
こんにちは
自然言語では、無限の方法で同じ事実を言うことができます。 単語を所定の場所に並べ替えたり、同義語に置き換えたり、ケースごとに傾斜させたり(ケースで言語について話している場合)したりできます。
2つのフレーズの類似性を判断する必要性は、1つの小さな実用的な問題を解決する際に生じました。 機械学習を使用せず、ニューラルネットワークも使用しませんでしたが、単純なメトリックを使用して統計を収集し、係数を較正しました。
作業の結果、プロセスの説明、gitのコードをあなたと共有する準備ができました。
したがって、簡単に言えば、タスクは次のように述べることができます。 「一定の頻度で、現在のニュースはさまざまなソースから発信されます。 出力に同じ事実に関する2つのニュースがないように、それらをフィルターする必要があります。
警告:この記事には実際のニュースの見出しが含まれています。 私はそれらを専ら作業資料として扱い、どの国の政治的または経済的状況についても見解を表明しません。
タスクの制限
タスクには文字が適用されているため、制限を設定する必要があります。
- 各ニュースは、見出しと本文(コンテンツ)で構成されています。
- 見出しは、人がニュースの本質を理解できる自然言語の意味のある文です。
- タイトルは最大100文字です。 数字、句読点、特殊文字など、任意の文字で構成できます。
- 5分間隔で表示できる新しいニュースの最大数は20個です。
- 新しいニュースは、最終日に届いたすべてのニュースと比較する必要があります。
4ポイントと5ポイントの制限から、新しい制限を生成できます。新しいニュースと比較するニュースの最大数は24時間*(60分/ 5分)* 20個= 5760ニュースです。 (5分間で20の新しいニュースは仮想的に可能な値ですが、実際には15から20分で1または2の本当に新しいニュースが届きます。つまり、実際の値は24 *(60/15)* 1 = 96になります) 。
制限2から、ニュースの見出しをそのコンテンツに注意を払わずに分析するだけで十分であると結論付けました。
ヘッダーの例
16; 政府は千島開発プログラムに変更を加えました
18; 閣僚は、千島列島の連邦開発プログラムのための資金を増やしました
19; 政府は千島開発プログラムの資金を増やしました
6; エンジニアは労働市場で最も人気を集めています
12; ロシアで最も人気のある職業に選ばれました
20; ロシアで最も人気のある職業が知られるようになりました
26; ロシア連邦の労働市場で最も人気があると認められたエンジニア
32; エンジニアは9月にロシアの労働市場で最も人気がありました
51; ロシアで最も人気のある職業に選ばれました
53; 労働省がロシアで最も人気のある職業に指名
25; Sberbankは10月16日以降、消費者ローンの金利を引き下げます
31; ズベルバンクは多くのローンの金利を引き下げた
37; ズベルバンクは多くのローンの金利を引き下げました
0; ロシアは独自の暗号通貨をリリースする-暗号通貨
5; ロシアは暗号ルーブルを緊急に作成
27; ロシアでは暗号ルーブルのリリースに従事します
35; ロシアでは、彼らは独自の暗号通貨を作成します
36; ロシアは暗号瓦の生産を開始する
42; ロシアは独自の暗号通貨をリリースする-暗号ルーブル
ファジー文字列の比較方法
2行の類似度を決定する問題を解決するためのいくつかの方法を説明します。
レーベンシュタイン距離
ある行を別の行に変えるために必要な操作(挿入、削除、または置換)の数を示す数値を返します。
プロパティ:簡単な実装。 語順中毒; 出力番号; 何かと比較する必要があります。
帯状疱疹アルゴリズム
テキストを帯状疱疹(英語-スケール)に分割します。つまり、10個の単語のチェーン(交差点を含む)で、帯状疱疹にハッシュ関数を適用し、マトリックスを受け取ります。
プロパティ:アルゴリズムを実装するには、数学的な部分を詳細に調査する必要があります。 大きなテキストで動作します。 オファーの順序に依存しません。
ジャカード係数(商-係数。谷本)
次の式により係数を計算します。
K=c/(a+b−c)
ここで、aは1行目の文字数、bは2行目の文字数、cは一致する文字数です。
プロパティ:実装が簡単。 「abc」と「bca」は彼にとって同じだからです。
複合アプローチ
上記の各アルゴリズムには、解決する問題に対して重大な欠点があります。 その過程で、レーベンシュタイン距離とタニモト係数が計算されましたが、予想通り、それらは悪い結果を示しました。
経験的な考慮事項は、組み合わされたアプローチを以下のステップに結合します。
比較文の正規化
行は小文字に変換され、文字、数字、スペース以外のすべての文字が削除されます。
オファーの正規化
/// <summary> /// : /// - /// - /// </summary> /// <param name="sentence">.</param> /// <returns> .</returns> private string NormalizeSentence(string sentence) { var resultContainer = new StringBuilder(100); var lowerSentece = sentence.ToLower(); foreach (var c in lowerSentece) { if (IsNormalChar(c)) { resultContainer.Append(c); } } return resultContainer.ToString(); } /// <summary> /// . /// </summary> /// <param name="c">.</param> /// <returns>True - , False - .</returns> private bool IsNormalChar(char c) { return char.IsLetterOrDigit(c) || c == ' '; }
単語を強調する
単語は、スペースのないすべての文字シーケンスであると見なされ、長さは3以上です。これにより、ほとんどすべての前置詞、接続詞などが削除されます。 -これが正規化の継続に起因する程度。
単語を強調する
/// <summary> /// . /// </summary> /// <param name="sentence">.</param> /// <returns> .</returns> private string[] GetTokens(string sentence) { var tokens = new List<string>(); var words = sentence.Split(' '); foreach (var word in words) { if (word.Length >= MinWordLength) { tokens.Add(word); } } return tokens.ToArray(); }
部分文字列による単語の比較
ここではTanimoto係数が適用されますが、シンボルには適用されず、連続する文字のタプルに適用され、タプルはオーバーラップします。
あいまいな単語の比較
/// <summary> /// . /// </summary> /// <param name="firstToken"> .</param> /// <param name="secondToken"> .</param> /// <returns> .</returns> private bool IsTokensFuzzyEqual(string firstToken, string secondToken) { var equalSubtokensCount = 0; var usedTokens = new bool[secondToken.Length - SubtokenLength + 1]; for (var i = 0; i < firstToken.Length - SubtokenLength + 1; ++i) { var subtokenFirst = firstToken.Substring(i, SubtokenLength); for (var j = 0; j < secondToken.Length - SubtokenLength + 1; ++j) { if (!usedTokens[j]) { var subtokenSecond = secondToken.Substring(j, SubtokenLength); if (subtokenFirst.Equals(subtokenSecond)) { equalSubtokensCount++; usedTokens[j] = true; break; } } } } var subtokenFirstCount = firstToken.Length - SubtokenLength + 1; var subtokenSecondCount = secondToken.Length - SubtokenLength + 1; var tanimoto = (1.0 * equalSubtokensCount) / (subtokenFirstCount + subtokenSecondCount - equalSubtokensCount); return ThresholdWord <= tanimoto; }
Tanimoto係数をヘッダーに適用します
各文に含まれる単語の数、「ファジーマッチング」単語の数、およびこれに馴染みのある式を適用します。
文のファジー比較
/// <summary> /// . /// </summary> /// <param name="first"> .</param> /// <param name="second"> .</param> /// <returns> .</returns> public double CalculateFuzzyEqualValue(string first, string second) { if (string.IsNullOrWhiteSpace(first) && string.IsNullOrWhiteSpace(second)) { return 1.0; } if (string.IsNullOrWhiteSpace(first) || string.IsNullOrWhiteSpace(second)) { return 0.0; } var normalizedFirst = NormalizeSentence(first); var normalizedSecond = NormalizeSentence(second); var tokensFirst = GetTokens(normalizedFirst); var tokensSecond = GetTokens(normalizedSecond); var fuzzyEqualsTokens = GetFuzzyEqualsTokens(tokensFirst, tokensSecond); var equalsCount = fuzzyEqualsTokens.Length; var firstCount = tokensFirst.Length; var secondCount = tokensSecond.Length; var resultValue = (1.0 * equalsCount) / (firstCount + secondCount - equalsCount); return resultValue; } /// <summary> /// . /// </summary> /// <param name="tokensFirst"> .</param> /// <param name="tokensSecond"> .</param> /// <returns> .</returns> private string[] GetFuzzyEqualsTokens(string[] tokensFirst, string[] tokensSecond) { var equalsTokens = new List<string>(); var usedToken = new bool[tokensSecond.Length]; for (var i = 0; i < tokensFirst.Length; ++i) { for (var j = 0; j < tokensSecond.Length; ++j) { if (!usedToken[j]) { if (IsTokensFuzzyEqual(tokensFirst[i], tokensSecond[j])) { equalsTokens.Add(tokensFirst[i]); usedToken[j] = true; break; } } } } return equalsTokens.ToArray(); }
アルゴリズムは数日にわたって数百のヘッダーでテストされ、その作業の結果は視覚的には許容できることが判明しましたが、次の係数を最適に選択する必要がありました。
ThresholdSentence-文全体のファジー等価の採用のしきい値。
ThresholdWord -2つの単語間のファジー等価を受け入れるためのしきい値 。
SubtokenLength -2つの単語を比較するときの部分文字列のサイズ(1からMinWordLengthまで)
性能評価アルゴリズム
仕事の質を評価するために、100の異なるニュースヘッドラインが選択され、次々と来ました。 次に、100x100の正方行列がマークアウトされました。見出しが異なるトピックにある場合は0、トピックが一致する場合は1を設定しました。 サンプルが小さく、アルゴリズムの精度が非常に正確に表示されない場合があることは理解していますが、それ以上はありませんでした。
アルゴリズムの出力を比較できるサンプルが用意されたので、単純な式(比較の総数に対する正解の比率)で精度を評価します。 さらに、メトリックとして、誤検知の数を推定できます。
87%の精度と3%の誤検知の数で最良の結果が得られるのは、次のパラメーターを使用した場合です。ThresholdSentence= 0.25、ThresholdWord = 0.45、SubtokenLength = 2;
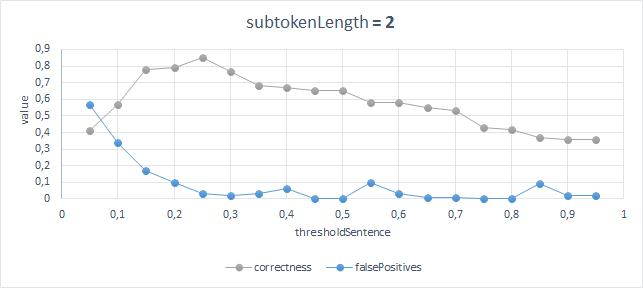
アルゴリズムの結果とモデルの比較
結果は次のように解釈できます。
単語を比較するときに、部分文字列の長さを2文字と見なす場合、最高の精度と最小のエラーが得られますが、一致する部分文字列の数と一致しない部分文字列の数の比率は0.45以上である必要があり、単語の4分の1以上が一致する場合、2つの見出しは同等になります。
導入された制限を考慮すると、結果は非常に正確です。 もちろん、人為的に必要な数のオプションを考え出すことができ、そのオプションに誤検出が表示されます。
誤検知の実際の例
VTBは現金ローンの最低金利を引き下げました
ズベルバンクは多くのローンの金利を引き下げました
おわりに
このタスクの起源は、関連するニュースの迅速な配信を自分で手配する必要があるという事実にあります。 情報のソース-インターネットに座っている間、私が絶えず読んでいて、多くの時間を失い、不必要な情報、不必要なクリックリンクに気を取られているメディア。 その結果、連絡先のいくつかの小さな電報チャネルとグループが生まれました。 突然誰かが興味を持ったら、リンクは私のプロフィールの説明の中にあります。
ライブラリ形式のアルゴリズムの既製の実装: SentencesFuzzyComparison 。