
この資料は、6月2〜3日にサンクトペテルブルクで開催されたHolyJS 2017会議での著者の報告に基づいて作成されました。 PDFでのプレゼンテーションは、 このリンクで見つけることができます。
映画「The Last Dragon Slayer」は数ヶ月前に公開されました。 そこで、主人公がドラゴンを殺すと、世界の魔法が消えます。 JavaScriptの世界には魔法の場所がないので、今日は敵になりたい、ドラゴンを殺したい。 動作するすべてが明示的に機能します。 どのように機能するかを理解するために、どのように機能するかを理解する必要があります。
私はあなたと私の情熱を共有したいと思います。 ある時点で、V8の内部でどのように機能するのかわからないことに気付きました。 私は文学を読み始め、主に英語のレポートを見て、蓄積された知識を体系化し、それをあなたに届けたいと思います。
私たちの言語は解釈またはコンパイルされていますか?
誰もが違いを知っていることを願っていますが、繰り返します。 コンパイルされた言語:それらのソースコードは、コンパイラによってマシンコードに変換され、ファイルに書き込まれます。 実行前にコンパイルを使用します。 利点は何ですか? 再コンパイルする必要はありません。コンパイル対象のシステムで可能な限り自動化されています。 欠点は何ですか? オペレーティングシステムが変更されており、ソースがない場合は、プログラムが失われます。
解釈された言語-インタープリタープログラムによってソースコードが実行されたとき。 利点は、クロスプラットフォームを簡単に実現できることです。 ソースコードをそのまま提供します。このシステムにインタープリターがあれば、コードは機能します。 もちろん、JavaScriptは解釈されます。
歴史に浸ってください。 Chromeは2008年に発売されます。 Googleはその年に新しいV8エンジンを導入しました。 2009年に、Node.jsはV8とioを提供するlibUVライブラリで構成される同じエンジンで導入されました。 ファイルへのアクセス、いくつかのネットワークなど。 一般に、私たちにとって非常に重要な2つのことはV8エンジンに基づいています。 それが何で構成されるかを見てみましょう。
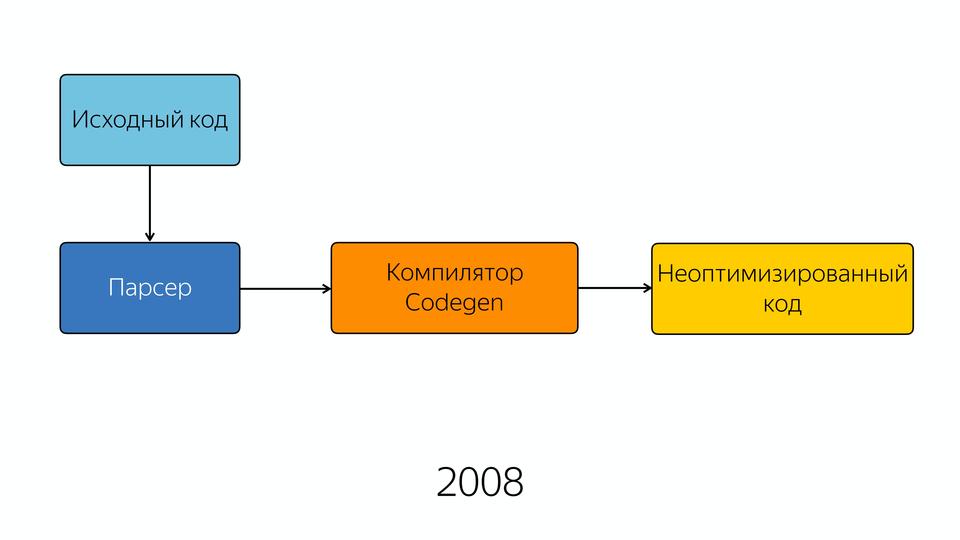
2008年、エンジンは内部が非常にシンプルになりました。 まあ、比較的単純です-そのレイアウトは単純でした。 ソースコードはパーサーからパーサーからコンパイラーに送られ、出力では半最適化されたコードが得られました。 最適化が適切ではなかったため、半最適化されました。 おそらくそれらの年には、オプティマイザが内部で最適化することを期待できなかったため、より良いJavaScriptを記述する必要がありました。
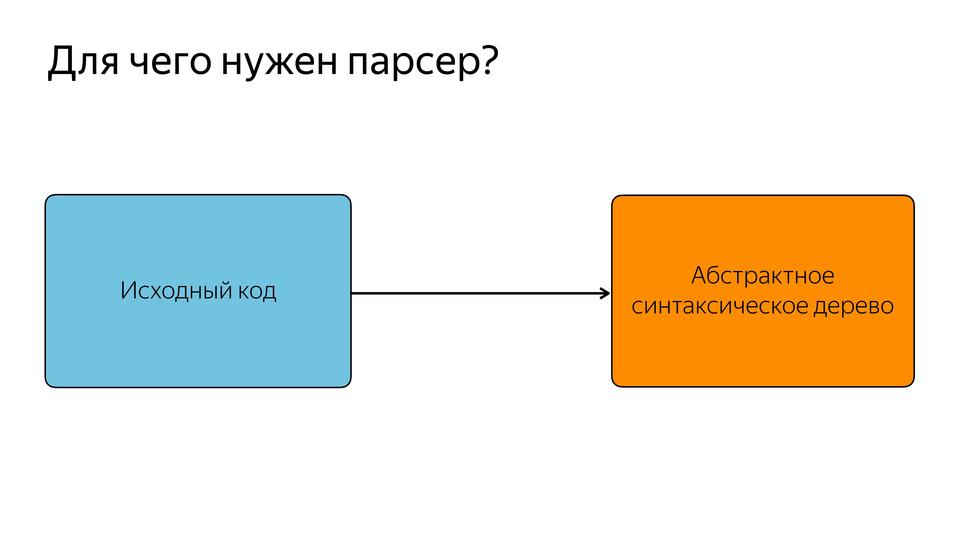
このスキームのパーサーは何ですか?
ソースコードを抽象構文ツリーまたはASTに変換するには、パーサーが必要です。 ASTは、すべての頂点が演算子であり、すべての葉がオペランドであるツリーです。
数式の例を見てみましょう。 このようなツリーがあり、すべての頂点は演算子であり、分岐はオペランドです。 それについて良いことは、後でそれからマシンコードを生成することが非常に簡単であることです。 アセンブラーで働いた人は、ほとんどの場合、命令は何をするか、何をするかで構成されていることを知っています。
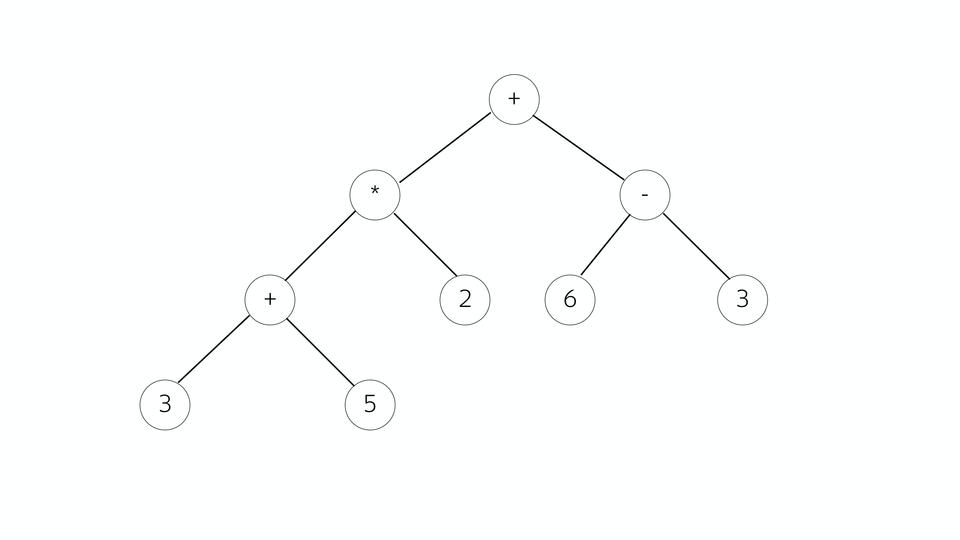
そして、ここで、現在のポイントに演算子かオペランドかを確認できます。 演算子の場合、そのオペランドを調べてコマンドを組み立てます。
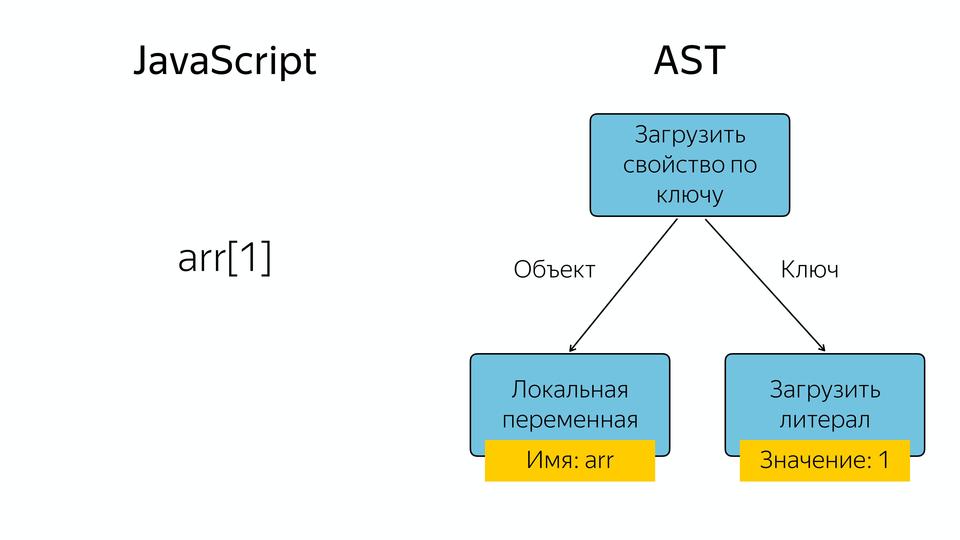
たとえば、配列があり、インデックス1で配列から要素を要求すると、JavaScriptで何が起こりますか? 演算子が「キーでプロパティをロードする」抽象構文ツリーが表示されます。オペランドは、このプロパティをロードするオブジェクトとキーです。
なぜjavascriptコンパイラで?
私が言ったように、私たちの言語は解釈されますが、そのスキームにはコンパイラがあります。 なんで? 実際には、2種類のコンパイラがあります。 実行前にコンパイルする事前処理コンパイラと、実行時にコンパイルするJITコンパイラがあります。 また、JITコンパイルにより、優れた加速が得られます。 これは何のためですか? 比較してみましょう。

同じコードがあります。 1つはPascal、もう1つはJavaScriptです。 パスカルは素晴らしい言語です。 JavaScriptを使用せずにプログラミングを学習する必要があると思います。 プログラミングの方法を学びたい人がいる場合は、PascalまたはCを見せてください。
違いは何ですか? Pascalはコンパイルと解釈の両方が可能で、JavaScriptには解釈が必要です。 最も重要な違いは静的型付けです。

Pascalで書くとき、必要な変数を指定してから、その型を書くからです。 コンパイラーは、最適化された適切なコードを簡単に構築できます。 メモリ内の変数にどのようにアクセスしますか? 住所があり、シフトがあります。 たとえば、整数32の場合、このアドレスで32をメモリにシフトし、データを取得します。
JavaScriptでは、いいえ、型は常に実行時に変更されます。コンパイラーは、このコードが最初に実行されるときに、このコードが最初に実行されたときに、型に関する情報を収集します。 そして、同じ機能を2回目に実行するとき、どのタイプがあったかを想定して、前回受け取ったデータに基づいて最適化をすでに行うことができます。 変数がすべて明確な場合、変数は値によって決定されますが、オブジェクトについてはどうでしょうか?
結局のところ、JavaScriptがあり、プロトタイプモデルがあり、オブジェクトのクラスはありません。 実際にはありますが、それらは見えません。 これらは、いわゆる隠しクラスです。 それらはコンパイラーにのみ表示されます。
隠しクラスはどのように作成されますか?
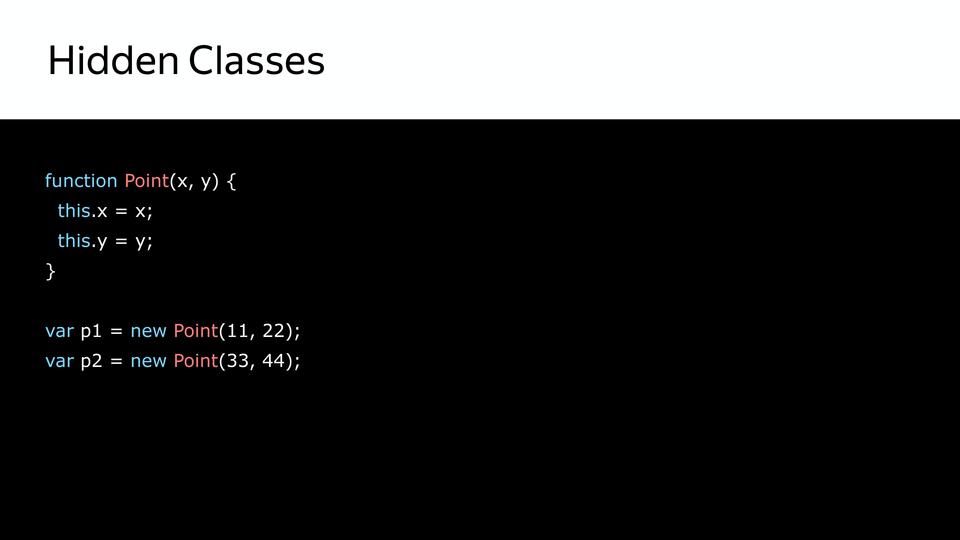
ポイントがあります-これはコンストラクターであり、オブジェクトが作成されます。 まず、ポイント自体のみを含む非表示のクラスが作成されます。

次に、このオブジェクトxのプロパティを設定し、非表示クラスがあったという事実から、xを含む次の非表示クラスが作成されます。
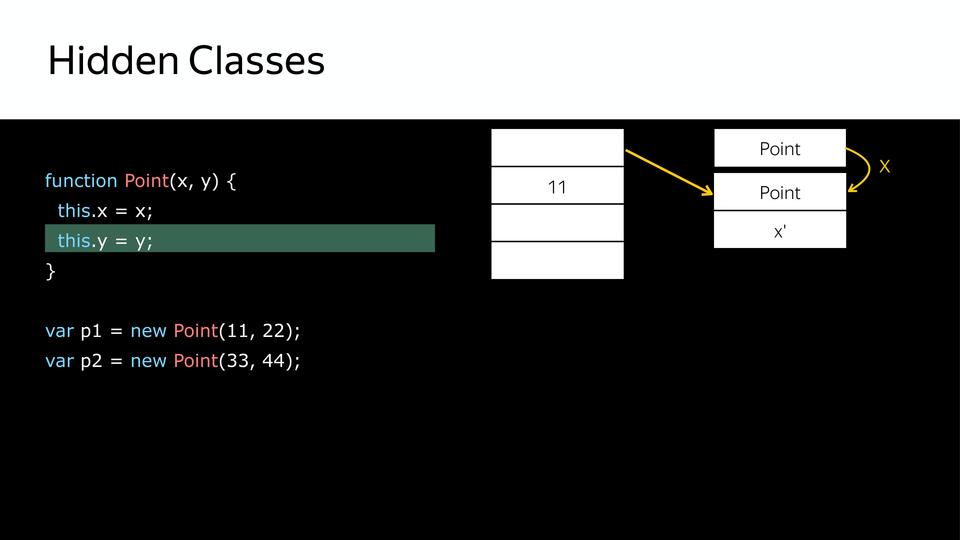
次に、yを設定し、それに応じて、xとyを含む別の非表示クラスを取得します。
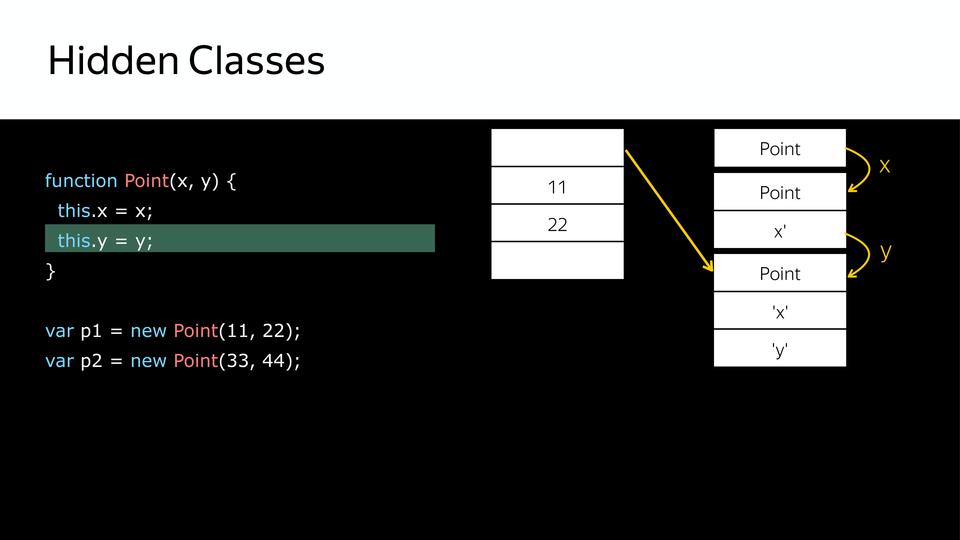
そこで、3つの隠されたクラスを取得しました。 その後、同じコンストラクターを使用して2番目のオブジェクトを作成すると、同じことが起こります。 すでに非表示のクラスがあり、それらを作成する必要はもうありません。マップするだけです。 そのため、後でこれら2つのオブジェクトの構造が同一であることがわかります。 そして、あなたは彼らと仕事をしているように見えます。
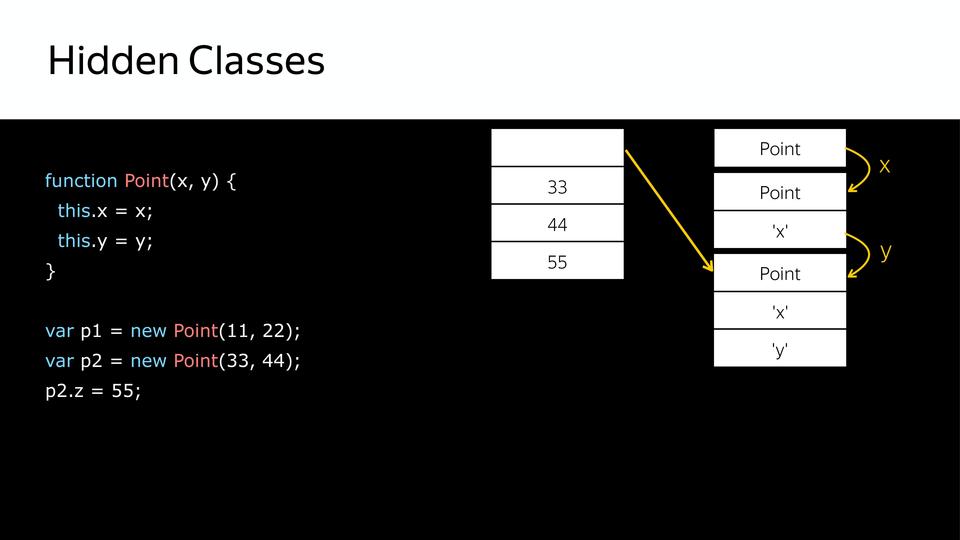
しかし、後でp2オブジェクトにプロパティを追加するとどうなりますか? 新しい非表示クラスが作成されます。 p1とp2はもはや類似していません。 なぜこれが重要なのですか? コンパイラがポイントループを反復処理し、p1と同じものがすべて揃うと、ツイスト、ツイスト、ツイスト、p2にぶつかり、別の隠されたクラスがあるため、コンパイラは最適化解除になります。彼は期待したものを受け取りませんでした。

これはいわゆるカモタイピングです。 アヒルタイピングとは何ですか? 表現はアメリカのスラングから来ました。何かがアヒルのように歩き、カチカチがアヒルのようであれば、それはアヒルです。 すなわち p1とp2の構造が同一である場合、それらは同じクラスに属します。 しかし、p2を構造に追加する必要があります。これらのアヒルはそれぞれ異なる方法でカチカチ音を立てます。これらは異なるクラスです。
そして、オブジェクトがどのクラスに属しているか、どのような変数、このデータをどこで使用し、どのように保存するかに関するデータを取得しました。 このために、インラインキャッシュシステムが使用されます。

この部分のインラインキャッシュの作成方法を見てみましょう。 最初に、コードを分析すると、そのような呼び出しで補足されます。 これは単なる初期化です。 インラインキャッシュの種類はまだわかりません。
ここで、ここで初期化すると言うことができます。this.primesの読み込みは次のとおりです。

主なダウンロードは次のとおりです。

そして、操作BinaryOperation-これはバイナリであることを意味するのではなく、単項演算ではなくバイナリであることを意味します。 左右のパーツがある操作。

実行時に何が起こりますか?
コードが到着すると、すべてコンパイラ内に既にあるコードに置き換えられ、コンパイラは型情報を持っている場合にこの特定のケースでうまく機能する方法を知っています。 つまり、ここでは、オブジェクトから素数を取得する方法を知っているコードを呼び出す代わりに使用されます。

ここでは、SMI配列から要素を取得する方法を知っているコードに置き換えられます。

2つのSMIの除算の剰余を計算する方法を知っているコードを次に示します。

すでに最適化されています。 そのため、コンパイラーはほぼ動作し、そのような部分で飽和しました。

もちろん、これによりオーバーヘッドが発生しますが、パフォーマンスも向上します。
私たちはインターネットを開発し、JavaScriptの数が増加し、より多くの生産性が必要になり、Googleは新しいクランクシャフトコンパイラを作成することで対応しました。
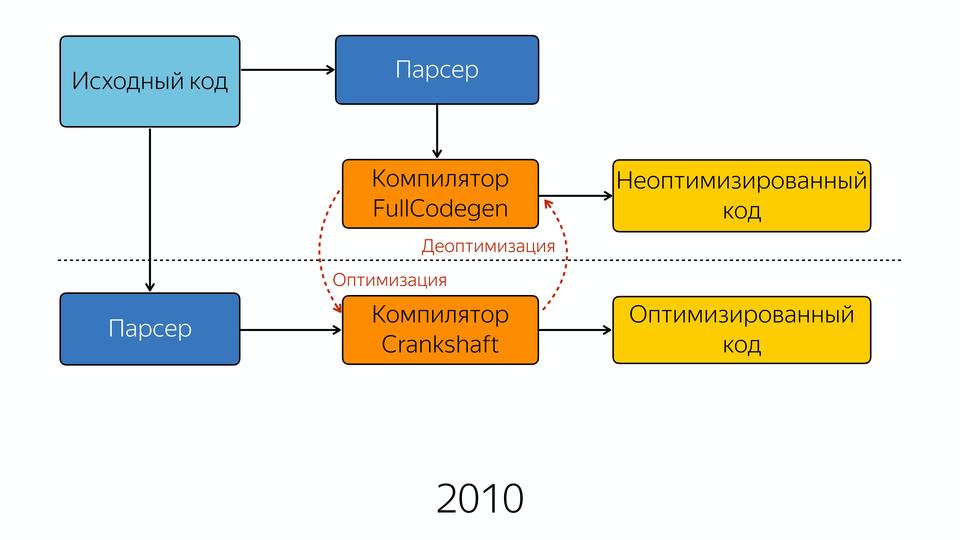
古いコンパイラはFullCodegenとして知られるようになりました。これは、完全なコードベースで動作し、すべてのJavaScriptとそのコンパイル方法を知っているためです。 そして、最適化されていないコードを生成します。 彼が何度か呼び出される関数に出くわした場合、彼はそれが熱くなったと信じており、Crankshaftコンパイラーがそれを最適化できることを知っています。 そして、彼は型に関する知識を与え、この機能は新しいクランクシャフトコンパイラで最適化できることを示しました。 次に、新しいコンパイラは抽象構文ツリーを取得します。 古いASTコンパイラからではなく、戻ってASTを要求することが重要です。 そして、型を知って最適化を行い、最後に最適化されたコードを取得します。
彼が最適化を行えない場合、彼は非最適化に陥ります。 これはいつ起こりますか? たとえば、隠しクラスサイクルでスピンした後、予期せぬ何かが発生し、最適化が解除されるなど、前に言ったとおりです。 または、たとえば、多くの人々は、左側に何かがあるときにチェックを行うことを好みます。たとえば、長さを取得します。 文字列があるかどうかを確認し、その長さを取得します。 なぜこれが悪いのですか? 行がない場合、左側にブール値が表示され、出力はブール値になり、その前に数値が表示されるためです。 この場合、最適化が解除されます。 または、彼はコードに会ったが、それを最適化することはできません。
例として同じコードを使用します。 ここでは、インラインキャッシュでいっぱいのコードがありました。新しいコンパイラーではすべてインラインです。

彼はそれをすべてインラインに挿入します。 さらに、このコンパイラは投機的最適化コンパイラです。 彼は何を推測していますか? 彼は型の知識を推測しています。 彼は、このタイプで10回呼び出した場合、このタイプは継続すると想定しています。 彼が期待するタイプが来るようなチェックがどこにでもあり、彼が期待していなかったタイプが来るとき、彼は非最適化に陥ります。 これらの改善によりパフォーマンスは大幅に向上しましたが、V8エンジンに関係するチームは徐々にすべてをゼロから始める必要があることに気付きました。 なんで? 最初のバージョンを作成するときにソフトウェアを開発する方法はありますが、2番目のバージョンを最初から作成するのは、作成方法を理解しているためです。 そして、彼らは新しいコンパイラー-2014年のターボファンを作成しました。
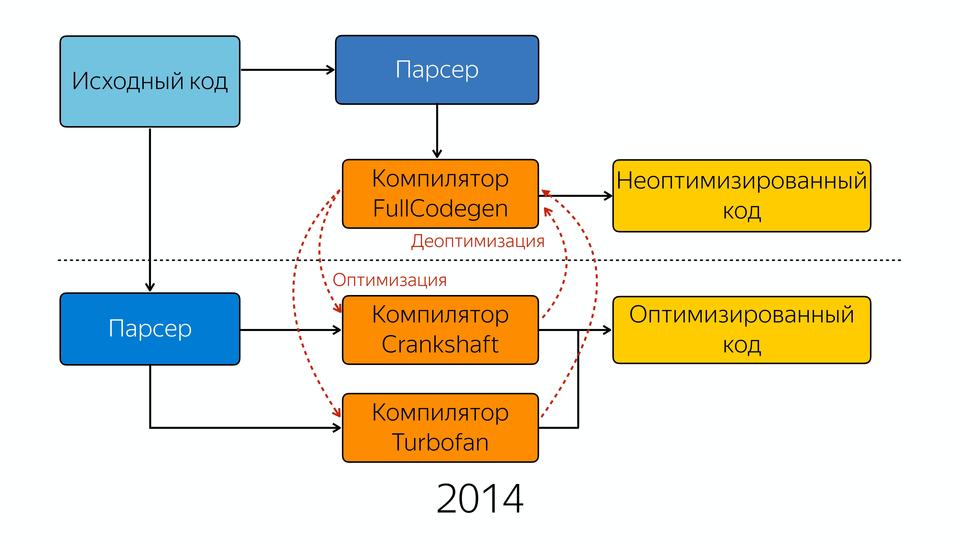
ソースコードがあり、これはパーサーに、次にFullCodegenコンパイラーに分類されます。 それで、違いはありませんでした。 出力では、最適化されていないコードを取得します。 あらゆる種類の最適化を行うことができる場合、CrankshaftとTurbofanの2つのコンパイラーに進みます。 FullCodegenは、Turbofanコンパイラーが特定のものを最適化できるかどうかを判断し、可能な場合は送信し、できない場合は古いコンパイラーに送信します。 そこで、ES6から新しいデザインを徐々に追加し始めました。 asm.jsを最適化することから始めました。
なぜ新しいコンパイラが必要なのですか?
- 基本的なパフォーマンスを改善する
- パフォーマンスを予測可能にします。
- ソースコードの複雑さを軽減
「基本的なパフォーマンスを向上させる」とはどういう意味ですか?
古いコンパイラは、強力なデスクトップがあった時代に書かれました。 そして、オクタン、合成などのテストでテストされ、ピーク性能がテストされました。 最近、Google I / Oカンファレンスがあり、V8の開発を管理しているマネージャーは、コンパイラが実際に動作するものに対応しないため、基本的にオクタンを放棄したと述べました。 そして、これは私たちが非常に良いピークパフォーマンスを持っているという事実につながりましたが、基本的なもの、すなわち コード内の事柄は最適化されておらず、うまく機能するコードがそのような事柄に出くわすと、パフォーマンスが大幅に低下しました。 そして、そのような操作はたくさんありますが、そのうちのいくつかを以下に示します:forEach、map、reduce。 それらは、チェックを詰めたプレーンなJSで書かれています。 頻繁に使用することをお勧めします。
バインドの遅い動作-内部的に実装されており、完全に恐ろしいことが判明しました。 多くのフレームワークが独自のバインド実装を作成しました。 多くの場合、人々は私が座って膝の上にバインドを書いたと言って、驚くほど速く動作します。 try {} catch(e){}(そして最後に)を含む関数は非常に遅いです。

多くの場合、パフォーマンスが低下しないように、使用しない方が良いタブレットがありました。 実際、コンパイラが正常に動作していないため、コードは遅くなります。 また、ターボファンの出現により、すべてがすでに最適化されているため、それを忘れることができます。 また、非常に重要です:非同期関数のパフォーマンスが改善されました。
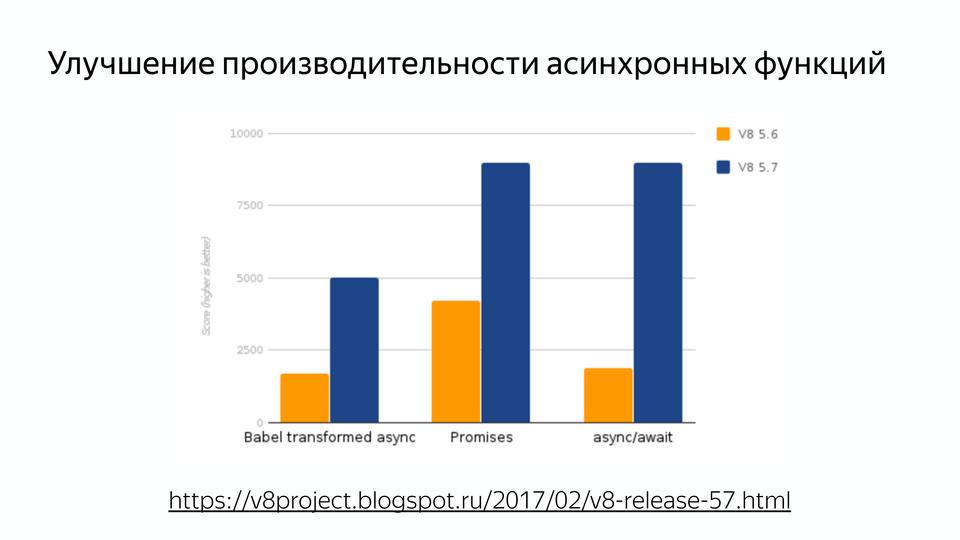
したがって、誰もが最近リリースされた新しいノードのリリースを待っています;そこでは非同期/待機のパフォーマンスが重要です。 私たちの言語は最初は非同期であり、コールバックのみをうまく使用できました。 また、promiseを使用して記述している人は、サードパーティの実装がネイティブの実装よりも高速であることを知っています。
次の課題は、パフォーマンスを予測可能にすることでした。 このような状況がありました:jsPerfで正常に実行されたコードは、動作中のコードに貼り付けられたときにまったく異なるパフォーマンスを示しました。 しかし、コードが当初の期待どおりに生産的に機能することを保証できなかった場合もあります。
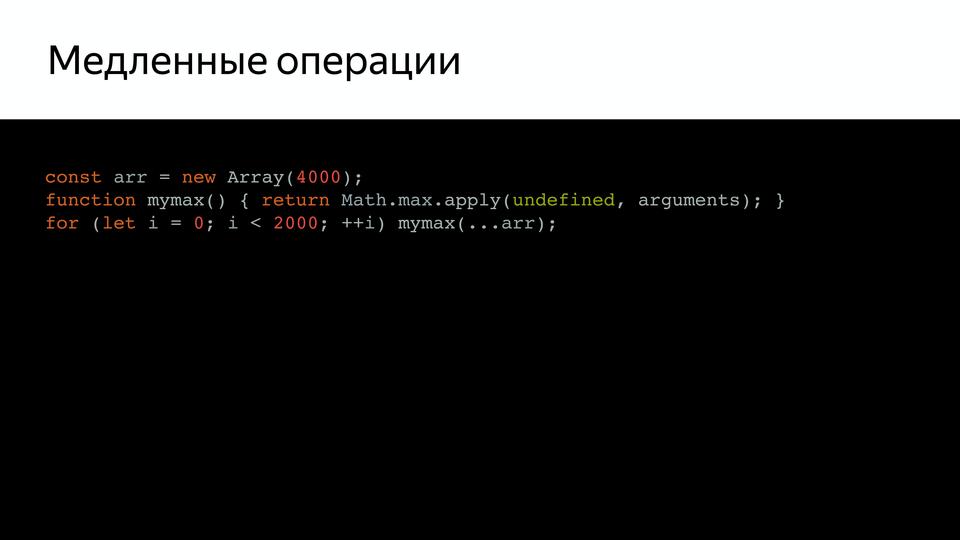
たとえば、mymaxを呼び出す非常に単純なコードがあり、それをチェックすると(キーtrace-optおよびtrace-deoptを使用して、どの関数が最適化され、どの関数が最適化されなかったかを示します)。
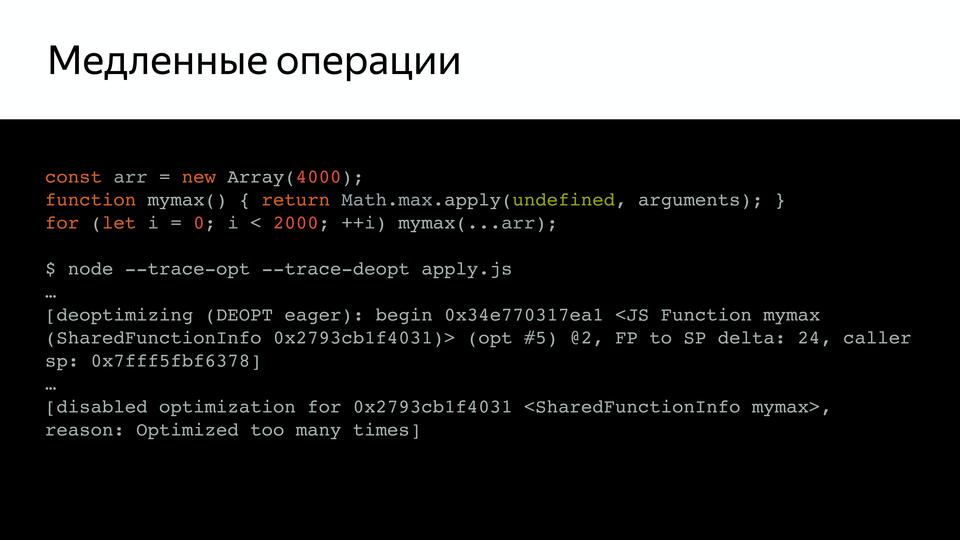
これをノードで実行するか、V8がブラウザーとは別に動作する特別な環境であるD8で実行できます。 最適化が無効になっていることがわかります。 検証のために何度も実行されたためです。 問題は何ですか? 引数の擬似配列が大きすぎることがわかり、内部では、この配列のサイズのチェックが行われたことがわかりました。 さらに、このチェックは、Benedikt Meurer(Turbofanのリード開発者)が言ったように、何の意味もありませんでしたが、長年にわたってコピーペーストで処理されていました。
そして、なぜ長さが制限されているのですか? 結局のところ、スタックのサイズはチェックされず、何もチェックされませんでした。 これは、排除する必要がある予期しない動作です。

別の例として、ここでは2つのコールバックを呼び出すディスパッチャーがあります。 また、彼を呼び出すと、彼が最適化されていないことがわかります。 ここで問題は何ですか? その1つの関数は厳密であり、2番目の関数は厳密ではありません。 また、古いコンパイラでは異なる隠しクラスを取得します。 すなわち 彼はそれらを異なると考えています。 また、この場合、彼は最適化を解除します。 このコードと以前のコードの両方は、原則として正しく記述されていますが、最適化されていません。 これは予想外です。

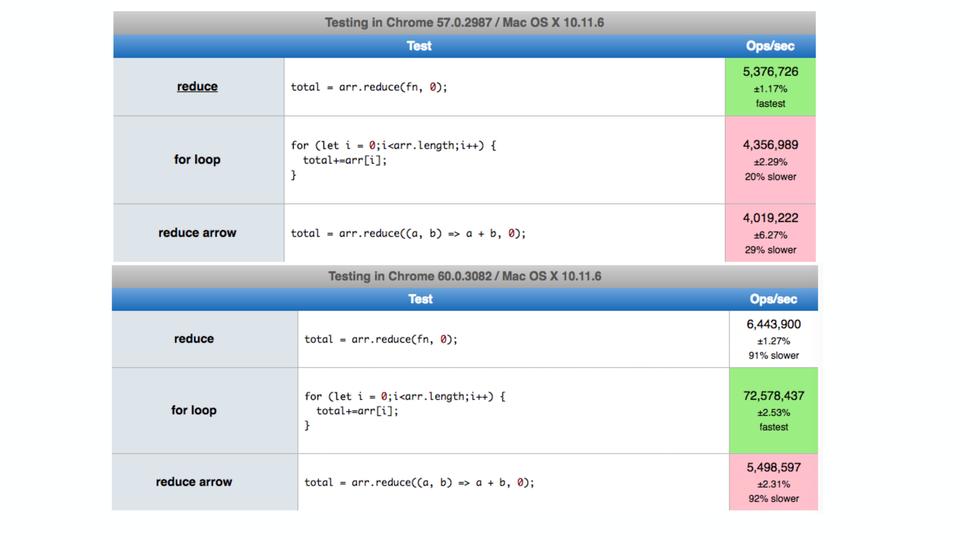
また、Twitterでそのような例があり、いくつかのケースではchromeのforループがreduceよりも遅く動作することが判明しました。 reduceの方が遅いことはわかっていますが。 問題は、予期せずにfor内でletが使用されていたことが判明しました。 その時点で最新バージョンをインストールしましたが、結果はすでに良好です-修正済み。
次のポイントは、複雑さを軽減することでした。 ここにはバージョンV8 3.24.9があり、4つのアーキテクチャをサポートしていました。
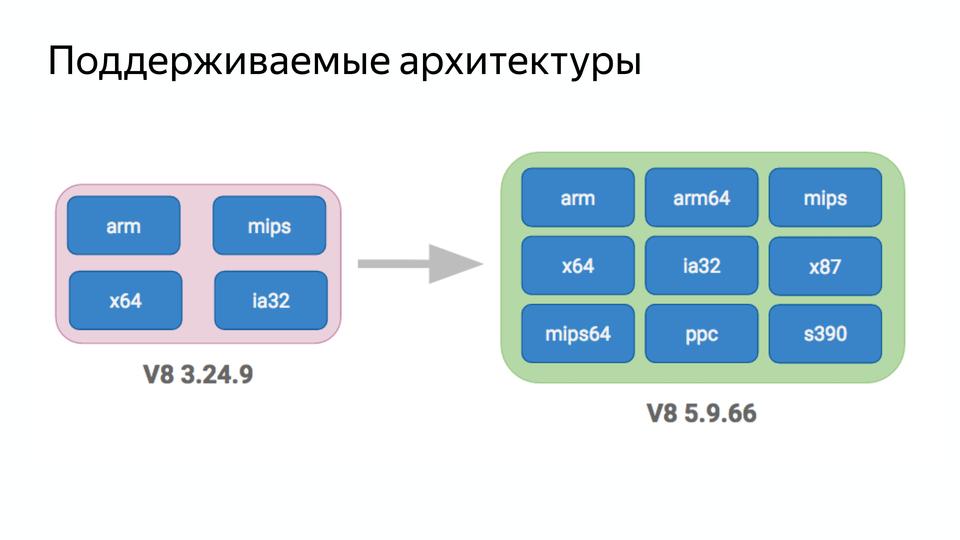
V8は9つのアーキテクチャをサポートするようになりました!
そして、コードは何年も蓄積されてきました。 JS、アセンブラー、Cで部分的に書かれていたため、チームに来た開発者はこのように感じました。

世界の変化に対応できるように、コードは簡単に変更できる必要があります。 また、ターボファンの導入により、アーキテクチャ固有のコードの量が減少しました。
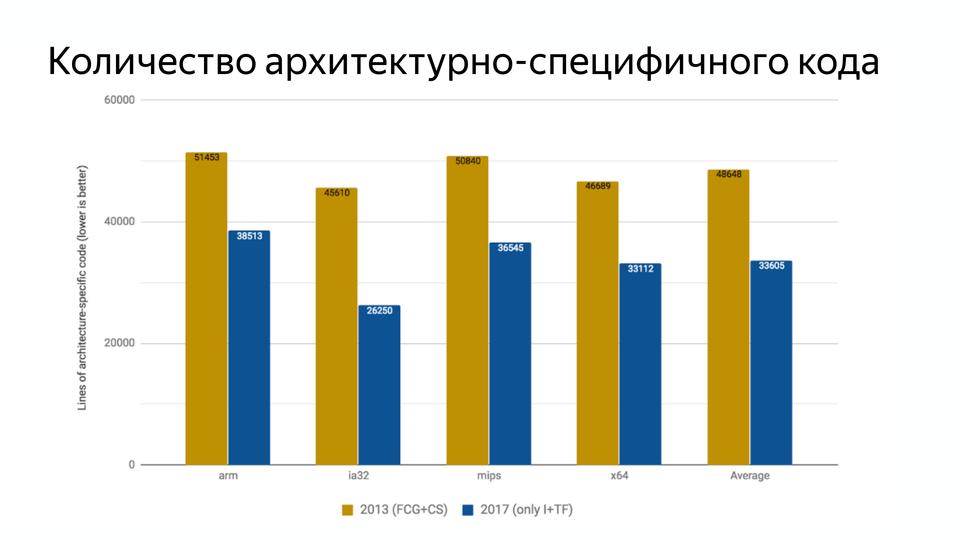
2013年から2017年にかけて、アーキテクチャ固有のコードよりも29%少なくなりました。 これは、新しいターボファンコード生成アーキテクチャの登場によるものです。
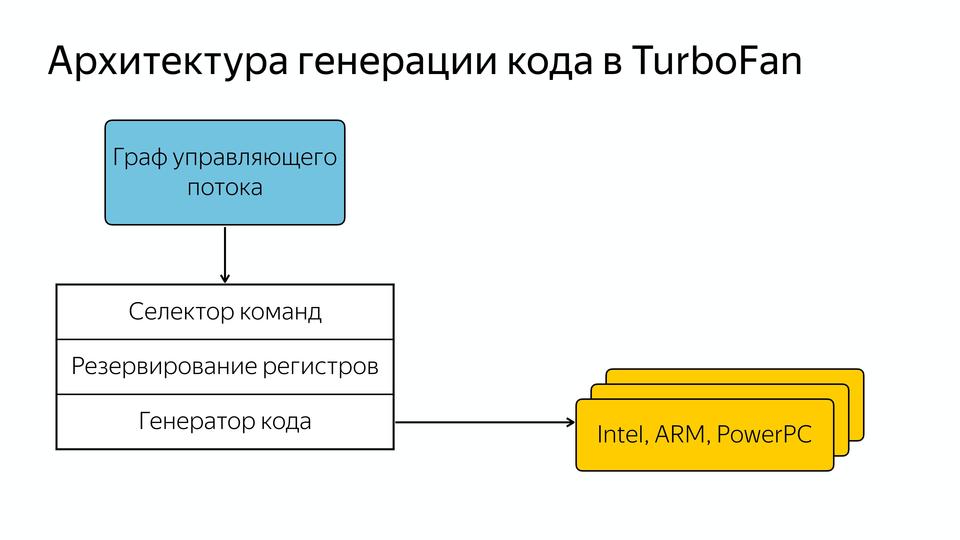
彼らはそれをデータ駆動型、つまり 制御フローグラフがあり、そこに何が起こるかについてのデータと知識が含まれています。 そして、それは一般的なコマンドセレクターに分類され、レジスタの予約があり、次に異なるアーキテクチャのコード生成があります。 すなわち 開発者は、特定のアーキテクチャ向けにすべてがどのように記述されているかを知る必要はなくなりましたが、より一般的なコードを作成できます。 そういうわけで、コードはよく改善されましたが、インタープリター言語用のコンパイラーを書いてから数年後には、インタープリターが必要であることがわかりました。
その理由は何ですか? その理由は、Steve Jobsの手にかかっています。

もちろん、これはiPhone自体ではなく、iPhoneを生み出したスマートフォンであり、インターネットへの便利なアクセスを可能にしました。 そしてこれは、モバイルデバイス上のユーザーの数がデスクトップ上の数を超えたという事実につながりました。
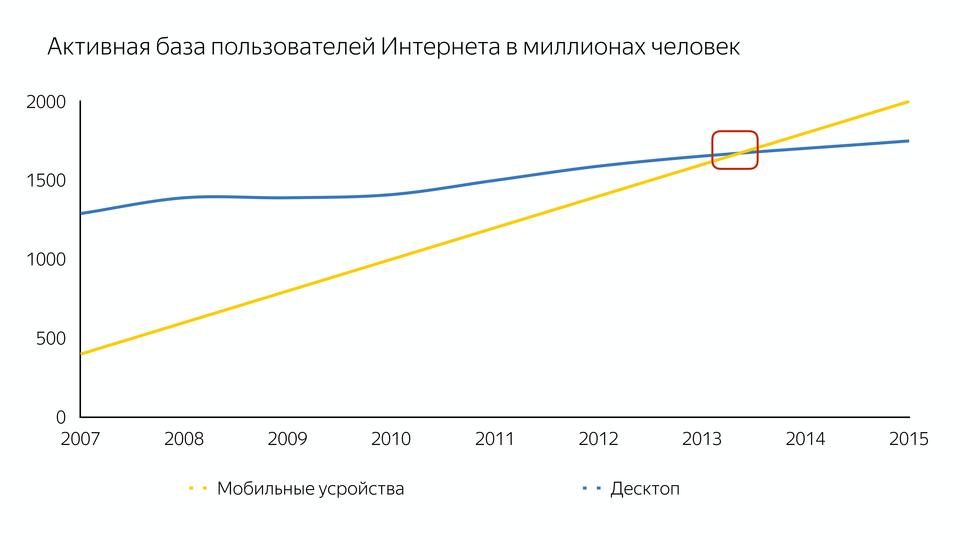
そして当初、コンパイラはモバイルデバイス用ではなく、強力なデスクトップ用に設計されていました。
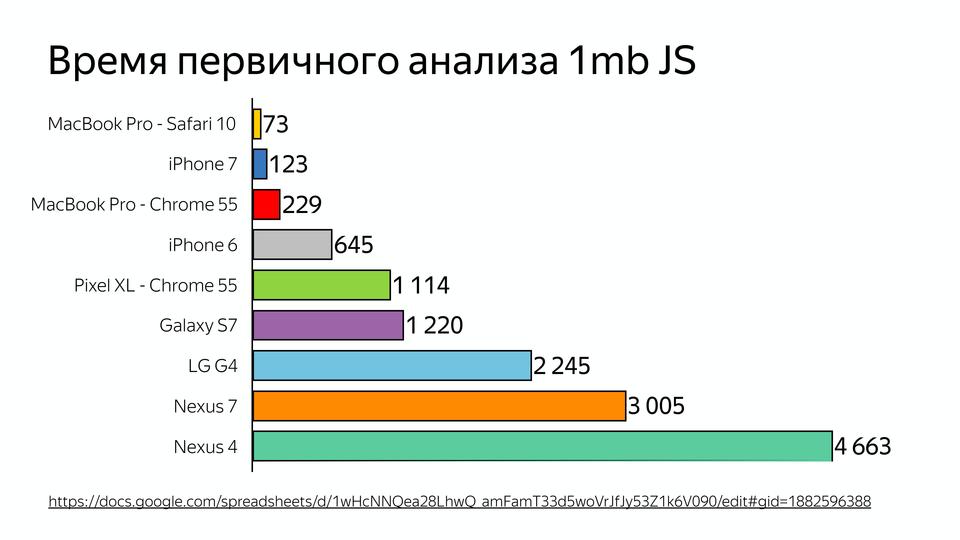
これは、1MB JavaScriptの初期分析タイムラインです。 そして最近、VKontakteがクライアントレンダリングではなくサーバーレンダリングを行う理由について質問がありました。 JS分析に費やされる時間は、モバイルデバイスでは2〜5倍長くなる可能性があるためです。 そして、我々はトップエンドのデバイスについて話している、そして人々はしばしば完全に異なるもので行く。
もう1つの問題:多くの中国のデバイスには512 MBのメモリがあり、V8メモリの割り当て方法を見ると、別の問題があります。
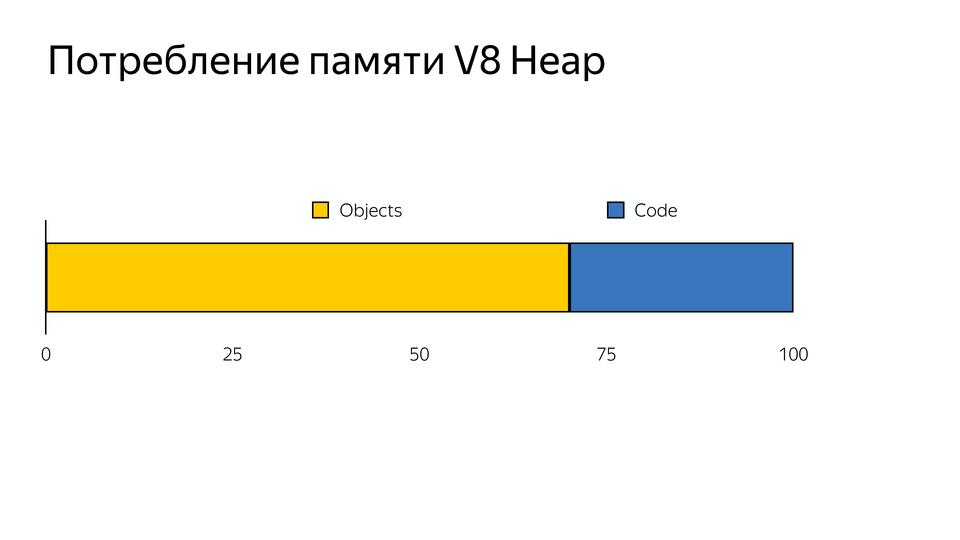
メモリは、オブジェクト(コードが使用するもの)とコードオブジェクト(コンパイラが使用するものです-たとえば、インラインキャッシュをそこに格納する)に分かれています。 内部使用をサポートするために、メモリの30%が仮想マシンによって占有されていることがわかりました。 , .
- , 2016 Android Ignition.

, , Turbofan, , - . -.
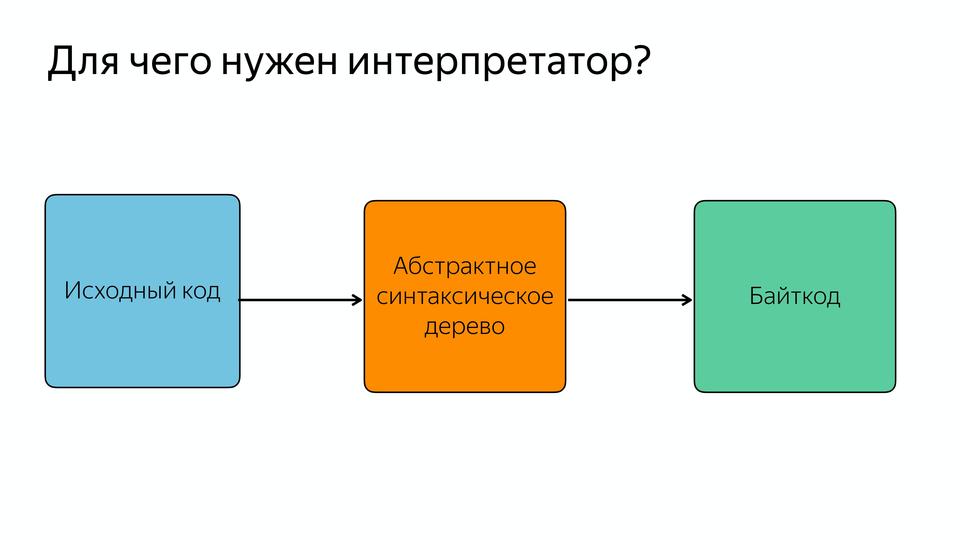
-, JavaScript , .
- , – . - assembler, . , .
, .

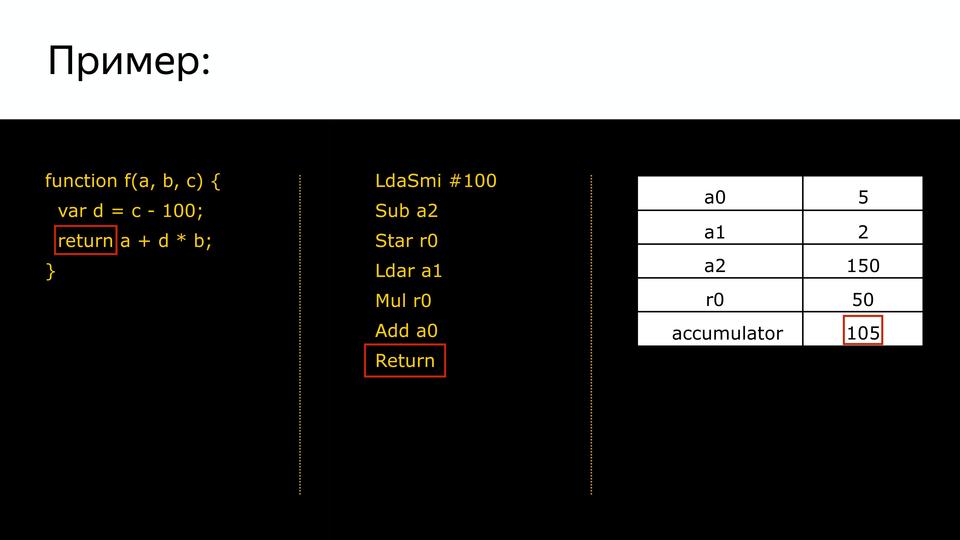
, .
, . accumulator ( , , ) smi integer 100.

, a2 ( 150) (100). accumulator 50.

, r0. d.

. b, accumulator, a0 , , 105.
. , .
, , inline caches. – Data-driven IC, . – , – .
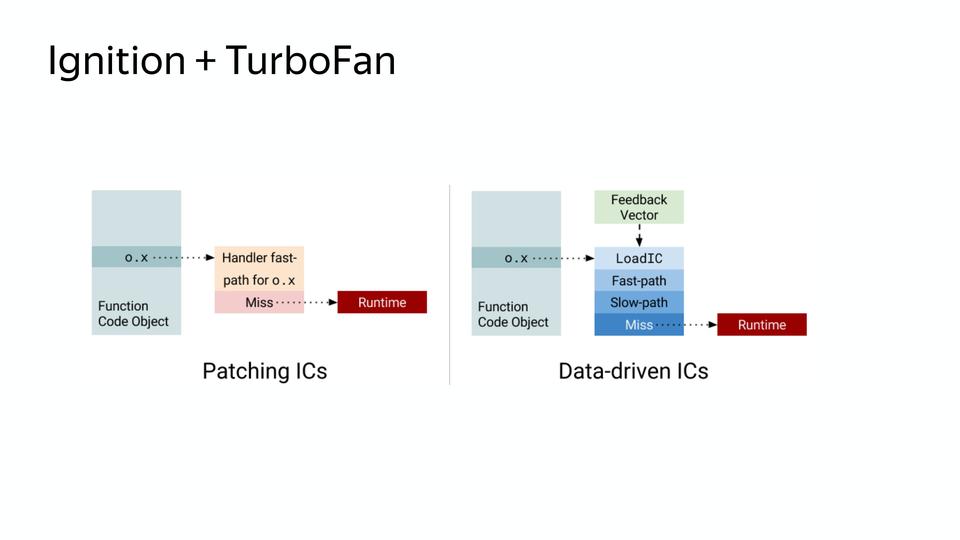
. - , , , - . , , , . inline caches, , , . , , , . .
.
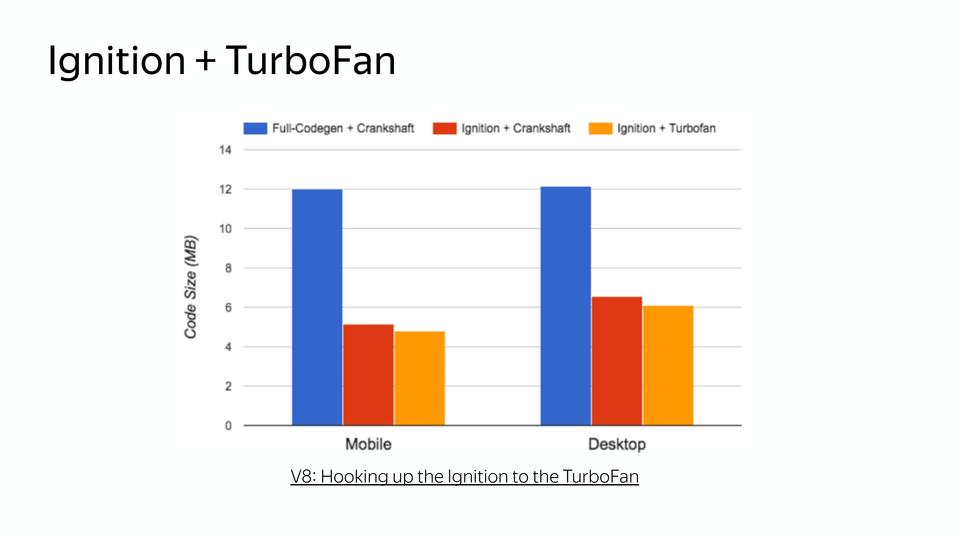
Turbofan. , FullCodegen JS, Crankshaft — JS, Turbofan JS JS. , , , , , . .

, ( , ES6 , ). , , . すなわち , hidden class – , , . hidden class, , , .
V8 JIT-. JIT- — . JIT- , , , . , , - . , . a+b – . , number+number string+string, . JIT-.
, (, ). – . Turbofan , , .
– . , . , , , . . - , . - . .
. , . , ( , , ).
.
github.com/v8/v8/wiki/TurboFan
http://benediktmeurer.de/
http://mrale.ph/
http://darksi.de/
https://medium.com/@amel_true
JS , , , HolyJS :
- Better, faster, stronger — getting more from the web platform (Martin Splitt)
- The Post JavaScript Apocalypse (Douglas Crockford)
- Testing serverless applications (Slobodan Stojanovic)