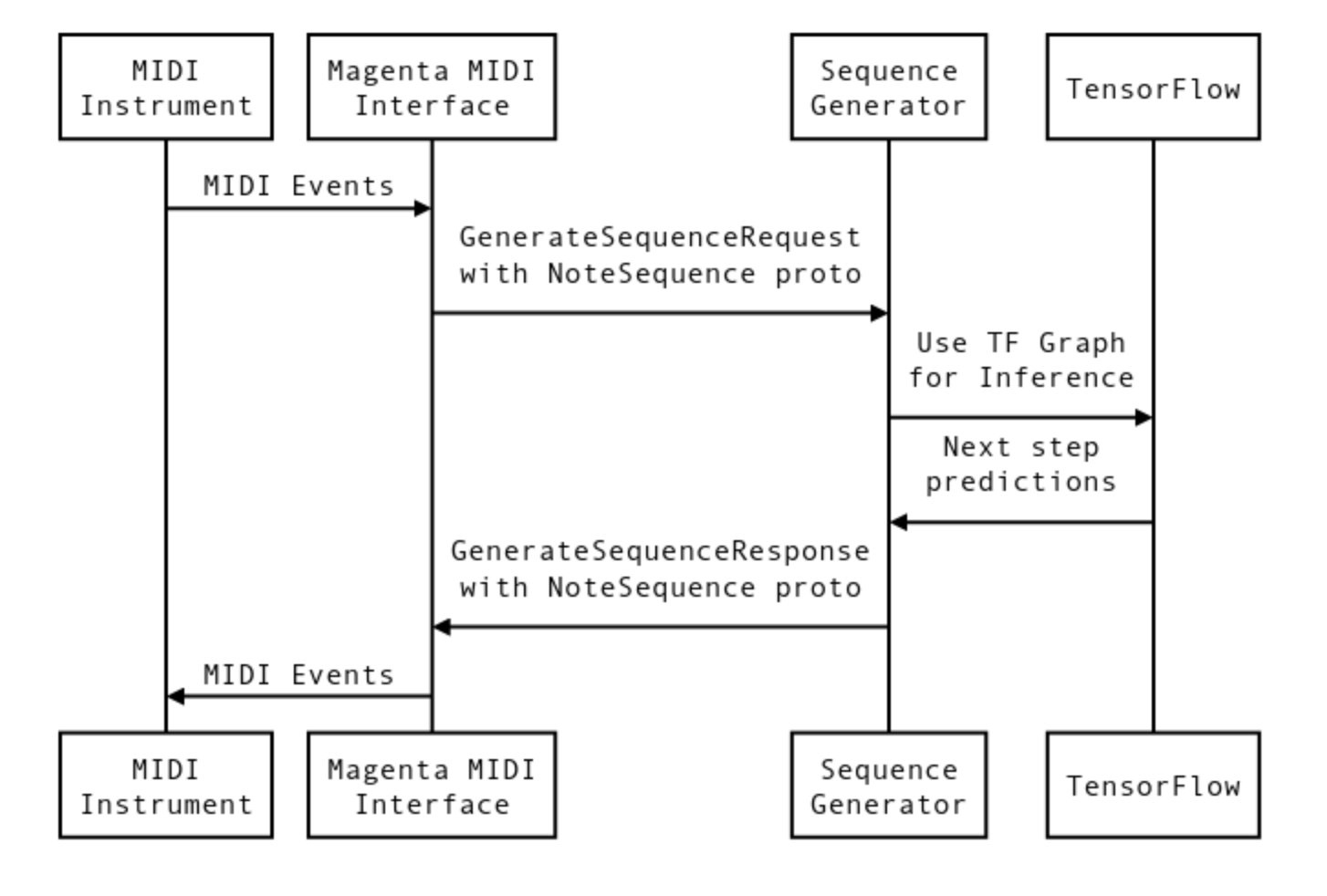
信号はMIDIインターフェイスを通過し、NoteSequence形式に変換されます。 これは、モデルと通信するためのプロトコルバッファ形式です。 トレーニングのデータは、 ここからダウンロードするか、事前トレーニング済みのモデルを取得して、それでトレーニングを続行できます。
最初はゼロからトレーニングを実施することを考えていましたが、まずトレーニングのデータ量に問題があり、次にAmazonで、たとえばGPUを使用してMagentaを実行しようとしたときに、トレーニングのさまざまな段階でフリーズする問題がありました。 問題は、ゼロからトレーニングするためのデータ量にあり、モデルがマゼンタリポジトリでトレーニングされたのと同じデータセットでトレーニングすることは意味がありません。 したがって、私は彼らのチェックポイントを続けました。 私は壊れたリズム音楽の束を汲み上げました。 Prodigy-Outer of Space and Goldie-Inner City Life to Massive Attackから
Magenta Project Githubには、準備されたノートシーケンスからドラムやメロディーなどのさまざまなセクションを抽出するためのツールが既にあります。 LSTMリカレントネットワークが使用され、128エレメントの2つのレイヤーが使用され、最後の2つのバーが考慮されました。 トレーニング時間はラップトップで約4日間です。 しかし、勾配は非常にゆっくりと下降し、最後に下降したのか、極小値付近で振動したのかはわかりません。
次に、これがすべてどのようにさらに接続されたかについて説明します。 チェックポイントはバンドルファイルで接続され、起動時に2つのモデルがロードされました。各モデルには独自の仮想ポートのペアがありました。 それらをmagenta_in / out 1および2と呼びます。次に、これらすべてをライブミュージシャンと接続する必要があります。 Alexander Zhedelevは、ユニバーサルグルーとしてAbletonを使用しました。
マゼンタプロジェクトサイトには、MaxMSPを使用してAbletonをリンクする方法の例がありますが、MaxMSPがクラッシュおよびクラッシュしたため、このオプションは削除されました。 作業を妨げることなくシステムから何かを捨てることができる場合は、安全に捨ててください。
アレクサンダージェデレフは、Abletonを想起させました。 midi_clockを介した一般的なマゼンタとAbletonの同期に関する小さな問題がありました。 最終的に、このような構成になりました。
2つのモデルがありました。 最初の人はその人の声に耳を傾け、答えを出します。その後、2番目の人は最初の人の答えを聞き始め、彼のパートを発行します。 面白い瞬間は、それらをループに結び付けたときでした(最初のループは2番目のループを丸で聴きます)。 私たちは昼食のために立ち去り、約1時間後に戻りましたが、私がそう言うことができれば、彼らはすでにお互いに激怒していました。 半分のトランス、半分の何かですが、時には面白くて面白いです。
人はドラムパッド(Ableton Push2)、リズムの例、モデルを演奏しますが、この間ずっと入力用のMIDI信号を受信し、例の終了後、しばらくして答えを出します。 さらに、試聴セクションの長さを長くして設定するほど、回答の意味が大きくなることに気付きました。 どうやらこれは非常に内部的な状態によるものです。 私はまだ完全に説明することもできません。最初にネットワークが対数尤度-70のオプションを提供する理由ですが、時間が経つにつれてこの値は-150、-400、さらには-750に低下します。 この値が低いほど、結果の最尤度が高くなります。 つまり、対数尤度を最小化することは、最尤関数を最大化することと同じです。 耳で、これはモデルが、あたかも演奏されたかのように激怒することを表しています。 つまり、モデルの内部状態は以前のコンテキストに依存しますが、時間の経過とともに生成された最適なシーケンスに収束することは明らかです。
その過程で。

最初はこんな感じでした。
これらは、モデルをリンクするためのさまざまなオプションの最初のステップおよびテストです。
しかし、生きている人々との最初の本当のリハーサルは、ビデオですべてをキャプチャすることにした瞬間でした。 Playtechがこのためのオフィススペースを提供してくれましたが、それには何かがありました。 窓の外には、離陸機のある空港があり、10階、夕方、空っぽのオフィス、バスの音が骨に届きます。 ニコライ・アルハゾフの助けと仕事に感謝します。このビデオなしでは不可能でした。 難点は、モデルの一部では毎回即興であったため、各テイクは以前のものとは異なり、これが陰謀を追加したことです。 そして、はい、良いココアは命を救いました。

リズムセクションはニューラルネットワークによって発行されます。 異なる時期に、アレキサンダーはリズムの種を演奏し、それから即興のチェーンが展開します。
アレクサンダーにとって、ある瞬間にモデルで何が起こっているかが重要だったので、マゼンタのウェブインターフェースは非常に便利で、ブラウザを介してネットワークパラメータを表示および変更できます。 ビデオでは、彼はテトリスのように横に走っています。
毎回、結果はどんどん良くなっています。 MIDI信号によって制御されるビデオを取得する場合、理論的にはネットワークをビデオおよび音楽に接続し、それらを相互に同期させることができます。 さらに検索するためのスペースは、ユースケースと同様に十分に大きいです。 モデルを相互に接続し、ループを作成し、予期しない、時には興味深いオプションを取得できます。
そして、ここで、地元のテレビでの今日のインタビュー。
とても面白くて珍しい経験でした。 そして、将来の方向性についての考えがあります。
このプロジェクトに参加してくれたすべての人々に感謝したいと思います。
- アレクサンドル・ゼデルヨフ、別名ファエルシュテイン
- マルテン・アルトロフ-MODULSHTEIN
- Aleksej Semenihhin-MODULSHTEIN
- Nikolay Alhazov 、このビデオをリアルにしたことに対して
- Katrin Kvade 、サウンドエンジニアリング
- プレイテック会社
- MarianneVõimeとErgoJõepereは個人的にサポートと支援をしてくれました