
着信条件と要件
遊び場を作成する必要があったシステムの目的について少し説明します。
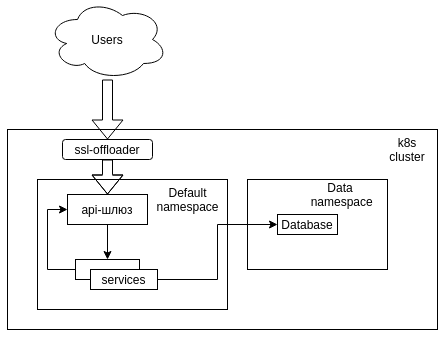
- Kubernetes、ベアメタルクラスター。
- nginxに基づく単純なAPIゲートウェイ。
- データベースとしてのMongoDB。
- CIサーバーとしてのJenkins。
- BitbucketのGit。
- 相互に(apiゲートウェイ経由で)、ベースおよびユーザーと通信できる2ダースのマイクロサービス。
チームリーダーとの積極的なコミュニケーションで策定できた要件:
- リソース消費の最小化。
- 遊び場で作業するためのサービスコードの変更を最小限に抑える。
- いくつかのサービスの並行開発の可能性。
- 1つのスペースで複数のサービスを開発する機能。
- ステージングにデプロイする前に顧客に変更を示す機能。
- 開発されたすべてのサービスは1つのデータベースで機能します。
- テストコードを展開する開発者の労力を最小限に抑えます。
トピックに関する考察
最初から、k8sで並列スペースを作成する最も論理的な方法は、仮想クラスターのネイティブツールまたはk8sの用語である名前空間を使用する最も論理的な方法であることは明らかでした。 また、タスクは、クラスター内のすべての対話がkube-dnsによって提供される短い名前を使用して実行されるという事実によって簡素化されます。つまり、接続を失うことなく、構造を別のネームスペースで起動できます。
このソリューションには、1つの問題しかありません。利用可能なすべてのサービスをネームスペースにデプロイする必要があります。これは長く、不便で、大量のリソースを消費します。
名前空間とDNS
サービスを作成するとき、k8sは<service-name>。<namespace-name> .svc.cluster.localの形式のDNSレコードを作成します。 このメカニズムにより、起動された各コンテナのresolv.confに加えられた変更により、同じ名前空間内の短い名前を介した通信が可能になります。
通常の状態では、次のようになります。
search <namespace-name>.svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.2
options ndots:5
つまり、同じ名前空間のサービスは、名前<service-name>でアクセスでき、隣接する名前空間では名前<service-name>でアクセスできます。
システムを回る
この時点で、単純な考えが思い浮かびます:「 ベースは一般的であり、api-gatewayはリクエストをサービスにルーティングする責任があります。名前空間で最初にサービスにアクセスし、デフォルトで存在しない場合はどうですか? 」
はい、同様のソリューションを名前空間設定で整理することができます(nginxであることを覚えています)が、同様のソリューションはpgと他のクラスターの設定に違いを生じさせ、不便で多くの問題を引き起こす可能性があります。
そのため、文字列の置換方法が選択されました
search <namespace-name>.svc.cluster.local svc.cluster.local cluster.local
に
search <namespace-name>.svc.cluster.local svc.cluster.local cluster.local default.svc.cluster.local
このアプローチは、ネームスペースに必要なサービスがない場合、ネームスペースのデフォルトに自動的に切り替わります。

次のように、クラスターで同様の結果を得ることができます。 Kubeletはホストマシンのresolve.confからコンテナに検索パラメーターを追加するため、各ノードの/etc/resolv.confに次の行を追加します。
search default.svc.cluster.local
ノードにサービスのアドレスを解決させたくない場合は、kubeletの起動時に--resolv-confオプションを使用できます。これにより、/ etc / resolv.confの代わりに他のファイルを指定できます。 たとえば、同じ行の/etc/k8s/resolv.confファイル。
技術の問題
さらなる決定は非常に簡単で、次の契約に同意するだけです。
- 新しい機能は、play / <機能名>という形式の別々のブランチで開発されます
- 同じ機能内で複数のサービスを操作するには、関連するすべてのサービスのリポジトリでブランチ名が一致する必要があります。
- Jenkinsはすべての展開作業を自動的に行います。
- 機能テストは、テスト用に<feature-name> .cluster.localで入手できます。
SSLオフローダー設定
リクエストを対応するネームスペースのapi-gwにリダイレクトするNginx構成
server_name ~^(?<namespace>.+)\.cluster\.local; location / { resolver 192.168.0.2; proxy_pass http://api-gw.$namespace.svc.cluster.local; }
ジェンキンス
展開プロセスを自動化するには、Jenkins Pipeline Multibranch Pluginプラグインが使用されます。
プロジェクト設定では、play / *パターンに一致するブランチのみが収集されることを示し、コレクターが使用するすべてのプロジェクトのルートにJenkinsfileを追加します。
groovyスクリプトは処理に使用されますが、全体を説明するのではなく、いくつかの例を示します。 展開の残りの部分は、基本的に通常と変わりません。
ブランチ名の取得:
def BranchName() { def Name = "${env.BRANCH_NAME}" =~ "play[/]?(.*)" Name ? Name[0][1] : null }
名前空間の最小構成にはデプロイ済みのapi-gatewayが必要なので、名前空間を作成してそこにapi-gatewayをデプロイするプロジェクトへの呼び出しを追加します。
def K8S_NAMESPACE = BranchName() build job: 'Create NS', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]] build job: 'Create api-gw', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]]
おわりに
特効薬はありませんが、ベストプラクティスだけでなく、サンドボックスが他の人によってどのように編成されているかについての説明も見つからなかったため、k8に基づいてサンドボックスを作成するために使用した方法を共有することにしました。 おそらくこれは理想的な方法ではないので、この問題がどのように解決されるかについてのコメントやストーリーを喜んで受け入れます。