
こんにちは、Habr!
Rユーザーは長い間、ディープラーニングに参加する機会を奪われており、単一のプログラミング言語のフレームワーク内にとどまっています。 MXNetのリリースにより状況は変わり始めましたが、後方互換性を損なう独特のドキュメントや頻繁な変更がこのライブラリの人気を制限しています。
さらに魅力的なのは、 TensorFlowとKerasでRインターフェースを使用し、バックエンド(TensorFlow、Theano、CNTK)から選択できること、詳細なドキュメント、および多くの例です。 このメッセージでは、 Carvana Image Masking Challenge ( 勝者 )を例として使用し、背景から16の異なる角度から撮影した車を分離する方法を学習する必要がある画像セグメンテーションの問題の解決策を分析します。 「ニューラルネットワーク」部分はKerasに完全に実装され、 magick ( ImageMagickへのインターフェース)は画像処理を担当し、並列処理はparallel + doParallel + foreach (Windows)またはparallel + doMC + foreach (Linux)によって提供されます。
内容:
- 必要なものをすべてインストールする
- 画像操作: OpenCVの代替としてのmagick
- WindowsとLinuxでRコードを同時に実行する
- 網状および反復子
- セグメンテーションの問題とその損失関数
- U-Netアーキテクチャ
- モデルトレーニング
- モデルベースの予測
1.必要なものすべてをインストールする
リーダーにはすでに4 GB以上のメモリを備えたNvidia GPUがあり(おそらくそれ以下ですが、それほどおもしろくない)、CUDAおよびcuDNNライブラリもインストールされていると想定しています。 Linuxの場合、後者のインストールは簡単で( 多くのマニュアルの1つ )、Windowsの場合はさらに簡単です( マニュアルの「CUDA&cuDNN」セクションを参照)。
次に、Python 3でAnacondaディストリビューションをインストールすることをお勧めします。 スペースを節約するために、Minicondaの最小オプションを選択できます。 ディストリビューションのPythonバージョンがconda install python=3.6
サポートされている最後のバージョンよりも先にある場合、 conda install python=3.6
という形式のコマンドで置き換えることができます。 また、すべてが通常のPythonおよび仮想環境で動作します。
使用されるRパッケージのリストは次のとおりです。
library(keras) library(magick) library(abind) library(reticulate) library(parallel) library(doParallel) library(foreach)
library(keras) library(magick) library(abind) library(reticulate) library(parallel) library(doMC) library(foreach)
これらはすべてCRANでインストールされますが、 devtools::install_github("rstudio/keras")
はGithubで使用するのが最適です: devtools::install_github("rstudio/keras")
。 続いてinstall_keras()
コマンドを実行すると、conda環境が作成され、TensorflowとKerasの正しいPythonバージョンがインストールされます 。 何らかの理由でこのコマンドが正しく機能しない場合(たとえば、必要なPythonディストリビューションが見つからなかった場合)、または使用するライブラリの特定のバージョンが必要な場合は、 conda環境を自分で作成し 、必要なパッケージをインストールしてから、Rでレチクルパッケージを指定する必要がありますこの環境はuse_condaenv()
コマンドを使用しています。
以下で使用されるパラメーターのリスト:
input_size <- 128 # , epochs <- 30 # batch_size <- 16 # orig_width <- 1918 # orig_height <- 1280 # train_samples <- 5088 # train_index <- sample(1:train_samples, round(train_samples * 0.8)) # 80% val_index <- c(1:train_samples)[-train_index] # images_dir <- "input/train/" masks_dir <- "input/train_masks/"
2.画像操作: OpenCVの代替としてのmagick
グラフィックデータで機械学習の問題を解決する場合、少なくともディスクから画像を読み取り、配列の形でニューラルネットワークに転送できる必要があります。 通常、いわゆる拡張を実装するために、さまざまな画像変換を実行できる必要もあります。トレーニングセットに、トレーニングセット自体に実際に存在するサンプルから作成された人工的なサンプルを追加します。 拡張は、(ほとんど)モデルの品質を常に向上させることができます 。たとえば、 このメッセージから基本的な理解を得ることができます 。 今後は、これらすべてを迅速かつマルチスレッドで実行する必要があることに注意してください。比較的高速なCPUや比較的低速のビデオカードであっても、準備段階はニューラルネットワーク自体をトレーニングするよりも多くのリソースを消費します。
Pythonは伝統的にOpenCVを使用して画像を処理します。 R用のこのメガバイトライブラリのバージョンはまだ作成されておらず、その関数をレチクル経由で呼び出すことはスポーツマンらしくないソリューションのように見えるため、利用可能な代替案から選択します。
最も強力な上位3つのグラフィックパッケージは次のとおりです。
EBImage-パッケージはS4クラスを使用して作成され、Bioconductoraリポジトリに配置されました。これは、パッケージ自体とそのドキュメントの両方の品質に対する最高の要件を意味します。 残念ながら、このソフトウェア製品の膨大な機能を楽しむことは、その非常に遅い速度によって妨げられています。
imager-このパッケージの主な作業はCImgライブラリに面したコンパイルされたコードによって実行されるため、このパッケージはパフォーマンスの面でより興味深いように見えます。 利点の中でも、「パイプライン」演算子
%>%
(およびmagrittrの他の演算子)のサポート 、いわゆるパッケージとの緊密な統合に注目できます。 tigpverse(ggplot2を含む) 、およびsplit-apply-combineイデオロギーのサポート。 また、一部のPCで画像を読み取るための機能が動作不能になった不可解なバグだけが、このメッセージの作成者がこのパッケージを選択できないようにしました。
- magickは、 ImageMagickのラッパーパッケージであり、 rOpenSciコミュニティのメンバーによって開発され、積極的に開発されています。 Tesseract OCRライブラリーとの統合という形で、以前のパッケージのすべての利点、安定性、バグのないこと、およびキラー機能(タスクの一部としては役に立たない)を組み合わせています。 異なるコア数で画像を読み取って変換するときの速度の測定値を以下に示します。 マイナス記号のうち、難解な構文は場所に注意することができます。たとえば、切り取りやサイズ変更を行うには、関数の
height
とwidth
の型の通常の引数の代わりに"100x150+50"
という形式の文字列を渡す必要があります。 前処理の補助関数はこれらの値によって正確にパラメーター化されるため、paste0(...)
構造paste0(...)
またはsprintf(...)
を使用する必要があります。
以下、Peter GiannakopoulosのKerasによるKaggle Carvana Image Masking Challengeソリューションの概要を説明します。
ファイルをペアで読み取る必要があります-画像とそれに対応するマスク、また、拡張を使用する場合は同じ変換(回転、シフト、反射、ズーム)を画像とマスクに適用する必要があります。 1つの関数の形式で読み取りを実現します。これにより、写真がすぐに目的のサイズに縮小されます。
imagesRead <- function(image_file, mask_file, target_width = 128, target_height = 128) { img <- image_read(image_file) img <- image_scale(img, paste0(target_width, "x", target_height, "!")) mask <- image_read(mask_file) mask <- image_scale(mask, paste0(target_width, "x", target_height, "!")) list(img = img, mask = mask) }
画像をマスクした関数の結果:
img <- "input/train/0cdf5b5d0ce1_01.jpg" mask <- "input/train_masks/0cdf5b5d0ce1_01_mask.png" x_y_imgs <- imagesRead(img, mask, target_width = 400, target_height = 400) image_composite(x_y_imgs$img, x_y_imgs$mask, operator = "blend", compose_args = "60") %>% image_write(path = "pics/pic1.jpg", format = "jpg")

増強の最初の種類は、明るさ、彩度、色相の変化です。 明らかな理由から、カラー画像に適用されますが、白黒マスクには適用されません。
randomBSH <- function(img, u = 0, brightness_shift_lim = c(90, 110), # percentage saturation_shift_lim = c(95, 105), # of current value hue_shift_lim = c(80, 120)) { if (rnorm(1) < u) return(img) brightness_shift <- runif(1, brightness_shift_lim[1], brightness_shift_lim[2]) saturation_shift <- runif(1, saturation_shift_lim[1], saturation_shift_lim[2]) hue_shift <- runif(1, hue_shift_lim[1], hue_shift_lim[2]) img <- image_modulate(img, brightness = brightness_shift, saturation = saturation_shift, hue = hue_shift) img }
この変換は50%の確率で適用されます(半分の場合、元の画像が返されます: if (rnorm(1) < u) return(img)
)、3つのパラメーターのそれぞれの変更値は、元の割合として指定された値の範囲内でランダムに選択されます数量。
また、50%の確率で、画像とマスクの水平反射を使用します。
randomHorizontalFlip <- function(img, mask, u = 0) { if (rnorm(1) < u) return(list(img = img, mask = mask)) list(img = image_flop(img), mask = image_flop(mask)) }
結果:
img <- "input/train/0cdf5b5d0ce1_01.jpg" mask <- "input/train_masks/0cdf5b5d0ce1_01_mask.png" x_y_imgs <- imagesRead(img, mask, target_width = 400, target_height = 400) x_y_imgs$img <- randomBSH(x_y_imgs$img) x_y_imgs <- randomHorizontalFlip(x_y_imgs$img, x_y_imgs$mask) image_composite(x_y_imgs$img, x_y_imgs$mask, operator = "blend", compose_args = "60") %>% image_write(path = "pics/pic2.jpg", format = "jpg")

さらに表示するための残りの変換は基本的なものではないため、それらについては説明しません。
最後の段階では、写真を配列に変換します。
img2arr <- function(image, target_width = 128, target_height = 128) { result <- aperm(as.numeric(image[[1]])[, , 1:3], c(2, 1, 3)) # transpose dim(result) <- c(1, target_width, target_height, 3) return(result) } mask2arr <- function(mask, target_width = 128, target_height = 128) { result <- t(as.numeric(mask[[1]])[, , 1]) # transpose dim(result) <- c(1, target_width, target_height, 1) return(result) }
画像の行が行列の行のままになるように転置が必要です:画像は行ごとに形成されます(キネスコープで走査ビームが移動するため)、Rの行列は列で埋められます(列優先 、またはFortranスタイル、比較のため、 numpyで)列優先形式と行優先形式を切り替えることができます)。 それなしでもできますが、より理解しやすいです。
3. WindowsおよびLinuxでのRコードの並列実行
Rでの並列計算の一般的な理解は、チュートリアルパッケージ 'parallel' 、 doParallelとforeachの 入門 、およびdoMCとforeachの 入門にあります。 操作アルゴリズムは次のとおりです。
必要なコア数でクラスターを開始します。
cl <- makePSOCKcluster(4) # doParallel
SOCKクラスターは、複数のPCのCPUを使用する機能を含む、ユニバーサルソリューションです。 残念ながら、イテレータとニューラルネットワークトレーニングを使用したこの例はWindowsで機能しますが、Linuxでは機能しません。 Linuxでは、代替のdoMCパッケージを使用できます。これは、元のプロセスのフォークを使用してクラスターを作成します。 残りの手順を実行する必要はありません。
registerDoMC(4) # doMC
doParallelとdoMCの両方が、 並列機能とforeach機能を仲介します。
makePSOCKcluster()
を使用する場合、必要なパッケージと機能をクラスターにロードする必要があります。
clusterEvalQ(cl, { library(magick) library(abind) library(reticulate) imagesRead <- function(image_file, mask_file, target_width = 128, target_height = 128) { img <- image_read(image_file) img <- image_scale(img, paste0(target_width, "x", target_height, "!")) mask <- image_read(mask_file) mask <- image_scale(mask, paste0(target_width, "x", target_height, "!")) return(list(img = img, mask = mask)) } randomBSH <- function(img, u = 0, brightness_shift_lim = c(90, 110), # percentage saturation_shift_lim = c(95, 105), # of current value hue_shift_lim = c(80, 120)) { if (rnorm(1) < u) return(img) brightness_shift <- runif(1, brightness_shift_lim[1], brightness_shift_lim[2]) saturation_shift <- runif(1, saturation_shift_lim[1], saturation_shift_lim[2]) hue_shift <- runif(1, hue_shift_lim[1], hue_shift_lim[2]) img <- image_modulate(img, brightness = brightness_shift, saturation = saturation_shift, hue = hue_shift) img } randomHorizontalFlip <- function(img, mask, u = 0) { if (rnorm(1) < u) return(list(img = img, mask = mask)) list(img = image_flop(img), mask = image_flop(mask)) } img2arr <- function(image, target_width = 128, target_height = 128) { result <- aperm(as.numeric(image[[1]])[, , 1:3], c(2, 1, 3)) # transpose dim(result) <- c(1, target_width, target_height, 3) return(result) } mask2arr <- function(mask, target_width = 128, target_height = 128) { result <- t(as.numeric(mask[[1]])[, , 1]) # transpose dim(result) <- c(1, target_width, target_height, 1) return(result) } })
foreachの並列バックエンドとしてクラスターを登録します。
registerDoParallel(cl)
その後、コードを並列モードで実行できます。
imgs <- list.files("input/train/", pattern = ".jpg", full.names = TRUE)[1:16] masks <- list.files("input/train_masks/", pattern = ".png", full.names = TRUE)[1:16] x_y_batch <- foreach(i = 1:16) %dopar% { x_y_imgs <- imagesRead(image_file = batch_images_list[i], mask_file = batch_masks_list[i]) # augmentation x_y_imgs$img <- randomBSH(x_y_imgs$img) x_y_imgs <- randomHorizontalFlip(x_y_imgs$img, x_y_imgs$mask) # return as arrays x_y_arr <- list(x = img2arr(x_y_imgs$img), y = mask2arr(x_y_imgs$mask)) } str(x_y_batch) # List of 16 # $ :List of 2 # ..$ x: num [1, 1:128, 1:128, 1:3] 0.953 0.957 0.953 0.949 0.949 ... # ..$ y: num [1, 1:128, 1:128, 1] 0 0 0 0 0 0 0 0 0 0 ... # $ :List of 2 # ..$ x: num [1, 1:128, 1:128, 1:3] 0.949 0.957 0.953 0.949 0.949 ... # ..$ y: num [1, 1:128, 1:128, 1] 0 0 0 0 0 0 0 0 0 0 ... # ....
最後に、クラスターを停止することを忘れないでください。
stopCluster(cl)
マイクロベンチマークパッケージを使用して、複数のコア/スレッドを使用する利点を確認します。 4 GBのメモリを搭載したGPUでは、16ペアのイメージのバッチを操作できます。つまり、2、4、8、または16スレッドを使用することをお勧めします(時間は秒単位で示されます)。
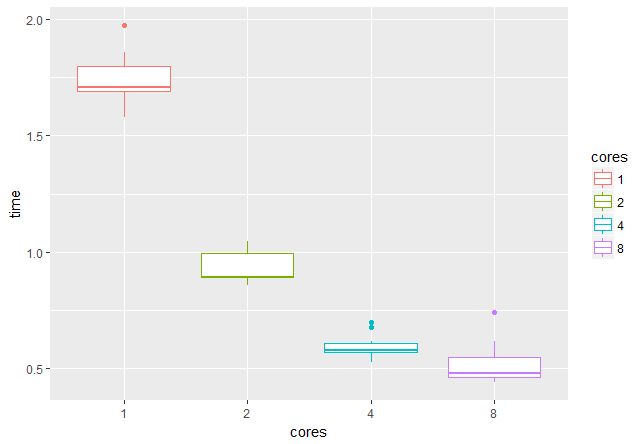
16スレッドをチェックすることはできませんでしたが、1スレッドから4スレッドに切り替えると、速度が約3倍になり、非常に楽しいことは明らかです。
4. 網状および反復子
メモリに収まらないデータを処理するには、 reticulateパッケージの反復子を使用します。 基本は、通常のクロージャー関数、つまり呼び出されると、呼び出し環境とともに別の関数を返す関数です。
train_generator <- function(images_dir, samples_index, masks_dir, batch_size) { images_iter <- list.files(images_dir, pattern = ".jpg", full.names = TRUE)[samples_index] # for current epoch images_all <- list.files(images_dir, pattern = ".jpg", full.names = TRUE)[samples_index] # for next epoch masks_iter <- list.files(masks_dir, pattern = ".gif", full.names = TRUE)[samples_index] # for current epoch masks_all <- list.files(masks_dir, pattern = ".gif", full.names = TRUE)[samples_index] # for next epoch function() { # start new epoch if (length(images_iter) < batch_size) { images_iter <<- images_all masks_iter <<- masks_all } batch_ind <- sample(1:length(images_iter), batch_size) batch_images_list <- images_iter[batch_ind] images_iter <<- images_iter[-batch_ind] batch_masks_list <- masks_iter[batch_ind] masks_iter <<- masks_iter[-batch_ind] x_y_batch <- foreach(i = 1:batch_size) %dopar% { x_y_imgs <- imagesRead(image_file = batch_images_list[i], mask_file = batch_masks_list[i]) # augmentation x_y_imgs$img <- randomBSH(x_y_imgs$img) x_y_imgs <- randomHorizontalFlip(x_y_imgs$img, x_y_imgs$mask) # return as arrays x_y_arr <- list(x = img2arr(x_y_imgs$img), y = mask2arr(x_y_imgs$mask)) } x_y_batch <- purrr::transpose(x_y_batch) x_batch <- do.call(abind, c(x_y_batch$x, list(along = 1))) y_batch <- do.call(abind, c(x_y_batch$y, list(along = 1))) result <- list(keras_array(x_batch), keras_array(y_batch)) return(result) } }
val_generator <- function(images_dir, samples_index, masks_dir, batch_size) { images_iter <- list.files(images_dir, pattern = ".jpg", full.names = TRUE)[samples_index] # for current epoch images_all <- list.files(images_dir, pattern = ".jpg", full.names = TRUE)[samples_index] # for next epoch masks_iter <- list.files(masks_dir, pattern = ".gif", full.names = TRUE)[samples_index] # for current epoch masks_all <- list.files(masks_dir, pattern = "gif", full.names = TRUE)[samples_index] # for next epoch function() { # start new epoch if (length(images_iter) < batch_size) { images_iter <<- images_all masks_iter <<- masks_all } batch_ind <- sample(1:length(images_iter), batch_size) batch_images_list <- images_iter[batch_ind] images_iter <<- images_iter[-batch_ind] batch_masks_list <- masks_iter[batch_ind] masks_iter <<- masks_iter[-batch_ind] x_y_batch <- foreach(i = 1:batch_size) %dopar% { x_y_imgs <- imagesRead(image_file = batch_images_list[i], mask_file = batch_masks_list[i]) # without augmentation # return as arrays x_y_arr <- list(x = img2arr(x_y_imgs$img), y = mask2arr(x_y_imgs$mask)) } x_y_batch <- purrr::transpose(x_y_batch) x_batch <- do.call(abind, c(x_y_batch$x, list(along = 1))) y_batch <- do.call(abind, c(x_y_batch$y, list(along = 1))) result <- list(keras_array(x_batch), keras_array(y_batch)) return(result) } }
ここで、コール環境では、各時代に減少する処理済みファイルのリストと、次の各時代の初めに使用される完全なリストのコピーが保存されます。 この実装では、ランダムなファイルのシャッフルについて心配する必要はありません-各バッチはランダムなサンプリングによって取得されます。
上記のように、 x_y_batch
は16個のリストのリストであり、各リストは2つの配列のリストです。 purrr::transpose()
関数はネストされたリストを裏返しにし、それぞれが16配列のリストである2つのリストのリストを取得します。 abind()
は指定された次元に沿って配列を結合し、 do.call()
は任意の数の引数を内部関数に渡します。 追加の引数( along = 1
)は非常に奇妙な方法で与えられます: do.call(abind, c(x_y_batch$x, list(along = 1)))
。
これらの関数をpy_iterator()
理解するオブジェクトに変えることは残っています:
train_iterator <- py_iterator(train_generator(images_dir = images_dir, masks_dir = masks_dir, samples_index = train_index, batch_size = batch_size)) val_iterator <- py_iterator(val_generator(images_dir = images_dir, masks_dir = masks_dir, samples_index = val_index, batch_size = batch_size))
iter_next(train_iterator)
を呼び出すと、1つの反復の結果が返されます。これは、デバッグフェーズで役立ちます。
5.セグメンテーションの問題とその損失関数
セグメンテーションの問題は、ピクセルごとの分類と見なすことができます。各ピクセルは特定のクラスに属すると予測されます。 2つのクラスの場合、結果はマスクになります。 クラスが3つ以上ある場合、マスクの数は、クラスの数から1を引いたものに等しくなります(ワンホットエンコードのアナログ)。 私たちの競争では、2つのクラス(車と背景)のみがあり、品質メトリックはサイコロ係数です。 彼はこの方法で計算します:
K <- backend() dice_coef <- function(y_true, y_pred, smooth = 1.0) { y_true_f <- K$flatten(y_true) y_pred_f <- K$flatten(y_pred) intersection <- K$sum(y_true_f * y_pred_f) result <- (2 * intersection + smooth) / (K$sum(y_true_f) + K$sum(y_pred_f) + smooth) return(result) }
損失関数を最適化します。これは、クロスエントロピーと1 - dice_coef
です。
bce_dice_loss <- function(y_true, y_pred) { result <- loss_binary_crossentropy(y_true, y_pred) + (1 - dice_coef(y_true, y_pred)) return(result) }
6. U-Netアーキテクチャ
U-Netはセグメンテーションの問題を解決するための古典的なアーキテクチャです。 回路図:
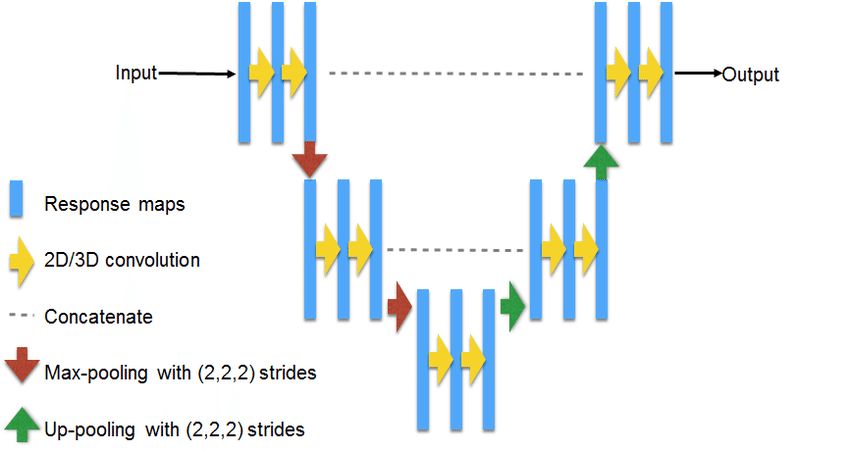
ソース: https : //www.researchgate.net/figure/311715357_fig3_Fig-3-U-NET-Architecture
写真128x128の実装:
get_unet_128 <- function(input_shape = c(128, 128, 3), num_classes = 1) { inputs <- layer_input(shape = input_shape) # 128 down1 <- inputs %>% layer_conv_2d(filters = 64, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 64, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") down1_pool <- down1 %>% layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2)) # 64 down2 <- down1_pool %>% layer_conv_2d(filters = 128, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 128, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") down2_pool <- down2 %>% layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2)) # 32 down3 <- down2_pool %>% layer_conv_2d(filters = 256, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 256, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") down3_pool <- down3 %>% layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2)) # 16 down4 <- down3_pool %>% layer_conv_2d(filters = 512, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 512, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") down4_pool <- down4 %>% layer_max_pooling_2d(pool_size = c(2, 2), strides = c(2, 2)) # 8 center <- down4_pool %>% layer_conv_2d(filters = 1024, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 1024, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") # center up4 <- center %>% layer_upsampling_2d(size = c(2, 2)) %>% {layer_concatenate(inputs = list(down4, .), axis = 3)} %>% layer_conv_2d(filters = 512, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 512, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 512, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") # 16 up3 <- up4 %>% layer_upsampling_2d(size = c(2, 2)) %>% {layer_concatenate(inputs = list(down3, .), axis = 3)} %>% layer_conv_2d(filters = 256, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 256, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 256, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") # 32 up2 <- up3 %>% layer_upsampling_2d(size = c(2, 2)) %>% {layer_concatenate(inputs = list(down2, .), axis = 3)} %>% layer_conv_2d(filters = 128, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 128, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 128, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") # 64 up1 <- up2 %>% layer_upsampling_2d(size = c(2, 2)) %>% {layer_concatenate(inputs = list(down1, .), axis = 3)} %>% layer_conv_2d(filters = 64, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 64, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") %>% layer_conv_2d(filters = 64, kernel_size = c(3, 3), padding = "same") %>% layer_batch_normalization() %>% layer_activation("relu") # 128 classify <- layer_conv_2d(up1, filters = num_classes, kernel_size = c(1, 1), activation = "sigmoid") model <- keras_model( inputs = inputs, outputs = classify ) model %>% compile( optimizer = optimizer_rmsprop(lr = 0.0001), loss = bce_dice_loss, metrics = c(dice_coef) ) return(model) } model <- get_unet_128()
{layer_concatenate(inputs = list(down4, .), axis = 3)}
の中括弧は、 %>%
演算子のように最初のオブジェクトとしてではなく、必要な引数としてオブジェクトを置き換えるために必要です。 このアーキテクチャの多くの変更を提供できます: layer_conv_2d_transpose
代わりにlayer_upsampling_2d
使用し、通常のlayer_separable_conv_2d
代わりにlayer_separable_conv_2d
個別の畳み込みを適用し、フィルター番号とオプティマイザー設定を試します。 Kerasリンク付きのKaggle Carvana Image Masking Challengeソリューションには 、1024x1024までの解像度のオプションがあり、これもRに簡単に移植できます。
このモデルには多くのパラメーターがあります。
# Total params: 34,540,737 # Trainable params: 34,527,041 # Non-trainable params: 13,696
7.モデルトレーニング
ここではすべてが簡単です。 Tensorboardを起動します。
tensorboard("logs_r")
別の方法として、 tfrunsパッケージを使用できます 。これにより、TensorboardアナログがRStudio IDEに追加され、ニューラルネットワークのトレーニング作業を合理化できます。
コールバックを指定します。 早期停止を使用し、プラトーに達したときのトレーニングの速度を低下させ、最適なモデルの重量を維持します。
callbacks_list <- list( callback_tensorboard("logs_r"), callback_early_stopping(monitor = "val_python_function", min_delta = 1e-4, patience = 8, verbose = 1, mode = "max"), callback_reduce_lr_on_plateau(monitor = "val_python_function", factor = 0.1, patience = 4, verbose = 1, epsilon = 1e-4, mode = "max"), callback_model_checkpoint(filepath = "weights_r/unet128_{epoch:02d}.h5", monitor = "val_python_function", save_best_only = TRUE, save_weights_only = TRUE, mode = "max" ) )
トレーニングを開始して待機します。 GTX 1050tiでは、1つの時代に約10分かかります。
model %>% fit_generator( train_iterator, steps_per_epoch = as.integer(length(train_index) / batch_size), epochs = epochs, validation_data = val_iterator, validation_steps = as.integer(length(val_index) / batch_size), verbose = 1, callbacks = callbacks_list )
8.モデルベースの予測
- run-length encoding.
test_dir <- "input/test/" test_samples <- 100064 test_index <- sample(1:test_samples, 1000) load_model_weights_hdf5(model, "weights_r/unet128_08.h5") # best model imageRead <- function(image_file, target_width = 128, target_height = 128) { img <- image_read(image_file) img <- image_scale(img, paste0(target_width, "x", target_height, "!")) } img2arr <- function(image, target_width = 128, target_height = 128) { result <- aperm(as.numeric(image[[1]])[, , 1:3], c(2, 1, 3)) # transpose dim(result) <- c(1, target_width, target_height, 3) return(result) } arr2img <- function(arr, target_width = 1918, target_height = 1280) { img <- image_read(arr) img <- image_scale(img, paste0(target_width, "x", target_height, "!")) } qrle <- function(mask) { img <- t(mask) dim(img) <- c(128, 128, 1) img <- arr2img(img) arr <- as.numeric(img[[1]])[, , 2] vect <- ifelse(as.vector(arr) >= 0.5, 1, 0) turnpoints <- c(vect, 0) - c(0, vect) starts <- which(turnpoints == 1) ends <- which(turnpoints == -1) paste(c(rbind(starts, ends - starts)), collapse = " ") } cl <- makePSOCKcluster(4) clusterEvalQ(cl, { library(magick) library(abind) library(reticulate) imageRead <- function(image_file, target_width = 128, target_height = 128) { img <- image_read(image_file) img <- image_scale(img, paste0(target_width, "x", target_height, "!")) } img2arr <- function(image, target_width = 128, target_height = 128) { result <- aperm(as.numeric(image[[1]])[, , 1:3], c(2, 1, 3)) # transpose dim(result) <- c(1, target_width, target_height, 3) return(result) } qrle <- function(mask) { img <- t(mask) dim(img) <- c(128, 128, 1) img <- arr2img(img) arr <- as.numeric(img[[1]])[, , 2] vect <- ifelse(as.vector(arr) >= 0.5, 1, 0) turnpoints <- c(vect, 0) - c(0, vect) starts <- which(turnpoints == 1) ends <- which(turnpoints == -1) paste(c(rbind(starts, ends - starts)), collapse = " ") } }) registerDoParallel(cl) test_generator <- function(images_dir, samples_index, batch_size) { images_iter <- list.files(images_dir, pattern = ".jpg", full.names = TRUE)[samples_index] function() { batch_ind <- sample(1:length(images_iter), batch_size) batch_images_list <- images_iter[batch_ind] images_iter <<- images_iter[-batch_ind] x_batch <- foreach(i = 1:batch_size) %dopar% { img <- imageRead(image_file = batch_images_list[i]) # return as array arr <- img2arr(img) } x_batch <- do.call(abind, c(x_batch, list(along = 1))) result <- list(keras_array(x_batch)) } } test_iterator <- py_iterator(test_generator(images_dir = test_dir, samples_index = test_index, batch_size = batch_size)) preds <- predict_generator(model, test_iterator, steps = 10) preds <- foreach(i = 1:160) %dopar% { result <- qrle(preds[i, , , ]) } preds <- do.call(rbind, preds)
, qrle
, ( skoffer -):
:

— 128128. , , .
, .
合計
このメッセージでは、Rの上に座ってファッションのトレンドに遅れずについていくことができ、ディープニューラルネットワークをうまくトレーニングできることが示されました。さらに、Windowsでさえこれを防ぐことはできません。
継続するには、通常どおり、次のようにします。