さらに読む前にこの質問に自分で答えてみて、現時点でそのようなインタビューの準備を確認してください。
理論的な考慮事項を実数でバックアップするには、標準のArrays.parallelSort()メソッドの小さなベンチマークを実行することをお勧めします。このメソッドは、マージソートアルゴリズムのバリアントを実装し、ForkJoinPool.commonPool()で実行します。 commonPoolのサイズが異なる同じ大きな配列でこのアルゴリズムを実行し、結果を分析します。

ベンチマークが実行されたマシンには4つのコアと、サーバーアプリケーションに最適ではないWindowsオペレーティングシステムがあり、バックグラウンドサービスで過負荷になっているため、結果にかなりのばらつきが見られますが、それでも物事の本質を見ることはありません。
ベンチマークはJMHを使用して作成され、次のようになります。
``` package ru.klimakov; import org.openjdk.jmh.annotations.*; import java.util.Arrays; import java.util.Random; import java.util.concurrent.TimeUnit; @Fork(1) @Warmup(iterations = 10) @Measurement(iterations = 5) @BenchmarkMode(Mode.AverageTime ) @OutputTimeUnit(TimeUnit.MICROSECONDS) public class MyBenchmark { @State(Scope.Benchmark) public static class BenchmarkState { public static final int SEED = 42; public static final int ARRAY_LENGTH = 1_000_000; public static final int BOUND = 100_000; volatile long[] array; @Setup public void initState() { Random random = new Random(SEED); this.array = new long[ARRAY_LENGTH]; for (int i = 0; i < this.array.length; i++) { this.array[i] = random.nextInt(BOUND); } } } @Benchmark public long[] defaultParallelSort(BenchmarkState state) { Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] twoThreadsParallelSort(BenchmarkState state) { System.setProperty( "java.util.concurrent.ForkJoinPool.common.parallelism", "2"); Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] threeThreadsParallelSort(BenchmarkState state) { System.setProperty( "java.util.concurrent.ForkJoinPool.common.parallelism", "3"); Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] fourThreadsParallelSort(BenchmarkState state) { System.setProperty( "java.util.concurrent.ForkJoinPool.common.parallelism", "4"); Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] fiveThreadsParallelSort(BenchmarkState state) { System.setProperty( "java.util.concurrent.ForkJoinPool.common.parallelism", "5"); Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] tooLargePoolParallelSort(BenchmarkState state) { System.setProperty( "java.util.concurrent.ForkJoinPool.common.parallelism", "128"); Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] singleThreadParallelSort(BenchmarkState state) { System.setProperty( "java.util.concurrent.ForkJoinPool.common.parallelism", "1"); Arrays.parallelSort(state.array); return state.array; } @Benchmark public long[] serialSort(BenchmarkState state) { Arrays.sort(state.array); return state.array; } } ```
このコードを実行すると、次の最終結果が得られました(実際、いくつかの実行が行われ、数値はわずかに異なりましたが、全体像は変わりませんでした)。
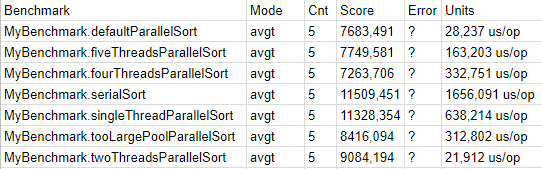
したがって、評価の勝者はfourThreadsParallelSortでした。 このテストでは、プールサイズをマシンのコア数に設定します。したがって、デフォルトのプールよりも1つ多く設定します。 それにもかかわらず、このマイクロベンチマークの勝利は、JDK開発者が示唆するように、コア数に等しいアプリケーション内のcommonPoolのサイズを決定し、1つ少ないワーカーを使用しないことを意味しません。 ほとんどのアプリケーションでは、それらの観点を受け入れてcommonPoolのサイズを変更しないことをお勧めしますが、マシンから最大値を絞り出し、より一般的なマクロベンチマークでゲームがろうそくに値することを証明する準備ができている場合、CPU使用率をより完全に向上させることができます。 commonPoolをコアの数に設定します。 同時に、ガベージコレクターなどのシステムスレッドがプールとプロセッサー時間を競い、オペレーティングシステムスケジューラーがコンテキストスイッチを作成してスレッドを中断することを忘れないでください。
defaultParallelSort-2位でした。 プールサイズ-3スレッド。 実行中のCPU使用率は約70%でしたが、前のケースでは90%でした。 したがって、並列ソートと呼ばれるメインプログラムフローが、フォーク結合タスクを掻き立てる本格的なワーカーになると主張するのは誤りであることが判明しました。
fiveThreadsParallelSort-プールサイズをコアの数よりも1つだけ多く設定することにより、どのように効果を失い始めるかを示しました。 このテストでは、CPU使用率は約95%でしたが、デフォルトでは少し低下しました。
tooLargePoolParallelSort-プールサイズ(この場合は最大128スレッド)を増やし続けると、効率が低下し続け、プロセッサーをさらに高密度に使用することを示しました(約100%)。
twoThreadsParallelSort-ランキングの最後の場所にあることが判明し、特に理由もなく仕事をせずにコアの1つをそのままにしておくと、結果が非常に平凡になることを示しました。
あなたは、serialSortとsingleThreadParallelSortについてはどうですか? しかし、何も。 これらは他のオプションと単純に比較することはできません。内部にはマージソートはまったくありませんが、完全に異なるアルゴリズム(DualPivotQuickSort)があり、異なる入力データでは、テストされたアルゴリズムよりも劣るまたはそれらよりも優れた結果を表示できます。 さらに言えば、考慮されたほとんどのランダム配列で、DualPivotQuickSortはArrays.parallelSortを大幅に上回り、今回はparallelSortが最良の結果を示した配列を生成することができました。 したがって、この特定の配列をベンチマークに含めることで、parallelSortを使用しても意味がないとは思わないようにしました。 時々それがありますが、それをチェックし、良いテストでそれを証明することを忘れないでください。
最後に、「どのような場合にcommonPoolのサイズを変更するのが合理的でしょうか?」という質問に答えてみましょう。 CPUをより高密度に利用したい場合、デフォルトで指定されているように、commonPoolのサイズをコア数に等しく設定し、1未満にしないことが意味がある場合があります。 別のケースとしては、アプリケーションと同時に他のアプリケーションが起動され、アプリケーション間でプロセッサコアを手動で分割したい場合があります(これらの目的にはdockerが適しているようです)。 そして最後に、Fork Join Poolに入れたいタスクが十分にクリーンでないことが判明する場合があります。 これらのタスクにより、RAMでの計算と読み取り/書き込みだけでなく、ブロッキング入力/出力ソースのスリープ、待機、読み取り/書き込みも可能になります。 この場合、そのようなタスクをcommonPoolに配置することはお勧めしません。これらのタスクはプールから貴重なスレッドを取得し、スレッドがスタンバイモードになり、このスレッドによって使用されるはずだったカーネルがアイドル状態になるためです。 したがって、このような少し眠いタスクには、個別のカスタムForkJoinPoolを作成することをお勧めします。
終わり
質問や提案はいつでも歓迎します。 待ってます、先生。