
最近kaggle.comで、宇宙競争からアマゾンを理解する惑星がありました
それ以前は、画像認識を扱っていなかったため、写真の操作方法を学ぶ絶好の機会だと思いました。 さらに、チャットルームの人々の保証によると、エントリのしきい値は非常に低く、誰かがデータセットを「MNIST on steroids」とも呼びました。
挑戦する
実際、各競争の始まりは問題の声明と品質指標です。 タスクは次のとおりでした:写真はアマゾン地域の衛星から撮影され、各写真にはラベルを貼る必要がありました:道路、川、野原、森林、雲、晴天など(合計17個)。 さらに、同じ絵の中にいくつかのクラスがあります。 ご覧のとおり、地形のタイプに加えて、気象条件に関連するクラスもありました。そして、論理的には、写真の天気は1つだけになります。 まあ、それは明確でも曇りでもありえません。 競争を決定するとき、私は目でデータを見ませんでした、マシン自体が兄弟が誰であるかを理解することを望んでいたので、私は画像の例を与えるためにさまよう必要がありました:

ベースライン
そのような問題を解決する方法は? 大きなデータセットでトレーニングされた畳み込みニューラルネットワークを使用して、写真セットの重みを再トレーニングします。 理論的にはもちろん、私はこれを聞いたが、ここではすべてが明らかであるように見えるが、私の手が届くまでそれを取り込んで実装するようだ。 まず、作業のフレームワークを選択する必要があります。 非常に優れたドキュメントと明確な人間のコードがあるので、私は簡単な道をたどってkerasを使用しました。
スケールのさらなるトレーニングの手順についてもう少し説明します(業界ではこれをFine-tuneと呼びます )。 数百万の写真で構成されるImageNetデータセットでトレーニングされたVGG16などの畳み込みニューラルネットワークを使用して、1000のクラスの1つを予測します。 まあ、彼女は猫、犬、車を予測しているので、何ですか? 私たちのクラスは完全に異なります...しかし、ポイントは、ニューラルネットワークの下位層がすでに画像の基本的なコンポーネントを線と勾配として認識できることです。 残っているのは、1000個のニューロンの最上層を削除し、代わりに17個のニューロンを独自に配置することです(多くのクラスが衛星画像に含まれるのと同じように)。
したがって、ニューラルネットワークは17のクラスのそれぞれの確率を予測します。 写真に特定のクラスがある場合、どのように言えますか? 最も単純なアイデアは、単一のしきい値でカットオフすることです。たとえば、確率が0.2より大きい場合はクラスを含め、そうでない場合は含めません。 クラスごとにこのしきい値を個別に選択することができます。また、チャットで呼び出されたときに、 しきい値をソートするために、独立したものよりも賢いものは思いつきませんでした(もちろん、1つのしきい値を改善すると別の選択に影響する可能性があります)。
すぐに言ってやった。 結果は、 トップ90%のリーダーボードです。 はい、悪いですが、どこかから始めなければなりません。 そして、ここで私は競争の大きな利点について言いたいと思います-多くの人々、専門家であり、それほど多くはない人が1つの問題に取り組んでおり、既製のベースラインさえ公開されています。 議論から、ファイルが正しくないことにすぐに気付きました。 実際には、次の2段階で体重をトレーニングする必要があります。
- 最後の(17個のニューロンの)層を除くすべての層の重みを「フリーズ」し、彼だけを訓練する
- 損失が特定の値まで低下し、さらに変動した後、すべての重みを「フリーズ解除」し、グリッド全体をトレーニングします
私の意見では、これらの簡単な操作の後、少なくとも許容できる品質が得られました。 次に何をする?
増強
データセットを充実させるために、増強を行うことができると聞いた-ニューラルネットワークの入力に供給される画像のいくつかの変換。 まあ、本当に、写真を回転させると、川やそこからの道はどこにも行かないでしょうが、今では訓練のために1枚ではなく2枚があります。 私はあまり賢くないことに決め、90度の倍数である角度でのみ写真を回し、それらを映しました。 したがって、トレーニングデータセットのサイズは8倍に増加し、品質にすぐに影響しました。

それから私は、なぜ同じことをしないのかと考えましたが、予測フェーズでは、変換された画像と平均のネットワーク出力を取得しますか? そのため、予測はより安定するようです。 私はそれを実装しようとしました、私はすでに写真を回転させる方法を学びました。 予想外ですが、それは本当に機能しました。同じネットワークアーキテクチャで、リーダーボードの100行を登りました。 後になって、チャットからすべてがすでに私の前に発明されており、この技術はテスト時間拡張と呼ばれていることを知りました。
アンサンブル1
最近、競争に勝つためには「xgboostをスタックする」だけでよいという意見があります。 はい、アンサンブルを構築しなければ、トップに到達することはできませんが、適切な物理的エンジニアリングがなければ、有能な検証がなければ、結果は得られません。 したがって、アンサンブルを進める前に、かなりの量の作業を行う必要があります。
画像認識問題ではどのモデルを組み合わせることができますか? 明らかなアイデアは、畳み込みニューラルネットワークのさまざまなアーキテクチャです。 この記事でそれらのトポロジーについて読むことができます。
私は次を使用しました:
- VGG16
- VGG19
- Resnet101
- Resnet152
- Inception_v3
アンサンブルの方法は? まず、すべてのネットワークの予測を取得して平均化できます。 それらがあまり相関せず、ほぼ同じ品質を提供する場合、私の経験では、平均化はほぼ常に機能します。 今はうまくいった。
チーム
少なくとも、私は銅メダルの境界に到達しました。 一方、競争の終わりまで一週間が残った。 この時点で、いわゆるマージ期限が来ます。チーム化が禁止された直後です。 それで、締め切りの20分前に、実際に誰かとチームを組まないのではないかと思います。 私はリーダーボードを見て、近くのチャットから誰かを見つけたいと思っています。 しかし、誰もオンラインではありません。 asanakoyのみ。当時は私より40行も高かった。 何、どう? まあ、私は書いた。 deadline'aに2分のまま-私は、さらに何かをする準備ができている場合、アサナコイは団結を気にしないという答えを得る。 Artyom Sanakoevは、コンピュータビジョンの博士課程の学生であり、コンテストで既存の勝利を収めたことが判明しました。もちろん、私は喜んでいます。 チームワークは、Kaggleコンテストに参加する上で大きなプラスです 。なぜなら、私のような初心者は、問題の共同解決中に、経験豊富な同僚から新しいことを直接学ぶことができるからです。 参加してみてください。少なくとも小さな成功と何かをしたいという強い願望があるなら、あなたは確かにチームに連れて行かれ、彼らはすべてを教え、誰もが見せます。 まあ、合併後に最初に欲しいのは、あなたの決定を組み合わせることで即座に後押しを得ることです。 同時に30行を登りましたが、これは最小限の労力で行われたことを考えると、非常に良いことでした。 Artyomのおかげで、ネットワークのトレーニングが大幅に不足していることに気付きました。ゴミ箱に入っている彼のモデルの1つが、品質をすべて兼ね備えていました。 しかし、彼のチームメイトのアドバイスの助けを借りてすべてを修正する時間がまだありました。
アンサンブル2
そのため、コンテストの終了まで数日が残っていたため、ArtyomはCVPR会議に向けて出発しました。私は、さまざまなグリッドの予測をまとめて座っていました。 平均化は確かに優れていますが、スタッキングなどの高度な技術があります。 次のアイデアは、トレーニングセットをたとえば5つの部分に分割し、そのうち4つでモデルをトレーニングし、5番目に予測し、
そして、5つすべてのフォールドに対してそれを行います。 説明図:
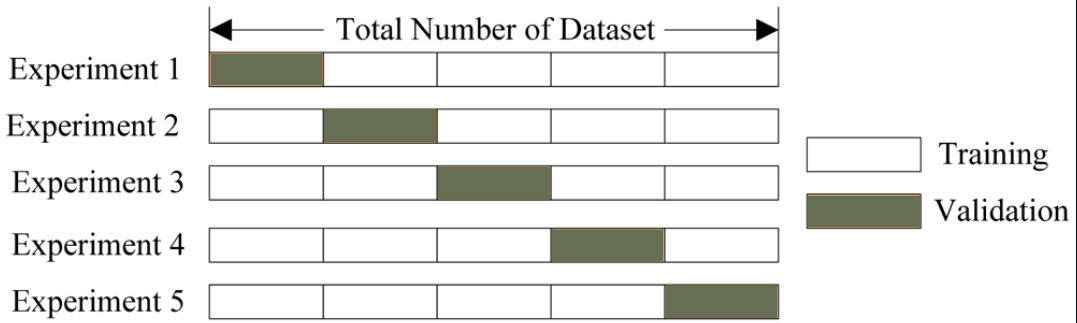
スタックの詳細については、競争の例については、 こちらをご覧ください 。
これをタスクに適用する方法:17のクラス(合計6つのネットワーク* 17のクラス= 102の認識)ごとに各ネットワークの確率の予測があります。 これが新しいトレーニングセットになります。 結果のテーブルで、各クラスのバイナリ分類器(合計17の分類器)をトレーニングしました。 その結果、各ショットにラベルの確率がありました。 それらに加えて、以前に使用した欲張りアルゴリズムを適用できます。 しかし、驚いたことに、積み重ねは単純な平均化よりも性能が劣っていました。 私にとっては、トレーニングセットをフォールドに分割したさまざまな内訳があることでこれを説明しました-Artyomは5フォールドを使用し、4フォールドしか使用しませんでした(フォールドが多いほど、より多くのトレーニングモデルを費やす必要があります)。 その後、ニューラルネットワークの予測のみでスタッキングを行い、Artyomの予測と結果の加重合計を取ることにしました。 使用された第2レベルのモデルは、lightgbm、xgboost、および3層パーセプトロンで、その後、それらの出力が平均化されました。
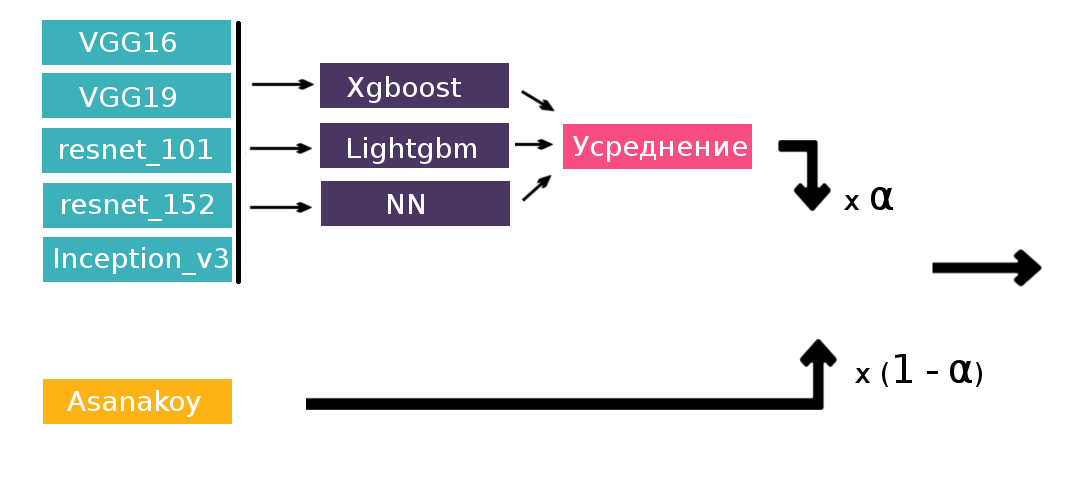
そして、ここでのスタックは本当にうまくいきました。リーダーボードでは、自信を持って銀メダルを獲得しました。 アイデアも時間もほとんどなかったので、最後の4つのニューロンとソフトマックスの活性化で、気象条件のみを予測する別のニューラルネットワークをスタッキングに追加することにしました。 より狭い問題が知られている場合、それを使用しないのはなぜですか? これにより改善されましたが、非常に強力であるとは言えません。
まとめ
それにもかかわらず、結果として、私たちはほぼ1000人中17位であり、ディープラーニングの最初の競争にとっては非常に良いようです。 金メダルは11位から始まり、私たちは本当に近いことを実感しました。ソリューションはおそらく実装の詳細が異なるだけで、トップのソリューションとは異なります。
他にできること
- フォーラムで、Densenetアーキテクチャは非常に良い結果を示していると多くの人が書きまし
たが、経験不足のために曲がったため、接続できませんでした。 - シングルフォールドを作成しますが、それ以上(チャットでは10フォールドを行うと書いています)
- 天気を予測するために、1つのモデルではなく、複数のモデルを使用することができました
結論として、レスポンシブチャットコミュニティods.aiに感謝します。ここでは、いつでもアドバイスを求めることができ、ほとんどの場合に役立ちます。 さらに、2つのチャットチームがそれぞれ3位と7位になりました。