
これは、JSエンジンV8の公式ブログからの投稿の翻訳です。 記事は短く、テキストは小さく、V8コードの何も疑っていないGoogle社員を待っている問題についての魅力的な物語のようです。 Chrome 62およびNode v9.xで利用可能になるV8でのES6プロキシの処理の高速化について話しますが、プロキシを使用して最高速度を得るための最適な方法についてはほとんど説明しません。
はじめに
ES2015標準の採用により、JavaScriptにプロキシが登場しました。 オブジェクトの基本的な操作を傍受し、その動作を再定義できます。 プロキシは、 jsdomやComplink RPCライブラリなどのライブラリの基盤です。 最近、V8でプロキシのパフォーマンスを改善するために多くの努力をしました。 この記事では、V8、特にプロキシーのパフォーマンスを向上させる一般的なアプローチについて少し説明します。
プロキシは、「基本的な操作(プロパティへのアクセス、割り当て、列挙、関数呼び出しなど)をオーバーライドするために使用されるオブジェクト」(MDNから)です。 詳細については、 完全な仕様を参照してください 。 たとえば、次のコード例は、オブジェクトのプロパティに呼び出しログを追加します。
const target = {}; const callTracer = new Proxy(target, { get: (target, name, receiver) => { console.log(`get was called for: ${name}`); return target[name]; } }); callTracer.property = 'value'; console.log(callTracer.property); // get was called for: property // value
プロキシ作成
最初に注意することは、プロキシの作成です。 C ++での最初の実装では、EcmaScript仕様の手順を繰り返したため、下図に示すように、C ++ランタイムとJSランタイムの間で最低4回のジャンプが発生しました。 この実装を、JSランタイムで実行されるプラットフォームに依存しないCodeStubAssembler (CSA)に変換したいと考えました。 この移植により、言語ランタイム間のホップ数が最小化されます。 CEntryStub
とJSEntryStub
はJSEntryStub
です。 点線は、ランタイム環境間の境界を示しています。 幸いなことに、ほとんどのヘルパー述語はすでにCSAに含まれていたため、 初期バージョンが簡潔で読みやすくなりました。
次の図は、プロキシがインターセプター(この例では、プロキシが関数として使用されるときに呼び出されるapply
インターセプト)で動作しているときの制御フローを示し、次のコードを使用しています。
function foo(...) {...} g = new Proxy({...}, { apply: foo }); g(1, 2);
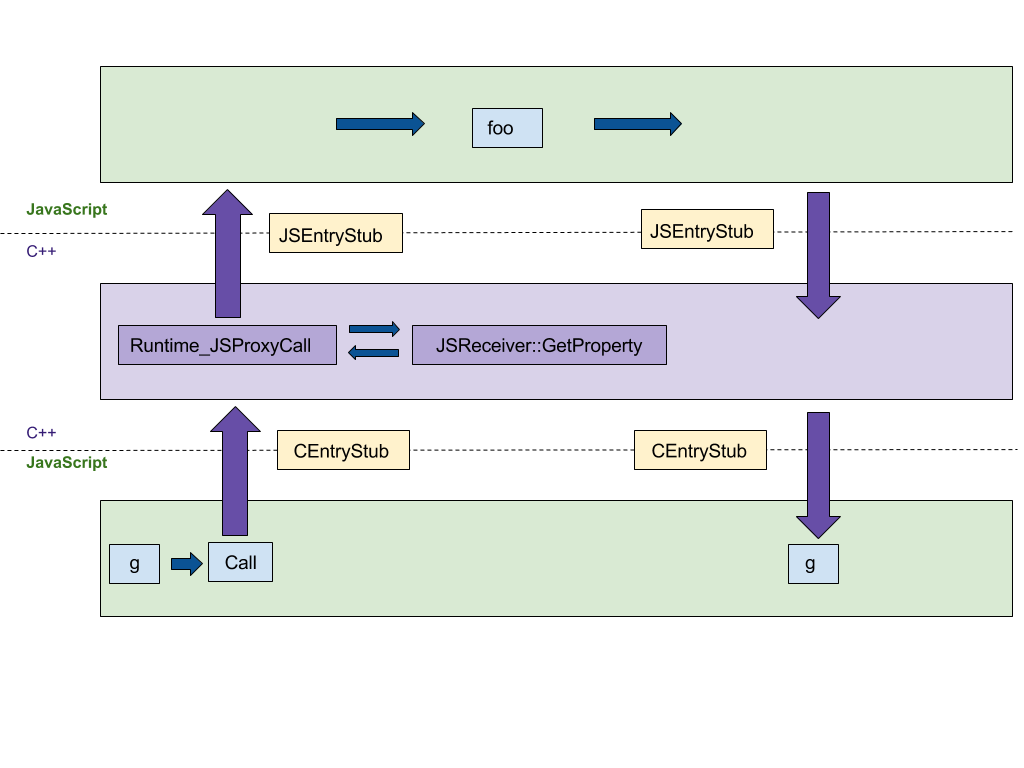
インターセプター呼び出しをCSAに移植した後、すべての呼び出しはJS環境で行われ、言語間の「ジャンプ」の数を4からゼロに減らします。
この変更により、以下のパフォーマンスが改善されました。
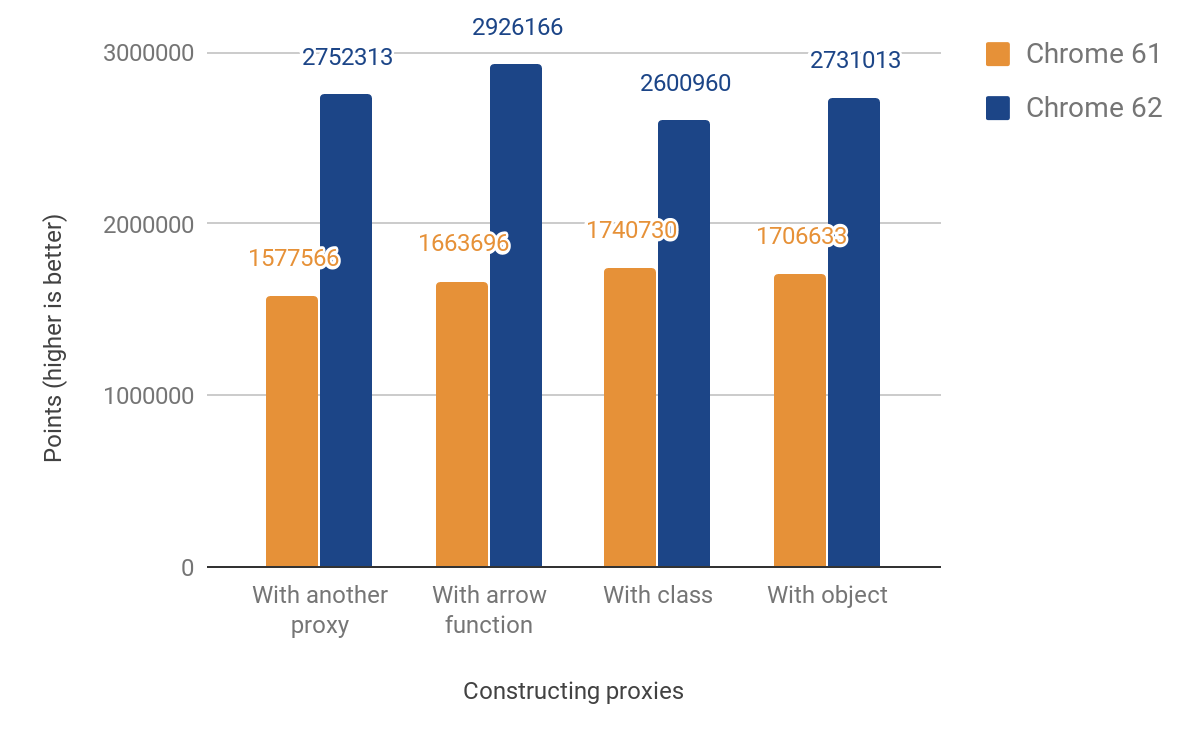
JSのパフォーマンス測定では、49%から74%の加速が示されています。 大まかに言えば、特定のマイクロベンチマークを1000ミリ秒で起動できる回数を測定しました。 一部のテストでは、コードを数回実行して結果を明確にします(タイマーの精度が制限されているため)。 以下のすべてのベンチマークのコードは、js-perf-testディレクトリにあります。
インターセプターをCall
てconstruct
する
次の部分は、コールインターセプターの最適化と作成の結果を示しています(これらは、 apply
とconstruct
も行いapply
)。
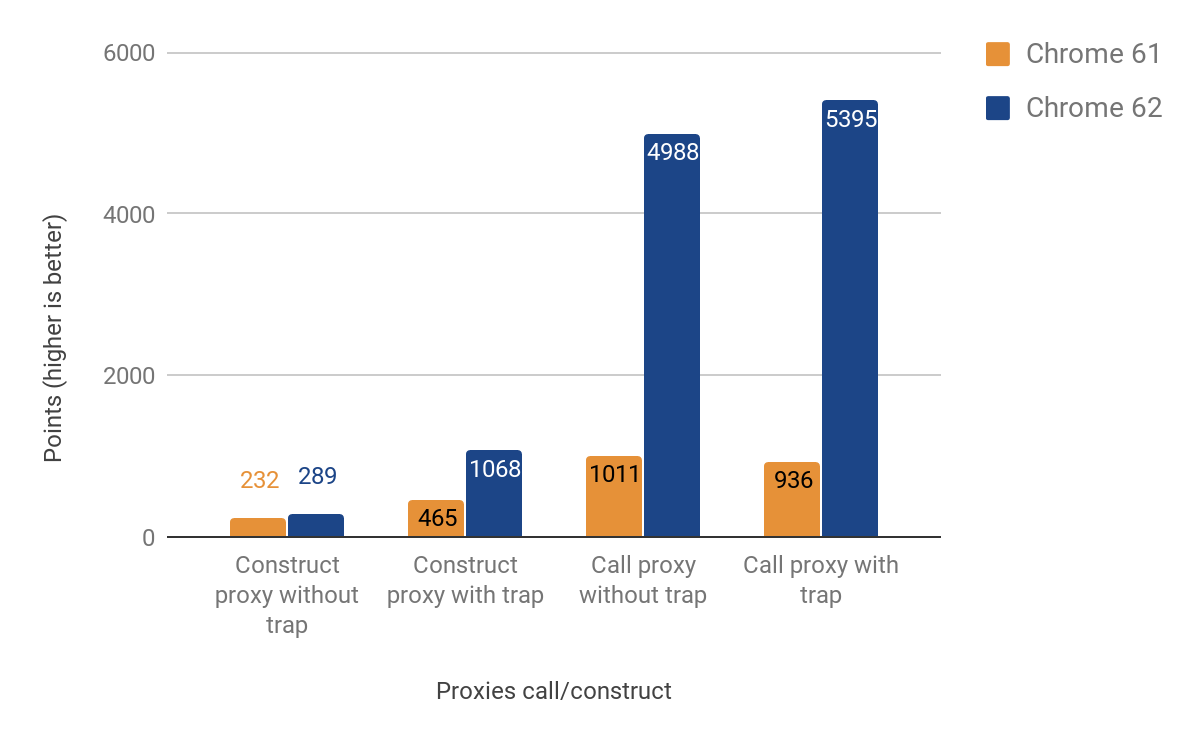
プロキシを呼び出すときのパフォーマンスの大幅な向上-最大500%高速! そして、特にインターセプターが定義されていない場合、プロキシ作成の加速はそれほど顕著ではありません-この場合、加速はわずか25%です。 d8 shell
で次のコマンドを実行すると、これらの結果が得られました。
test.js
は次の内容のファイルです。
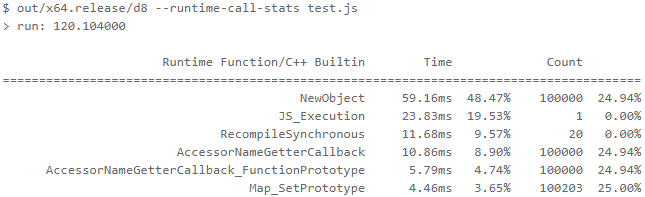
function MyClass() {} MyClass.prototype = {}; const P = new Proxy(MyClass, {}); function run() { return new P(); } const N = 1e5; console.time('run'); for (let i = 0; i < N; ++i) { run(); } console.timeEnd('run');
ほとんどの時間はNewObject
関数とそれがNewObject
関数に費やされていることNewObject
したため、今後のリリースでどのように高速化するかを考えています。
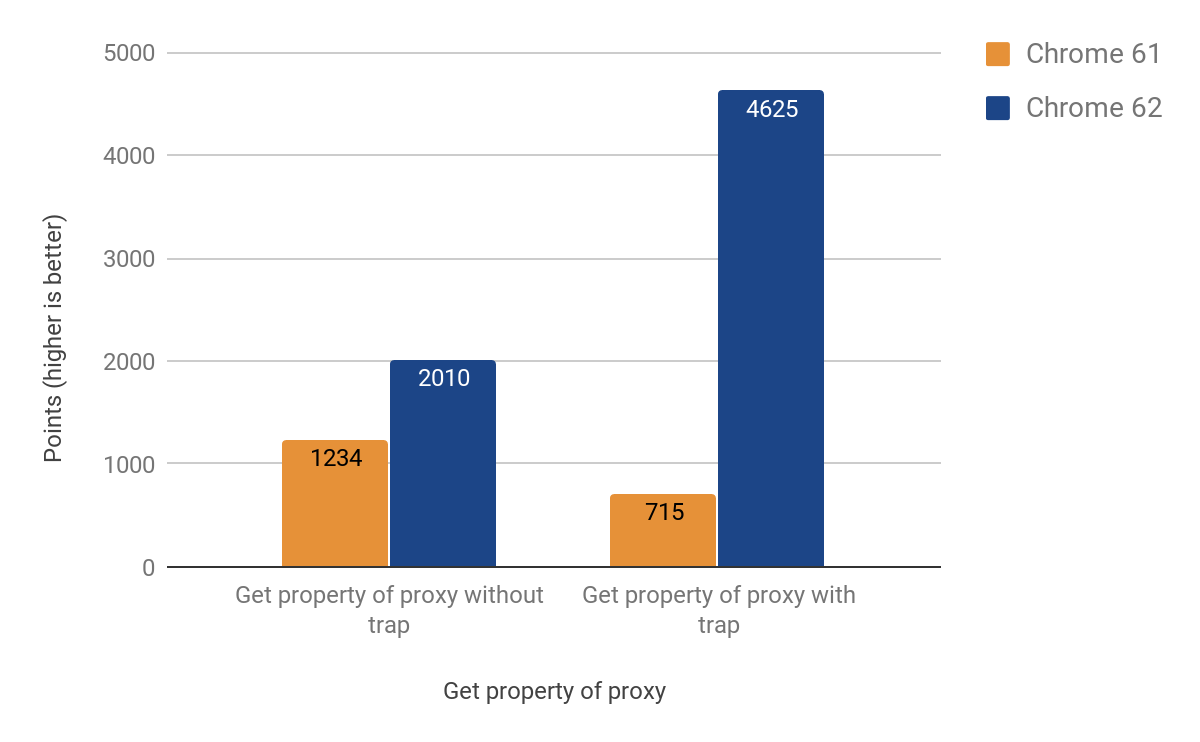
インターセプターを取得する
次のセクションでは、最もよく使用される操作(プロキシを介したプロパティの読み取りと書き込み)を最適化する方法について説明します。 インラインキャッシュの動作により、 get
インターセプターは前の例よりも混乱しやすいことがわかりました。 このビデオでインラインキャッシュの詳細を見ることができます。
最終的に、CSAで動作するポートを取得し、次の結果が得られました。
変更を適用した後、Android用のChrome apkファイルのサイズが約160Kb増加したことに気付きました。これは20行の小さな関数では予想以上ですが、幸いなことに、このような統計を保持しています。 この関数は別の関数から2回呼び出され、3回目は3回呼び出され、4回呼び出されることが判明しました。 問題の原因は、積極的なインライン関数でした。 最後に、関数を別のスタブ( ここでは明らかに、 上記の「述語」と呼ばれる 同じスタブ を意味する)に入れることで問題を解決し、貴重なキロバイトを節約しました 。
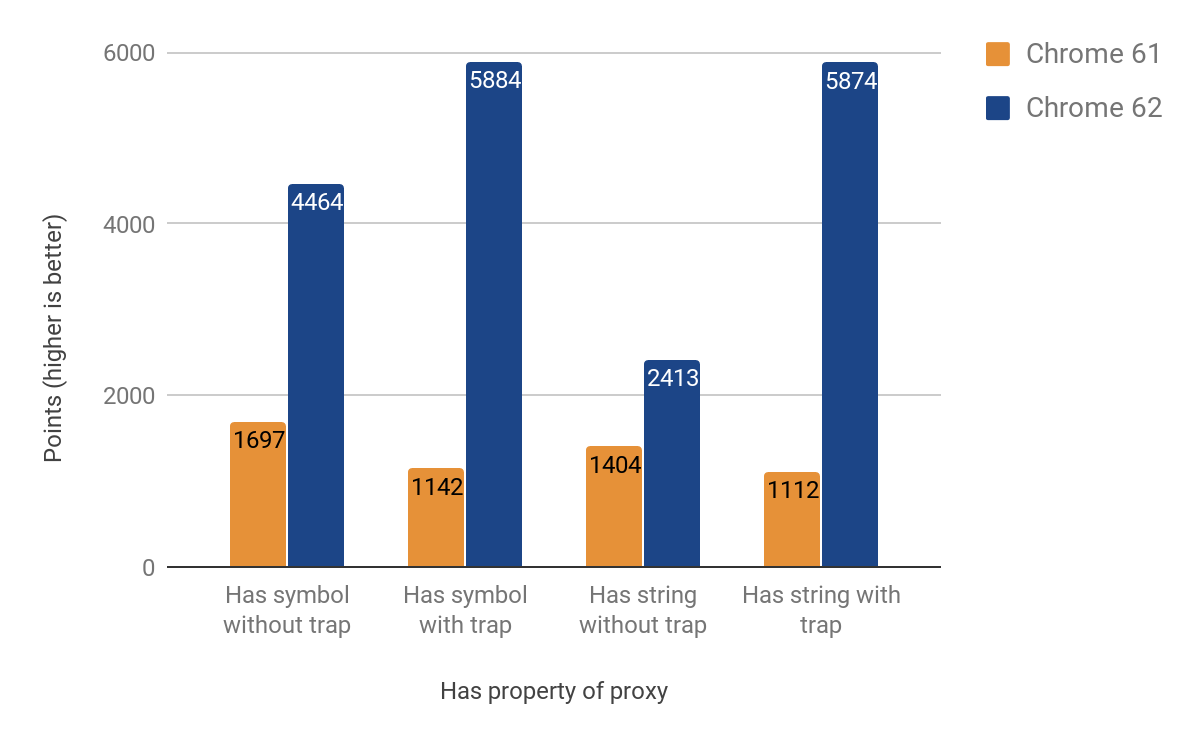
Has-interceptor
次の部分は、 インターセプターの最適化の結果を示しています。 これは簡単だと思っていましたが(get-interceptorからのコードのほとんどを再利用する予定です)、独自の雰囲気があります。 一部は、オペレータin
呼び出さin
ときにプロトタイプチェーンをバイパスするというデバッグが難しい問題のためです。 改善結果の範囲は71%〜428%です。 また、インターセプターが作成時に定義されている場合、ゲインはより顕著になります。
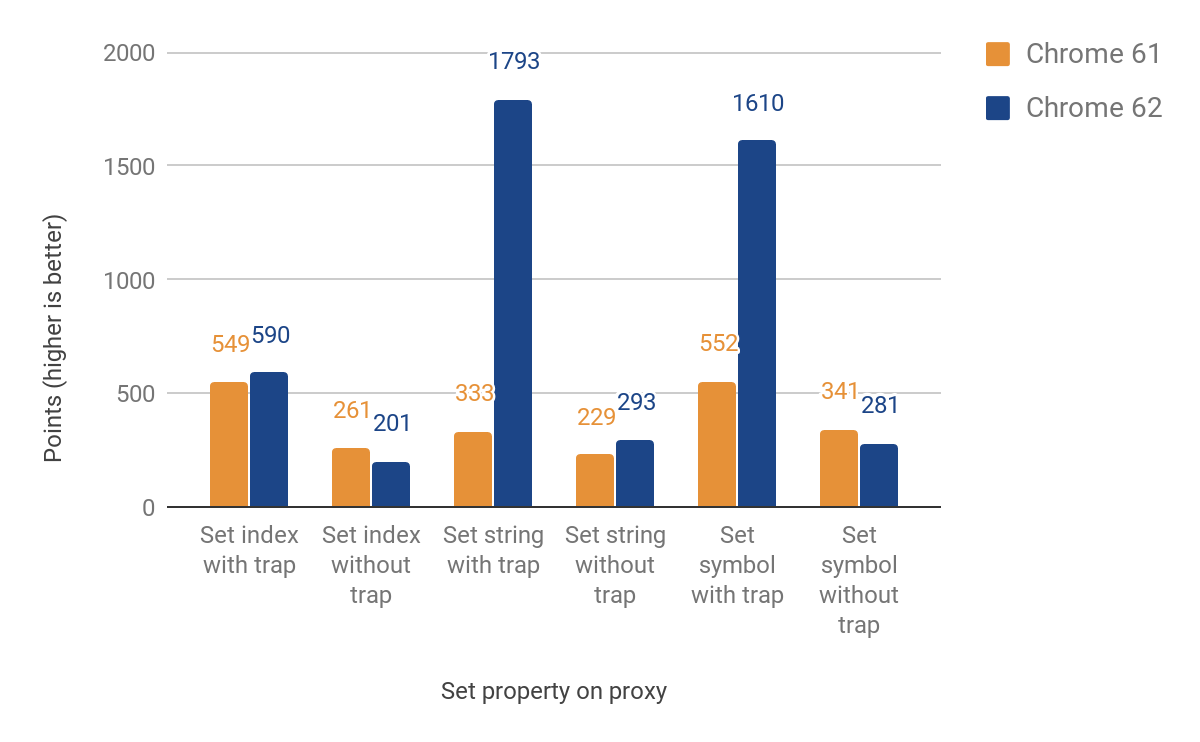
インターセプター
次に、 インターセプターのset
進みます。 そして今回は、 名前 付きプロパティとインデックス付きプロパティ(要素)を別々に操作する必要があります 。 これらの2つのタイプはJS言語の一部ではありませんが、オブジェクトプロパティを処理するための内部最適化の結果です。 最初のプロキシ実装は、ランタイム(要素の場合)をそのまま残します。これにより、ランタイム環境が交差します。 それでも、インターセプターが定義されている場合は27%から438%に改善されていますが、23%のスローダウンが犠牲になっています(決定されていない場合)。 ここでのパフォーマンスの低下は、オブジェクトのインデックス付きプロパティと名前付きプロパティを区別するための追加チェックによるものです。 インデックス付きプロパティの改善はまだありません。 完全な結果のグラフを次に示します。
実際の使用結果
jsdom-proxy-benchmark で受信 :
jsdom-proxy-benchmarkプロジェクトは、 Ecmarkupツールを使用してECMAScript仕様をコンパイルします(単語の意味で:1つのhtmlファイルにコンパイルします)。 jsdom@11.2.0 ( Ecmarkupの基礎)では、プロキシを使用してNodeList
やHTMLCollection
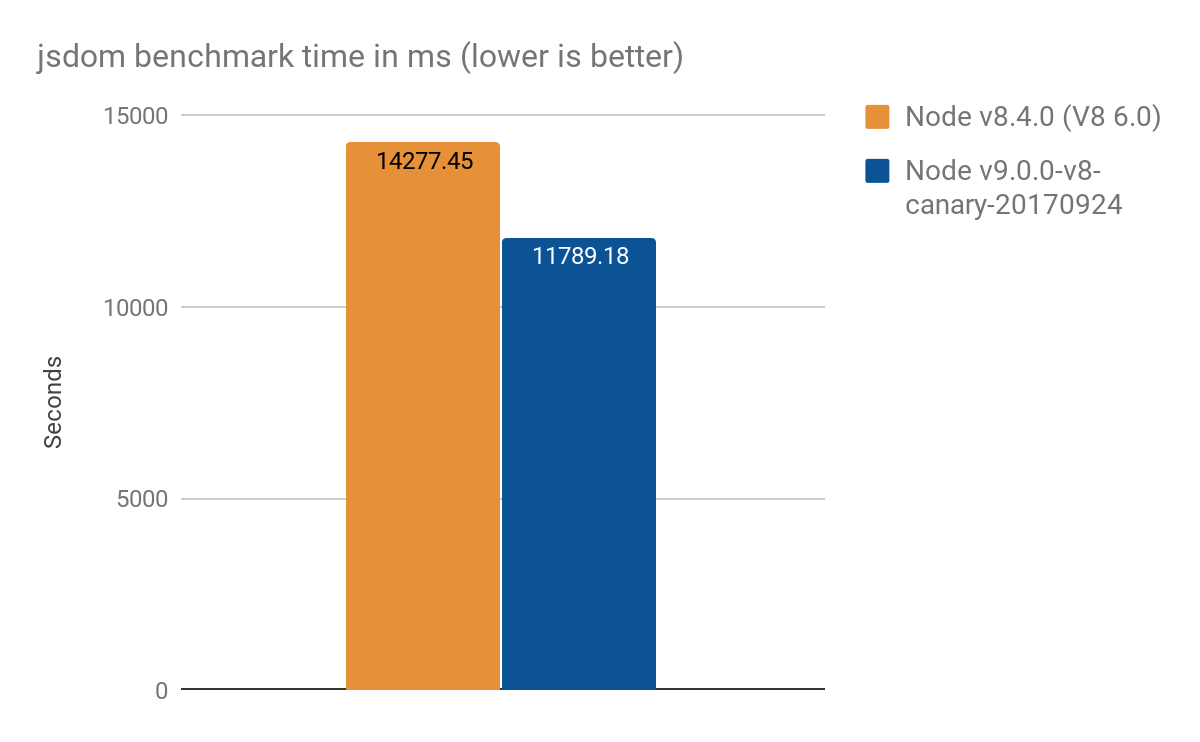
などの構造を実装します。 これをベンチマークとして使用して、合成マイクロベンチマークより現実の世界に近いシナリオで生産性を測定しました。 100パスの場合、平均結果は次のとおりです。
- Node v8.4.0(プロキシ最適化なし): 14277±159 ms
- Node v9.0.0-v8-canary-20170924 (ハーフ最適化インターセプターのみ): 11789±308 ms
- 結果の差は約2.4秒で、これは〜17%の改善を意味します
- NamedNodeMapをプロキシに変換すると、処理時間が改善されました。
- V8 6.0(ノードv8.4.0)で1.9秒
- V8 6.3で0.5秒(ノードv9.0.0-v8-canary-20170910)
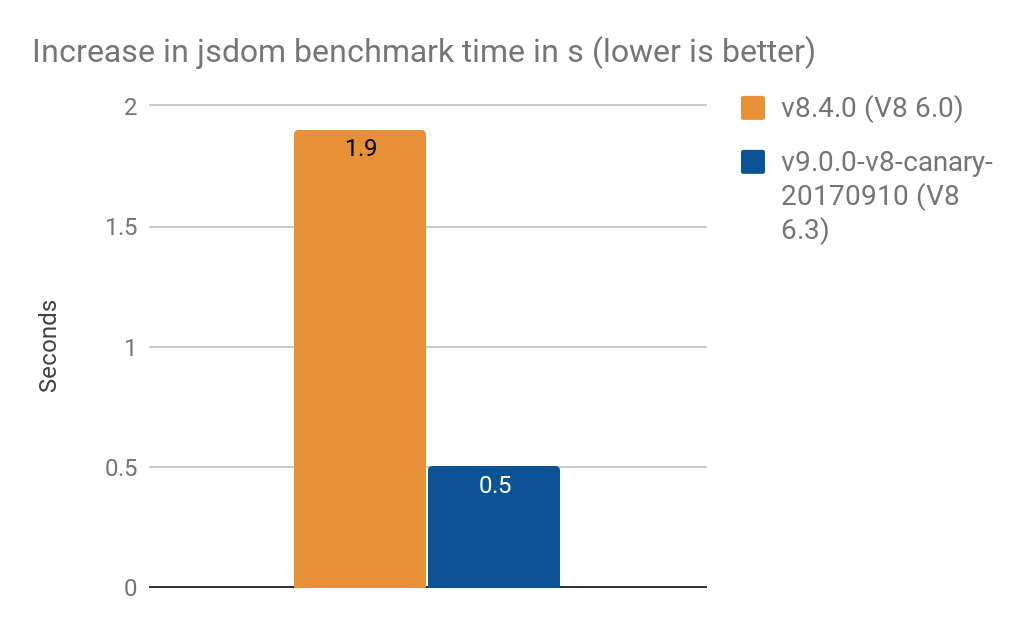
TimothyGuから提供された結果をありがとう。
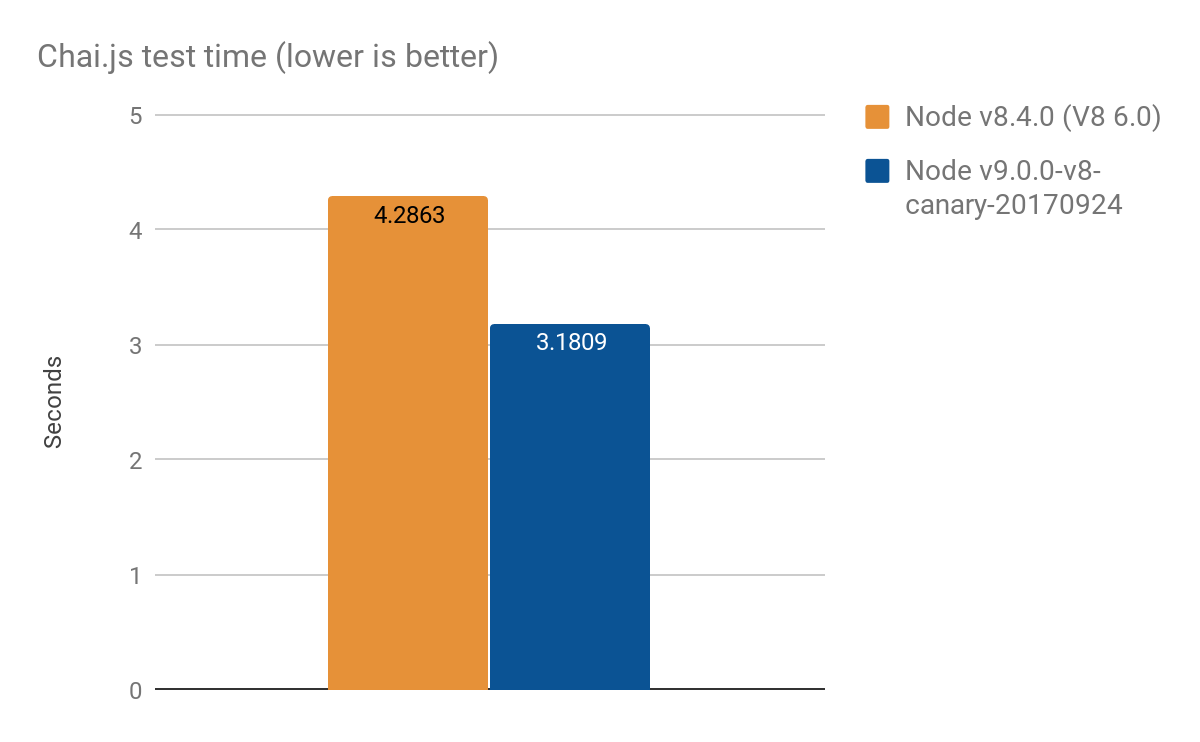
Chai.jsは、プロキシをかなり厳密に使用する一般的なアサートライブラリです。 実際のスクリプトを使用してベンチマークのようなことをしました。 V8のさまざまなバージョンのテストを実行した結果、4つのうち1秒以上の勝利を収めました。 平均して、100を超える起動:
- ノードv8.4.0(プロキシ最適化なし): 4.2863±0.14秒
- Node v9.0.0-v8-canary-20170924(ハーフ最適化インターセプターのみ): 3.1809±0.17 s
最適化に使用されるアプローチ:
パフォーマンスのボトルネックを解消するための標準的なアプローチを採用しましたが、次のいくつかのステップが基礎となります(この記事で開示されている作業でこれに従いました)。
- 個々の小さな機能のパフォーマンステストを行う
- テストを追加して、仕様への準拠を確認します(または、ゼロから作成します)
- C ++での元の実装を学ぶ
- プラットフォームに依存しないCodeStubAssemblerへの機能の転送
- TurboFan実装の作成によりコードをさらに最適化する
- ベンチマークでパフォーマンスの変化を確認する
これらの手順は、必要な最適化に適しています。