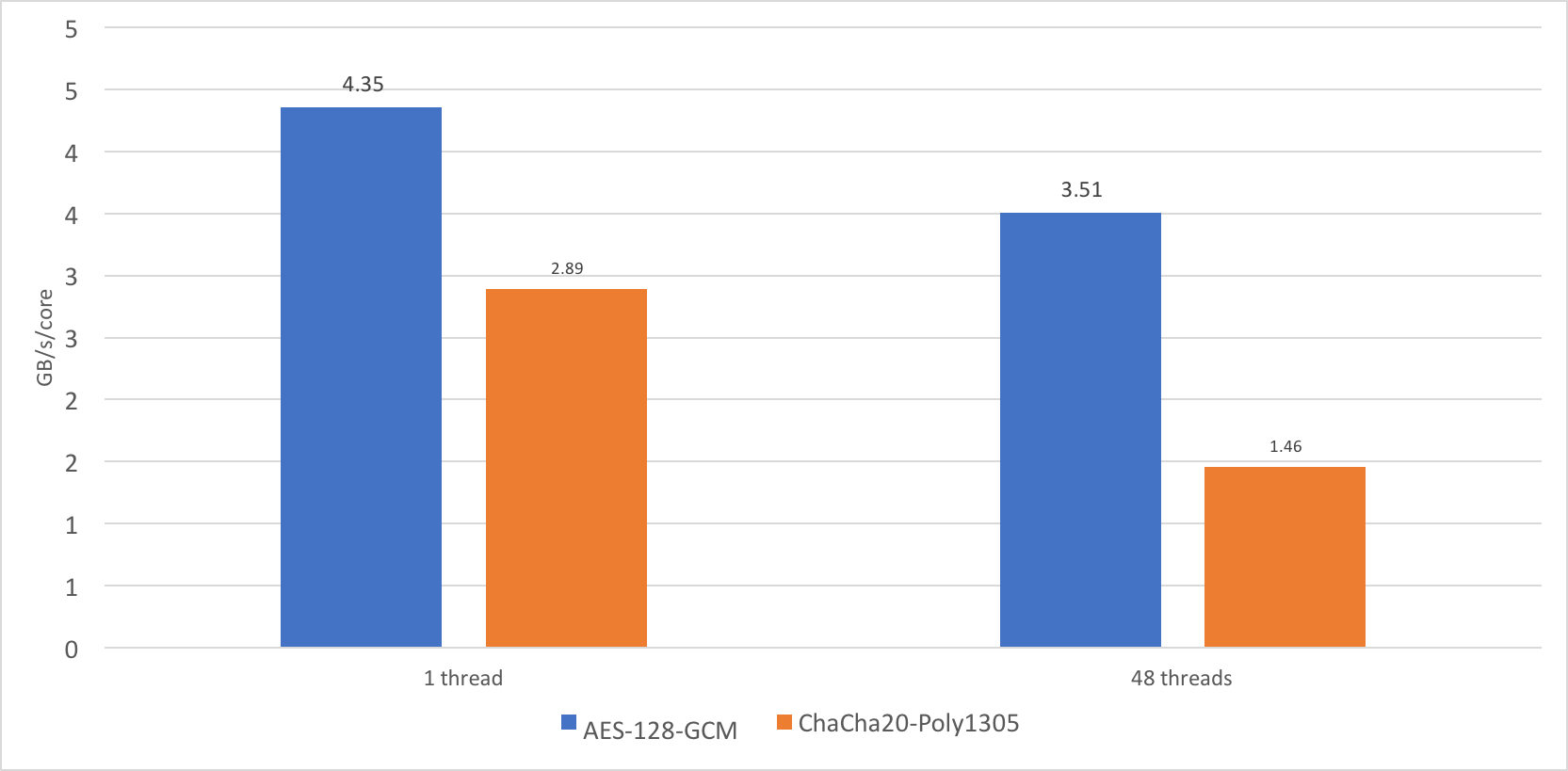
Qualcommの新しいCentriqサーバーチップと既存のIntel Xeon世代のSkylakeを比較すると 、奇妙なことに気づきました。ChaCha20-Poly1305暗号のパフォーマンスは、コアを追加するときにうまくスケーリングしません。 1つのストリームは約2.89 GB /秒の速度で動作し、24コアで48スレッドで合計パフォーマンスはわずか35 GB /秒でした。
もちろん悪くありませんが、69 GB / sのようなものが表示されると予想していました。 35 GB / sはコアあたり1.46 GB / sであり、単一コアのパフォーマンスの約50%です。 AES-GCMは、同じ条件下で1コアのパフォーマンスの最大約80%まではるかに優れたスケーリングを実現します。これは、1コアの負荷下で周波数を上げるプロセッサの能力によって説明されます。

ChaCha20-Poly1305のスケーリングがそれほど悪いのはなぜですか? 既存のほとんどのSIMD命令を512ビットに拡張し、いくつかの新しい命令を追加するAVX-512命令セットを確認してください。 問題は、1回の実行で8から64の通常の操作が必要になるため、かなりの量のエネルギーを消費することです。
エネルギー消費を許容可能なレベルに維持するために、Intelは3年前にHaswellプロセッサファミリに動的な周波数変更を導入しました。 このメカニズムにより、AVX2またはAVX-512命令を実行する場合にプロセッサの基本周波数が低下します。 AVX-512コードのみが実行される場合、すべてが正常です。 頻度は低くなりますが、単位時間あたりに実行される操作の総数は多くなります。
OpenSSL 1.1.1devには、AVX2およびAVX-512の使用を含むChaCha20-Poly1305のいくつかの実装が含まれています。 BoringSSLはわずかに異なる方法でアルゴリズムを実装し、AVX2のみを使用しているため、シングルコアでのパフォーマンスはOpenSSLで2.89 GB / sではなく1.6 GB / sにすぎません。
これは、負荷が従来の計算とAVX-512を使用したわずかな計算の混合である状況でどのような効果がありますか? Xeon Silver 4116は、デュアルソケット構成で2.1 GHzの基本周波数で使用します。 wikichipにある表から、1つのコアでAVX-512命令を実行するとベース周波数が1.8 GHzに低下し、すべてのコアで命令を実行するとベース周波数が1.4 GHzに低下することがわかります。
アプリケーションも実行するWebサーバー(ApacheまたはNGINX)があるとします。 問題は、AVX-512命令を使用して実装されたChaCha-Poly1305アルゴリズムを使用してトラフィックの暗号化を開始するとどうなりますか?
NGINXの2つのバージョンを作成しました。1つはOpenSSL 1.1.1devで、もう1つはBoringSSLで-2つのXeon Silver 4116を搭載したサーバーにインストールし、合計24コアを受け取りました。 Webサーバーは、中規模のHTMLページを処理およびレンダリングするように構成されています。 LuaJITを使用して、改行と余分な空白、およびページ圧縮アルゴリズムbrotliを削除しました。 次に、サーバーが全負荷で処理できるリクエストの数を測定しました。

AES-GCMの代わりにChaCha20-Poly1305を使用する場合、OpenSSLで構築されたWebサーバーは10%少ないリクエストを処理しました。これは、アイドル状態の2つのプロセッサコアに相当します。 ChaCha20-Poly1305アルゴリズム自体の速度が遅いために、このような違いが観察されると仮定できますが、そうではありません。
まず、BoringSSLは両方の暗号化アルゴリズムで同等に良好に機能しました。 次に、リクエストの10%のみがChaCha20-Poly1305を使用している場合でも、パフォーマンスは5.5%低下し、そのようなリクエストの割合が20%に達すると7%低下します。 参考:実際のCloudflare HTTPSトラフィックでは、ChaCha20-Poly1305アルゴリズムを使用したリクエストの割合は15%です。
パフォーマンスによると、プロセッサは、ChaCha20-Poly1305からの要求の100%の割合でAVX-512命令を処理する時間のわずか2.5%を費やし、そのような要求の10%で0.3%未満を費やします。 要求の割合に関係なく、AVX-512命令はすべてのコアで一度に実行されるため、CPU周波数は低下します。
特定の時点でプロセッサの周波数がどれだけ低下するかを言うのは困難です。 ただし、 lscpu
読み取り値を確認した後、 openssl speed -evp chacha20-poly1305 -multi 48
の実行中に、 CPU MHz: 1199.963
得られることがCPU MHz: 1199.963
。 OpenSSLおよびAES-GCMアルゴリズムを備えたWebサーバーのCPU MHz: 2399.926
、 CPU MHz: 2399.926
を取得しCPU MHz: 2399.926
およびChaCha20-Poly1305アルゴリズムを備えたWebサーバーのCPU MHz: 2184.338
、 CPU MHz: 2184.338
、つまり9%減少します。
もう1つの興味深い違いは、AVX2を使用するChaCha20-Poly1305アルゴリズムはOpenSSLで少し遅くなりますが、BoringSSLでのパフォーマンスは失われないことです。 その理由は、BoringSSLはPoly1305のAVX2乗算命令を使用せず、ChaCha20の場合は比較的単純なxor、shift、add命令のみを使用するため、コアをベース周波数に維持できるためです。
OpenSSL 1.1.1devはまだ開発中であるため、この問題は誰にもまだ発生していないと思われます。 数か月前にBoringSSLを使用するように切り替えましたが、サーバーのパフォーマンスは前述の影響を受けません。
今後の準備は何日ですか? インテルは、将来の世代のために、暗号操作のパフォーマンスをさらに向上させる新しい命令セットを発表しました。 これらの拡張機能には、AVX512 + VAES、AVX512 + VPCLMULQDQおよびAVX512IFMAが含まれます。 ただし、この時間までに頻度を下げる問題が解決されない場合、新しい命令セットを使用すると、パフォーマンスの観点からは害が大きくなる可能性があります。
問題は暗号ライブラリだけではなく、それほど多くありません。 OpenSSLの作者は、パフォーマンスを向上させる方法を探していることを責めることはできませんが、逆に、私自身はAVX-512を使用してかなりの量のOpenSSLコードを作成しました。 観察された行動は悲しい副作用です。 AVX-512を使用するライブラリは多数あり、ユーザーは実装の詳細について最新ではない可能性が高いです。 特定の計算集約的なタスクにAVX-512を使用する必要がない場合は、プロセッサ周波数の望ましくない低下を避けるために、サーバーとパーソナルコンピューターでのサポートをオフにすることをお勧めします。
もちろん、これらの事実はガイダンス文書に記載されています:周波数低減自体はIntel Advanced Vector Extensionsによるパフォーマンスの最適化に記載されており、 Intel®Xeon®Processor Scalable Family Specificationで特定のSkylake プロセッサーに対して実行されるカーネル操作の数に応じた変更の制限更新する しかし、これらの文書は、その存在を読んだり、知っている人すらいないという意味で、一般の人々向けではありません。 たとえば、 PCUの公式の説明と、AVX-512の指示に従って周波数を下げる実際のアルゴリズムを見つけることができませんでした。
開発でのAVX-512の使用について説明したHabrに関する記事が既にありました(たとえば、 どのようにして最速のイメージサイズ変更を行いましたか。パート2、SIMD )。 現代のプロセッサとシステム管理者の動作の微妙な違いについても知っておくと非常に便利です(現在どのように呼ばれていても)。したがって、システム管理ハブに転送を公開します。
説明:翻訳者はCloudflare、Inc.と提携していません。 翻訳は、芸術への愛、所有者のすべての権利から作られています。 KDPV blumblaumに よる 、CC BY-SA 2.0。 見出しはCodeRushを思いついた 。