YouTube動画IDがどのように機能するか疑問に思ったことはありますか?
あなたはすでに答えを知っている/見つけたかもしれませんが、Stack Overflowに関する議論が示したように、多くの人々はこの技術を誤解しています。 新しいことを学ぶことに興味があるなら、猫へようこそ。
ID構造
まず、YouTube動画IDとは何かを思い出しましょう。
IDは11文字です(以前は9文字でした)。
構成:
- 大文字のラテン文字
[AZ]
-26文字。 - 小文字のラテン文字
[az]
文字。 - 数字
[0-9]
-10文字。 - ダッシュとアンダースコア
[-_]
-2文字。
合計64文字。
多くのBase64( RFC 2045セクション6.8)でよく知られているものとの類似性に既に気付いているかもしれませんが、これは偶然ではありません。 Base64標準のみが、ダッシュとアンダースコアではなく、プラスとスラッシュ[+/]
を追加文字として使用します。 プラスとスラッシュはURLで使用するために予約されており、URLでIDを使用する際の問題を回避するために、YouTubeはそれらをより安全なものに置き換えました。 ただし、キャラクターを使用することもできます。詳細については後で説明します。
なぜそれが必要ですか
奇妙なことに、ほとんどのユーザーと開発者は、IDを徹底的に検索することですべてのサイトコンテンツをダウンロードできるグラバーから保護するために、そのようなIDが必要であると誤って信じています。
したがって、多くの人はそのようなIDをセキュリティシステムとして真剣に考え、増分数値識別子の複雑なハッシュアルゴリズムを考え出し、ライブラリを作成し、それらを促進します。
ただし、これはハッシュされた数字ではなく、単なる文字列です。 さらに、増分文字列ではなく、 UUIDとの類推によってランダムに生成された値は、著しくコンパクトです。
これは、増分識別子を常に使用し、このデータベースに依存している人にとっては理解が難しい場合があります。 生成された識別子には、インクリメンタル識別子に対する独自の目的、長所と短所があります。
分散システム生成識別子
初めて、分散システムで生成された識別子に直面します。
増分識別子の問題は、データベースがそれらを作成することです。 データの一貫性を維持するには、それらを生成する1つのマスターデータベースが必要です。 これにより、負荷が増加し、シャーディングが困難になります。
一部の人々は、IDの生成のみを扱う別個のデータベースまたはサービスを作成することにより、この問題を解決します。 しかし、サーバーを地理的に分散させて地域を接続する必要がある場合、事態は複雑になります。
解決策は、ローカルIDを維持し、メインサーバーと定期的に同期して、システム全体のパススルーIDを受信することです。 つまり、地域サーバーでは、ローカルIDとエンドツーエンドの2つのIDがあります。
このような問題を解決するために、UUIDなどの生成された識別子が発明されました。 多数の組み合わせがあるため、識別子の競合の可能性は非常に低くなります。 したがって、グローバルIDの生成を特定のアプリケーションインスタンスに任せることができます。
DDDと識別子
ドメイン駆動設計(DDD)の概念は、 Eric EvansとVaughn Vernonの本に詳しく説明されています。 DDDの一般的な考え方は、私たちの主題分野に焦点を当てること、つまり、現実世界にできるだけ近いシステムを設計したいという願望に帰着します。 ここで、DDDにおける識別子の役割についてお話したいと思います。
DDDアプローチでは、識別子なしでエンティティを作成することはできません。 エンティティの新しいインスタンスを初期化するとき、識別子は既にその中にあるはずです。 つまり、作成されたエンティティの識別子をコンストラクタで渡すか、ドメインレベルのサービスを渡して識別子を取得するか、エンティティ自体によって形成された自然な識別子である必要があります。
エンティティの作成時にドメインイベントをスローする場合は、識別子が必要になる場合があります。 イベントに識別子がない場合、リスナーはエンティティの識別に問題がある可能性があります。
同時に、挿入する増分キーがデータベースで使用されます。 データベースにデータを書き込むまで、エンティティの識別子を取得できません。 不一致が得られます。 IDがないためエンティティを作成できません。また、データベースにエンティティを書き込む必要があるため、データベースからIDを取得できません。
この問題を解決するにはさまざまな方法があります。 それらの1つはランダムに生成された識別子であり、これについては現在話しています。
短所
生成された識別子にも欠点があります。 それらなしで。
明らかな欠点は、識別子の生成にかかる時間と、衝突/競合識別子の可能性です。 競合の可能性については、次のセクションで説明します。
ID衝突確率
組み合わせのコースを覚えて、組み合わせの数を推定しましょう。 繰り返しのある配置式が必要です。
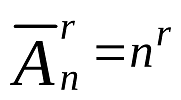
ウイド
UUIDの場合、組み合わせの数はわかっていますが、比較のためにそれらを計算します。
UUIDの形式は550e8400-e29b-41d4-a716-446655440000
で、長さは32文字から区切り文字( -
)を除いたもので、16進数で構成されています。 これにより、16 32または2 128の組み合わせが得られます。 これはたくさんあります。
UUIDには多くの優れた機能があり、多くのユーザーが正常に使用しています。 個人的には、非常に長く、データベース内で多くのスペースを占有し、URLで使用することは困難ですが、気にしませんが、好きではありません 。
YouTube ID
次に、UUIDとYouTubeビデオIDを比較して、組み合わせの数を計算します。
前に確認したように、YouTube動画IDは64文字で構成され、11文字の長さを持っているため、64 11または2 66になります。 この数字は確かにUUIDよりも明らかに小さいですが、それでもかなり大きいと思います。
73 786 976 294 838 206 464
少なくとも何らかの方法でこの数を認識するために、11文字のすべての可能な識別子値を取得し、 ナノ秒ごとに識別子を作成するには2, 339年かかると想像してください。
また、UUIDと同じ数の組み合わせを取得するには、21文字の長さ、つまりUUID(37文字)のほぼ2倍の長さの2,128 = 64,221行が必要です。 UUIDと同じ長さの識別子を取得すると、UUIDの2,128に対して64 37 = 2,222を取得します。
このアプローチの最も重要な利点は、文字列の長さを変更することで組み合わせの数を自分で制御できることです。
より大きな文字セットを使用することにより、識別子をさらにコンパクトにすることができると推測することは難しくありません。 たとえば、128文字のセットを取得してから18文字の識別子を取得すると、128 18 = 2,126の組み合わせが得られ、これはUUIDに匹敵します。 しかし、それはほんの数人のキャラクターを救うだけで、たくさんの問題が追加されます。 使用する文字数が増えると、予約文字を使用する問題や、文字エンコードの不一致の問題に直面します。 したがって、64文字に制限し、識別子の長さだけで再生することをお勧めします。
衝突の確率を計算するには、 WikipediaのUUIDに関する記事の式を使用します。

彼女は

どこで
Nは可能なオプションの数です。
nは、生成されたキーの数です。
YouTubeのような11文字の識別子を取得すると、 N = 64 11 = 2 66が得られ、それに応じて次のようになります。
p(2 25 )≈7.62 * 10 -6
p(2 30 )≈0.0077
p(2 36 )≈0.9999
これにより、最初の数百万の識別子が一意であることが保証されます。 そのような短い識別子にとっては悪い結果ではありません。
ID生成
そして最後にコード。 IDは基本的に生成されます。
class Base64UID { private const CHARS = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-'; public static function generate(int $length): string { $uid = ''; while ($length-- > 0) { $uid .= self::CHARS[random_int(0, 63)]; } return $uid; } }
使用法:
$uid = Base64UID::generate(11); // iKtwBpOH2Ew
DDD
それでは、DDDアプローチを使用するときに、サブジェクトエリアでどのように使用できるかを考えてみましょう。 Articleの本質で新しいIDを使用したいとします。 最初に、記事IDのValueObjectを作成して、記事のIDを一意に識別します。
class ArticleId { private $id; public function __construct(string $id) { $this->id = $id; } public function id(): string { return $this->id; } public function __toString(): string { return $this->id; } }
次に、IDを取得するためのドメインサービスインターフェイスを作成します。 IDの生成をカプセル化し、必要に応じてそれらを偽装するサービスが必要です。
interface ArticleIdGenerator { public function nextIdentity(): ArticleId }
新しいランダム識別子ジェネレーターを使用して、特定の記事IDジェネレーターサービスの実装を作成します。
class Base64ArticleIdGenerator implements ArticleIdGenerator { public function nextIdentity(): ArticleId { return new ArticleId(Base64UID::generate(11)); } }
これで、識別子を持つArticleエンティティを作成できます。
class Article { private $id; public function __construct(ArticleIdGenerator $generator) { $this->id = $generator->nextIdentity(); } public function id(): ArticleId { return $this->id; } }
使用例:
$generator = new Base64ArticleIdGenerator(); $article = new Article($generator); echo $article->id(); // iKtwBpOH2Ew
おわりに
このように単純な方法で、高度な一意性を持つ管理された生成された識別子を取得しました。 生成された識別子をプロジェクトで使用するかどうかはあなた次第ですが、それらの利点は明らかです。
生成された識別子を使用しますか? コメントで教えてください。
PS:自分で書くのが面倒な人のために、PHP 5.3+用の既製のライブラリがあります
PSS:計算には、 このオンライン計算機をお勧めします。
アップデート02-02-2018
この記事の目的は、生成された識別子の原理、長所、短所を示すことであり、UUIDのメリットを損なうことも、Base64を最適なソリューションとして提案することもありません。
アップデート02/05/2018
コメントで議論を要約する。
medvedeviaは、UUIDをbase64にパッケージ化できることに非常に正確に気付きました。 パックされたUUIDの場合、22文字の長さの文字列が出力されますが、これはすでにはるかにコンパクトです。
$uuid = '550e8400-e29b-41d4-a716-446655440000'; $uuid = str_replace('-', '', $uuid); $uuid = hex2bin($uuid); $uuid = base64_encode($uuid); $uuid = str_replace('=', '', $uuid); // VQ6EAOKbQdSnFkRmVUQAAA var_dump($uuid);
ただし、UUIDはまだ長く、 sand14で説明されている他の多くの欠陥があります。
または、 MikalaiR によって提案されたスノーフレークIDを検討して ください 。 TwitterおよびInstagramで正常に使用されています。
スノーフレークIDは64ビットの数値です:
- 符号(1ビット)-タイムスタンプ境界を決定するために必要です。
- タイムスタンプ(41ビット)-マイクロ秒単位の生成IDの日付。
- ジェネレーター(10ビット)-IDを生成するサービスのID。 通常2-データセンターID(5ビット)とマシンID(5ビット)に分かれています。
- シーケンス(12ビット)は増分番号です。
生成されたIDのタイムスタンプが最後に生成されたIDのタイムスタンプと一致すると、シーケンスがインクリメントされます。 ローカルレベルでの競合に対する一種の保護。
かなり単純なスキームが得られます。 Snowflake IDの利点は次のとおりです。
- UUIDよりもコンパクト。
- タイムスタンプの使用により、IDが常に増加しています。
- 衝突に対する高度な保護。
- 乱数ジェネレーターを使用しません
- 手動で構成可能。UUIDよりも早くSnowflake IDを生成できます。
次に、スノーフレークの欠点について説明します。
最初の問題は、ID生成アプリケーションが同じサーバー上で異なるプロセスで実行できることです。 その結果、同じサーバー内で既に衝突を起こす可能性があります。 いくつかの理由により、IDを生成するときにプロセスIDを使用できません。
解決策は、idの生成をマイクロサービスに転送するか、アプリケーションで子プロセスを開始するマスタープロセスに、アルゴリズムで既に使用できる子プロセスにidを強制的に渡すことです。
2番目の問題は、プロジェクトインフラストラクチャに関する情報の開示です。 サーバーの数とデータセンターの数。
3番目の問題は、タイムスタンプの使用です。 時間は無限であり、それをフレームワークに入れることで、失敗に終わります。
すでにコメントで書いたように、タイムスタンプの長さは41ビットで、2039年にはすでに42ビットになります。 スペースのオーバーフローが発生し、idの生成がゼロから始まります。つまり、69年前と同じidを受け取ります。 タイムスタンプの長さが43ビット(2248)の場合、整数オーバーフローが発生します。
Twitterは、この問題を無視する場合があります。これは、Twitterが長い間ツイートを保存しない可能性があるためですが、すべての人に適用できるわけではありません。
いくつかの解決策もあります。 MikalaiRが 言ったように、時間の開始日を、たとえば2000-01-01時代の初めに変更できます。これにより、避けられないものがさらに30年遅れます。
devaloneは、より適切な解決策を提案し ました 。 ビットを再配布し、タイムスタンプの下のスペースを、たとえば最大45ビットまで増やすことができます。これにより、転換点が3084まで延期され、4199でのみ整数オーバーフローが発生します。
スノーフレークID生成の例:
$last_time = 0; $datacenter = 1; $machine = 1; $sequence = 0; $offset = 0; // //$offset = strtotime('2000-01-01 00:00:00') * 1000; $time = floor(microtime(true) * 1000) - $offset; if (!$last_time || $last_time == $time) { $sequence++; } var_dump(sprintf('%b', $time)); $id = 1 << (64 - 1); $id |= $time << (64 - 1 - 41); $id |= $datacenter << (64 - 1 - 41 - 5); $id |= $machine << (64 - 1 - 41 - 5 - 5); $id |= $sequence << (64 - 1 - 41 - 5 - 5 - 12); // //$id = 1 << 63 | $time << 22 | $datacenter << 17 | $machine << 12 | $sequence; var_dump(sprintf('%b', $id)); // base64 $id = dechex($id); $id = hex2bin($id); $id = base64_encode($id); $id = str_replace('=', '', $id); var_dump($id); // oT561auCEAE
ここにYouTube IDが表示されますが、表示されません。 複数のIDを生成すると、それらはほぼ同じであり、最後の4文字は通常一定であることがわかります。
oT5+eFUCEAE oT5+eU8CEAE oT5+ekkCEAE
比較のために、YouTubeにアップロードされた動画を数秒の差で識別します。
fxEbFmSBuIM et34RK4qLy8 3oypcgF-LJQ
バイナリ表現の識別子を比較することにより 、Snowflake idがYouTubeよりもはるかに類似していることを確認することもできます
1010000100111110011111100111100001010101000000100001000000000000 // oT5+eFUCEAE 1010000100111110011111100111100101001111000000100001000000000000 // oT5+eU8CEAE 1010000100111110011111100111101001001001000000100001000000000000 // oT5+ekkCEAE 1010000100111110011111100111100001000001000000100001000000000000 //
0111111100010001000110110001011001100100100000011011100010000011 // fxEbFmSBuIM 0111101011011101111110000100010010101110001010100010111100101111 // et34RK4qLy8 0000000011011110100011001010100101110010000000010100101100100101 // 3oypcgF-LJQ 0000000000010000000010000000000000100000000000000000100000000001 //
YouTubeは、ランダムまたは疑似ランダムに生成された値を使用すると考えています。
アップデート02/21/2018
記事に記載されている識別子を生成する方法は一例です。 特定の例に焦点を合わせないでください。
比較のために、識別子の生成のいくつかの追加例を示して、比較すべきものがあるようにします。 それらのすべては暗号で安全な乱数ジェネレータを使用します。
ランダム文字生成
$length = 11; $chars = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-'; $uid = ''; while ($length-- > 0) { $uid .= $chars[random_int(0, 63)]; } var_dump($uid); // 4rnQMtJ4HRw
長所
- アイデンティティの長さの制御
- 識別子の長さに制限はありません
- 文字セット内の文字自体を変更することが可能です
- セット内の文字数を変更することが可能です
-
random_int()
への複数の呼び出しは、ローカル衝突の可能性を減らします
短所
-
random_int()
への複数の呼び出しは、パフォーマンスに悪影響を及ぼします
バイト生成ID
$length = 64; $uid = ''; while ($length-- > 0) { $uid .= random_int(0, 1); } $uid = bindec($uid); $uid = dechex($uid); $uid = hex2bin($uid); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // tDiGk9YyWAA
長所
- アイデンティティの長さの制御
- 前のバージョンと比較して
random_int()
をより頻繁に呼び出すと、ローカル衝突の可能性が低くなります。
短所
- 文字セット内の文字自体を変更する機能を失った
- セット内の文字数を変更する機能を失った
- 識別子は64ビットに制限されています
-
random_int()
への複数の呼び出しは、パフォーマンスに悪影響を及ぼします
乱数とタイムスタンプ
$time = floor(microtime(true) * 1000); $prefix = random_int(0, 0b111111111); $suffix = random_int(0, 0b111111111); $uid = 1 << (9 + 45 + 9); $uid |= $prefix << (9 + 45); $uid |= $time << 9; $uid |= $suffix; $uid = dechex($uid); $uid = hex2bin($uid); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // vELDchIFvk0
長所
- タイムスタンプを使用して衝突の可能性を減らします
短所
- 文字セット内の文字自体を変更する機能を失った
- セット内の文字数を変更する機能を失った
- 識別子は64ビットに制限されています
- 識別子の長さを管理するのが難しい
- Snowflakeと同様に、識別子は似ています
乱数と浮動タイムスタンプ
$time = floor(microtime(true) * 1000); $prefix_length = random_int(1, 18); $prefix = random_int(0, bindec(str_repeat('1', $prefix_length))); $suffix_length = 18 - $prefix_length; $suffix = random_int(0, bindec(str_repeat('1', $suffix_length))); $uid = 1 << ($suffix_length + 45 + $prefix_length); $uid |= $prefix << ($suffix_length + 45); $uid |= $time << $suffix_length; $uid |= $suffix; $uid = dechex($uid); $uid = hex2bin($uid); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // 4WG5MmC3SQo
長所
- 同じタイムスタンプを使用している場合でも、IDは前の例ほど類似していません。
短所
- 文字セット内の文字自体を変更する機能を失った
- セット内の文字数を変更する機能を失った
- 識別子は64ビットに制限されています
- 識別子の長さを管理するのが難しい
- タイムスタンプの一貫性のない位置のため、衝突は依然として可能です
ランダムバイト生成
$uid = random_bytes(8); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // BOjs1VmavxI
長所
- すべての最短かつ最も簡単なソリューション
- 識別子の長さに制限はありません
短所
- 文字セット内の文字自体を変更する機能を失った
- セット内の文字数を変更する機能を失った
- 最終的な識別子の長さの管理は複雑です
PS:何かを見逃した場合は、コメントを修正してください。