
この記事は、 Azure ML Workbenchによる鳥の検出の翻訳です。
データ
以下のビデオは、Abram Fleishman(サンノゼ州立大学)およびConservation Metrics、Inc.によって提供されています。 アカアシモドキの自然の生息地-検出手段の開発が必要な鳥の種をキャプチャします。 生物学者は、登山用具を含むさまざまな機器を使用して岩の上にカメラを設置し、昼夜を問わず写真を撮ります。
モデルをトレーニングするために、写真を使用し、 ビジュアルオブジェクトタグ付けツール(VOTT)を使用してイメージマークアップを実行しました。 データのラベル付けには約20時間かかり、その間に約12,000個のバウンディングボックスが記録されました。

タグ付きデータはGitHubのリポジトリで利用できます 。
からのデータはどこですか
これらのデータは、 Dr。Rachel Orben (オレゴン大学)、Abram Fleishman(サンノゼ州立大学)およびConservation Metrics、Inc.によって収集されました。 アカアシイタチの初期の営巣期間を研究する主要プロジェクトの一環として、食物の入手可能性の要因の影響を決定し、ベーリング海(アラスカ)での非繁殖期間を分析します。
オブジェクト検出
オブジェクト検出技術の詳細については、 畳み込みニューラルネットワーク(CNN)に関するブログ投稿を参照してください。 より高速なR-CNN(Convolutional Neural Networkを使用した地域提案)-比較的新しいアプローチ(この方法に関する最初の文書は2015年に公開されました)。 機械学習コミュニティで広く使用されており、PyTorch、CNTK、Tensorflow、Caffeなどを含む最も人気のあるディープニューラルネットワーク(DNN)フレームワークに組み込まれています。
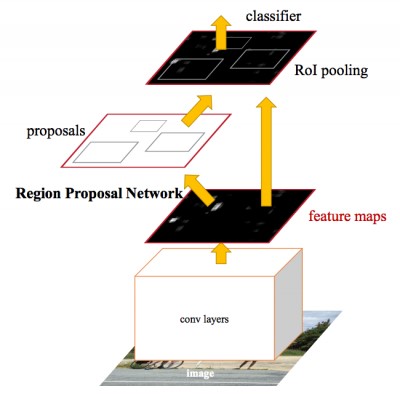
この記事では、CNTKおよびTensorflowフレームワークを使用してオブジェクトを検出するFaster R-CNNアルゴリズムについて説明します。
Azure Machine Learning Workbench
最近発表されたAzure Machine Learning Workbenchプラットフォームを使用して、モデルをトレーニングし、予測Webサービスを作成しました。 分析ツールのセットであり、データスペシャリストはデータを準備し、機械学習実験を実行し、クラウド環境にモデルを展開できます(「 インストールと構成 」セクションのドキュメントを参照)。
画像を処理する必要があるため、CNTKおよび実験を開始するツールであるTensorflowでMNIST手書き数字分類モデルを使用しました 。

原則として、ディープニューラルネットワーク(DNN)トレーニングは、グラフィックプロセッサ(GPU)を使用して効率的に実行されます。これにより、行列に対する多数の操作のパフォーマンスが大幅に向上します。 モデルをトレーニングするために、GPUからのデータを処理および分析するための仮想マシンをデプロイし、Azure ML Workbenchで利用可能なリモートDockerランタイムを使用しました(「 詳細 」セクションとターゲットプラットフォームに関する追加情報を参照)。
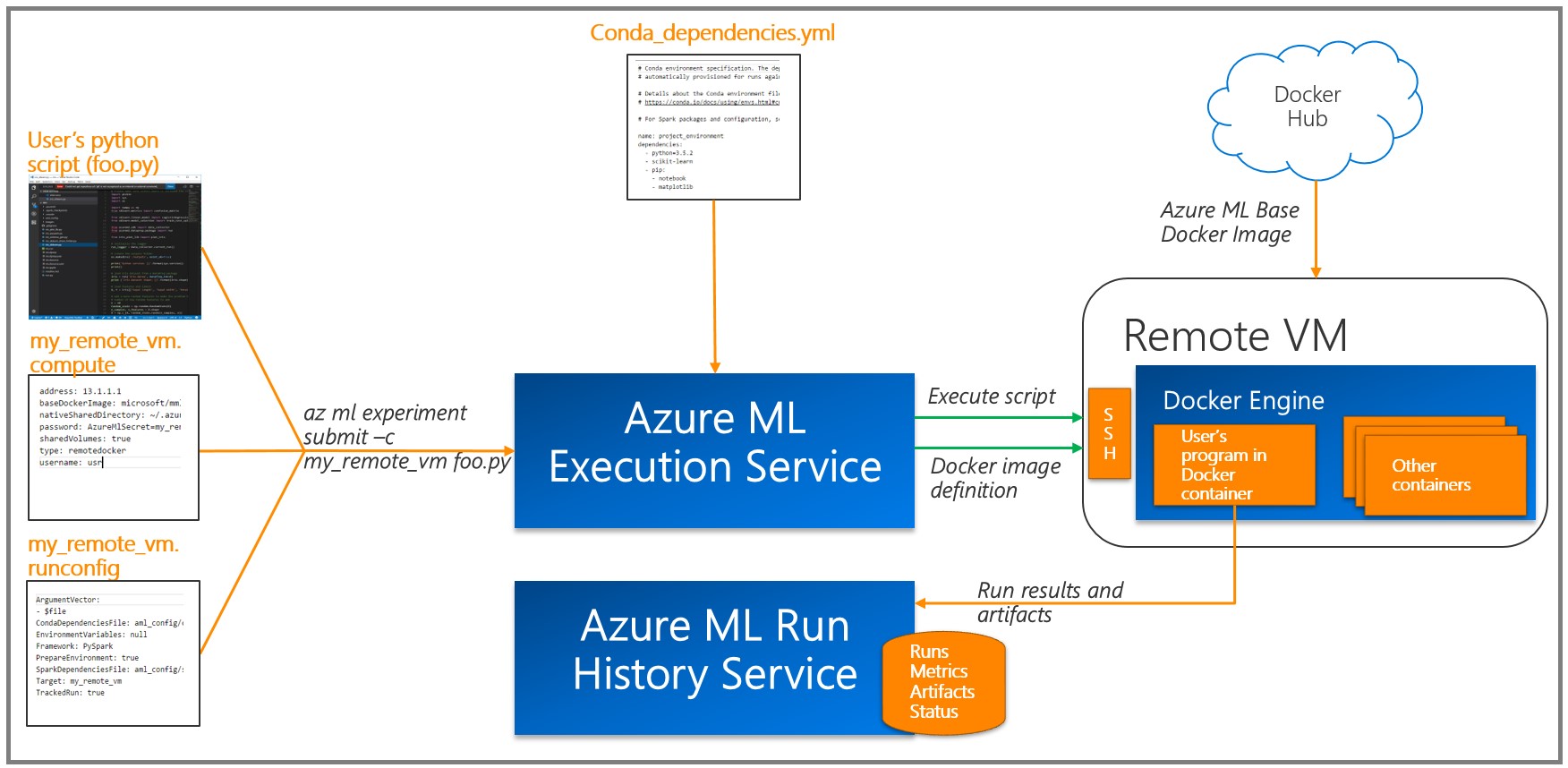
Azure MLは、各タスク(実験)の結果を実行ログに書き込みます 。 実験ではモデルパラメータのさまざまな組み合わせが使用されたため、この機能は非常に有用であることが判明しました。利用可能な視覚化ツールは、最高のパフォーマンスのモデルを選択するのに役立ちます。 Azure ML Logging APIを使用してツールをトレーニング/評価コードに追加して、必要なメトリック(分類の精度など)を追跡する必要があることに注意してください。
画像のレイアウトとエクスポート
VOTTユーティリティ (WindowsおよびMacOSで使用可能)を使用して、データをマークアップし、それぞれCNTKおよびTensorflow Pascal形式にエクスポートしました。
これは、識別に便利なインターフェイスを備えたツールで、画像や動画の目的の領域にマークを付けることができます。 それを使用するには、フォルダ内の画像を収集してからVOTTを実行し、画像データのセットを指定して、マーキング領域に移動する必要があります。

終了したら、[オブジェクト検出]、[タグのエクスポート]の順にクリックして、CNTKおよびTensorflowにエクスポートします。
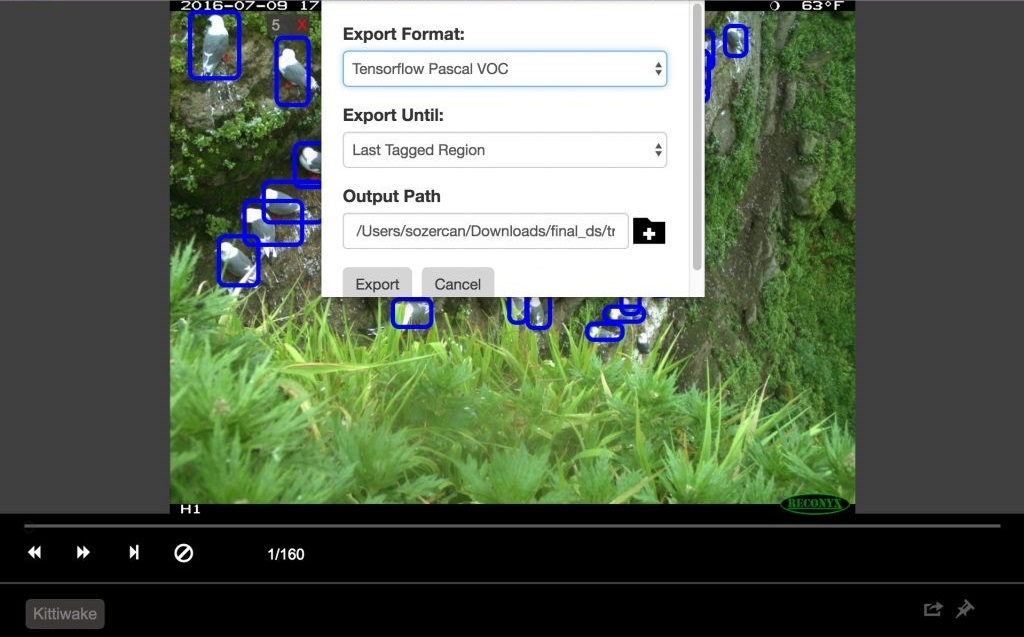
Tensorflowでは、エクスポート形式はVOC Pascalであるため、トレーニングと評価で使用するためにデータをTFRecordsに変換しました。 以下で詳しく説明します。
CNTKを使用したトレーニング鳥検出モデル
前のセクションで示したように、鳥の検出モデルでは、一般的なFaster R-CNNアルゴリズムを使用しました。 このセクションでは、アプローチの2つの側面に焦点を当てます。
- Azure ML Workbenchを使用して、リモートVMの学習を開始します。
- Azure ML Workbenchを介してハイパーパラメーターを構成します。
Azure ML Workbenchを使用してリモートVMでトレーニングする
モデルの最初のドラフトが良好な結果を示していれば、すぐに使用できる機械学習モデル(またはディープラーニング)を構築するプロセスのメインステージはハイパーパラメーターの設定です。 ここでの問題は、Azure ML Workbenchによるプロセスの効率的な実装と簡素化です。
パラメーターを構成するには、多数のトレーニング実験が必要であり、通常は非常に長い時間がかかります。 アプローチの1つは、強力なローカルコンピューターまたはクラスターでのトレーニングに基づいています。 ただし、このアプローチは、リモート(仮想)マシン上のDockerコンテナーを使用してクラウドで学習することを目的としています。 主な利点は、並列設定に必要な数のコンテナを発行できることです。 Azure MLのこのドキュメントに従って、各仮想マシンを実験の計算のターゲットとして登録する必要があります。 パスワード文字には制限があることに注意してください。たとえば、パスワードに「*」文字を使用するとエラーが発生します。
az ml computetarget attach --name "my_dsvm" --address "my_dsvm_ip_address" --username "my_name" --password "my_password" --type remotedocker
コマンドを実行すると、ファイル
myvm.compute
および
myvm.rucomfig
が
aml_config
フォルダーに作成されます。 このタスクはGPUマシンにより適しているため、次の変更を行う必要があります。
myvm.computeで
baseDockerImage: microsoft/mmlspark:plus-gpu-0.7.91 nvidiaDocker: true
myvm.runconfigで
EnvironmentVariables: "STORAGE_ACCOUNT_NAME": "STORAGE_ACCOUNT_KEY": Framework: Python PrepareEnvironment: true
Azure Storageを使用して、トレーニングデータ、事前トレーニングモデル、モデルブレークポイントを保存しました。 ストレージ資格情報は
EnvironmentVariables
としてリストされます。
conda_dependencies.yml
パッケージが
conda_dependencies.yml
含まれていることを確認してください。
これで、コマンドを実行してマシンの準備を開始できます。
az ml experiment –c prepare myvm
次に、オブジェクトを検出するためのモデルをトレーニングします。
az ml experiment submit –c Detection/FasterRCNN/run_faster_rcnn.py .. .. .. Evaluating Faster R-CNN model for 53 images. Number of rois before non-maximum suppression: 8099 Number of rois after non-maximum suppression: 1871 AP for Kittiwake = 0.7544 Mean AP = 0.7544
Azure ML Workbenchを介してハイパーパラメーターを構成する
Azure MLとWorkbenchを使用すると、複数のコンテナーを同時に実行することで、ハイパーパラメーターやその他のパフォーマンスメトリックを簡単に記録できます(詳細については、ドキュメントの「 ログ情報 」セクションを参照してください)。
試行する最初のアプローチは、事前に訓練された異なる基本モデルを使用することです。 この記事の執筆時点では、CNTK Faster R-CNN APIメソッドは、 AlexNetとVGG16の 2つの基本モデルをサポートしていました 。 これらの訓練されたモデルを使用して、画像の特徴を強調できます。 これらの基本モデルは、 ImageNetなどの他のデータセットで低および中レベルでトレーニングされたという事実にもかかわらず、画像の属性は異なるアプリケーションで同じであるため、公開されています。 この現象は、転移学習として知られています。
AlexNetには5つの畳み込みCONVレイヤーがあり、VGG16には12があります。 VGG16でトレーニングされたパラメーターの数は1億3,800万で、AlexNetをほぼ3倍超えています。 ここでは、ベースモデルとしてVGG16を使用しました。 以下は、スコアカードのパフォーマンスを向上させるために最適化されたVGG16ハイパーパラメーターです。
検出中/ FasterRCNN / FasterRCNN_config.py:
# Learning parameters __C.CNTK.L2_REG_WEIGHT = 0.0005 __C.CNTK.MOMENTUM_PER_MB = 0.9 # The learning rate multiplier for all bias weights __C.CNTK.BIAS_LR_MULT = 2.0
検出/ utils / configs / VGG16_config.py:
__C.MODEL.E2E_LR_FACTOR = 1.0 __C.MODEL.RPN_LR_FACTOR = 1.0 __C.MODEL.FRCN_LR_FACTOR = 1.0
Azure ML Workbenchは、さまざまなパラメーター構成の視覚化と比較を大幅に簡素化します。

ベースモデルVGG16を使用したmAP
Evaluating Faster R-CNN model for 53 images. Number of rois before non-maximum suppression: 6998 Number of rois after non-maximum suppression: 2240 AP for Kittiwake = 0.8204 Mean AP = 0.8204
実装手順については、GitHubリポジトリを参照してください。
トレーニングTensorflow鳥検出モデル
Googleは最近、オブジェクト検出用の強力なAPIセットを導入しました。 Google Cloud Machine Learning Engineを使用した動物認識ツールのトレーニングに関するドキュメントを使用しました。これは、Azure ML Workbenchで乳虫を検出するモデルをトレーニングするプロジェクトを開発するきっかけとなりました。 Tensorflow Object Detection APIには、 COCOデータセットに関する多くの事前学習済みモデルが含まれています。 私たちの実験では、ResNet-101( 深い残余ネットワーク 、レイヤー101)を基本モデルとして使用し、動物認識の例の構成を適用して、オブジェクト検出のトレーニングのセットアップを開始しました。
このリポジトリには、Azure ML WorkbenchおよびTensorflowを通じてオブジェクト検出モデルをトレーニングするために使用されるスクリプトが含まれています。
トレーニングの準備
ステップ1. Tensorflowオブジェクト検出APIに必要なTFレコード形式でデータを準備します。 このアプローチでは、 VOTTツールの標準出力を変換する必要があります。 詳細については、 create_pascal_tf_record.py汎用コンバーターを参照してください 。
python create_pascal_tf_record.py --label_map_path=/data/pascal_label_map.pbtxt --data_dir=/data/ --output_path=/data/out/pascal_train.record --set=train python create_pascal_tf_record.py --label_map_path=/data/pascal_label_map.pbtxt --data_dir=/data/ --output_path=/data/out/pascal_val.record --set=val
ステップ2. DockerイメージにさらにインストールするためのTensorflowオブジェクト検出およびスリムコードパッケージを作成します。これは実験に使用されます。 Tensorflowオブジェクト検出ドキュメントの手順は次のとおりです。
# From tensorflow/models/research/ python setup.py sdist (cd slim && python setup.py sdist)
次に、生成された
conda_dependancies.yaml
を実験にアクセスできる場所(たとえば、
conda_dependancies.yaml
ストレージ)に
conda_dependancies.yaml
し、実験用に
conda_dependancies.yaml
にリンクを
conda_dependancies.yaml
します。
dependencies: -python=3.5.2 -tensorflow-gpu -pip: #... More dependencies here… #TF Object Detection -<a href="https://olgalidata.blob.core.windows.net/tfobj/object_detection-0.1_3.tar.gz">https:///object_detection-0.1.tar.gz</a> -<a href="https://olgalidata.blob.core.windows.net/tfobj/slim-0.1.tar.gz">https://</a><a href="https://olgalidata.blob.core.windows.net/tfobj/object_detection-0.1_3.tar.gz">/</a><a href="https://olgalidata.blob.core.windows.net/tfobj/slim-0.1.tar.gz">/slim-0.1.tar.gz</a>
手順3.実験スクリプトにインポートを追加します。
from object_detection.train import main as training_module
次に、training_module(_)関数を使用して、コードでトレーニングプロシージャを呼び出します。
学習と評価プロセス
Tensorflow Object Detection APIの検出には、コマンドラインから2つの個別のコマンドを実行して、学習と評価(モデルの現在のパフォーマンスの確認)を開始することが含まれます 。 いくつかの実験を開始する場合、非表示データ内のオブジェクトを認識するモデルの能力を分析するために、定期的に評価(たとえば100回の反復ごと)を実行することをお勧めします。
Tensorflow Object Detection APの場合、 train_eval.pyを追加しました 。これは、継続的な学習と評価へのアプローチを示しています。
print("Total number of training steps {}".format(train_config.num_steps)) print("Evaluation will run every {} steps".format(FLAGS.eval_every_n_steps)) train_config.num_steps = current_step while current_step <= total_num_steps: print("Training steps # {0}".format(current_step)) trainer.train(create_input_dict_fn, model_fn, train_config, master, task, FLAGS.num_clones, worker_replicas, FLAGS.clone_on_cpu, ps_tasks, worker_job_name, is_chief, FLAGS.train_dir) tf.reset_default_graph() evaluate_step() tf.reset_default_graph() current_step = current_step + FLAGS.eval_every_n_steps train_config.num_steps = current_step
いくつかのモデルハイパーパラメーターを確立し、モデルへの影響を評価するために、データをトレーニング、検証(カスタマイズ可能)、テストセットに分けました:それぞれ160画像、54画像、55画像。
実行比較
Tensorflow Object Detection Frameworkは、ユーザーにさまざまなパラメーター設定を提供し、特定のデータセットに最適なオプションを選択できるようにします。
この演習では、いくつかの実行を行い、どれが最良のモデルパフォーマンスを提供するかを確認します。 ターゲットメトリックとして、オブジェクト検出の精度を使用します。これは通常、mAP(平均精度、平均精度の平均値)として定義されます。 各実行で、
azureml.logging
を使用して最大mAPに関する情報を取得し、トレーニングの反復を識別します。 さらに、「mAP and iteration」グラフを作成し、Azure ML Workbenchで表示するために出力フォルダーに保存します。
TensorBoardイベントとAzure ML Workbenchの統合
TensorBoardは、ディープニューラルネットワーク(DNN)をデバッグおよび視覚化するための強力なツールです。 Tensorflow Object Detection APIは、すでに正確性の概要メトリックを提供しています。 このプロジェクトでは、TensorBoardが視覚化のために使用するTensorflowサマリーイベントをAzure ML Workbenchに統合しました。
<span class="pl-k">from</span> tensorboard.backend.event_processing <span class="pl-k">import</span> event_accumulator <span class="pl-k">from</span> azureml.logging <span class="pl-k">import</span> get_azureml_logger ea = event_accumulator.EventAccumulator(eval_path, ...) df = pd.DataFrame(ea.Scalars('Precision/mAP@0.5IOU')) max_vals = df.loc[df["value"].idxmax()] #Plot chart of how mAP changers as training progresses fig = plt.figure(figsize=(6, 5), dpi=75) plt.plot(df["step"], df["value"]) plt.plot(max_vals["step"], max_vals["value"], "g+", mew=2, ms=10) fig.savefig("./outputs/mAP.png", bbox_inches='tight') # Log to AML Workbench best mAP of the run with corresponding iteration N run_logger = get_azureml_logger() run_logger.log("max_mAP", max_vals["value"]) run_logger.log("max_mAP_interation#", max_vals["step"])
詳細については、 results_logger.pyコードを参照してください 。
Azure ML Workbenchの実験インフラストラクチャを使用して実施したいくつかのトレーニング実行の分析を次に示します。
実行番号1は、確率的勾配降下法を使用しており、データ増加は無効になっています(勾配最適化の可能性の概要については、 このブログ投稿を参照してください)。
Azure ML Workbenchランタイムログには、各実行の詳細が記載されています。
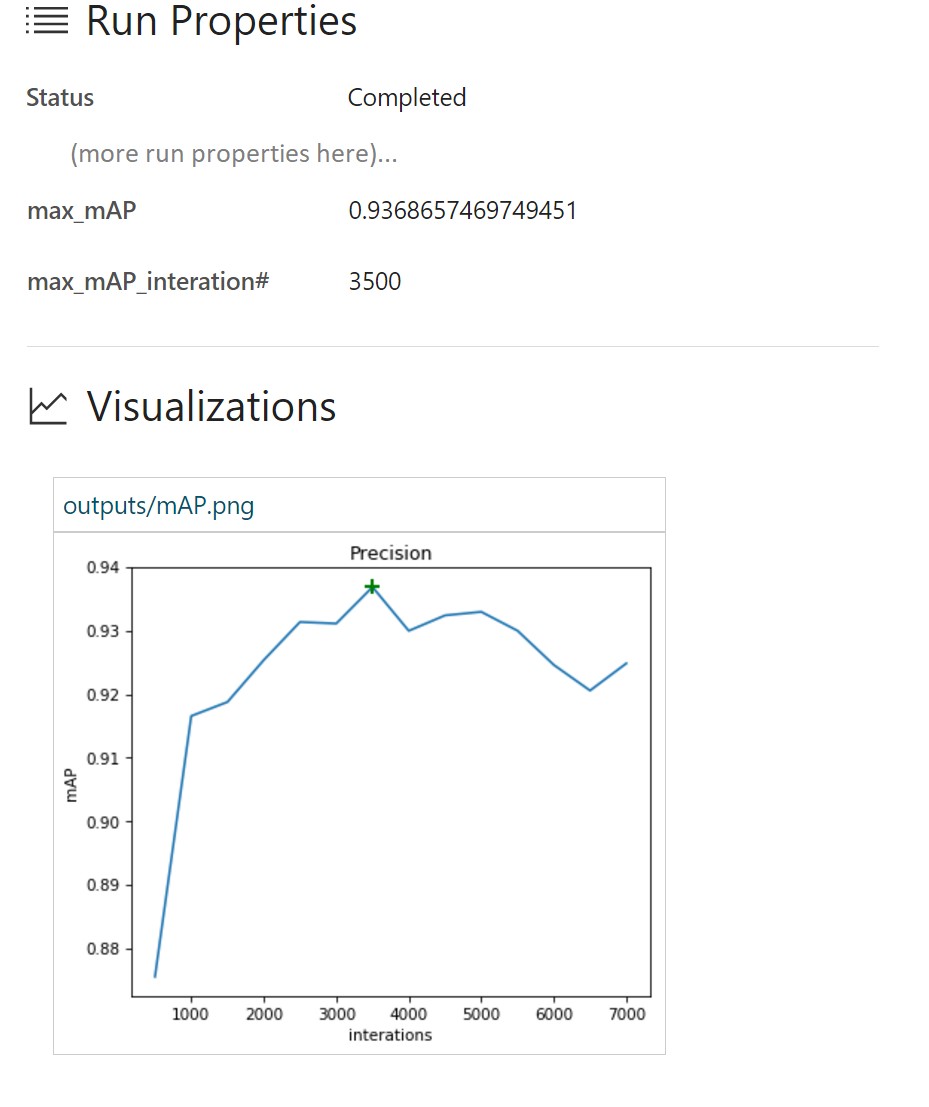
この場合、約3,500回の反復で最大mAP値が93.37%であることがわかります。 したがって、トレーニングデータ用にモデルが再トレーニングされ、テストセットのパフォーマンスが低下し始めます。
実行番号2は、高度なAdam最適化アルゴリズムを使用します。 他のすべてのパラメーターは同じです。

ここで、93.6%のmAP値は、実行番号1よりもはるかに速く達成されます。 どうやら、評価セットの精度値が急速に低下しているため、モデルははるかに早く再トレーニングされます。
実行番号3は、データ構成をトレーニング構成に追加します。 以降の実行では、Adam最適化アルゴリズムをそのままにします。
data_augmentation_options{ random_horizontal_flip{} }
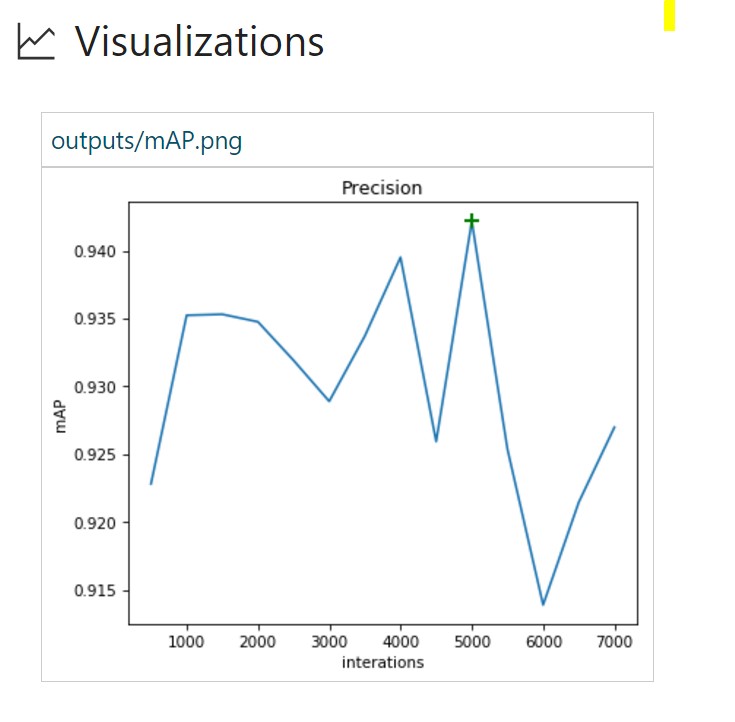
画像のランダムな水平表示により、実行番号2の93.6から94.2%にmAPインジケーターを改善できました。 モデルを再トレーニングするには、より多くの反復も必要です。
実行番号4には、より多くのデータ拡張オプションが含まれています。
data_augmentation_options{ random_horizontal_flip{} random_pixel_value_scale{} random_crop_image{} }
以下に興味深い結果を示します。

mAP値が最大(91.1%)ではないという事実にもかかわらず、7,000回の反復後、再トレーニングはありません。 この場合、mAPの価値を高めることができるかどうかを理解するために、このモデルのトレーニングを継続することが論理的です。
Azure ML Workbenchを使用した学習プロセスの概要は次のとおりです。

Azure ML Workbenchを使用すると、ユーザーは実行を並行して比較できます(実行番号1、3、および4を以下に示します)。

さらに、目的の画像の推定結果でグラフを作成し、値を比較するときにそれらを使用することもできます。 TensorBoardイベントには、必要なすべてのデータが既に含まれています。
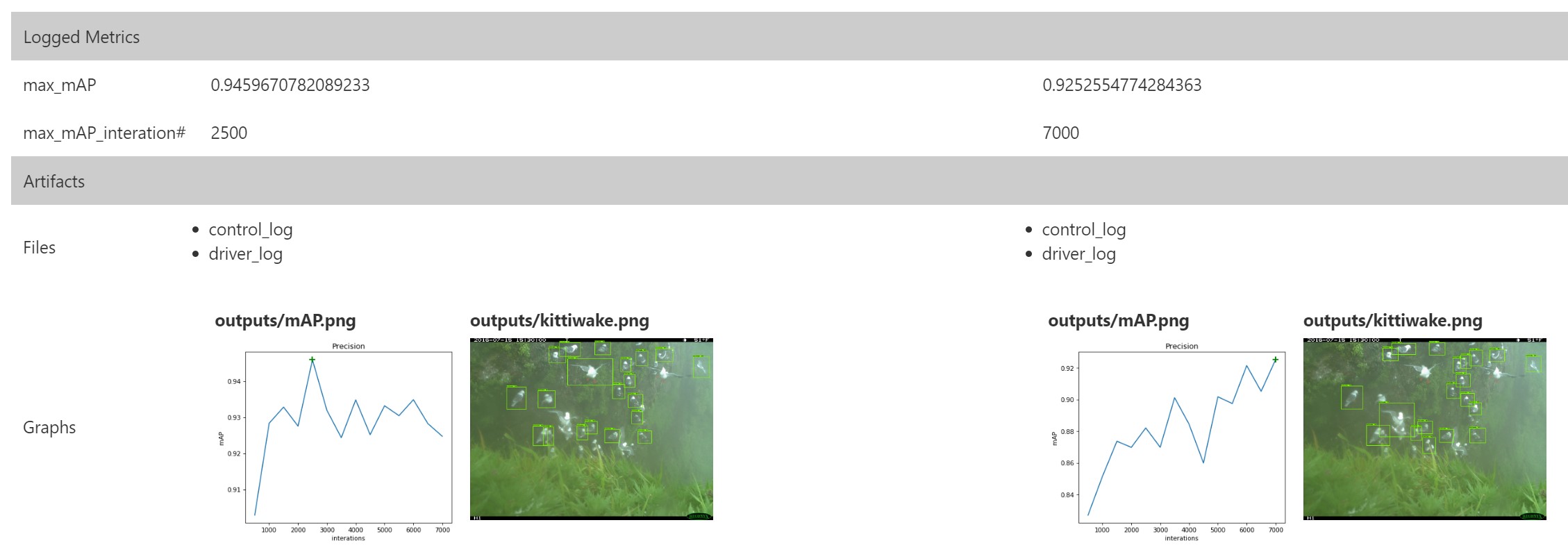
したがって、ResNetに基づいたオブジェクトの検出により、小さなデータセットでもより良い結果を得ることができます。 Azure ML Workbenchには、実験を実行して結果を比較する単一の領域を提供する便利なインフラストラクチャがあります。
評価Webサービスの展開
十分なパフォーマンスでオブジェクトの検出と分類のためのモデルを開発した後、バードウォッチングアプリケーションに接続できるように、ホストされたWebサービスの形でモデルを展開します。 組み込みのAzure MLツールを使用してこれを行う方法と、カスタム展開を実行する方法を示します。
Azure ML CLIを使用したWebサービス
Azure MLは、ローカルコンピューターまたはAzureクラウドプラットフォームでのモデル運用のサポートを強化します。
Azure ML CLIをインストールする
モデルをWebサービスとしてデプロイする前に、使用しているVMでSSHを実行する必要があります。
ssh @
この例では、VMを使用して、Azure CLIがインストールされているAzureデータを処理および分析します。 別のVMを使用している場合、次を使用してAzure CLIをインストールします。
pip install azure-cli pip install azure-cli-ml
次を使用してログインします。
az login
環境の準備
まず、環境プロバイダーを次のものに登録します。
az provider register -n Microsoft.MachineLearningCompute
ローカルコンピューターにWebサービスを展開する場合、最初に環境を準備する必要があります。
az ml env setup -l [Azure region, eg eastus2] -n [environment name] -g [resource group]
この手順により、リソースグループ、ストレージアカウント、Azure Container Registry(ACR)、およびApplication Insightsアカウントを作成できます。
次のように環境を設定します。
az ml env set -n [environment name] -g [resource group]
モデル管理アカウントを作成します。
az ml account modelmanagement create -l [Azure region, eg eastus2] -n [your account name] -g [resource group name] --sku-instances [number of instances, eg 1] --sku-name [Pricing tier for example S1]
これで、モデルを展開する準備が整いました! 以下を使用してサービスを作成できます。
az ml service create realtime --model-file [model file/folder path] -f [scoring file eg score.py] -n [your service name] -r [runtime for the Docker container eg spark-py or python] -c [conda dependencies file for additional python packages]
現在、nvidia-dockerは予測に使用できないことに注意してください。 Condaの依存関係を変更して、tensorflow-gpuなどのGPU関連のリンクを削除してください。
サービスをデプロイした後、次でWebサービスを使用する方法に関する情報を表示できます。
az ml service usage realtime -i [your service name]
たとえば、
curl
コマンドを使用してサービスをテストできます。
curl -X POST -H "Content-Type:application/json" --data !! YOUR DATA HERE !! http://127.0.0.1:32769/score
評価Webサービスの代替案を展開する
予測Webサービスをデプロイする別の方法は、独自のSanic Webサーバーのインスタンスを作成することです。 SanicはFlaskに似たPython 3.5+ Webサーバーで、Webアプリケーションを作成および実行できます。 前のセクションでCNTKとFaster R-CNNを使用してトレーニングされたモデルを使用して、画像内の鳥の位置を特定する予測を実行できます。
最初に、Sanic Webアプリケーションを作成する必要があります。 次のコードスニペット(およびapp.py )を使用して、Webアプリケーションを作成し、サーバー上で実行する場所を決定できます。 必要な各APIについて、ルート、HTTPメソッド、および各リクエストを処理するためのメソッドを指定できます。
app = Sanic(__name__) Config.KEEP_ALIVE = False server = Server() server.set_model() @app.route('/') async def test(request): return text(server.server_running()) @app.route('/predict', methods=["POST",]) def post_json(request): return json(server.predict(request)) app.run(host= '0.0.0.0', port=80) print ('exiting...') sys.exit(0)
Webアプリケーションを定義したら、イメージパスを使用して予測結果をユーザーに返すために、ロジックを実装する必要があります。
predict.pyを使用して、最初に予測を構築する必要がある画像をロードし、次に以前にトレーニングされたモデルと比較して評価し、予測データをJSONに返します。
regressed_rois, cls_probs = evaluate_single_image(eval_model, img_path, cfg) bboxes, labels, scores = filter_results(regressed_rois, cls_probs, cfg)
返されるJSONは、画像内で見つかった各鳥の予測ラベルとバウンディングボックスの配列です。
[{"label": "Kittiwake", "score": "0.963", "box": [246, 414, 285, 466]},...]
予測ロジックとWebサービスを実装したので、サーバーでアプリケーションをホストできます。 Dockerを使用して、展開の依存関係とプロセス自体を単純で再現可能にします。
cd CNTK_faster-rcnn/Detection
Dockerfileを使用してDockerイメージを作成し、アプリケーションをDockerコンテナーとして実行できるようにします。
FROM hsienting/dl_az COPY ./ /app ADD run.sh /app/ RUN chmod +x /app/run.sh ENV STORAGE_ACCOUNT_NAME ENV STORAGE_ACCOUNT_KEY ENV AZUREML_NATIVE_SHARE_DIRECTORY /cmcntk ENV TESTIMAGESCONTAINER data EXPOSE 80 ENTRYPOINT ["/app/run.sh"]
これで、次を実行してDockerイメージを構築できます。
docker build -t cmcntk .
Docker cmcntkイメージがローカルで使用可能になったら、そのインスタンスをコンテナーとして起動できます。 次のコマンドを使用して、ボリュームノードをコンテナー内のcmcntkに接続して、データの安定性を確保します(これは、モデルをトレーニングしたときの前の段階を参照)。 次に、ノード80のポートをコンテナー80のポートにマップし、最後のDocker cncntkイメージを実行します。
docker run -v /:/cmcntk -p 80:80 -it cmcntk:latest
これで、curlコマンドを使用してWebサービスをテストできます。
curl -X POST http://localhost/predict -H 'content-type: application/json' -d '{"filename": ""}'
サービスへのアクセス
これで、サービスが実行されます。 次は? 顧客はどのように彼らと対話しますか? 1つのAPIでそれらを統合する方法は? Conservation Metricsの作業中に、分類プロセス全体を完了するための実験的なソリューションとしてアプリケーションを作成しました。
問題
アプリケーションに必要な操作はわかっていますが、現在のサービスには多くの制限があるため、相互作用の問題がある可能性があります。 含む:
- 多くのサービスには共通の機能目標(マークアップデータの出力)がありますが、共通のエンドポイントはありません。
- これらのサービスに直接アクセスするには、クライアントにCORS権限(ソースに関係なくリソースへの共有アクセス)が必要です。これはすべてのサーバー/ロードバランサーで管理する必要があります。
解決策
ユニバーサルAPIエンドポイントを作成するには、 Azure API管理サービスを構成します。 このようにして、APIのCORS対応エンドポイントを構成および公開できます。
Azure API管理サービス
はじめに:
- Webサイトhttps://ms.portal.azure.com/#create/hubにアクセスします
- 「API管理」を検索して選択します。
- インスタンスを作成して構成します。
構成:
- 新しいAPIを作成します。

初期API構成:

準備が完了したら、APIにアクセスします。 [+ APIを追加]ボタンをクリックし、[空のAPI]オプションを選択します。 WebサービスURLが外部サーバー上のAPIであり、サフィックスAPIがAPIを管理するためにURLに追加されるサフィックスによって表されるようにAPIを構成します。[製品]タブで、この最終登録するAPI製品の必要なタイプをマークしますポイント。
作成されたAPIで、「コードビュー」アイテムを使用して「インバウンド処理」アイテムを構成し、ポリシーに以下の値を設定します(すべての外部URLのCORSサポートをアクティブ化するため)。
* *
APIの接続を直接確認するときのように、APIコントロールセクションで設定したサフィックスURL APIを使用できます。
例は古いAzure管理ポータルからのものですが、より詳細な入門ガイド (API管理サービスとCORSポリシー)を確認することをお勧めします。
サンプルアプリケーション
サンプルのWebクライアントアプリケーションは、次のアクションを実行します。
- Azure BLOBストレージから直接コンテナー/ BLOBからデータを読み取ります。
- 新しいAzure API Management ServiceとBLOBストレージ内のイメージ間の接続をテストします。
- 返された予測データ(鳥の境界ボックス)を画像に表示します。
GitHubコード 。
API管理サービスの接続チェック
「ネイティブ」APIからAPI管理サービスの接続をチェックする唯一の違いは、すべてのリクエストで追加のOcp-Apim-Subscription-Keyヘッダーを追加する必要があることです。 このサブスクリプションキーは、指定されたAPIエンドポイントを含むAPI管理製品にバインドされます。
サブスクリプションキーを取得するには:
- 「パブリッシャーポータル」APIに移動します。
- 対応するメニュー項目でユーザーを選択します。
- 使用するサブスクリプションキーを書き留めます。
同じサンプルアプリケーションで、添付の
Ocp-Apim-Subscription-Key
ヘッダーの値としてこのサブスクリプションキーを追加します。
<span class="hljs-keyword">export</span> <span class="hljs-keyword">async</span> <span class="hljs-function"><span class="hljs-keyword">function</span> <span class="hljs-title">cntk</span>(<span class="hljs-params">filename</span>) </span>{ <span class="hljs-keyword">return</span> fetch(<span class="hljs-string">'/tensorflow/'</span>, { method: <span class="hljs-string">'post'</span>, headers: { Accept: <span class="hljs-string">'application/json'</span>, <span class="hljs-string">'Content-Type'</span>: <span class="hljs-string">'application/json'</span>, <span class="hljs-string">'Cache-Control'</span>: <span class="hljs-string">'no-cache'</span>, <span class="hljs-string">'Ocp-Apim-Trace'</span>: <span class="hljs-string">'true'</span>, <span class="hljs-string">'Ocp-Apim-Subscription-Key'</span>: , }, body: <span class="hljs-built_in">JSON</span>.stringify({ filename, }), }) }
データ使用量
これで、サービスと画像の接続を確認し、返された境界ボックスのリストを取得できます。
基本的な使用例は、画像にフレームを描くことです。 Webクライアントでこれを行う簡単な方法の1つは、次を使用して画像を表示し、フレームオーバーレイを適用することです。
<span class="xml"><span class="hljs-tag"><<span class="hljs-title">body</span>></span> <span class="hljs-tag"><<span class="hljs-title">canvas</span> <span class="hljs-attribute">id</span>=<span class="hljs-value">'myCanvas'</span>></span><span class="hljs-tag"></<span class="hljs-title">canvas</span>></span> <span class="hljs-tag"><<span class="hljs-title">script</span>></span><span class="javascript"> <span class="hljs-keyword">const</span> imageUrl = <span class="hljs-string">"some image URL"</span>; cntk(imageUrl).then(labels => { <span class="hljs-keyword">const</span> canvas = <span class="hljs-built_in">document</span>.getElementById(<span class="hljs-string">'myCanvas'</span>) <span class="hljs-keyword">const</span> image = <span class="hljs-built_in">document</span>.createElement(<span class="hljs-string">'img'</span>); image.setAttribute(<span class="hljs-string">'crossOrigin'</span>, <span class="hljs-string">'Anonymous'</span>); image.onload = () => { <span class="hljs-keyword">if</span> (canvas) { <span class="hljs-keyword">const</span> canvasWidth = <span class="hljs-number">850</span>; <span class="hljs-keyword">const</span> scale = canvasWidth / image.width; <span class="hljs-keyword">const</span> canvasHeight = image.height * scale; canvas.width = canvasWidth; canvas.height = canvasHeight; <span class="hljs-keyword">const</span> ctx = canvas.getContext(<span class="hljs-string">'2d'</span>); <span class="hljs-comment">// render image on convas and draw the square labels</span> ctx.drawImage(image, <span class="hljs-number">0</span>, <span class="hljs-number">0</span>, canvasWidth, canvasHeight); ctx.lineWidth = <span class="hljs-number">5</span>; labels.forEach((label) => { ctx.strokeStyle = label.color || <span class="hljs-string">'black'</span>; ctx.strokeRect(label.x, label.y, label.width, label.height); }); } }; image.src = imageUrl; }); </span><span class="hljs-tag"></<span class="hljs-title">script</span>></span> <span class="hljs-tag"></<span class="hljs-title">body</span>></span> <span class="hljs-tag"></<span class="hljs-title">html</span>></span> </span>
, :

. GitHub .
おわりに
, :
- ;
- CNTK/Tensorflow Azure ML Workbench;
- Azure ML Workbench;
- - ;
- .
資源
- GitHub .
- Azure Machine Learning Workbench.
- GitHub: Microsoft Cognitive Toolkit.
- GitHub: Tensorflow Object Detection API.
- : Analyzing Big Data with Microsoft R ( ), Perform Cloud Data Science with Azure Machine Learning ( ) Performing Data Engineering on Microsoft HD Insight ( ).
, Azure .