患者はいつ再発しますか? 顧客はいつ出発しますか? このような質問に対する答えは、生存分析を使用して見つけることができます。生存分析は、オブジェクトの「誕生」から「死」までの期間、または同様のイベントを調査するすべての分野で使用できます:機器の受け取りから故障まで、使用開始から会社のサービスおよびあきらめる前など 多くの場合、これらのモデルは医療で使用され、患者の死亡リスクを評価する必要があり、これがモデルの名前の理由ですが、製造、銀行、保険セクターにも適用できます。

明らかに、検討中のオブジェクトの中には、「死」(障害、保険イベントの発生)がまだ発生していないオブジェクトが常に存在し、それらを考慮に入れないことはアナリストの間の一般的な間違いです。時間間隔を人為的に短くすることができます。 この問題を解決するために、まだ発生していない「死」を伴う観測の潜在的な「平均寿命」を推定する生存分析が開発されました。
NHLプレーヤーのキャリア分析
データと生存曲線
医学と経済学におけるこのアプローチの適用について話しましたが、今度はささいな例-NHLプレーヤーのキャリアの持続時間について考えます。 ホッケーは非常にダイナミックで予測不可能なゲームであり、ゴーディハウ(26シーズン)の最高レベルでプレイしたり、衝突が失敗して数シーズン後にキャリアを終了したりすることができることを知っています。 したがって、私たちは、ホッケー選手がNHLで過ごすことができるシーズン数と、キャリアの持続時間に影響する要因は何ですか?
すでにクリアされ、分析の準備ができているデータを見てみましょう。
df.head(3)
| お名前 | 役職 | ポイント | バランス | Career_start | Career_length | 観測された |
|---|---|---|---|---|---|---|
| オリ・ヨキネン | F | 419 | -58 | 1997 | 18 | 1 |
| ケビン・アダムス | F | 72 | -14 | 1997 | 11 | 1 |
| マット・ペッティンガー | F | 99 | -44 | 2000年 | 10 | 1 |
1979年以降にプレーし、少なくとも20試合に出場した688人のNHLホッケー選手のデータが収集されました。フィールドでの位置、得点数、チームの利益(±)、NHLキャリアの始まりとその期間。 観察された列は、プレーヤーがキャリアを完了したかどうか、つまり値0のプレーヤーがまだリーグでプレーしているかどうかを示します。
プレイしたシーズン数によるプレーヤーの分布を見てみましょう。
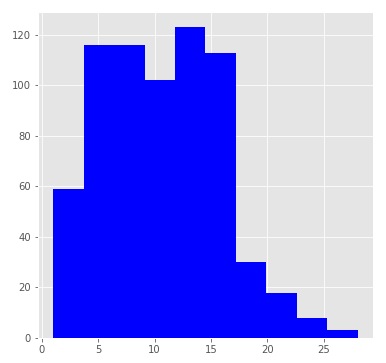
分布は対数正規分布に似ており、中央値は11シーズンです。 これらの統計では、2017年以前にプレーした現在のプレーヤーがプレーしたシーズンの数のみが考慮されるため、スコアの中央値は明らかに過小評価されています。
より正確な値を取得するために、 ライフラインライブラリを使用して生存関数を評価します。
from lifelines import KaplanMeierFitter kmf = KaplanMeierFitter() kmf.fit(df.career_length, event_observed = df.observed)
Out:<lifelines.KaplanMeierFitter: fitted with 1808 observations, 340 censored>
ライブラリの構文はscikit-learnに似ており、その適合/予測: KaplanMeierFitterを開始してから、データでモデルをトレーニングします。 引数として、 fitメソッドは、 carrier_length時間間隔と観測ベクトルを取ります。
最後に、モデルがトレーニングされると、NHLプレーヤーのサバイバル関数を構築できます。
kmf.survival_function_.plot()
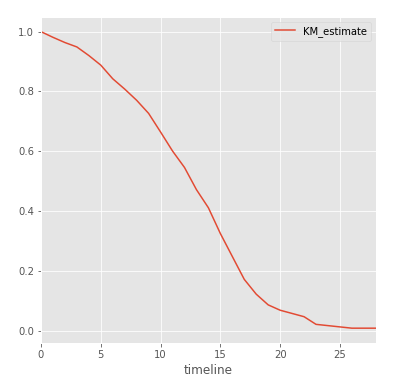
グラフの各ポイントは、プレーヤーがtシーズン以上プレーする確率です。 ご覧のとおり、6シーズンのしきい値はプレーヤーの80%によって克服されていますが、NHLでは17シーズン以上プレーするプレーヤーは非常に少数です。 より厳密に:
print(kmf.median_) print(kmf.survival_function_.KM_estimate[20]) print(kmf.survival_function_.KM_estimate[5])
Out:13.0 0.0685611305647 0.888063315225
したがって、NHLプレイヤーの50%は13シーズンにわたってプレイします。これは、最初の見積もりよりも2シーズン多くなります。 ホッケー選手が5シーズンと20シーズン以上プレーする可能性は、それぞれ88.8%と6.9%です。 若い選手にとっては大きなインセンティブです!
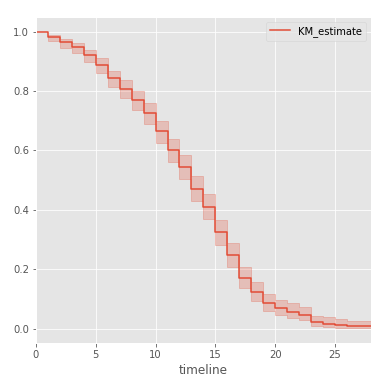
確率の信頼区間とともに、生存関数を導出することもできます。
kmf.plot()
同様に、Nelson-Aalen手順を使用して脅威関数を構築します。
from lifelines import NelsonAalenFitter naf = NelsonAalenFitter() naf.fit(df.career_length,event_observed=df.observed) naf.plot()
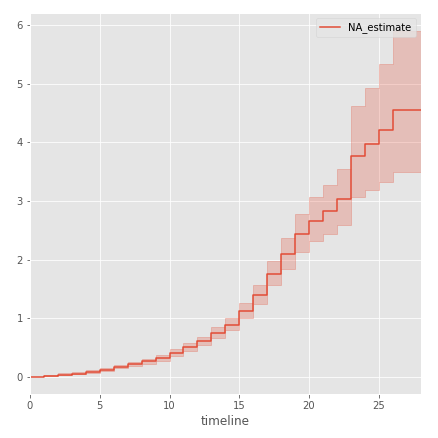
グラフからわかるように、最初の10年間は、NHLプレイヤーがシーズンの終わりにキャリアを終了するリスクは非常に小さいですが、シーズン10以降、このリスクは急激に増加します。 言い換えれば、NHLで10シーズンを過ごした後、プレーヤーはキャリアを終了する方法についてますます考えるようになります。
フォワードとディフェンダーの比較
NHLのキャリアディフェンダーとストライカーの期間を比較します。 最初は、攻撃者は平均してディフェンダーよりもはるかに長くプレイすると想定しています。なぜなら、彼らは多くの場合ファンの間でより人気があり、しばしば複数年の契約を結ぶからです。 また、年齢とともに、プレイヤーは遅くなります。これは、ディフェンダーにとって最も難しいヒットです。ディフェンダーは、活発なフォワードに対処することがますます難しくなっています。
ax = plt.subplot(111) kmf.fit(df.career_length[df.Position == 'D'], event_observed=df.observed[df.Position == 'D'], label="Defencemen") kmf.plot(ax=ax, ci_force_lines=True) kmf.fit(df.career_length[df.Position == 'F'], event_observed=df.observed[df.Position == 'F'], label="Forwards") kmf.plot(ax=ax, ci_force_lines=True) plt.ylim(0,1);
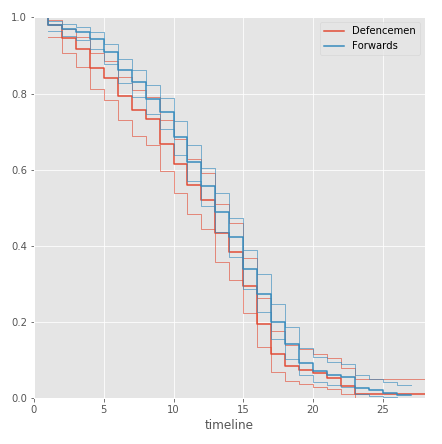
防御側のキャリアの長さは、攻撃側のキャリアの長さよりわずかに短いようです。 結論が正しいことを確認するために、カイ二乗基準に基づいて統計検定を実施します。
from lifelines.statistics import logrank_test dem = (df["Position"] == "F") L = df.career_length O = df.observed results = logrank_test(L[dem], L[~dem], O[dem], O[~dem], alpha=.90 ) results.print_summary()
Results t 0: -1 test: logrank alpha: 0.9 null distribution: chi squared df: 1 __ p-value ___|__ test statistic __|____ test result ____|__ is significant __ 0.05006 | 3.840 | Reject Null | True
したがって、10%の有意水準では、帰無仮説を拒否します。防御者は実際に攻撃者よりも早くキャリアを終了する可能性が高く、グラフからわかるように、キャリアの終わりに向かって差が大きくなります。ゲームと需要が少なくなっています。
生存回帰
多くの場合、「人生」の期間に影響する他の要因も考慮する必要があります。 このために、生存回帰モデルが開発されました。これは、古典的な線形回帰と同様に、従属変数と一連の因子を持ちます。
回帰パラメータを評価するための一般的なアプローチの1つを検討してください-従属変数として時間間隔自体を選択しなかったが、それらに基づいて計算された脅威関数の値である加法アーレンモデル \ラムダ(t) :
lambda(t)=b0(t)+b1(t)x1+...+bn(t)xn
モデルの実装に移りましょう。 モデルの要因として、ポイント数、プレーヤーの位置、キャリア開始日、およびチーム全体のユーティリティ(±)を使用します。
from lifelines import AalenAdditiveFitter import patsy # patsy, design # -1 , X = patsy.dmatrix('Position + Points + career_start + Balance -1', df, return_type='dataframe') aaf = AalenAdditiveFitter(coef_penalizer=1.0, fit_intercept=True) # penalizer, , )
すべてが準備できたので、サバイバル回帰をトレーニングします。
X['L'] = df['career_length'] X['O'] = df['observed'] # career_length observed aaf.fit(X, 'L', event_col='O')
NHLで2人のプレイヤーがプレーするシーズンの数を試してみましょう:2010年にキャリアを開始し、+ 109のユーティリティスコアで310ポイントを獲得したストライカー、デレクステパンと、それをNHLで終わったあまり成功していないNHLプレイヤーであるクラスダルベックと比較してみましょう2014年、ユーティリティスコア-12で11ポイントを獲得しました。
ix1 = (df['Position'] == 'F') & (df['Points'] == 360) & (df['career_start'] == 2010) & (df['Balance'] == +109) ix2 = (df['Position'] == 'D') & (df['Points'] == 11) & (df['career_start'] == 2014) & (df['Balance'] == -12) stepan = X.ix[ix1] dahlbeck = X.ix[ix2] ax = plt.subplot(2,1,1) aaf.predict_cumulative_hazard(oshie).plot(ax=ax) aaf.predict_cumulative_hazard(jones).plot(ax=ax) plt.legend(['Stepan', 'Dahlbeck']) plt.title(' ') ax = plt.subplot(2,1,2) aaf.predict_survival_function(oshie).plot(ax=ax); aaf.predict_survival_function(jones).plot(ax=ax); plt.legend(['Stepan', 'Dahlbeck']);
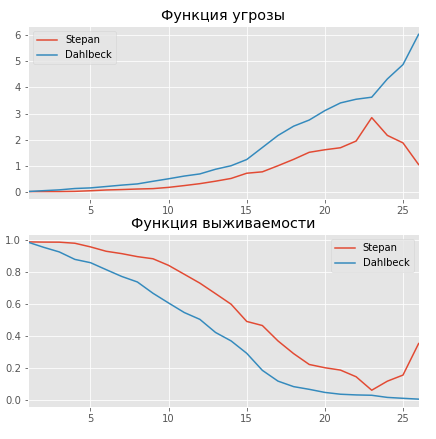
予想通り、より成功したプレーヤーはより高いキャリア期待を持っています。 したがって、Stepanは11シーズン以上プレイする可能性があります-80%、Dalbekは55%しかありません。 脅威曲線は、シーズン13以降、次のシーズンでキャリアを終了するリスクが急激に増加し、ダルベックがステパンよりも速く成長することも示しています。
相互検証
回帰の品質をより厳密に評価するために、 ライフラインライブラリに組み込まれた相互検証手順を使用します。 同時に、打ち切りデータで作業する場合、標準誤差および同様の基準を品質指標として使用することはできません。したがって、ライブラリはAUC指標の一般化である一致インデックスまたは同意インデックスを使用します。 5段階の相互検証を実行します。
from lifelines.utils import k_fold_cross_validation score = k_fold_cross_validation(aaf, X, 'L', event_col='O', k=5) print (np.mean(score)) print (np.std(score))
Out:0.764216775131 0.0269169670161
すべての反復の平均精度は76.4%で、偏差は2.7%です。これは、アルゴリズムの品質がかなり良いことを示しています。