1.マルチマスタークラスター
Postgres Pro Enterpriseバージョンでのみ使用可能な
multimaster
拡張機能とカーネルでのそのサポートにより、高可用性サーバーのクラスターを構築できます。 各トランザクションの後、グローバルな整合性(クラスター全体のデータ整合性)が保証されます。 各ノードでデータは同一になります。 同時に、ノード数の増加に伴って読み取りパフォーマンスが直線的にスケーリングすることを簡単に実現できます。
バニラPostgreSQLでは、ストリーミングレプリケーションを使用してアクセスしやすいクラスターを構築できますが、障害が発生したノードを特定し、障害後にノードを復元するには、サードパーティのユーティリティと独創的なスクリプトが必要です。
multimaster
は独自にこれを行い、外部ユーティリティやサービスを使用せずにそのまま動作します。
バニラ
PostgreSQL
読み取りスケーリングは、ホットスタンバイモードでのレプリケーションで
PostgreSQL
可能ですが、重要な注意事項があります。アプリケーションは、
read-write
read-only
クエリと
read-write
クエリを分離できる必要があります。 つまり、バニラクラスタで作業するには、アプリケーションを書き直す必要があります。可能であれば、読み取り専用トランザクション用にデータベースへの個別の接続を使用し、これらの接続をすべてのノードに分散します。
multimaster
備えたクラスターの場合、任意のノードに書き込むことができるため、データベース接続を書き込み接続と読み取り接続のみに分割しても問題はありません。 ほとんどの場合、アプリケーションを書き換える必要はありません。
フォールトトレランスを確保するには、アプリケーションが
reconnect
できる必要があります。 違反が発生した場合、データベースとの接続を復元しようとします。 これは、バニラクラスタと
multimaster
両方に適用されます。
バニラ
PostgreSQL
論理レプリケーションを使用すると、非同期の双方向レプリケーション(たとえば、 2ndQuadrantの
BDR
)を実装できますが、これはグローバルな整合性を提供せず、競合を解決する必要があり、これは内部ロジックに基づいてアプリケーションレベルでのみ実行できます。 つまり、これらの問題はアプリケーションプログラマに渡されます。
multimaster
自体がトランザクション分離を提供します(
Repeatable Read
および
Read Committed
トランザクション分離レベルが実装されました。トランザクションのコミット中、すべてのレプリカは一貫性があり、ユーザーアプリケーションは同じ状態になります。ベースは、彼取引を開始、あなたがそれを行うと、ノードに障害が発生した場合に予測可能な応答時間を得るために要求している車の種類を知る必要はありません、我々は、3フェーズ・コミット・トランザクション(3相,.実施している
commit protocol
それはあります)。 メカニズムは、より多くのように、私たちはその仕組みを説明させて、よりよく知られた2相よりも複雑になっている。簡単にするために、二つのノード、ノード2と同様、実際に一般のノードの偶数を動作することを念頭に置いてベアリングを示しています。

図 1.作業計画マルチマスター
トランザクションコミット要求がノード1に到着し、ノードWALに記録されます。 クラスターの残りのノード(図のノード2)は、論理レプリケーションプロトコルを使用してデータ変更に関する情報を受け取り、トランザクションコミットを準備する要求を受け取ると、変更を適用します(コミットなし)。 その後、トランザクションを開始したノードに、トランザクションをコミットする準備ができたことを通知します(
transaction prepared
)。 少なくとも1つのノードが応答していない場合、トランザクションはロールバックされます。 すべてのノード
precommit
肯定的に
precommit
場合、ノード1は、トランザクションをコミットできるというメッセージをノードに送信します(トランザクションの
precommit
コミット)。
これは、2フェーズトランザクションとの違いです。 このアクションは一見余分に見えるかもしれませんが、実際にはこれは重要なフェーズです。 2フェーズトランザクションの場合、ノードはトランザクションを記録し、トランザクションを開始した最初のノードに報告します。 この時点で接続が切断された場合、ノード2でのトランザクションの成功/失敗について何も知らないノード1は、整合性を維持するために何をすべきかが明らかになるまで回答を待つ必要があります:トランザクションをロールバックまたはコミット(またはコミット)リスクを伴います)。 したがって、3フェーズスキームでは、2番目のフェーズで、すべてのノードが投票します:トランザクションをコミットするかどうか。 ほとんどのノードがコミットの準備ができている場合、アービターはトランザクションがコミットされたことをすべてのノードに通知します。 ノード1は、トランザクションを
commit
し、論理レプリケーション
commit
介して
commit
を送信し、トランザクションコミットタイムスタンプを報告します(すべてのノードが読み取り要求のトランザクション分離を維持する必要があります。将来、タイムスタンプは
CSN
トランザクションコミット識別子、
Commit Sequence Number
置き換えられます)。 ノードが少数である場合、書き込みも読み取りもできません。 接続が切断されても、整合性の違反は発生しません。
将来的に
multimaster
アーキテクチャを選択しました。効率的なシャーディングの開発に取り組んでいます。 テーブルが分散されると(つまり、ノード上のデータが既に異なる場合)、クラスターのすべてのノードにすべてのデータを並行して書き込む必要がないため、読み取りだけでなく書き込みによってもスケーリングすることが可能になります。 さらに、ノードが他のノードのメモリと直接通信する場合、
RDMA
プロトコルを使用して(
InfiniBand
スイッチまたは
RDMA
サポートされている
Ethernet
デバイスで)ノード間の通信手段を開発し
Ethernet
。 このため、ネットワークパケットのパッキングとアンパッキングに費やされる時間が短くなり、データ送信の遅延が小さくなります。 変更を同期するときにノードは集中的に通信するため、これによりクラスター全体のパフォーマンスが向上します。
2. 64ビットトランザクションカウンター
DBMSカーネルのこの基本的な変更は、負荷の高いシステムにのみ必要ですが、それらにとっては望ましいことではありません。 彼女が必要です。
PostgreSQL
カーネルには32ビットのトランザクションカウンターがあります。つまり、40億を超えてカウントすることはできません。 これは、「フリーズ」
VACUUM FREEZE
特別な定期メンテナンス手順によって解決される問題につながります。 ただし、カウンターが頻繁にオーバーフローすると、この手順のコストが非常に高くなり、データベースに何かを書き込むことができなくなる可能性さえあります。 ロシアでは現在、1日にオーバーフローが発生する企業システムはそれほど多くないため、毎週の間隔でオーバーフローするベースはもはや珍しくありません。 オタワで開催されたPGCon 2017開発者会議で、2〜3時間でメーターのオーバーフローが発生した顧客もいると述べました。 今日、人々は以前に捨てられたデータをデータベースに入れる傾向があり、当時のテクノロジーの限られた機能を理解して処理していました。 現代のビジネスでは、分析に必要なデータが事前にわからないことがよくあります。
カウンターオーバーフローの問題は、トランザクション番号のスペースがループするため(
transaction ID wraparound
)と呼ばれ
transaction ID wraparound
(これについては、 Dmitry Vasilievの 記事で明確に説明されています )。 オーバーフローすると、カウンターはゼロにリセットされ、次のラウンドに進みます。
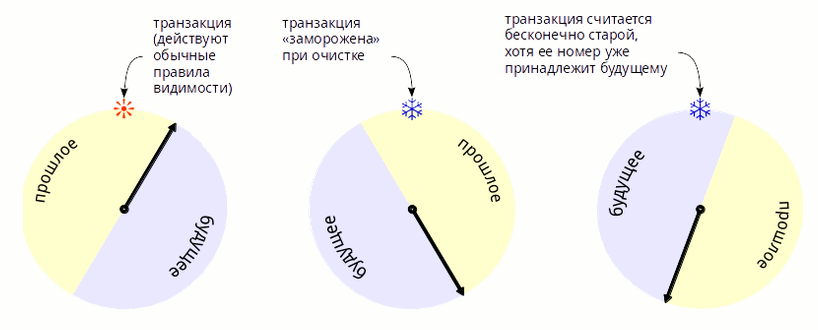
図2.トランザクションのフリーズが半円以上遅れる方法。
通常の
PostgreSQL
(つまり、既知の32ビットトランザクションカウンター)では、トランザクションラップアラウンドの問題を軽減するために何かが行われます。 これを行うために、バージョン9.6では、
all-frozen
ビットが
(visibility map)
形式に追加され、ページ全体がフリーズとしてマークされるため、スケジュールされた(多くの古いトランザクションが蓄積する)および緊急(オーバーフローが近づくと)フリーズがはるかに速くなります。 残りのページでは、DBMSは通常どおり動作します。 このため、オーバーフロー処理中のシステム全体のパフォーマンスは低下しませんが、問題は原則として解決されていません。 説明されているシステムのシャットダウンの状況は、その可能性は減少しましたが、まだ除外されていません。 それでも、
VACUUM FREEZE
の設定を注意深く監視して、その操作による予期しないパフォーマンスの低下がないようにする必要があります。
32ビットカウンターを64ビットカウンターに置き換えると、オーバーフローはほぼ無限になります。
VACUUM FREEZE
の必要性は実質的になくなります(現在のバージョンでは、以下に説明する緊急の場合に
pg_clog
と
pg_multixact
を処理するために凍結が使用されます)。 しかし、仕事は額で解決されません。 テーブルにフィールドがほとんどない場合、特にこれらのフィールドが整数である場合、そのボリュームは大幅に増加する可能性があります(各レコードには、レコードを生成したトランザクション番号とこのバージョンのレコードを削除したトランザクション番号が含まれており、各番号は4ではなく8バイトで構成されているため)。 開発者は32ビットを追加しただけではありません。
Postgres Pro Enterprise
上位4バイトはレコードに含まれず、「時代」、つまりデータページレベルでの
(offset)
を表します。 元号は、テーブルエントリの通常の32ビットトランザクション番号に追加されます。 そして、テーブルは膨張しません。
システムがページの時代によって定義された範囲に収まらない
XID
を書き込もうとする場合、シフトを増やすか、ページ全体をフリーズする必要があります。 しかし、これはメモリ内で簡単に実行されます。
(snapshots)
がまだ要求できる最小の
XID
が、このページに書き込みたい
XID
よりも2 32以上遅れている場合には制限があります。 しかし、これはほとんどありません。 さらに、近い将来、この制限を克服する可能性があります。
32ビットカウンターのもう1つの問題は、オーバーフロー処理が非常に複雑なプロセスであることです。 バージョン9.5までは、対応するコードで非常に重大なバグが検出および修正され、将来のバージョンでバグが表示されないという保証はありません。 64ビットトランザクションカウンターの実装には、シンプルで明確なロジックがあるため、オーバーフローと戦うよりも、それを操作してさらに開発する方が簡単です。
64ビットカウンターを備えたシステムのデータファイルは32ビットカウンターとバイナリ互換ではありませんが、データを変換するための便利なユーティリティがあります。
3.ページネーション
PostgreSQLでは、他のほとんどのDBMSとは異なり、
(page level compression)
はありません。
TOAST
データのみが圧縮されます。 データベースに比較的小さなテキストフィールドを持つレコードが多数ある場合、圧縮によりデータベースのサイズが数倍小さくなり、ディスクに保存するだけでなく、DBMSのパフォーマンスも向上します。 ディスクから大量のデータを読み取り、あまり変更しない分析クエリは、I / O操作を減らすことで特に効率的に加速できます。
Postgres
コミュニティは、圧縮の圧縮サポートを備えたファイルシステムの使用を提案しています。 しかし、これは常に便利で可能とは限りません。 そのため、
Postgres Pro Enterprise
、ページング圧縮の独自の実装を追加しました。 さまざまな
Postgres Pro
ユーザーのテスト結果によると、データベースサイズは2倍から5倍に減少しました。
実装では、ページはディスクに圧縮されて保存されますが、バッファに読み込まれると展開されます。したがって、RAMでのページの操作は通常とまったく同じです。 圧縮データの展開とその圧縮は迅速に行われ、実際にはプロセッサの負荷は増加しません。
ページの圧縮中に変更されるデータの量は増加する可能性があるため、常に元の場所に戻すことはできません。 圧縮されたページをファイルの最後に書き込みます。 ディスクにページを順番に書き込むと、システム全体のパフォーマンスが大幅に向上します。 これには、論理アドレスを物理アドレスにマップするファイルが必要ですが、このファイルは小さく、オーバーヘッドは見えません。
順次記録中のファイル自体のサイズは増加します。 規則に従って、または手動でガベージコレクションを起動することにより、空でないページをすべてファイルの先頭に移動することにより、定期的にファイルをよりコンパクトにする(デフラグする)ことができます。 バックグラウンドでガベージを収集できます(セグメントはブロックされますが、テーブル全体ではありません)。また、ガベージを収集するバックグラウンドプロセスの数を設定できます。
| 圧縮(アルゴリズム) | サイズ(GB) | 時間(秒) |
|---|---|---|
| 圧縮なし | 15.31 | 92 |
| スナッピー | 5.18 | 99 |
| lz4 | 4.12 | 91 |
| postgres内部lz | 3.89 | 214 |
| lzfse | 2.80 | 1099 |
| zlib(最高速度) | 2.43 | 191 |
| zlib(デフォルトレベル) | 2.37 | 284 |
| zstd | 1.69 | 125 |
圧縮には、最新のzstdアルゴリズムを選択しました( Facebookで開発されました )。 さまざまな圧縮アルゴリズムを試し、
zstd
で解決し
zstd
。これは、表からわかるように、品質と圧縮速度の最適な妥協点です。
4.オフライントランザクション
技術的には、自律型トランザクションの本質は、親のコミット/ロールバックに関係なく、メインの親トランザクションから作成されたこのトランザクションをコミットまたはロールバックできることです。 自律型トランザクションは、独自のコンテキストで実行されます。 自律ではなく、別の内部の通常のトランザクション(ネストされたトランザクション)を定義する場合、親トランザクションがロールバックされると、内部トランザクションが常にロールバックされます。 この動作は、アプリケーション開発者に常に適しているとは限りません。
自律型トランザクションは、アクションのログ記録または監査が必要な場合によく使用されます。 たとえば、トランザクションがロールバックされる状況で、ログで何らかのアクションを実行しようとする試みの記録が必要です。 自律型トランザクションを使用すると、従業員の「機密」アクション(顧客アカウントの表示または変更)によって、緊急時に画像を復元するために使用できるトレースを常に残すことができます(このトピックの例を以下に示します)。
Oracle
や
DB2
などのDBMS(
MS SQL
はありません)では、自律型トランザクションは正式にトランザクションとして定義されるのではなく、プロシージャ、関数、トリガー、および名前のないブロック内の自律型ブロックとして定義されます。
SAP HANA
には自律型トランザクションもあり
SAP HANA
が、機能ブロックだけでなく、トランザクションとして定義することもできます。
たとえば、
Oracle
では、自律型トランザクションはブロックの先頭で
PRAGMA AUTONOMOUS_TRANSACTION
として定義されます。 プロシージャ、関数、または名前のないブロックの動作は、コンパイルの段階で決定され、実行中に変更することはできません。
PostgreSQL
はオフライントランザクションがまったくありません。 これらは、dblinkを使用して新しい接続を起動することでシミュレートできますが、これはオーバーヘッドに変換され、パフォーマンスに影響を及ぼし、単に不便です。 最近、
pg_background
モジュールの登場後、バックグラウンドプロセスを開始して自律型トランザクションをシミュレートすることが提案されました。 しかし、これは無効であることが判明しました(テスト結果を分析するとき、以下の理由に戻ります)。
Postgres Pro Enterpriseでは、
自律型トランザクションを実装しました。 これで、ネストされた自律型トランザクションとしても機能内でも使用できます。
ネストされた自律型トランザクションでは、親トランザクションのレベルに関係なく、使用可能なすべての
PostgreSQL
分離レベル(読み取りコミット、繰り返し読み取り、シリアル化可能)を定義できます。 例:
BEGIN TRANSACTION
<..>
BEGIN AUTONOMOUS TRANSACTION ISOLATION LEVEL REPEATABLE READ
<..>
END ;
END ;
可能なすべての組み合わせが機能し、開発者に必要な柔軟性を与えます。 自律型トランザクションは、まだコミットされていないため、親のアクションの結果を見ることはありません。 反対は、メインの分離レベルに依存します。 ただし、独立して開始されたトランザクションとの関係では、通常の分離ルールが適用されます。
関数の構文はわずかに異なります:
TRANSACTION
キーワードはエラーをスローします。 関数内の自律ユニットは、次のように定義されます。
CREATE FUNCTION <..> AS
BEGIN ;
<..>
BEGIN AUTONOMOUS
<..>
END ;
END ;
したがって、分離レベルは設定できず、親トランザクションのレベルによって決定され、明示的に設定されていない場合はデフォルトで設定されます。
世界の古典的な商用DBMSの1つと考えられる例を示します。 一部の銀行では、customer_infoテーブルに顧客データと負債が保存されています
CREATE TABLE customer_info (acc_id int , acc_debt int );
INSERT INTO customer_info VALUES (1, 1000),(2, 2000);
このテーブルに銀行員が直接アクセスできないようにします。 ただし、利用可能な機能を使用して顧客の債務をチェックすることができます。
CREATE OR REPLACE FUNCTION get_debt (cust_acc_id int ) RETURNS int AS
$$
DECLARE
debt int ;
BEGIN
PERFORM log_query( CURRENT_USER :: text , cust_acc_id, now());
SELECT acc_debt FROM customer_info WHERE acc_id = cust_acc_id INTO debt;
RETURN debt;
END ;
$$ LANGUAGE plpgsql;
クライアントデータをスパイする前に、関数はDBMSユーザー名、クライアントアカウント番号、および操作時間をログテーブルに書き込みます。
CREATE TABLE log_sensitive_reads (bank_emp_name text , cust_acc_id int , query_time timestamptz);
CREATE OR REPLACE FUNCTION log_query (bank_usr text , cust_acc_id int , query_time timestamptz ) RETURNS void AS
$$
BEGIN
INSERT INTO log_sensitive_reads VALUES (bank_usr, cust_acc_id, query_time);
END ;
$$ LANGUAGE plpgsql;
従業員にクライアントの借金について問い合わせることができるようにしたいのですが、怠idleなまたは悪意のある好奇心を助長しないために、常にログで彼の活動の痕跡を見たいと思います。
好奇心employee盛な従業員がコマンドを実行します。
BEGIN ;
SELECT get_debt (1);
ROLLBACK ;
この場合、そのアクティビティに関する情報は、トランザクション全体のロールバックとともにロールバックされます。 これは私たちには合わないので、ロギング機能を変更します。
CREATE OR REPLACE FUNCTION
log_query (bank_usr text , cust_acc_id int , query_time timestamptz ) RETURNS void AS
$$
BEGIN
BEGIN AUTONOMOUS
INSERT INTO log_sensitive_reads VALUES (bank_usr, cust_acc_id, query_time);
END ;
END ;
$$ LANGUAGE plpgsql;
これで、従業員がどのようにトラックを隠そうとしても、顧客データのすべてのビューが記録されます。
オフライントランザクションは、最も便利なデバッグツールです。 疑わしいコードには、失敗したトランザクションがロールバックする前にデバッグメッセージを書き込む時間があります。
BEGIN AUTONOMOUS
INSERT INTO test (msg) VALUES ( 'STILL in DO cycle. after pg_background call: ' ||clock_timestamp():: text );
END ;
パフォーマンスについての結論。 自律トランザクションの実装を、自律トランザクションのない同じSQLと、
dblink
を
pgbouncer
と接続制御と組み合わせた裸の
dblink
したソリューションと比較してテストしました。
pg_background
は3つの関数を作成し
pg_background_launch(query)
は、
background worker
バックグラウンドプロセスを開始し、渡されたSQL関数を実行します。
pg_background_result(pid)
は
pg_background_launch(query)
によって作成されたプロセスから結果を取得し、
pg_background_detach(pid)
はバックグラウンドプロセスを作成者から切断します。 トランザクションを実行するコードは直観的ではありません。
PERFORM * FROM pg_background_result(pg_background_launch (query))
AS (result text );
しかし、より重要なことは、予想どおり、各SQLのプロセスの作成が遅いことです。 pg_backgroundの作成履歴から、4番目の関数
pg_background_run(pid, query)
想定
pg_background_run(pid, query)
れていたこと
pg_background_run(pid, query)
。これは、新しいタスクを既に実行中のプロセスに転送します。 この場合、プロセスを作成するための時間はすべてのSQLに費やされるわけではありませんが、この関数は現在の実装では使用できません。
pg_background
の最初のバージョンを作成したRobert Haasは次の
pg_background
に述べています。
「私はこのアプローチに懐疑的です(
pg_background]
を使用して自律型トランザクションをシミュレートする
pg_background]
。 , , ,
[backend]
,
[background_workers]
.
[max_worker_processes]
, , , , , , , ».
: , , , . , ,
pg_background
6-7 ,
Postgres Pro Enterprise
.
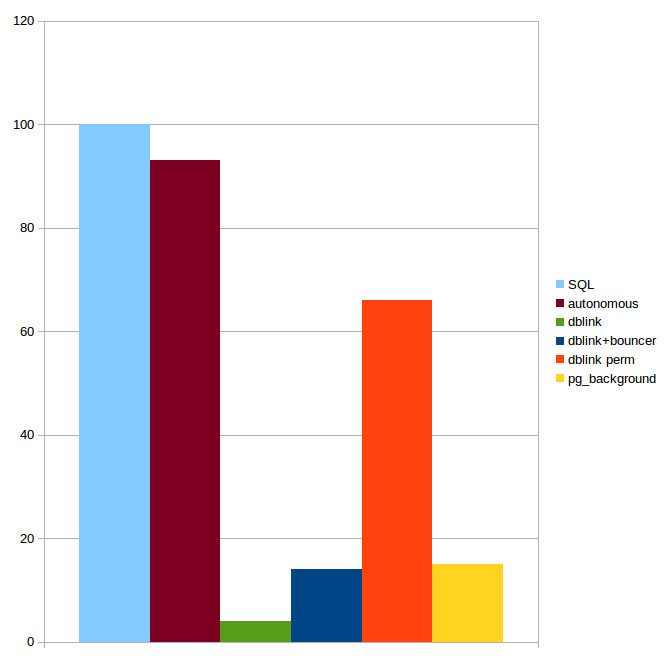
図 3. . pgbech
INSERT
pgbench_history
. 10. TPS «» SQL 100.
PS。 !
PPS. !