
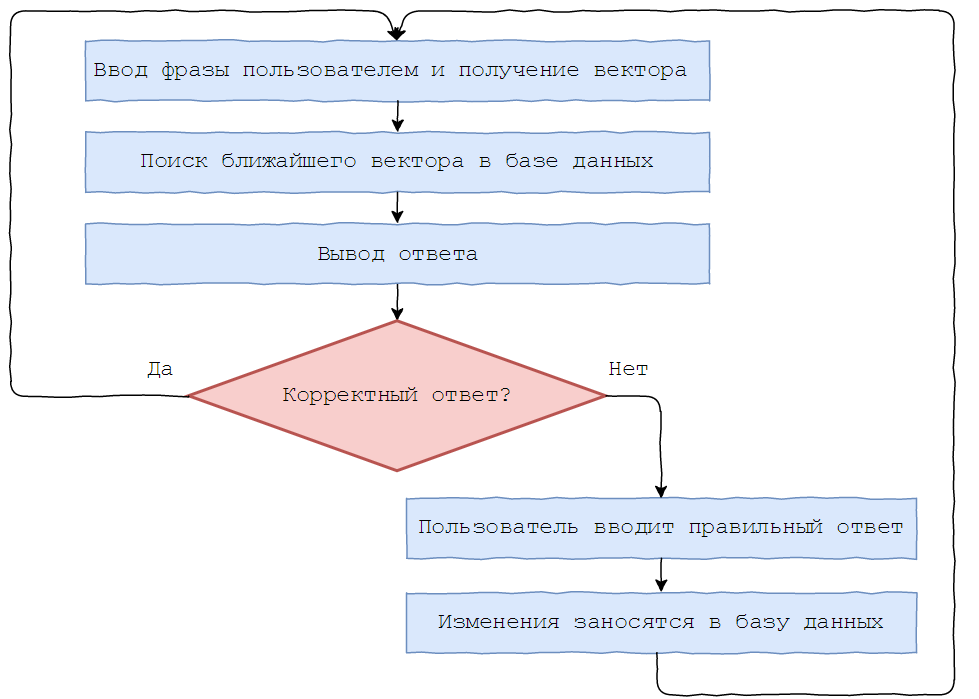
数年前、 インタビューが公開され、人工知能、特にチャットボットについて話しました。 回答者は、チャットボットは通信しないが、通信を模倣することを強調しています。
彼らは、完全に人間レベルのインテリジェントなマイクロダイアログのコアを構築し、このコアへの会話を絶えず減らす通信アルゴリズムを構築しました。 それだけです。私の意見では、これには何かがあります...
それでも、Habréではチャットボットについて多くの話があります。 それらは非常に異なる場合があります。 単語ごとの応答を生成するニューラル予測ネットワークに基づくボットが一般的です。 これは非常に興味深いものですが、実装の観点から、特に大量の単語形式のためにロシア語の場合は高価です。 Boltoonチャットボットを実装するために別のアプローチを選択しました。
Boltoonは、提案されたデータベースから最も意味的に最も近い回答を選択し、その後の処理を行うという原則に基づいて動作します。 このアプローチにはいくつかの利点があります。
- 作業速度;
- Chatbotはさまざまなタスクに使用できます。そのためには、新しいデータベースをダウンロードする必要があります。
- データベースを更新した後、ボットは追加のトレーニングを必要としません。
どのように機能しますか?
それらに対する質問と回答を含むデータベースがあります。

ボットが入力されたフレーズの意味をよく認識し、データベース内で類似したフレーズを見つけることが必要です。 たとえば、「お元気ですか?」、「お元気ですか?」、「お元気ですか?」という意味です。 なぜなら コンピューターは文字ではなく数字でうまく機能します。入力したフレーズと既存のフレーズとの対応の検索は、数字の比較に限定する必要があります。 データベースからの質問を含む列全体を数値に、またはN個の実数のベクトルに変換する必要があります。 したがって、すべてのドキュメントはN次元空間の座標を受け取ります。 想像するのは困難ですが、明確にするためにスペースの次元を2に減らすことができます。

同じ空間で、ユーザーが入力したフレーズの座標を見つけ、コサインメトリックに従って利用可能なフレーズと比較し、最も近いものを見つけます。 Boltoonは、このような単純なアイデアに基づいています。
次に、すべての順序とより正式な言語について説明します。 「テキストのベクトル表現」(単語の埋め込み)-マッピングの概念を紹介します 自然言語から固定長のベクトルへの単語(通常は100から500次元、この値が高いほど表現はより正確になりますが、計算が難しくなります)。
たとえば、「科学」、「本」という言葉の意味は次のとおりです。
v( "science")= [0.956、-1.987 ...]
v(「本」)= [0.894、0.234 ...]
Habréについてはすでにそれについて書いています( ここで詳細を読むことができます )。 このタスクには、 分散テキスト表示モデルが最適です。 特定の「意味の空間」、つまりすべての単語、文、または段落がポイントとなるN次元の球体があると想像してください。 問題は、それを構築する方法ですか?
2013年、 「ベクトル空間での単語表現の効率的な推定」という記事がThomas Mikolovによって登場し 、word2vecについて語っています 。 これは、単語の分散表現を見つけるためのアルゴリズムのセットです。 したがって、各単語は特定のセマンティック空間のポイントに変換され、この空間での代数演算は単語の意味の演算に対応します(したがって、セマンティック単語を使用します)。
写真は、「女性らしさ」ベクトルの例として、空間のこの非常に重要な特性を示しています。 単語「king」のベクトルから単語「man」のベクトルを減算し、単語「woman」のベクトルを追加すると、「queen」が得られます。 Yandexの講義でより多くの例を見つけることができます。また、特別な数学のないword2vecの説明があります。

Pythonでは、このように見えます(gensimパッケージをインストールする必要があります)。
import gensim w2v_fpath = "all.norm-sz100-w10-cb0-it1-min100.w2v" w2v = gensim.models.KeyedVectors.load_word2vec_format(w2v_fpath, binary=True, unicode_errors='ignore') w2v.init_sims(replace=True) for word, score in w2v.most_similar(positive=[u"", u""], negative=[u""]): print(word, score)
ロシアの分布シソーラスプロジェクトによって既に構築されたword2vecモデルを使用します
取得するもの:
0.856020450592041 0.8100876212120056 0.8040660619735718 0.7984248995780945 0.7981560826301575 0.7949156165122986 0.7862951159477234 0.7808529138565063 0.7741949558258057 0.7644592523574829
「王」に最も近い言葉をより詳細に検討します。 意味的に関連する単語を検索するためのリソースがあり、結果はエゴネットワークとして表示されます。 以下は、「王」という言葉に最も近い20人の隣人です。

Mikolovによって提案されたモデルは非常に単純です-同様の文脈の単語は同じことを意味すると仮定されます。 ニューラルネットワークのアーキテクチャを検討してください。
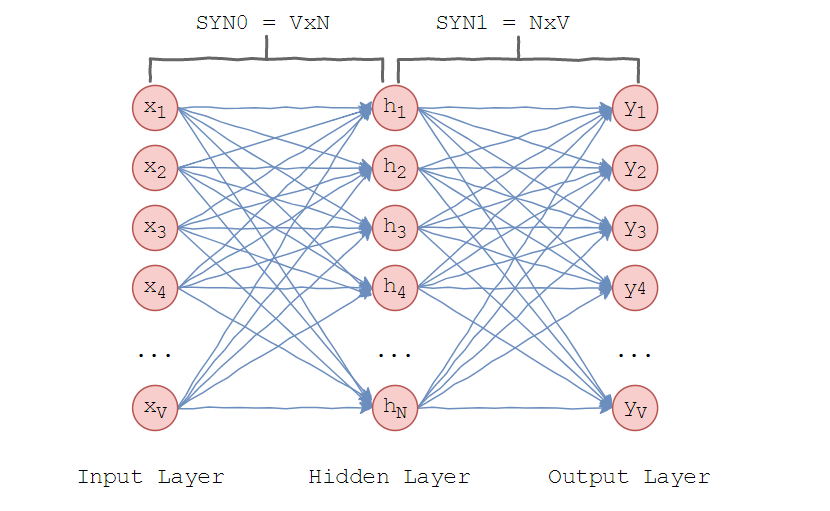
Word2vecは1つの隠しレイヤーを使用します。 入力層には、辞書の単語と同じ数のニューロンがあります。 非表示レイヤーのサイズは、スペースの次元です。 出力層のサイズは入力層と同じです。 したがって、学習用の語彙がV単語で構成され、Nが単語ベクトルの次元であると仮定すると、入力層と隠れ層の間の重みは、サイズV×NのSYN0行列を形成します。 以下を表します。

V行のそれぞれは、単語のベクトルN次元表現です。
同様に、非表示層と出力層の間の重みは、N×VマトリックスSYN1を形成します。 次に、出力レイヤーの入力で次のようになります。
どこで マトリックスSYN1のj番目の列です。
スカラー積は、n次元空間の2点間の角度の余弦です。 この式は、単語ベクトルがどれだけ近いかを示しています。 単語が反対の場合、この値は-1です。 次に、softmax-「ソフト最大関数」を使用して、単語の分布を取得します。
softmaxを使用すると、word2vecはその隣にある単語のベクトル間のコサイン測定値を最大化し、発生しない場合は最小化します。 これは、ニューラルネットワークの出力です。
アルゴリズムがどのように機能するかをよりよく理解するために、次の文で構成されるトレーニングのケースを検討してください。
「猫は犬を見た」
「猫は犬を追いかけていました」
「白猫は木に登った。」
コーパス辞書には8つの単語が含まれています:["white"、 "climbed up"、 "tree"、 "cat"、 "on"、 "stalked"、 "dog"、 "saw"]
アルファベット順にソートした後、各単語は辞書のインデックスによって参照できます。 この例では、ニューラルネットワークには8つの入力ニューロンと出力ニューロンがあります。 隠れ層に3つのニューロンがあるとします。 これは、SYN0およびSYN1がそれぞれ8×3および3×8行列になることを意味します。 トレーニングの前に、これらの行列は、通常のトレーニングの場合と同様に、小さなランダム値で初期化されます。 SYN0とSYN1を次のように初期化します。
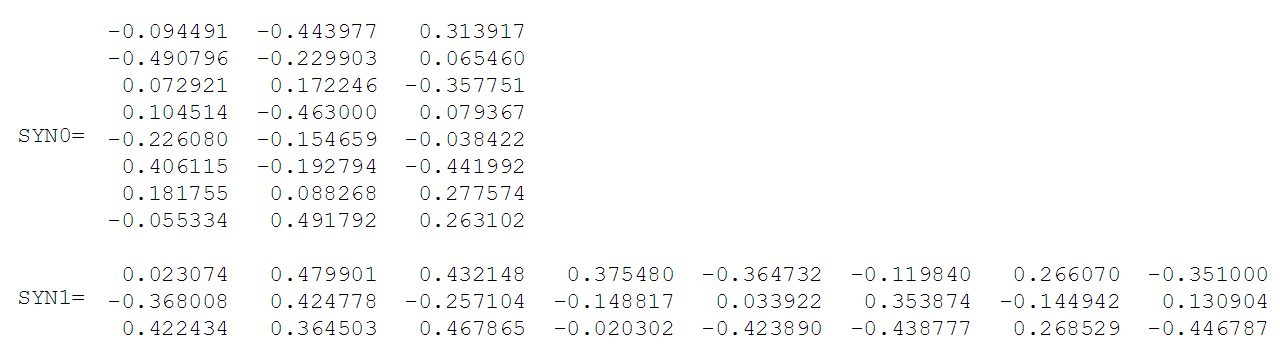
ニューラルネットワークが「登山」と「猫」という言葉の関係を見つけなければならないとします。 つまり、ネットワークの入力に「上昇」が入力された場合、ネットワークは「猫」という単語の高い確率を示す必要があります。 コンピュータ言語の用語では、「猫」という言葉は中枢と呼ばれ、「登る」という言葉は文脈的です。

この場合、入力ベクトルXは (「クライミング」は辞書の2番目であるため)。 ベクトル単語「猫」- 。
「上昇」を表すベクトルがネットワーク入力に供給されると、隠れ層のニューロンの出力は次のように計算できます。
隠れ層のベクトルHは、マトリックスSYN0の2行目に等しいことに注意してください。 したがって、非表示層のアクティブ化機能は、入力語のベクトルを非表示層にコピーすることです。
同様に、出力層の場合:
出力層で単語の確率を取得する必要があります。 のために 中心語と文脈入力との関係を反映しています。 ベクトルを確率で表示するには、softmaxを使用します。 j番目のニューロンの出力は、次の式で計算されます。
$$ display $$ y_j = P(word_ {context}│word_j)= \ frac {exp^ {val_j×val_ {context}}} {\ sum_ {k \ in V}exp^ {val_j×val_k}} = softmax $$表示$$
したがって、コーパス内の8つの単語の確率は次のとおりです。[0.143073 0.094925 0.114441 0.111166 0.14492 0.122874 0.119431 0.1448800]、「猫」の確率は0.111166です(辞書のインデックスによると) )
そこで、各単語をベクトルと一致させました。 しかし、言葉ではなくフレーズや文章全体で作業する必要があります。 人々はそのように伝えます。 このために、 Doc2vec (元々はParagraph Vector)があります-word2vecに基づいてテキストの一部の分散表現を取得するアルゴリズムです。 テキストは任意の長さにすることができます:コロケーションから段落まで。 そして、出力で固定長のベクトルを取得することが非常に重要です。
Boltoonはこの技術に基づいています。 まず、ロシア語版ウィキペディア( ダンプへのリンク)に基づいて、300次元のセマンティックスペースを構築します(前述のとおり、100から500の次元を選択します)。
もう少しPython。
model = Doc2Vec(min_count=1, window=10, size=100, sample=1e-4, workers=8)
パラメーターを使用してさらにトレーニングするために、クラスのインスタンスを作成します。
- min_count:頻度が指定された頻度より低い場合、単語の最小出現頻度-無視
- window:コンテキストが考慮される「ウィンドウ」
- サイズ:ベクトルの次元(スペース)
- サンプル:指定された頻度よりも高い場合、単語の最大出現頻度-無視
- ワーカー:スレッド数
model.build_vocab(documents)
辞書の表を作成します。 ドキュメント-ウィキペディアのダンプ。
model.train(documents, total_examples=model.corpus_count, epochs=20)
トレーニング。 total_examples-入力するドキュメントの数。 トレーニングは一度行われます。 これはリソースを大量に消費するプロセスであり、50 MBのウィキペディアダンプからモデルを構築しています(8 GBのRAMを搭載した私のラップトップはプルされません)。 次に、トレーニング済みモデルを保存して、これらのファイルを受け取ります。

前述のように、SYN0およびSYN1はトレーニング中に形成される重み行列です。 これらのオブジェクトは、pickleを使用して個別のファイルに保存されます。 サイズはN×V×Wに比例します。ここで、Nはベクトルの次元、Vは辞書内の単語の数、Wは1文字の重みです。 これにより、ファイルサイズが非常に大きくなりました。
質問と回答とともにデータベースに戻ります。 新しく構築された空間ですべてのフレーズの座標を見つけます。 データベースを拡張すると、システムを再トレーニングする必要がなくなり、追加されたフレーズを考慮して、同じスペースで座標を見つけるだけで十分であることがわかります。 これがBoltoon'aの主な利点です-データの更新への迅速な適応。
次に、ユーザーフィードバックについて説明します。 空間内の質問の座標とそれに最も近いフレーズを検索します。これはデータベースで利用できます。 しかし、ここでは、N次元空間で特定のポイントに最も近いポイントを見つけるという問題が発生します。 KD-Treeの使用をお勧めします(詳細については、 こちらをご覧ください )。
KDツリー(K次元ツリー)は、超平面でのクリッピングによってK次元空間を低次元の空間に分割できるデータ構造です。
from scipy.spatial import KDTree def build_tree(self, ethalon): return KDTree(list(ethalon.values()))
しかし、これには重大な欠点があります。要素が追加されると、ツリーは平均してO(NlogN)で再構築されるため、長時間かかります。 そのため、Boltoonは「遅延」更新を使用します-データベースに追加されたMフレーズごとにツリーを再構築します。 検索はO(logN)で行われます。
Boltoonのさらなるトレーニングのために、次の機能が導入されました。質問を受け取った後、品質を評価するために2つのボタンを持つ回答が送信されます。

否定的な回答の場合、ユーザーはそれを修正するように求められ、修正された結果がデータベースに入力されます。

データベースにないフレーズを使用したBoltoonとの対話の例。

もちろん、それを「心」と呼ぶことは困難です。ボルトンは知性を持っていません。 彼はSiriや最近のAliceのようなトップボットからはほど遠いですが、これは彼を役に立たず、面白くしません。結局のところ、これは1人によって作成された夏の練習の枠組みの学生プロジェクトです。 将来、応答処理モジュールを固定して(対話者のフロアと一致するなど)、会話のコンテキストを覚えて(以前のいくつかのメッセージのフレームワーク内で)タイプミスを処理する予定です。 より合理的なBoltoon 2.0が手に入ることを願っています。 しかし、これはすでに次の記事の会話です。
PS @boltoon_botリンクを使用して電報でBoltoonをテストできます。受信した各応答を評価することを忘れないでください。そうしないと、後続のメッセージが無視されます。 そして、誰が何を書いたかのすべてのログを見るので、良識の枠組みを維持しましょう。
PPSこの記事のアドバイスと建設的な批判について、先生のPavelMSTUとov7aに感謝します。