
Javaでは、シリアルコード、パラレルコード、および非同期コードを記述できます。 非同期-これは、イベント(たとえば、ファイルの読み取り)の後に開始するコールバックが登録されるときです。 これにより、スレッドのブロックは回避されますが、実行シーケンスは中断されるため、他のオプションがない場合、そのようなコードはより早くjavaで記述されます。 Kotlinはソリューションを提供します- コルーチン 、非同期コードはシリアルとほとんど同じに見えます。
コルーチンに関する記事はほとんどありません。 それらの利点を示す具体例はさらに少ない。
私が見つけたもの:
- コールバック地獄を取り除く 。 UIの実際
- チャンネルと俳優のコンセプトが好きでした。 それらは新しいものではなく、それらなしでも可能ですが、イベントシステムでは非常にうまく機能するはずです
- ローマンエリザロフからのアドバイス :「ほとんどの場合、何かを期待する非同期タスクにはコルーチンが必要です」
後者は興味深いです-ほとんどのエンタープライズアプリケーションは常に何かを待っています:データベース、他のアプリケーション、時にはファイルを読む必要があります。 そして、これはすべて完全に非同期にすることができます。つまり、アプリケーション全体を非同期要求処理に転送できます。
それでは、負荷がかかった場合のコルーチンの動作を見てみましょう。
IO対NIO
NIOの下には、 コルーチン用の既製のハーネスがあります。 コードを書きます:
suspend fun readFileAsync(): String { val channel = AsynchronousFileChannel.open(filePath) val bytes = ByteArray(size) val byteBuffer = ByteBuffer.wrap(bytes) channel.aRead(byteBuffer, 0L) /*(1)*/ /*(2)*/ channel.close() return bytes.toString(Charset.forName("UTF-8")) } fun readFileSync() = file.inputStream().use { it.readBytes(size).toString(Charset.forName("UTF-8")) }
仕組み
私は構文に焦点を合わせません。これには短いガイドがあります。 一番下の行では、行(1)でNIOからメソッドが呼び出され、コールバックが登録され、ポイント(2)で実行が継続されます。 優れたコンパイラーは、メソッドのローカル変数を保存し、それらを復元してプログラムを続行します。 (1)と(2)の間では、ファイルがディスクから読み取られている間、ストリームは無料で、たとえば、2番目のファイルの読み取りを開始できます。 ファイルの2回目の読み取りのロックの場合、最初の読み取りが終了するまで、別のスレッドを作成する必要があり、それもブロックされます。
パフォーマンスを測定する
JMHを使用して、単一の呼び出しを測定します。 結論:HDDの場合、差は誤差の範囲内であり、コルチン中のSSD NIOの場合は7.5%±0.01%高速です。 違いは小さいですが、これは驚くことではありません-すべてがディスクの速度に依存します。 しかし、コルチンの場合、スレッドは読み取り中にブロックされず、他の作業を実行できます。
ディスクから一定量のデータを読み取っている間に、さらに多くの作業を行えることを見てみましょう。 これを行うには、ForkJoinPoolで特定の比率でIOおよびCPUタスクをスローします。 400個のIOタスクを完了したら、純粋にCPUタスクがいくつ実行されたかを計算します。 ベンチマーク
| 経過時間(ミリ秒) | 完了したCPUタスクの数 | |||
|---|---|---|---|---|
| IOタスクを共有する | 同期する | 非同期 | 同期する | 非同期 |
| 3/4 | 117 | 116 | 497 | 584(+ 17%) |
| 1/2 | 128 | 127 | 1522 | 1652(+ 8%) |
| 1/4 | 163 | 164 | 4958 | 4960 |
| 1/8 | 230 | 238(+ 3%) | 11381 | 11495(+ 1%) |
違いがあります。 HDDで測定しましたが、単一の読み取り値はほぼ同じでした。 それとは別に、最後の行に注意してください。awaitは比較的多数のオブジェクトを生成し、GCを追加でロードします。これは、50個のオブジェクトを作成するCPUタスクの背景に対して顕著です。 個別に測定:タスクがオブジェクトを作成するほど、Futureとawaitの差は小さくなり、同等になります。
SQL
ロックなしでデータベースを操作できるライブラリが1つありました。 これはscalaで書かれており、MySqlとPostgresでのみ機能します。 誰か他のライブラリを知っているなら-コメントを書いてください。
Scalaから未来を待つ:
suspend fun <T> Future<T>.await(): T = suspendCancellableCoroutine { cont: CancellableContinuation<T> -> onComplete({ if (it.isSuccess) { cont.resume(it.get()) } else { cont.resumeWithException(it.failed().get()) } }, ExecutionContext.fromExecutor(ForkJoinPool.commonPool())) }
特にインデックスを使用せずにPostgresでタブレットをいくつか作成しました。その結果、タイミングが顕著になり、データベースがdockerで起動され、4つの論理プロセッサが提供されました。 ConnectionPoolは4に制限されています。各アプリケーションリクエストは、データベースに対して3回連続して呼び出しを行いました。
Springでは非同期httpサーバーを簡単に作成できます。このため、コントローラーメソッドからMyClasssの代わりにDeferredResultを返し、DeferredResultを(別のスレッドで)入力するだけで十分です。 便宜上、小さなラッパーを作成しました(数字は実際の実行順序を示しています)。
@GetMapping("/async") fun async(): DeferredResult<Response> = asyncResponse { (4) //code that produce Response } fun <R> asyncResponse(body: suspend CoroutineScope.() -> R): DeferredResult<R> { (1) val result = DeferredResult<R>() // (2) launch(CommonPool) { // try { (5) result.setResult(body.invoke(this)) } catch (e: Exception) { (5') result.setErrorResult(e) } } (3) return result // DeferredResult, }
別の問題は、プールからの接続が同期および非同期オプションを設定するのを待つことを決定することでした。 同期の場合はmsで、非同期の場合は断片で設定されます。 データベースへの平均クエリは約30ミリ秒であると判断したので、時間を30で割った-断片を取得しました(約3分の1に間違えたことが判明しました)。
1つの論理プロセッサを発行することにより起動されるアプリケーション。 別のマシンで、彼はYandexタンクを設置し、アプリケーションを撮影しました。 驚いたことに、違いはありませんでした...最大50 rps(左側の非同期 、右側の同期 )。
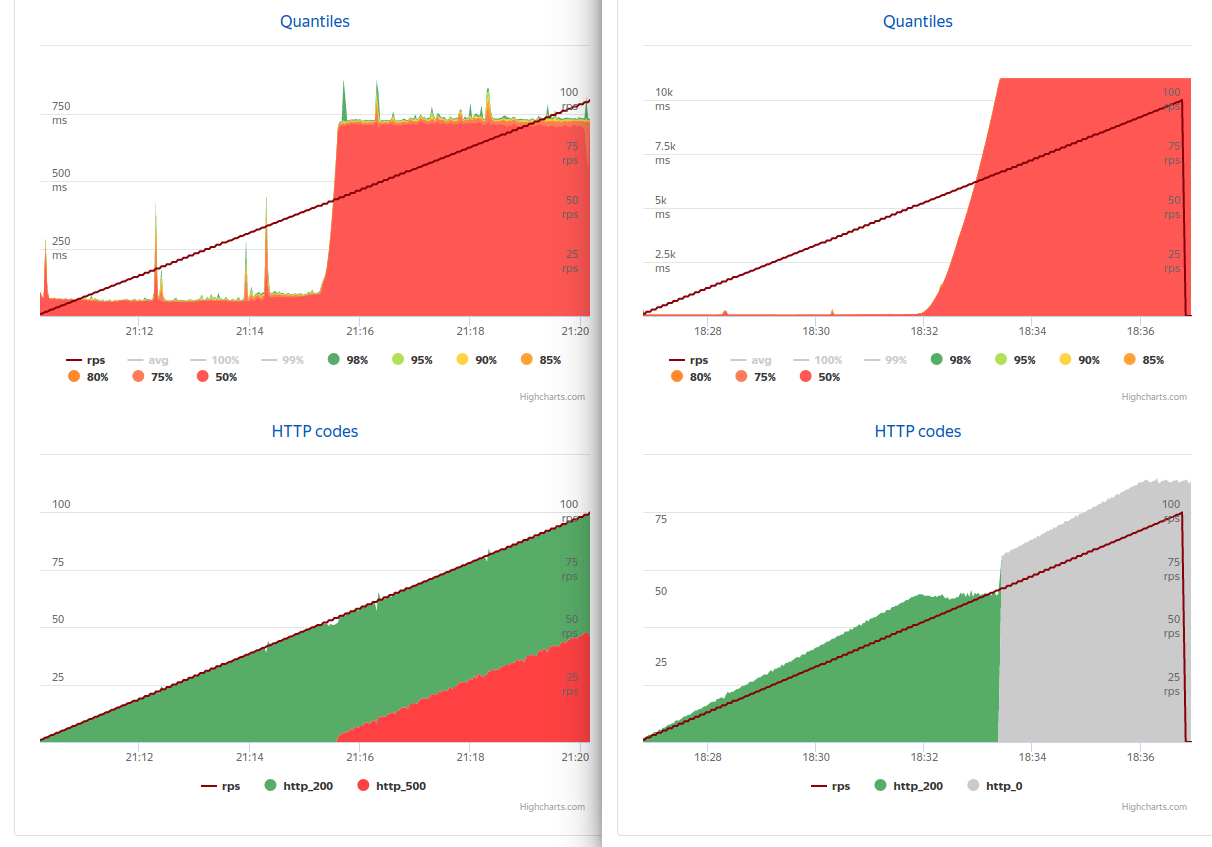
50 rps後、4つの接続が十分ではなくなり(この時点での平均タイミングは80 rps)、同期バージョンは66秒から11秒に到達して停止しました-タイムアウトのみが要求に応答し(負荷がまったく削除された場合でも)、非同期バージョンは54 rpsになりました730ミリ秒で、残りのすべてである500のデータベースで許可されている数の要求を正確に処理し始めましたが、エラーはほとんど常に即座に破棄されました。
8つの論理プロセッサでアプリケーションを起動すると、画像が少し変更されました(左非同期 、右同期 )
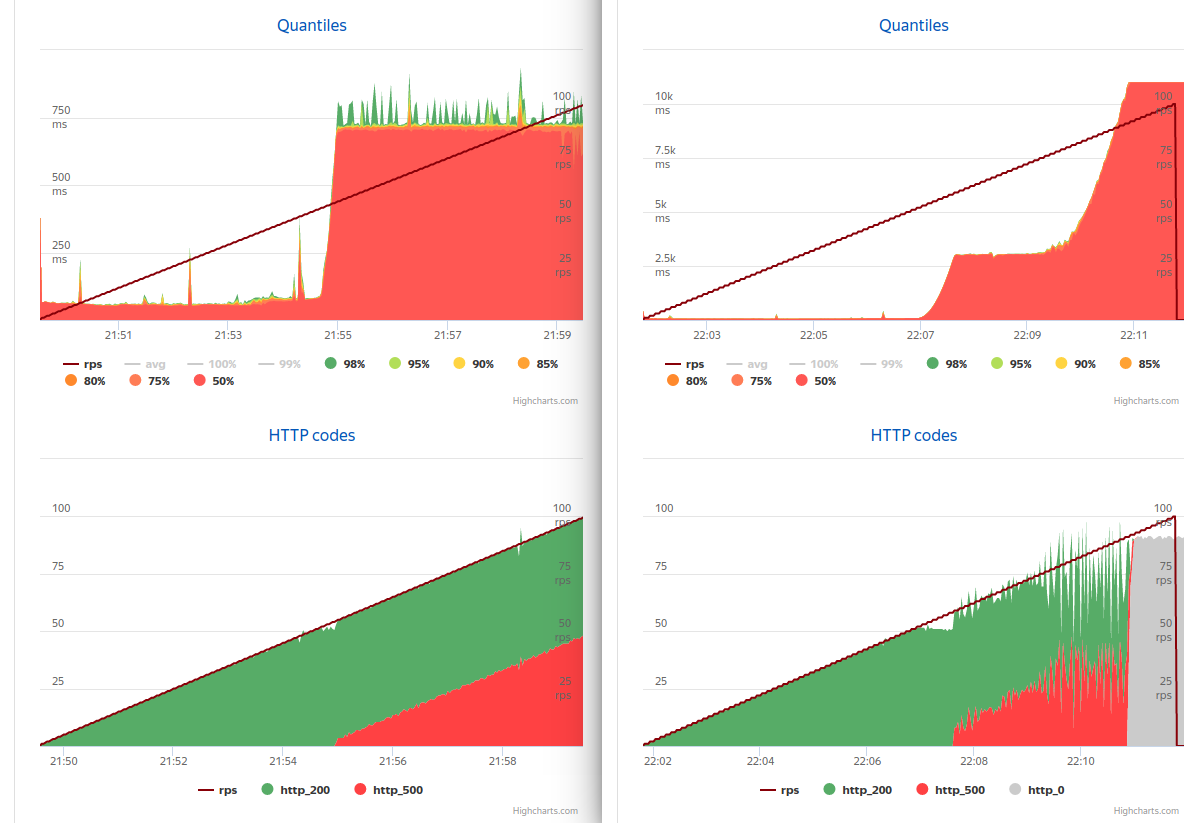
60〜80rpsの同期バージョンは3秒で応答し、不要な要求を破棄し、91rpsのみに応答しなくなりました。
なぜそれが起こったのですか? Tomcatは、着信リクエストを処理するために最大200(デフォルト)のスレッドを作成します。 処理できるよりも多くの要求がある場合、それらはすべて作成され、しばらくするとすべてがブロックされます。 さらに、各要求は3回接続を受信し、毎秒1回待機する必要があります。 非同期オプションの場合、リクエストはいつでも待機しませんが、このリソースを必要とする人が何人いるかを調べ、必要な人が多すぎる場合はエラーを送信します。 私の場合、制限は4接続で33でしたが、これはおそらく少し大きいでしょう。 この数が減少すると、サーバーの過負荷時に許容可能な応答速度が得られます。
HTTP
スムーズに拒否することは良いことですが、通常の状況でパフォーマンスを向上させることができるかどうかは疑問です。
今回、アプリケーションはhttp経由でスタブに移動し、スタブは遅延(1.5ミリ秒から)で応答しました。 2つのオプションを実行しました。スタブに対する100の連続した要求と100の並列(バッチ)要求です。 1および6スレッドでJMHを使用して測定(異なる負荷をシミュレート)。
| 順次(平均ms) | 並列(平均) | |||||
|---|---|---|---|---|---|---|
| 同期する | 非同期 | △ | 同期する | 非同期 | △ | |
| 1コア/ 1 jmhスレッド | 160.3±1.8 | 154.1±1.0 | 4.0%±1.7% | 163.9±2.4 | 10.7±0.3 | 1438.3%±4.6% |
| 2コア/ 1 jmhスレッド | 159.3±1.0 | 156.3±0.7 | 1.9%±1.1% | 57.6±0.5 | 15.4±0.2 | 274.0%±1.9% |
| 4コア/ 1 jmhスレッド | 159.0±1.1 | 157.4±1.3 | 1.0%±1.5% | 25.7±0.2 | 14.8±0.3 | 74.3%±2.8% |
| 1コア/ 6 jmhスレッド | 146.8±2.5 | 146.3±2.5 | 0.4%±3.4% | 984.8±34.2 | 79.3±3.7 | 1141.6%±5.1% |
| 2コア/ 6 jmhスレッド | 151.3±1.6 | 143.8±1.9 | 5.2%±2.3% | 343.9±17.2 | 86.7±3.7 | 296.5%±6.3% |
| 4コア/ 6 jmhスレッド | 152.3±1.5 | 144.7±1.2 | 5.2%±1.8% | 135.0±3.0 | 81.7±4.8 | 65.2%±8.1% |
リクエストが連続しても増加しますが、バッチでは増加します...もちろん、プロセッサを追加すると、同期バージョンの状況はずっと良くなります。 したがって、リソースを4倍に増やすと、同期バージョンが6.5倍になりますが、非同期速度には達しません。 同時に、非同期の速度はプロセッサの数に依存しません。
やばい
- すでに述べたように、非常に小さなタスクで非同期を実行することは有益ではありません。 しかし、私はこれが必要だとは思わない。
- ブロッキングコードを監視する必要があります。 おそらく、この場合、それらを実行するには別個のthreadPoolが必要です。
- ThreadLocalは忘れることができます。 Corutinは、提供されたプールからランダムストリームで復元されます(NIOの場合、指定することさえできません...)。 RequestScopeも動作を停止します(試行しませんでした)。 それにもかかわらず、何かをバインドできるCoroutineContextがありますが、とにかく明示的に渡す必要があります。
- Javaの世界はロックに使用されるため、非ブロッキングライブラリはわずかです。
後味
コルーチンを適用できますし、適用する必要があります。 それらに、同じ速度で動作するために必要なプロセッサーが少ないアプリケーションを作成できます。 私の印象では、ほとんどの場合、1〜2コアで十分です。
はい、フォールトトレランスという形の贈り物です。
Goのチャネル、C#のasync / await、C#のyieldおよびpythonでの作業のパターンを探す方が良いので、ベストプラクティスが徐々に現れることを願っています。
PS:
ソースコード
Kotlinからの後味、パート1
Kotlinの後味、パート2