
グレン・ジョーンズ
多くの小売業者は、バックエンドでサイトをホストしています。 データは自宅にあるため、このアプローチは便利です。また、小売ネットワークや他の大企業について話している場合、リンク、食物、ストリーミングアンチウイルスがあります。 大規模なデータセンターのサイトに移動すると、そのサイトはすべてのインフラストラクチャとともに転送されます。 そして私は、これらすべてがスムーズに機能するように答える人です。 今日は、サイトの成長の問題と、サービスプロバイダーがそれらをどのように見ているかについてお話したいと思います。 主に仮想インフラストラクチャに焦点を当てることを予約してください。
Webプロジェクトと成長の問題
サイト。 スタート。 原則として、Webプロジェクトは、小さい場合、その下に1つのサーバーがあり、一度にすべてを担当します。 時には複数のサイトをホストします。
すべてのための1つのサーバー。
このサーバーは、データベースとすべてのアプリケーションをホストします。 負荷は増大しています。 今、サーバーはチョークし始めています。 これは、データベースとアプリケーション間のリソースの競合が原因である可能性があります。 または、サイトが成長し、1つのサーバーが少なくなりました。 仮想インフラストラクチャを使用する場合、オペレーティングシステムレベルでの複雑なリソース割り当てを行うことなく、データベースとアプリケーションを異なる仮想マシンに単純に配布します。
プロセッサを増やす場所がない場合、またはベースが広くなりすぎてRAM上にある場合、分離を完全に回避することはできません。 その後、クライアントは自分のハードウェアを(まれに)持ち込むか、クラウドリソースをレンタルします(より頻繁に)。
別の考えられる理由は、データベース管理者を開発者から物理的に分離する必要があることです。 ここでは、3リンクのランドスケープについてはまだ説明していません。これがプロジェクトの始まりであり、1つまたは2つのサーバーのみです。 ただし、この段階でも、アプリケーションサーバーのみを必要とするユーザーのために、データベースサーバーへのアクセスを制限できます。

このように、2つの仮想マシンが判明しました。
さらに成長します。 負荷は増大し続けており、アプリケーションサーバーレベルで拡張する必要に直面しています。 これは、リソースを増やすという点でシステムの最も簡単な部分です。新しいマシンを追加するだけです。 したがって、2番目のアプリケーションサーバーがあります。 原則として、データベースはほとんどスペースを占有しないため、まだ複製されておらず、必要に応じてRAMとCPUを追加することで垂直方向にスケーリングされます。
同じ段階で、バランスを取るためにアプリケーションサーバーの前にフロントエンドを追加します。 アプリケーションサーバーは、インフラストラクチャで最も信頼性の低い場所です。 新しいコードが導入されており、テストの徹底に関係なく、常にプロジェクトの「最年少」です。 したがって、2番目のアプリケーションサーバーも予備です。それらの1つをローリングリリースまたは負荷テストのためにオフラインにすることができます。 何らかの種類がありますが、耐障害性があります。
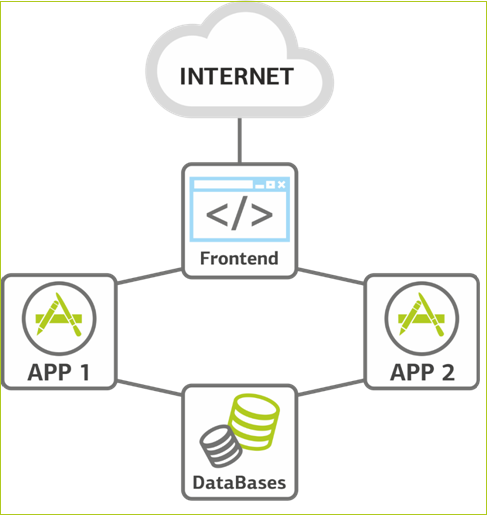
フロントエンドは負荷のバランスを取ります。
ご予約 次の段階は、すべてのロールを配布し、すべてのノードを予約するときです。 「すべてを予約しましょう」のアーキテクチャに移る前に、なぜこれを行うのかを理解する必要があります。これは、ソリューションのインフラストラクチャ全体を複雑にするためです。つまり、障害点とリスクを追加します。 まず、ダウンタイムのコストを見積もります。 まず、直接的な損失:サイトが機能しなかったために保留できなかった注文。 第二に、競合他社から1件の注文を行ったために切り替えたという事実のために失ったユーザー。
このソリューションは、2つの異なるデータセンターに地理的に分散できます。 ジオクラスターはより高価ですが、各ノードのリスクとダウンタイムの数値評価などがあります。 ダウンタイムの価格が決定の価格を上回る場合、予約する必要があります。 すべてのオンラインストアおよび他の売り手は、ダウンタイムの価格を十分に認識しています。 さらに、多くの場合、ストア内のeコマースおよびキャッシュデスクは、共通のITインフラストラクチャに条件付きで関連付けられているため、すべてが一度に立ち上がることができます。 しかし、たとえば、銀行はすべてを知っているわけではありませんが、行き詰まらない方が良いことを直感的に理解しています。 問題は、直接価格に加えて、銀行にとって重要な評判の低下もあるということです。 私は評判の損失のモデルを構築したいくつかの会社を知っています:それを正しくしてください:-)。
フロントエンド機能を広げます。 2つのフロントエンド間の切り替えは、仮想IPアドレスを使用して構成されます。 これを行うには2つの方法があります。 1つのフロントエンドがアクティブで、もう1つのフロントエンドがパッシブである場合、最初のオプションは「アクティブスタンバイ」です。 仮想IPはフロントエンドの1つで機能し、誤動作が発生した場合は別のフロントエンドに移動します。 2番目のオプションは「アクティブ-アクティブ」です。 これらは、2つのサーバーに存在する2つの仮想IPです。 要求は両方のサーバーに並列化され、要求の1つが利用できない場合、両方の仮想IPは2番目のサーバーに移動します。 しかし、標準モードでは、2つのIPで作業するため、負荷が分散されます。
アプリケーションサーバーの数が増えると、いくつかの重要な疑問が生じます。 最初の質問は、ユーザーセッションの制御と保存です。 何らかの理由でセッションが別のアプリケーションサーバーに転送された場合、ユーザーが再度ログインしていくつかの手順に戻る必要がないことを確認する必要があります。 最初の解決策は、セッションを保存するために別のモジュールを使用することです。 これには、NoSQLデータベースが適しています。たとえば、ユーザーセッションデータが保存されます。 すべてのアプリケーションサーバーは、最新のデータを取得するためにアクセスします。 2番目の方法も機能しますが、機能的ではありませんが、バランサーレベルでユーザーセッションを追跡する方法です。 その場合、ユーザーがすでに作業を開始したアプリケーションサーバーが常に送信されます。 2番目のオプションは、よりシンプルで安価な場合もありますが、松葉杖のようなものです。
リポジトリおよび変更の操作には特に注意が払われます。 そして、ここでも2つの主なアプローチがあります。 最初は、より危険な松葉杖です。 テスト済みかどうかに関係なく、すべての更新プログラムを置く何らかの種類のメインサーバーがあります。 さらに、rsyncなどの同期を使用して、他のすべてのサーバーに転送します。 このアプローチのリスクは明らかです。開発者の間違い-システムを停止します。 2番目のアプローチは、リポジトリを保存することです。 通常、それを行います。 リポジトリの保存には、たとえばGitとMercurialがあります。

すべての要素の予約。
ピーク負荷。 この場所では、サイトの負荷の増加に伴い、原則として、鉄と結びついて(まだ残っている場合)、仮想マシンのクラウドに移動する時が来たという理解が得られます。 これは、同じ小売店の季節的なピークのために非常に重要です。2〜4.6倍のインフラストラクチャが必要になる場合があります。 まあ、メモリとコアを成長させる方法は顧客にとって便利です。
季節のピークはすべての人で異なることを言わなければなりません。たとえば、スポーツ用品と家庭用品は新年の1週間前に破れ、12月29日にはすでに不況に陥っています。 一方、食べ物の配達は、12月30日の午前中、そして通常の人々がさまざまな予防作業のためにハイテクの窓を開ける毎週金曜日と土曜日の夜にピークに達し始めています。 5月9日に軍事データのピークのアーカイブがあるサイト。 観光客-夏に。 などなど。 季節的な負荷の調査を実施して、波の大きさと、波の大きさを把握しています。 現時点で実務が示しているように、キャパシティに関しては、クライアントリソースに対する季節的な負荷は、仮想サーバーの負荷のわずかな変動です。 サイトのピークは、データセンターの処理能力の10分の1です。 そしてこれは、物理ホストに障害が発生した場合の予約を考慮していません。
もっと必要です。 予約を見つけましたが、サイトは拡大し続けています。 ここでは、すでにシステムを水平方向にスケーリングし、十分なリソースがない仮想マシンの数を増やしています。 通常、フロントエンドをスケーリングすることは意味がありません-最小限の負荷があり、予約のみが必要です。
データベースでは、スケーリングに関する状況はより複雑です。 SQLのようなデータベースの場合、次のように進みます。1つのデータベースがあり、そのバックアップのために「フローティング」IPアドレスを持つクラスターを収集し、2番目のデータベースをその隣に置きます。 最初のベースが落ちると、2番目のベースに切り替わり、作業を続けます。 Webアプリケーションでは、データベースの負荷の90%が選択的(読み取り要求)であるため、レプリケーションを構成し、この負荷のほとんどをスレーブサーバーに分散できます。 私の記憶では、このようなスレーブサーバーが15個あるプロジェクトがあります。 レプリケーションプロセスの整合性のために、スレーブは読み取り専用に構成されています。
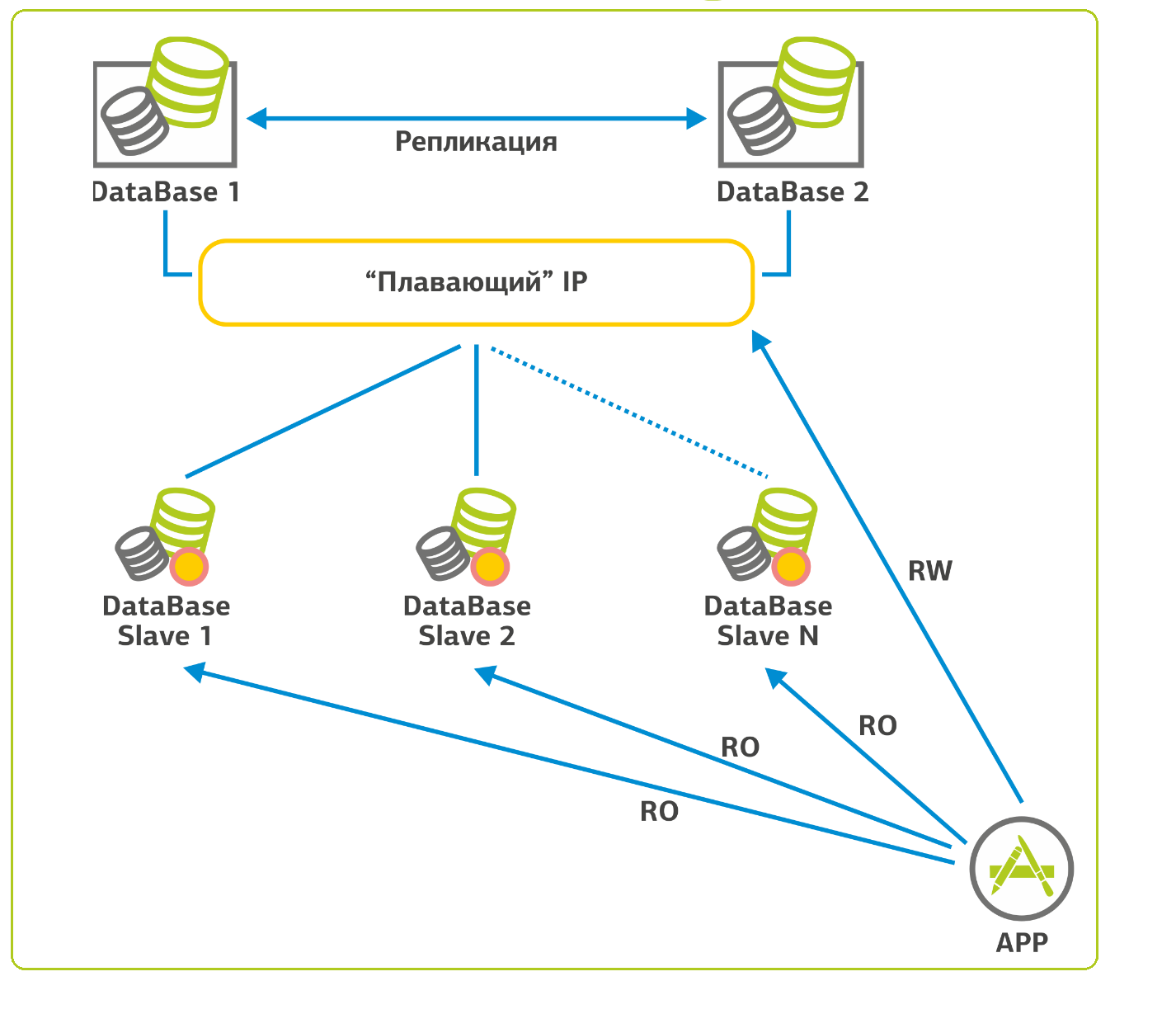
このように。
ウェブサイトが来ました
次に、クライアントサイトが到着したときに何が起こるかについて話しましょう。 ここが一番楽しいです。
多くの場合、OSとWebサーバーの交換から始まります。 一般的な状況-約2年前に前回パッチされた古いubuntと異なるモジュールの古いバージョンが表示されます。 彼らがFedorに企業のウェブサイトさえ持ってきたら(私はあなたに思い出させる:RedHatのテストサイト)。 そして、私たちはアップタイムを担当しているので、Fedora Coreに対するプラトニックな愛を込めて、この軸をそのままにしておくことはできませんでした。 財政的に支援されたSLAでは、なぜ落ちたのかさえわかりません。 私たちのプロジェクトでは、RedHat、CentOS、およびUnbreakable Linuxを好みます(以前は、ディストリビューションはより哀れな-Oracle Enterprise Linuxと呼ばれていました)。 したがって、Linux管理者はRedHatプログラムに従って認定されています。RHCEは、本稼働サーバーへのアクセスの最小レベルです。

これは、サービスのSLAの外観です。可用性の一般的なレベルは、最も弱いリンクより高くすることはできません。
多くの人はメールを簡単に転送する準備ができていますが、長いテストなしでメインサイトを提供する準備はできていません。 たとえば、大企業のオンラインストアは最後に転送されます。最初に、クライアントはいくつかのプロモーションページまたは静的HTMLからそれほど遠くないものを置き、すべてを慎重にロールします。 そして、すべてのテストがサイトの移動に先手を打った後です。
結論の代わりに
サーバーに住む「幻想的な生き物」について話しましょう。 生産から3〜5年生き残ったサイトでは、一部のサービスが古い管理者によってスタックされ、一部は新しい管理者によってスタックされることがよくあります。 これは常に適切に行われるとは限りません。多くの場合、プログラムはソースからコンパイルされ、パッケージマネージャーは完全に「壊れています」。 次のバージョンのリリースを確認する人はいません。原則として、そのようなシステムは更新されません。 破片は数年間漏れることがあります。 たとえば、Tomcatには苦労がありました。Tomcatは「現状のまま」収集し、触れません。 通常、開発者はそれを強制的に更新します。 彼らが新しい機能を手に入れたとき、誰も管理者を引き出せず、彼は製品の更新で得点し、誰もが同じバージョンで幸せに暮らします。 怒るまで、私は指を別の穴に向け始めません。
サーバーに動物園がある場合は、移行計画を提供します。必要なインフラストラクチャを展開します。インフラストラクチャは既に新鮮でスムーズであり、プロジェクトをその上にドラッグします。 具体的には、LinuxをLinuxからドラッグします。別のコマンドはWindowsで機能します。 プラットフォームへのアクセスを許可します-そして、顧客またはその開発者が転送を開始します。 時々それは私たちに委ねられます。
新しいインフラストラクチャは、データベースとサイトスクリプトのコピーを展開します。 次に、お客様とともに、機能テストと負荷テストに進みます。 ここでは、パフォーマンスメトリックのコレクションを構成し、エラーログを制御します。 テスト結果に応じて、開発チームとともに、追加のチューニング(チューニング)を実行します。
機能的な結果を含むテスト結果が満足のいくもので、エラーがなくなったら、サービスを本稼働に移行する準備をしています:監視を設定し、本稼働システムとデータを再同期し、新しいインフラストラクチャに負荷を転送します。 そして、インフラがサイトの成長に対応できるようにします。
今日は以上です。コメント欄で質問してください。