-今日は、音声技術の分野における未解決の問題についてお話します。 しかし、まず第一に、音声技術が私たちの生活の不可欠な部分になっていることを理解しましょう。 通りを歩いているときも、車で運転しているときも、検索エンジンに何らかの要求をしたいときは、印刷物などではなく音声で行うのが自然です。
今日は主に音声認識について説明しますが、他にも多くの興味深いタスクがあります。 私のストーリーは3つの部分で構成されます。 はじめに、音声認識の仕組みをおさらいします。 次に、人々がそれを改善しようとする方法と、科学記事では通常遭遇しないYandexが直面するタスクを説明します。
音声認識の一般的なパターン。 最初に、音波が入り口に到着します。

それを小さな断片、フレームに分割しました。 フレーム長は通常25ミリ秒、ステップは10ミリ秒です。 圧倒的です。
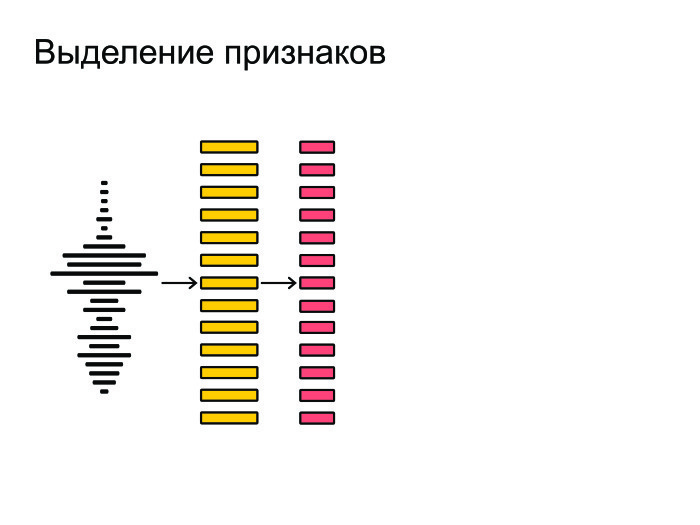
その後、フレームから最も重要な特徴を抽出します。 声や性別の音色は気にしないとしましょう。 最も重要な特徴を抽出するために、これらの要因に関係なく音声を認識したいのです。
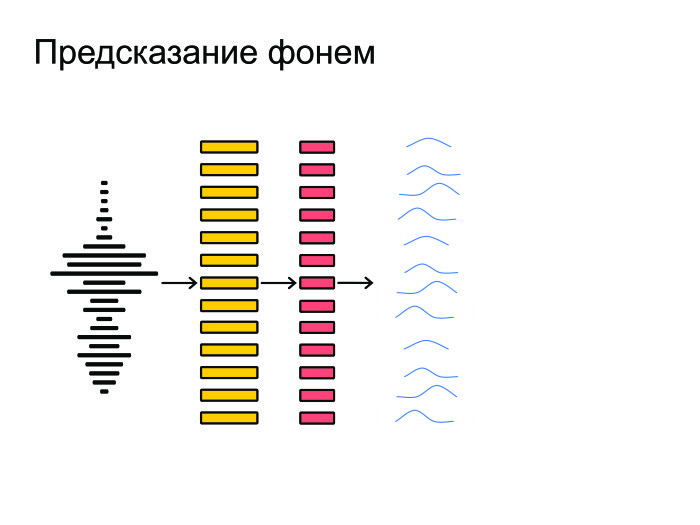
次に、ニューラルネットワークがこれらすべてに対抗し、各フレームの予測、音素ごとの確率分布を提供します。 ニューロンは、どの音素がこのフレームまたはそのフレームで言われたかを推測しようとします。
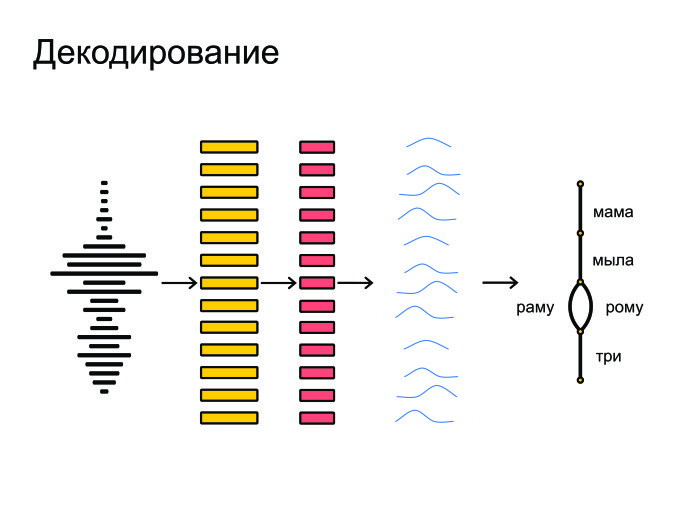
最終的に、これらはすべてグラフデコードに詰め込まれ、グラフデコードは確率分布を受け取り、言語モデルを考慮します。 「ママウォッシュラーマ」と言いましょう。ロシア語では「ママウォッシュローマ」よりも人気のあるフレーズです。 単語の発音も考慮され、最終的な仮説が与えられます。
一般的に、これはまさに音声認識が行うことです。
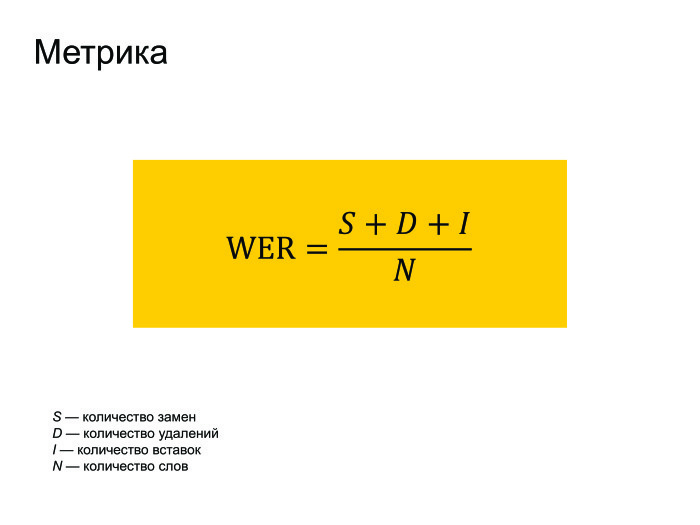
当然、メトリックについていくつかの単語を言う必要があります。 誰もが音声認識でWERメトリックを使用します。 それは世界エラー率として翻訳されます。 これは、レベンシュタインによると、認識されたものから実際にフレーズで話されたものまでの距離を、フレーズで実際に話された単語の数で割ったものです。
挿入が多数ある場合、WERエラーが複数になることがあります。 しかし、誰もこれに注意を払っておらず、誰もがそのようなメトリックを使用しています。

これをどのように改善しますか? 互いに交差する4つの主なアプローチを特定しましたが、これは注意する価値はありません。 主なアプローチは次のとおりです。ニューラルネットワークのアーキテクチャを改善し、損失関数の変更を試みます。最近流行のエンドツーエンドアプローチを使用しないでください。 最後に、たとえばデコードが不要な他のタスクについて説明します。
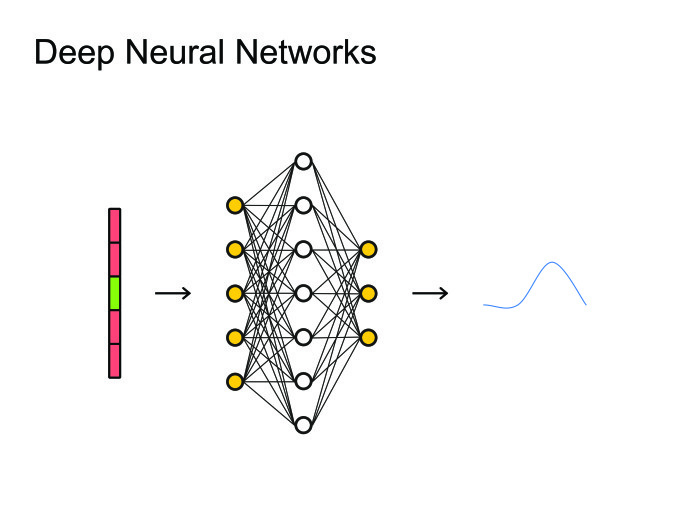
人々がニューラルネットワークを使用するというアイデアを思いついたとき、自然な解決策は最も単純なもの、つまりフィードフォワードニューラルネットワークを使用することでした。 フレーム、コンテキスト、左側のフレーム、右側のフレームを取り上げ、このフレームでどの音素が発声されたかを予測します。 次に、これをすべて画像として見て、画像処理にすでに使用されているすべての大砲、あらゆる種類の畳み込みニューラルネットワークを使用できます。
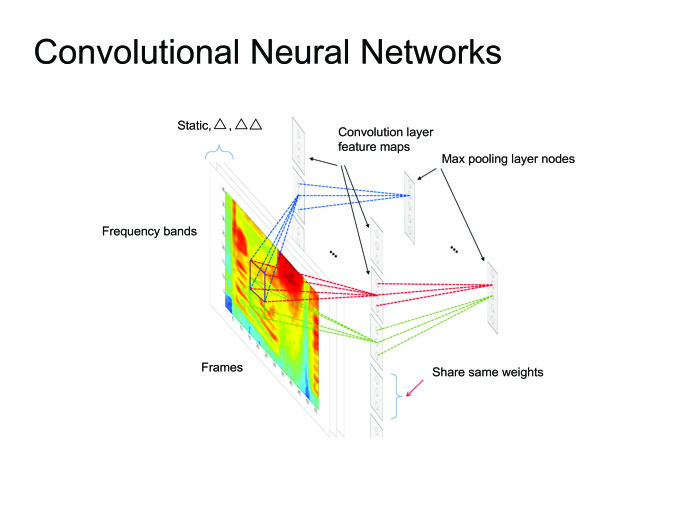
一般に、畳み込みニューラルネットワークを使用して多くの最先端の記事が取得されましたが、今日はリカレントニューラルネットワークについて詳しく説明します。
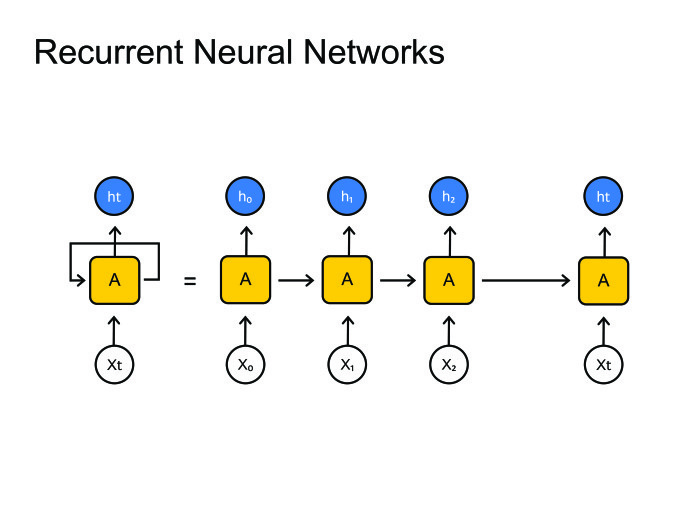
リカレントニューラルネットワーク。 誰もがどのように機能するかを知っています。 しかし、大きな問題が発生します。通常、音素よりもはるかに多くのフレームがあります。 音素ごとに10個または20個のフレームがあります。 どうにかしてこれと戦う必要があります。 通常、これはグラフのデコードに縫い付けられ、多くのステップで同じ状態のままになります。 原則として、あなたは何らかの形でこれと戦うことができます、パラダイムエンコーダーデコーダーがあります。 2つのリカレントニューラルネットワークを作成しましょう.1つはすべての情報をエンコードし、隠された状態を提供し、デコーダーはこの状態を取得して音素、文字、または単語のシーケンスを提供します-これがニューラルネットワークのトレーニング方法です。
通常、音声認識では非常に大きなシーケンスを使用します。 1つの非表示状態でエンコードする必要があるフレームは簡単に1000個あります。 これは非現実的であり、単一のニューラルネットワークでこれを処理することはできません。 他の方法を使用してみましょう。
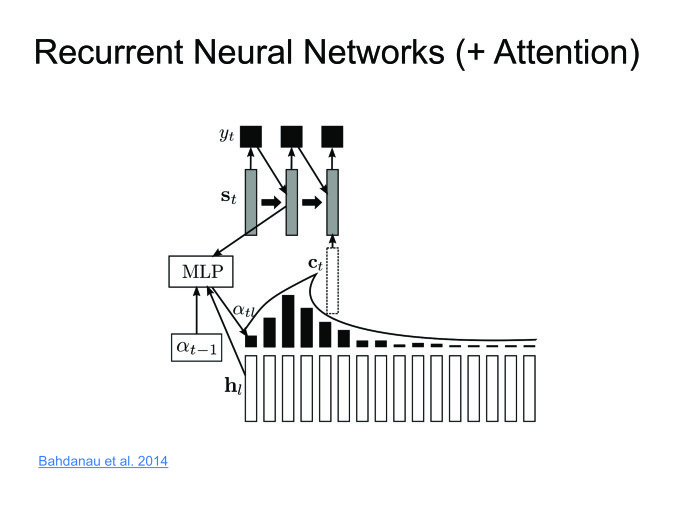
ShADの卒業生であるDima Bogdanovは、Attentionメソッドを発明しました。 エンコーダーに非表示の状態を与えてください。それらを破棄せず、最後の状態のみを残します。 各ステップで加重量を取得します。 デコーダーは、隠された状態の加重和を取ります。 したがって、特定の場合に見ているコンテキスト、コンテキストを維持します。
このアプローチは素晴らしく、うまく機能します。一部のデータセットでは最先端の結果が得られますが、大きなマイナス点が1つあります。 オンラインでスピーチを認識したいのです。ある人が10秒のフレーズを言って、すぐに結果を出しました。 しかし、注意はフレーズ全体を知る必要があり、これは大きな問題です。 その人は10秒間のフレーズを言い、10秒間はそれを認識します。 この時間中に、彼はアプリケーションをアンインストールし、二度とインストールしません。 これと戦う必要があります。 ごく最近、これは記事の1つで戦われました。 私はそれをオンラインの注意と呼びました。
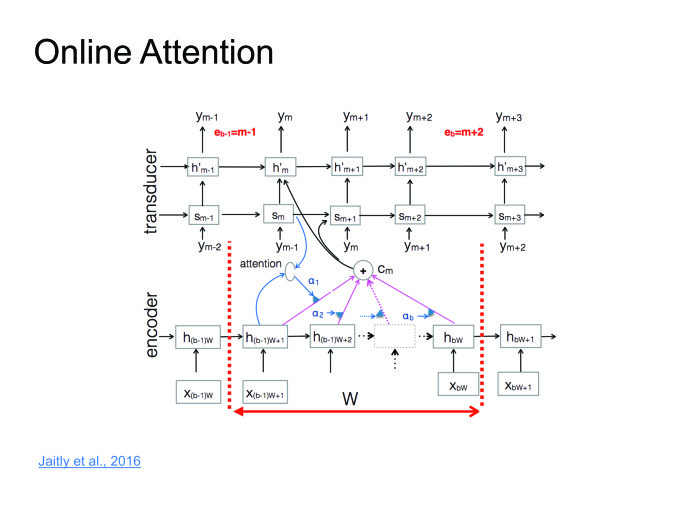
入力シーケンスを小さな固定長のブロックに分割し、各ブロック内にアテンションを配置すると、各ブロックに対応するシンボルを提供するデコーダーがあります。その後、ある時点でブロックの終わりのシンボルを表示し、次のブロックに移動しますここですべての情報を使い果たしました。
ここで一連の講義を読むことができます、私は単純にアイデアを定式化しようとします。

音声認識のためにニューラルネットワークのトレーニングを開始したとき、彼らは音素を推測しようとしました。 このために、通常のクロスエントロピー損失関数が使用されました。 問題は、クロスエントロピーを最適化したとしても、WERを適切に最適化するという意味ではないことです。これらのメトリックは100%の相関関係がないためです。
これを克服するために、シーケンスベースの損失関数が考案されました。すべてのフレームのすべての情報を蓄積し、1つの共通の損失を計算し、勾配をスキップしましょう。 詳細については触れません。CTCまたはSNBRの損失について読むことができます。これは、音声認識の非常に具体的なトピックです。
エンドツーエンドのアプローチには2つの方法があります。 1つは、より多くの「生の」機能を作成することです。 フレームから特徴を抽出した瞬間がありましたが、通常は人の耳をエミュレートしようとして抽出されます。 人の耳をエミュレートするのはなぜですか? どの機能が彼女にとって有用で、どの機能が役に立たないかをニューロンに学習させ、理解させます。 より多くの生の機能をニューロンに提供しましょう。
第二のアプローチ。 ユーザーに言葉、文字表現を提供します。 では、なぜ音素を予測するのですか? それらを予測することは非常に自然ですが、人は文字ではなく音素で話しますが、文字で最終結果を出さなければなりません。 それでは、文字、音節、または文字のペアを予測しましょう。
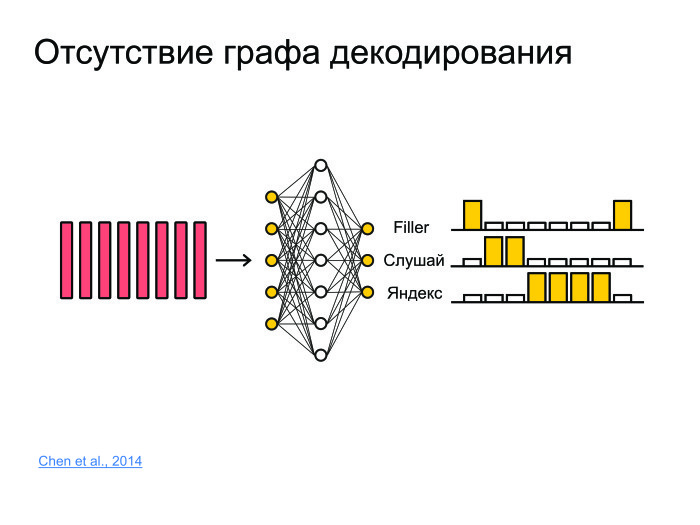
他にどんなタスクがありますか? フレームスポッティングの問題について考えてみましょう。 フレーズ「Listen、Yandex」が言われたかどうかについての情報を抽出する必要がある音があります。 これを行うには、フレーズを認識して「Listen、Yandex」と言うことができますが、これは非常に総当たり的なアプローチであり、通常はサーバーで認識が機能し、モデルは非常に大きくなります。 通常、サウンドはサーバーに送信されて認識され、認識されたフォームが送り返されます。 毎秒10万人のユーザーをロードし、サーバーにサウンドを送信します。1台のサーバーだけでは耐えられません。
小さく、電話で作業でき、バッテリーを消費しないソリューションを考え出す必要があります。 そして良質になるでしょう。
これを行うには、すべてをニューラルネットワークにプッシュしましょう。 彼女は、たとえば、音素や文字ではなく、単語全体を単純に予測します。 そして、3つのクラスを実行しましょう。 ネットワークは「listen」および「Yandex」という単語を予測し、他のすべての単語はフィラーにマッピングされます。
したがって、ある時点で最初に「聞く」確率が高く、次に「Yandex」の確率が高い場合、高い確率で「Listen、Yandex」というキーフレーズがありました。

記事ではあまり取り上げられていない問題。 通常、記事が作成されると、何らかのデータセットが取得され、そのデータセットで良好な結果が得られます。最新のビート-乾杯、記事を印刷します。 このアプローチの問題は、多くのデータセットが10年、または20年も変わらないことです。 そして、彼らは私たちが直面している問題に直面していません。
時々トレンドがあるので、私は認識したいのですが、この単語が標準的なアプローチのデコードグラフにない場合は、認識できません。 これと戦う必要があります。 デコードグラフを取得してダイジェストできますが、これは面倒なプロセスです。 たぶん朝にはいくつかの流行の言葉があり、夕方には他の言葉があります。 朝夕のカウントを維持しますか? これは非常に奇妙です。

簡単なアプローチが考案されました。小さなデコードグラフを大きなデコードグラフに追加します。これは、数千の最良のトレンドフレーズから5分ごとに再作成されます。 これら2つのグラフに沿って並行してデコードし、最適な仮説を選択します。
残ったタスクは何ですか? 彼らは最新技術を打ち負かし、問題を解決しました...ここ数年のWERグラフを提供します。
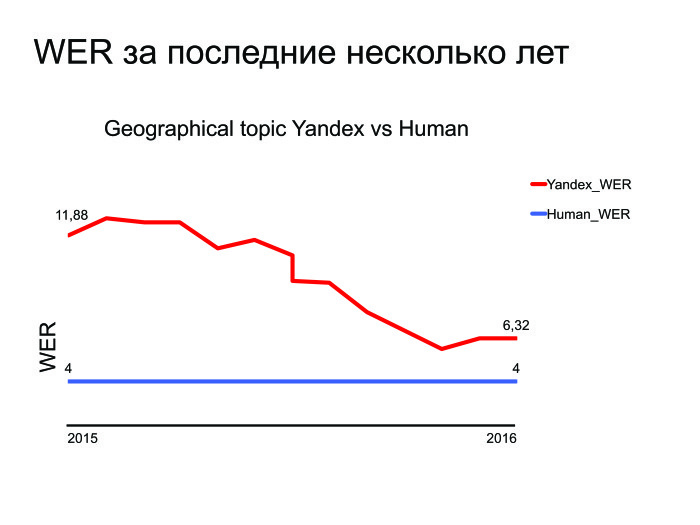
ご覧のとおり、Yandexは過去数年で改善されており、ここに最適なトピック(地理検索)のグラフがあります。 私たちが試み、改善していることは理解できますが、解消する必要がある小さなギャップがあります。 そして、人間の能力と比較して音声認識を行う場合でも、それを行う場合でも、別のタスクが発生します。それはサーバー上で行われましたが、それをデバイスに転送しましょう。 これは、別個の複雑で興味深いタスクです。
また、私が質問できる他の多くのタスクがあります。 ご清聴ありがとうございました。