
InterSystemsCachéDBMSには、非構造化iKnowデータを操作するための組み込み技術と、iFind全文検索技術があります。 私たちはテクノロジーを扱うと同時に、何か役に立つことをすることにしました。 結果は、iKnowおよびiFindテクノロジーを使用してインターシステムズのドキュメントを検索するためのWebアプリケーションであるDocSearchです。
Cachéでのドキュメントの動作
Cachéのドキュメントは、 Docbookテクノロジに基づいています。 ドキュメントにアクセスするためのWebインターフェイスが提供されています(iFindまたはiKnowを使用しない検索を含む)。 実際、ドキュメント記事のデータはCachéクラスにあります。これにより、これらのデータを個別に照会することができ、それに応じて独自の検索ユーティリティを作成することができます。
iKnowとiFindとは何ですか:
Intersystems iKnowは、テキストに含まれる文とエンティティにインデックスを付けることでデータへのアクセスを提供する非構造化データ分析ツールです。 分析を開始するには、非構造化データのリポジトリであるドメインを作成し、そこにテキストをロードする必要があります。 ドメインを作成するプロセスは、 こことここで詳しく説明されています 。 iKnowの基本的な使用方法はここに記載されています。 この記事もお勧めします。
IFindテクノロジは、Cachéクラスに基づいて全文検索を実行するためのCachéDBMSモジュールです。 iFindは、iKnowの多くの機能を使用して、インテリジェントなテキスト検索を提供します。 クエリでiFindを使用するには、Cachéクラスで特別なiFindインデックスを記述する必要があります。
iFindインデックスには3つのタイプがあり、各タイプのインデックスは前のタイプのすべての機能に加えて、追加の機能を提供します。
- メインインデックス(%iFind.Index.Basic):語句の検索をサポートします。
- セマンティックインデックス(%iFind.Index.Semantic):iKnowオブジェクトの検索をサポートします。
- 分析インデックス(%iFind.Index.Analytic):セマンティックインデックス内のすべてのiKnow関数、および単語のパスと近接性に関する情報をサポートします。
ドキュメントクラスは別の領域に格納されるため、この領域でクラスを使用できるようにするために、インストーラーはパッケージとグローバルをマッピングします。
XData Install [ XMLNamespace = INSTALLER ] { <Manifest> // <IfNotDef Var="Namespace"> <Var Name="Namespace" Value="DOCSEARCH"/> <Log Text="Set namespace to ${Namespace}" Level="0"/> </IfNotDef> // <If Condition='(##class(Config.Namespaces).Exists("${Namespace}")=1)'> <Log Text="Namespace ${Namespace} already exists" Level="0"/> </If> // <If Condition='(##class(Config.Namespaces).Exists("${Namespace}")=0)'> <Log Text="Creating namespace ${Namespace}" Level="0"/> // <Namespace Name="${Namespace}" Create="yes" Code="${Namespace}" Ensemble="" Data="${Namespace}"> <Log Text="Creating database ${Namespace}" Level="0"/> // <Configuration> <Database Name="${Namespace}" Dir="${MGRDIR}/${Namespace}" Create="yes" MountRequired="false" Resource="%DB_${Namespace}" PublicPermissions="RW" MountAtStartup="false"/> <Log Text="Mapping DOCBOOK to ${Namespace}" Level="0"/> <GlobalMapping Global="Cache*" From="DOCBOOK" Collation="5"/> <GlobalMapping Global="D*" From="DOCBOOK" Collation="5"/> <GlobalMapping Global="XML*" From="DOCBOOK" Collation="5"/> <ClassMapping Package="DocBook" From="DOCBOOK"/> <ClassMapping Package="DocBook.UI" From="DOCBOOK"/> <ClassMapping Package="csp" From="DOCBOOK"/> </Configuration> <Log Text="End creating database ${Namespace}" Level="0"/> </Namespace> <Log Text="End creating namespace ${Namespace}" Level="0"/> </If> </Manifest> }
iKnowに必要なドメインは、ドキュメントを含むテーブル上に構築されています。 データソースはテーブルなので、SQL.Listerを使用します。 コンテンツフィールドにはドキュメントのテキストが含まれているため、データフィールドとして示します。 残りのフィールドはメタデータに示されます。
ClassMethod Domain(ByRef pVars, pLogLevel As %String, tInstaller As %Installer.Installer) As %Status { #Include %IKInclude #Include %IKPublic set ns = $Namespace znspace "DOCSEARCH" // set dname="DocSearch" if (##class(%iKnow.Domain).Exists(dname)=1){ write "The ",dname," domain already exists",! zn ns quit } else { write "The ",dname," domain does not exist",! set domoref=##class(%iKnow.Domain).%New(dname) do domoref.%Save() } set domId=domoref.Id // Lister , set flister=##class(%iKnow.Source.SQL.Lister).%New(domId) set myloader=##class(%iKnow.Source.Loader).%New(domId) // set myquery="SELECT id, docKey, title, bookKey, bookTitle, content, textKey FROM SQLUser.DocBook" set idfld="id" set grpfld="id" // set dataflds=$LB("content") set metaflds=$LB("docKey", "title", "bookKey", "bookTitle", "textKey") // Lister set stat=flister.AddListToBatch(myquery,idfld,grpfld,dataflds,metaflds) if stat '= 1 {write "The lister failed: ",$System.Status.DisplayError(stat) quit } // set stat=myloader.ProcessBatch() if stat '= 1 { quit } set numSrcD=##class(%iKnow.Queries.SourceQAPI).GetCountByDomain(domId) write "Done",! write "Domain cointains ",numSrcD," source(s)",! zn ns quit }
ドキュメントを検索するには、%iFind.Index.Analyticインデックスを使用します。
Index contentInd On (content) As %iFind.Index.Analytic(LANGUAGE = "en", LOWER = 1, RANKERCLASS = "%iFind.Rank.Analytic");
ここで、contentIndはインデックスの名前、contentはインデックスを作成するフィールドの名前です。
パラメーターLANGUAGE = "en"は、テキストが書かれている言語を示します
パラメーターLOWER = 1により、大文字と小文字を区別しないように設定します
パラメーターRANKERCLASS = "%iFind.Rank.Analytic"。TF -IDFランキングアルゴリズムを使用できます。
このようなインデックスを追加および構築した後、たとえばSQLクエリで使用できます。 SQLでiFindを使用するための一般的な構文は次のとおりです。
SELECT * FROM TABLE WHERE %ID %FIND search_index(indexname,'search_items',search_option)
このようなパラメータを使用して%iFind.Index.Analyticインデックスを作成すると、次の形式のいくつかのSQLプロシージャが作成されます-[テーブル名] _ [インデックス名]プロシージャ名
このプロジェクトでは、そのうちの2つを使用します。
- DocBook_contentIndRank-リクエストのTF-IDFランキングアルゴリズムの結果を返します
構文は次のとおりです。
SELECT DocBook_contentIndRank(%ID, 'SearchString', 'SearchOption') Rank FROM DocBook WHERE %ID %FIND search_index(contentInd,'SearchString', 'SearchOption')
- DocBook_contentIndHighlight-検索結果を返します。検索ワードは指定されたタグで囲まれています。
SELECT DocBook_contentIndHighlight(%ID, 'SearchString', 'SearchOption','Tags') Text FROM DocBook WHERE %ID %FIND search_index(contentInd,'SearchString', 'SearchOption')
これらの手順の使用について以下に説明します。
最終的に起こったこと:
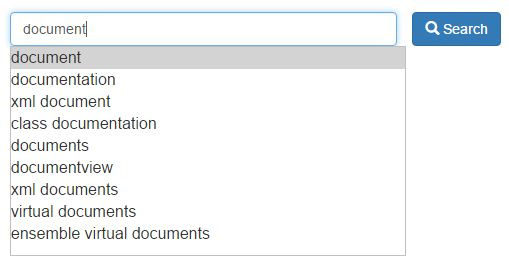
検索バーのオートコンプリート
検索バーにテキストを入力すると、可能なクエリオプションが提供され、必要な情報をすばやく見つけることができます。 これらのプロンプトは、入力した単語(または、単語が完成していない場合は単語の最初の部分)に基づいて作成され、ユーザーに最も類似した10個の単語またはフレーズが表示されます。
このプロセスは、iKnow、%iKnow.Queries.Entity.GetSimilarメソッドで発生します
ファジー検索
IFindテクノロジーは、検索文字列にほぼ一致する単語を見つけるためのファジー検索をサポートしています。 これは、2つの単語間のレーベンシュタイン距離を比較することで実現されます。 レーベンシュタイン距離は、1つの単語を別の単語に変更するために必要な1文字の変更(挿入、削除、または置換)の最小数です。 タイプミス、文章の小さなバリエーション、さまざまな文法形式(単数形および複数形)を修正するために使用できます。
iFind SQLクエリでは、search_optionパラメーターはファジー検索を使用します。
search_option = 3の値は、レーベンシュタイン距離が2に等しいことを意味します。
レーベンシュタイン距離をnに設定するには、値search_option = '3:n'を指定します
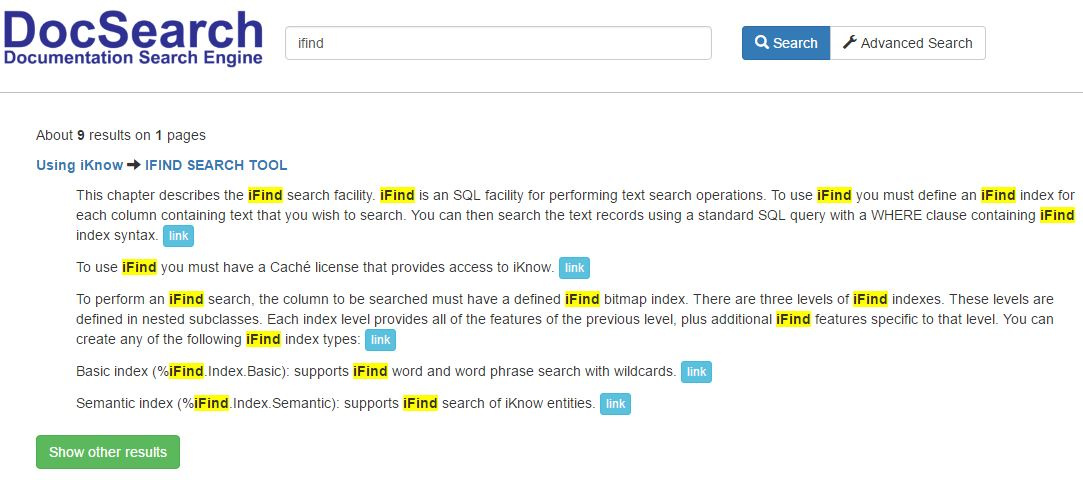
ドキュメントの検索では、1に等しいレーベンシュタイン距離が使用されます。これがどのように機能するかを示します。
検索ifindを入力します。
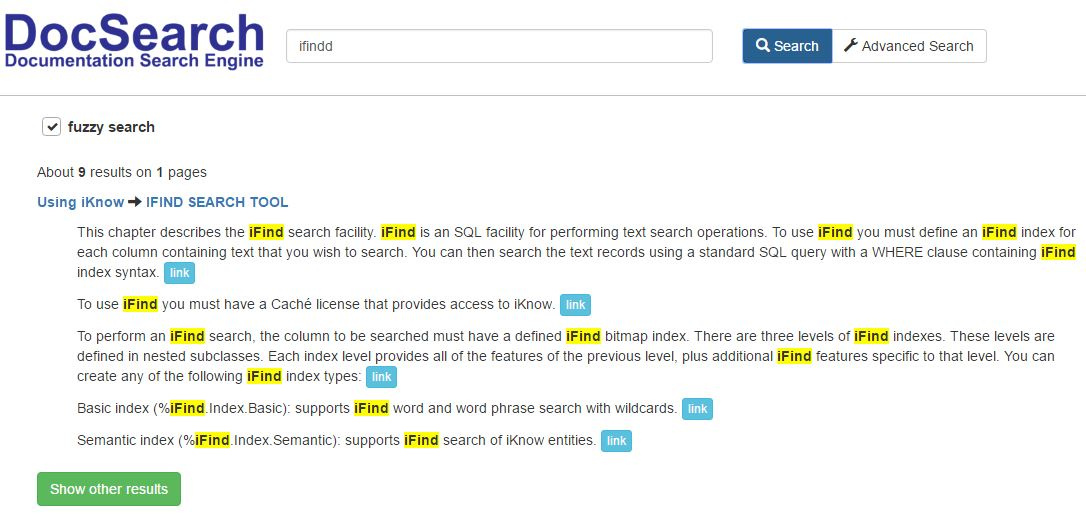
たとえば、スペルミスの単語-ifinddなど、あいまい検索を試みてみましょう。 ご覧のとおり、検索でタイプミスが修正され、必要な記事が見つかりました。
複雑なクエリ
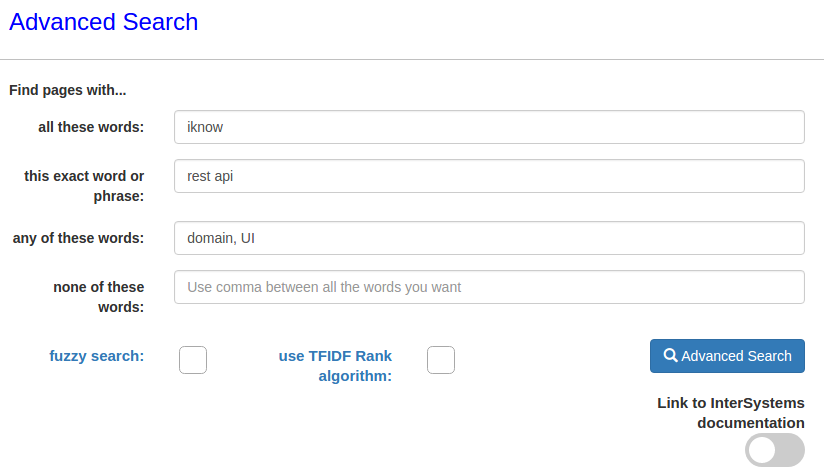
iFindは角括弧とAND OR NOT演算子を使用した複雑なクエリをサポートしているため、高度な検索を実装しました。 検索では、単語、フレーズ、いくつかの単語のいずれか、またはいくつかの単語を含まないことを指定できます。 フィールドは、1つ以上、またはすべてを一度に入力できます。
たとえば、単語iknow、フレーズrest api、および単語domainまたはUIのいずれかを含む記事を検索します。
そのような記事が2つあることがわかります。
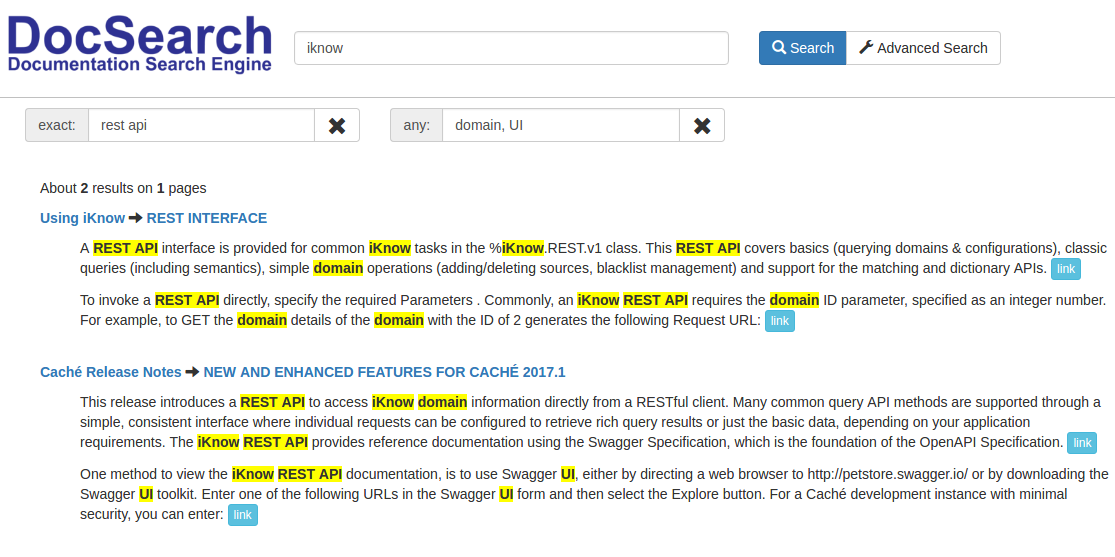
2番目の記事ではSwagger UIに言及していることに注意してください。クエリに追加して、Swaggerという単語を含まない記事を検索できます。
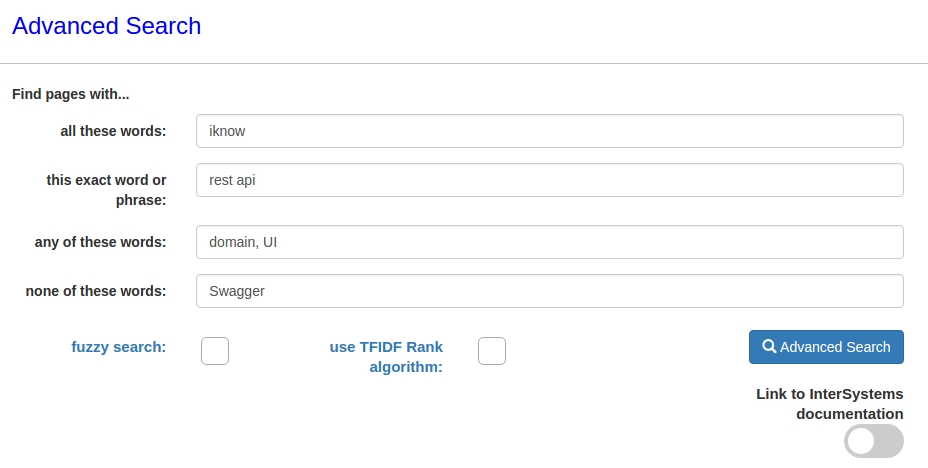
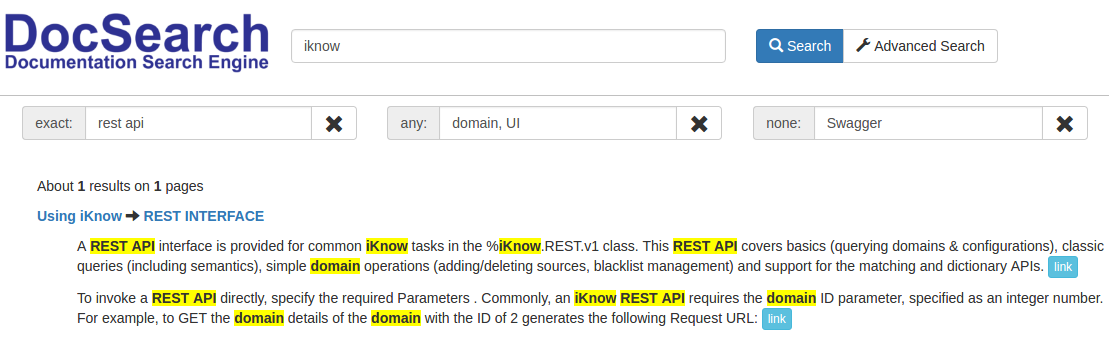
その結果、1つの記事のみが見つかりました。
検索結果の強調表示
上記のように、iFindインデックスを使用すると、DocBook_contentIndHighlightプロシージャが作成されます。 を使用して:
SELECT DocBook_contentIndHighlight(%ID, 'search_items', '0', '<span class=""Illumination"">', 0) Text FROM DocBook
タグに囲まれた目的のテキストを取得します
<span class="Illumination">
これにより、フロントエンドの検索結果を視覚的に強調できます。

結果ランキングアルゴリズム
iFindは、 TF-IDFアルゴリズムを使用して結果をランク付けする機能をサポートしています。 TF-IDFメジャーは、テキストの分析や情報検索の問題で、たとえば検索クエリに対するドキュメントの関連性の基準の1つとして使用されることがよくあります。
SQLクエリの結果として、ランクフィールドには単語の重みが含まれます。これは、記事でのこの単語の使用量に比例し、他の記事での単語の使用頻度に反比例します。
SELECT DocBook_contentIndRank(%ID, 'SearchString', 'SearchOption') Rank FROM DocBook WHERE %ID %FIND search_index(contentInd,'SearchString', 'SearchOption')
公式ドキュメント検索との統合
インストール後、「iFindを使用して検索」ボタンが公式ドキュメント検索に追加されます。

[検索語]フィールドが入力されている場合、[iFindを使用して検索]をクリックすると、入力したクエリの検索結果を含むページにリダイレクトされます。
フィールドが入力されていない場合、システムは新しい検索の開始ページに移動します。
設置
- リリースページの最新リリースからファイルInstaller.xmlをダウンロードします
- ダウンロードしたInstaller.xmlファイルを%SYS領域にインポートして、コンパイルします。
- %SYS領域のターミナルで、次のコマンドを入力します。
do ##class(Docsearch.Installer).setup(.pVars)
ドメインを構築するプロセスのため、このプロセスには約15〜30分かかります。
その後、検索はlocalhostで利用可能になります:[ポート] /csp/docsearch/index.html
デモ
オンライン検索のデモはこちらから入手できます 。
おわりに
このプロジェクトは、iFindおよびiKnowテクノロジーの興味深い便利な機能を示しています。これにより、検索の関連性が高まります。
批判、コメント、提案を歓迎します。
githubに投稿されたインストーラーとインストール手順を含むすべてのソースコード