
開始時に評価が必要です-イニシアチブの予算と財政的正当性を確保するため。 原則として、計画的な負荷に対するビジネスからの予備的なアーキテクチャと推定値、および統合相互作用の負荷に対する技術者からの推定値があります。 ポジションの総数と構成は、設計と実装の過程で、または負荷テストの結果に応じて調整できます。 つまり、入力データが小さく、「これは正確ではない」という事実により、すべてが複雑になります。
しかし、平滑化要因があります。 計算が個別に実行されるという事実にもかかわらず、すべての留保された鉄はESFプログラムの一般的な留保プールに分類されます。 これにより、多くの場所で「病院の平均気温」を使用できます。実際、あるケースで負荷が大きくなった場合は、別の負荷で平準化されます。 追加の平滑化要素は、備品プールの管理が集中化され、物理的な準備が銀行全体に共通しているため、準備プールに存在することで直ちにコストが発生するわけではないことです。 私たちにとっては、特定のサイジングにおけるエラーよりもシステムエラーを最小限に抑えることが重要です。
これは、各イニシアチブ、多くの入力パラメータ、および各コンポーネントの個別の計算のサイジングモデルの開発を意味する、サイジングの古典的なアプローチがここでは適切でないことを意味します。 幸いなことに、私たちにはまだ単一のシステムがあり、標準の「キューブ」から組み立てられた3つまたは4つの標準アーキテクチャがあります。 したがって、すべての複雑さと変動性を共通のサイジングモデルに減らすことができました。
ESFのサイジングモデルとは何ですか?
サイズ設定モデルは、いくつかのセクションのテンプレートです。 それぞれについて詳しく見ていきましょう。
セクション1.入力
入力データの量を最小限に抑え、ハードウェアの評価に大きな影響を与えるもののみを残し、同時に製品チームから早期に取得できます。 重要な入力パラメーターは、1時間あたりのビジネストランザクションのピーク数です。
リモートチャネルと内部ネットワークの入力を共有します。
どちらの場合も、お客様から評価を受け取ります:
- 1時間あたりのピークビジネスオペレーション。 この指標は重要な指標であり、必要な処理能力に影響します。
- 1日あたりのビジネスオペレーションの平均数。 保存されるデータの量を決定します。
また、外部システムとのMQ(Messages Queue)統合を通じてリクエストの数を取得します。
| 内部ネットワーク
| |
| お名前
| 解説
|
| 1時間あたりのピーク営業時間
| ビジネス要件から取得または計算:1日あたりの操作数/ 10
|
| 1日あたりのビジネスオペレーションの平均数
| ビジネス要件から取得または計算:1時間あたりの操作数* 10
|
| 1秒あたりのMQを介したピークリクエスト(外部システムとの直接統合)
| MQ上のポイントツーポイント合計
|
| 外部ネットワーク
| |
| お名前
| 解説
|
| 1時間あたりのピーク営業時間
| ビジネス要件から取得または計算:1日あたりの操作数/ 10
|
| 1日あたりのビジネスオペレーションの平均数
| ビジネス要件から取得または計算:1時間あたりの操作数* 10
|
1時間あたりのピークボリュームと1日あたりの平均をリンクする「マジックナンバー」10は、顧客が両方のパラメーターを自分で評価できない場合に使用されます。 Sberbankシステムの産業運用の経験に基づいており、そのビジネスの次の機能によって決定されます。
- ロシアでは、12のタイムゾーン、支店、顧客がすべてのタイムゾーンに分散しており、支店の営業時間は1日あたり10〜12時間です。
- ユーザーと操作の最大数はモスクワのタイムゾーンに集中しており、このゾーンがピーク負荷を決定します。
- クロックによる負荷分散のグラフには、午前と午後の2つのピークがあります。通常、すべてのタイムゾーンで同じであり、タイムシフトを考慮しています。
モデルパラメータ
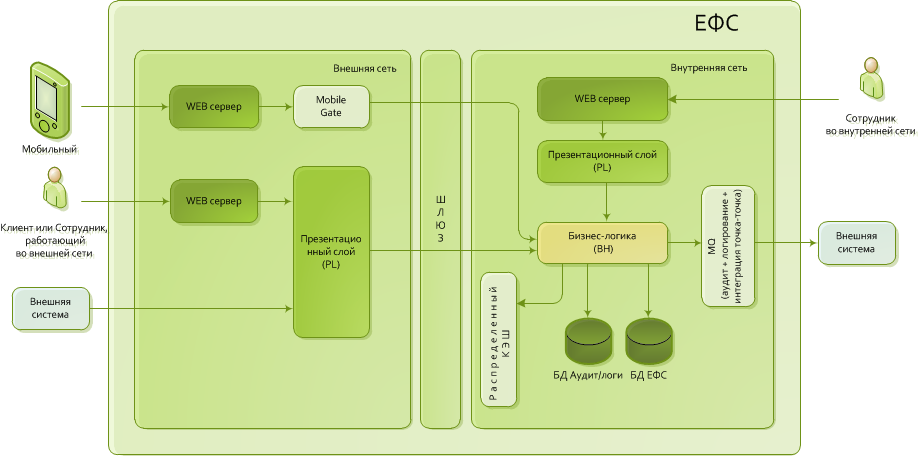
大きな図を表示します。
図1.簡素化されたESFアーキテクチャ
従来の3層アーキテクチャに基づくESFアーキテクチャ
- プレゼンテーション層。 ほとんどの場合-静的なnginxだけです。特別な場合には、アプリケーションサーバーが追加されます。
- ビジネスロジックを備えたアプリケーションサーバー。
- データベース
セクション2.モデルパラメーター
パラメーターは3つのグループに分けられます。
- 実装された機能に応じたパラメーター。
それらはほとんどの場合、特定のサイズに合わせてアーキテクトによって変更されます。 重要なパラメーターは、ビジネスオペレーションの数を着信HTTPリクエストの数に関連付ける係数です。 ここでは、典型的な「キューブ」のオン/オフを切り替え、それらの間のリクエストフローの分配を決定します。
- 特定のサイズに合わせて変更できるパラメーター。
これらは、ほとんどの場合に適した典型的なパフォーマンスパラメータです。
- 固定パラメーター。
私たちの条件における典型的な鉄の性能パラメータ。 たとえば、永続メッセージを使用しないため、永続性を無効にしてMQパフォーマンスを取得します。
モデルパラメータ:
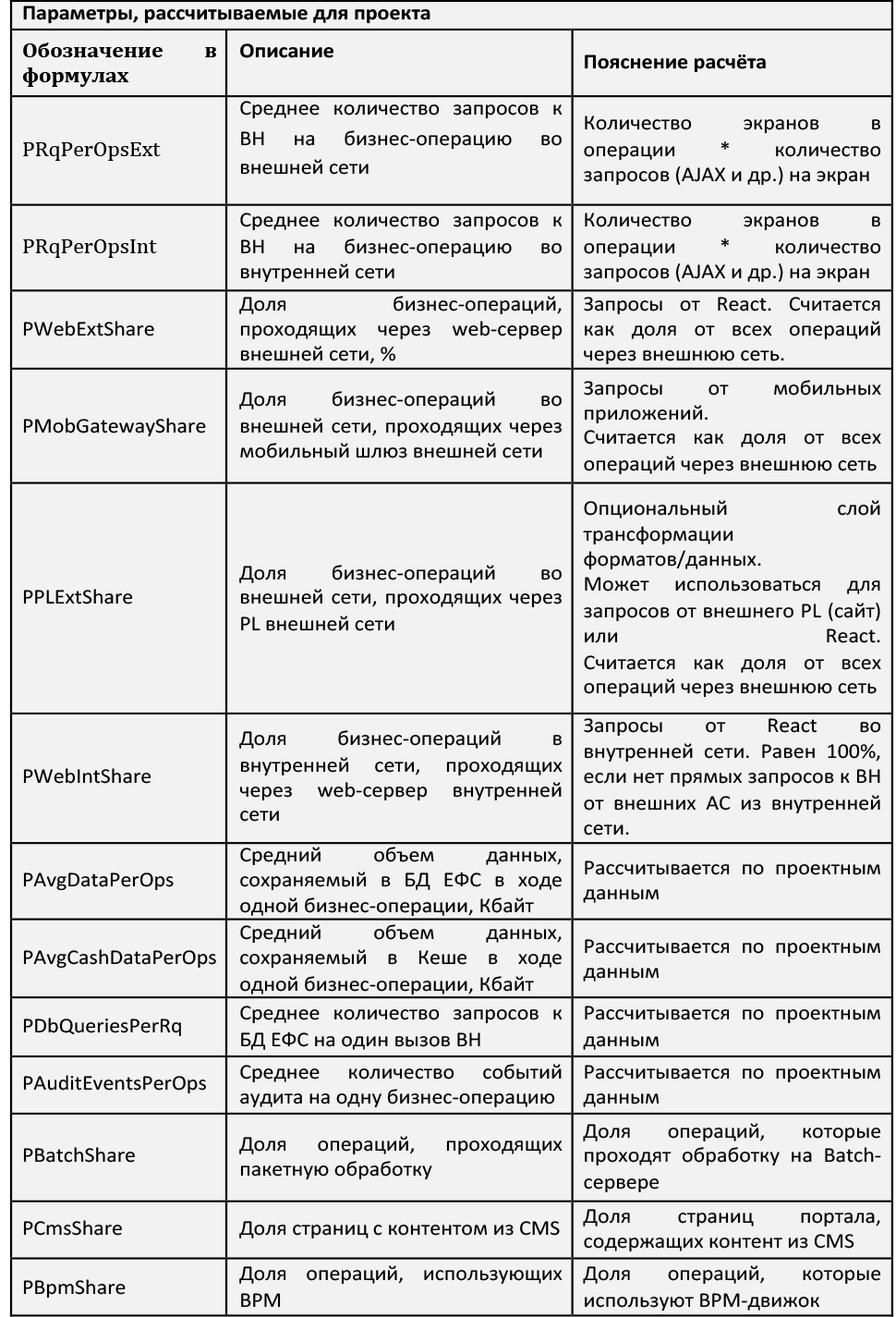
推定オッズ
表は係数の説明を提供します;値はそれ自身のために開発されました。 興味があれば、コメントで質問してください-専門家の評価を共有します。
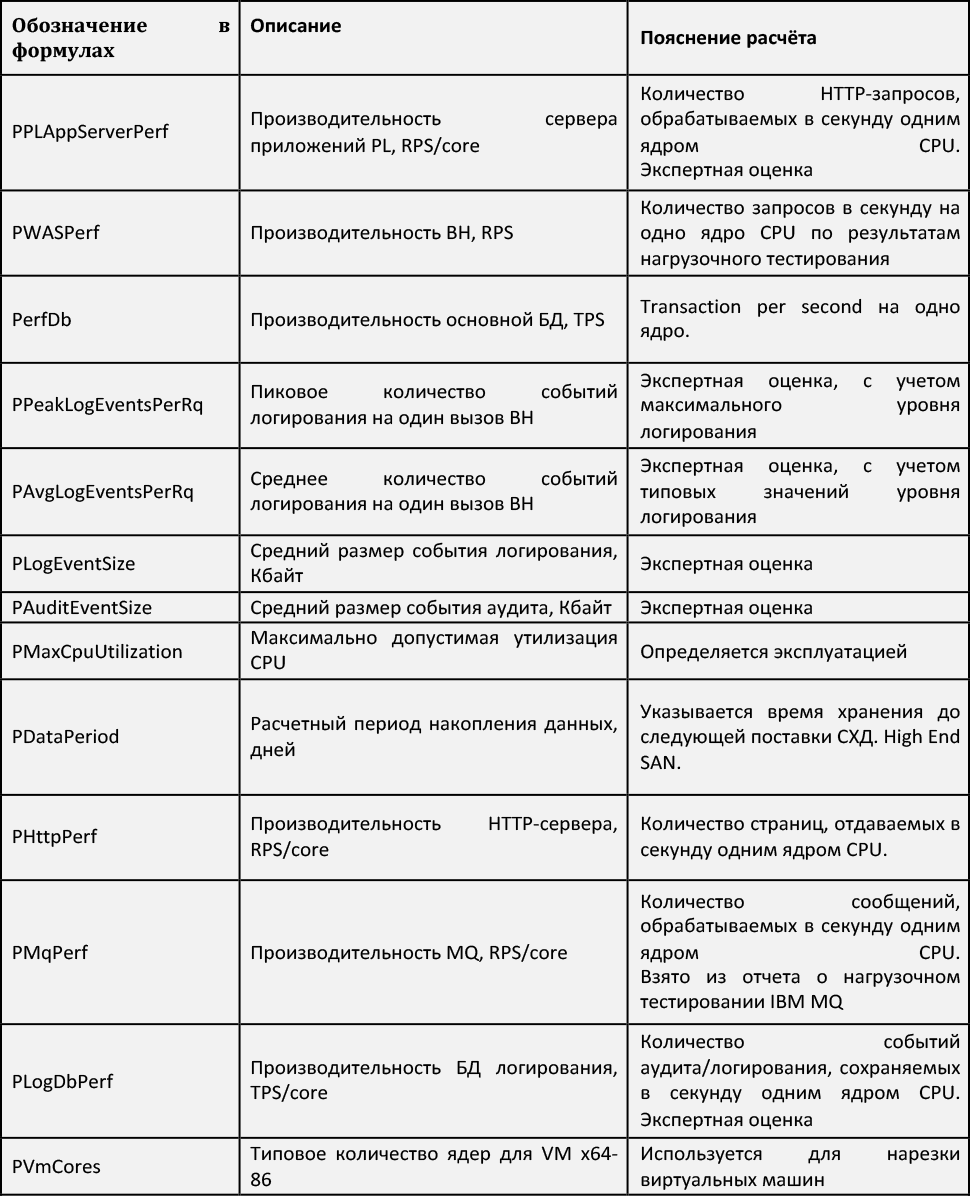
セクション3.計算モデル
各位置の最終推定値に入力データとパラメーターを表示する計算式を備えた計算モデル。
単純化されたサイジングモデルについて説明します。 それは職位のセットを減らし、産業環境のマルチブロック組織を反映しませんでした。 あなたのビジネスがSberbankのサイズを持っていない場合、面白くない側面で記事を過負荷にしないために単純化が行われます。 マルチブロックアーキテクチャは別の記事のトピックです。これについては他の記事で説明します。
アプリケーションサーバーとWebサーバーは、各アプリケーションサービスに割り当てられます。 障害やメンテナンス中の相互影響を排除するために、異なるアプリケーションサービスを組み合わせることはありません。 データベースは一般的なものであり、財務上の正当性と予測のために考慮されます。
以下は、計算に使用する公式です。
- 内部ネットワークでの1秒あたりのピークリクエスト:
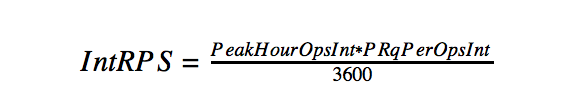
ユーザーのピーク数に1秒あたりの要求数を掛けると見なされます。
- 外部ネットワーク上の1秒あたりのピークリクエスト:
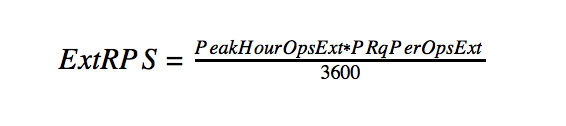
- Webサーバーの数の計算。
この計算には、内部ネットワークの静的配布、クエリルーティング、およびキャッシュが含まれます。
内部ネットワーク上のWebサーバーの数

- 外部ネットワーク内のWebサーバーの数
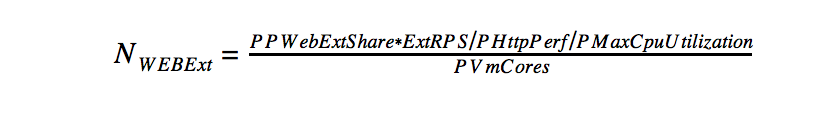
- モバイルゲートウェイ外部ネットワーク

- 外部ネットワークのプレゼンテーションロジック

- 内部ネットワーク上のプレゼンテーションロジック
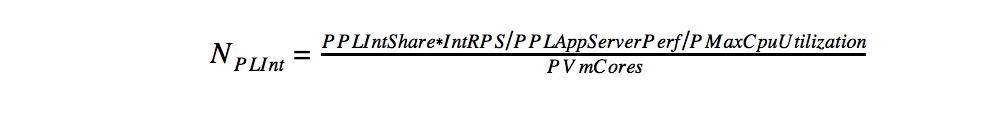
- ビジネスロジックのアプリケーションサーバーの計算

- MQ(監査+ロギング+ポイントツーポイント統合)
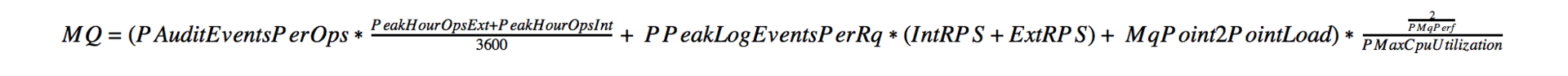
- 分散内部キャッシュ

- DBMS計算
- CPUデータベースの数

- RAMデータベースの数
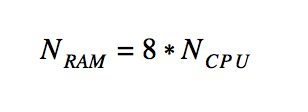
- DBサイズ

サイジングモデルの出力で、産業環境のハードウェアの推定値を取得します。
世界の実践では、3つの主要なサイジングモデルがあります。
- カスタムモデル
システムで同時に作業しているユーザーの数とその行動の分析に基づくモデル。 このモデルは、情報システムでのユーザー数とその行動に関する一般情報を持つ企業を対象としています。
- トランザクションモデル
トランザクションの分析、1人のユーザーまたはユーザーのグループに分類されるIP内のデータ量に基づくモデル。 このモデルは、知的財産の従業員の仕事の定量的特性に関する正確なデータを持っている企業を対象としています。 これは、会社にITインフラストラクチャがあり、ビジネスプロセスを自動化または改善するためのシステムを導入する段階にあることを意味します。
- テストモデル
パフォーマンステストに基づくモデル。 このモデルは、ビジネスアプリケーションを実装するための明確な計画があり、詳細を詳細に説明している企業を対象としています。 基本的に、これらは既に何らかのビジネスプロセス自動化システムを実装しているが、システムの機能を拡張したい企業です。 または、既存のITインフラストラクチャは現在の負荷に耐えることができません。
ESFプログラムには、トランザクションモデルとテストモデルの組み合わせがあります。 ビジネスオペレーションのピーク負荷の数に関する情報を持っているため、負荷テストから得られた指標にもガイドされます。 しかし、ESFに新しい機能が導入された特殊なケースがあります。これは他のシステムにはないもので、入力として予期されるデータを受け取り、「ユーザーモデル」と同様に動作します。
話しましょう、そしてどのモデルを使用していますか?