 JVMはどのようにして新しいオブジェクトを作成しますか?
JVMはどのようにして新しいオブジェクトを作成しますか? new Object()
を記述するとどうなりますか?
会議では、スレッドローカルアロケーションバッファー(スレッドローカルアロケーションバッファー)を使用してオブジェクトを割り当てると定期的に言います:各スレッドに排他的に割り当てられたメモリ領域、同期の欠如によりオブジェクトの作成が非常に高速です。
しかし、適切なサイズのTLAB'aを選択する方法は? TLABのサイズの10%を割り当てる必要があり、9%のみが無料の場合はどうすればよいですか? オブジェクトをTLABの外部に割り当てることはできますか? 割り当てられたメモリがリセットされるのはいつですか?
これらの質問をし、すべての答えを見つけられなかったので、状況を修正する記事を書くことにしました。
読む前に、ある種のガベージコレクタがどのように機能するかを覚えておくと役立ちます(たとえば、 この一連の記事を読んだ後)。
はじめに
新しい施設を作成するにはどのような手順が必要ですか?
まず、必要なサイズの未使用のメモリ領域を見つける必要があり、次にオブジェクトを初期化する必要があります:メモリをゼロにし、いくつかの内部構造( getClass()
を呼び出すとき、オブジェクトで同期するときなどに使用される情報)を初期化し、最後にコンストラクタを呼び出す必要があります。
この記事は次のように構成されています。最初に理論上何が起こるかを理解しようとし、次に何らかの方法でJVMの内部に入り、すべてが実際に起こる様子を確認し、最後にいくつかのベンチマークを作成して確認します。
免責事項:一部の部品は、一般性を失わずに意図的に簡略化されています。 ガベージコレクションといえば、圧縮コレクター、およびアドレス空間と言えば、若い世代のエデンです。 他の[標準または広く知られている]ガベージコレクターの場合、詳細は変更される可能性がありますが、あまり大きくありません。
TLAB 101
最初の部分は、オブジェクトに空きメモリを割り当てることです。
一般的なケースでは、効果的なメモリの割り当ては、痛み、苦しみ、ドラゴンに満ちた重要なタスクです。 たとえば、2の倍数のサイズのリンクリストが作成され、それらが検索され、必要に応じてメモリ領域が切り取られて、あるリストから別のリスト(別名バディアロケーター )に移動されます 。
幸いなことに、Javaマシンにはガベージコレクターがあり、ジョブの難しい部分を担っています。 若い世代を組み立てるプロセスでは、すべての生きているオブジェクトがサバイバースペースに移動され、edenに1つの大きな連続した空きメモリ領域が残されます。
JVMのメモリがGCを解放するため、アロケータはこの空きメモリの場所を知るだけでよく、実際、この空きメモリへの1つのポインタへのアクセスを制御します。 つまり、割り当ては非常に単純でなければなりません ポニーと虹で構成されています :ポインタにオブジェクトのサイズを追加して、edenとメモリを解放する必要があります(この手法はbump-the-pointerと呼ばれます )。
この場合、複数のスレッドがメモリを割り当てることができるため、何らかの形式の同期が必要です。 最も簡単な方法(ヒープ領域またはポインターのアトミック増分のブロック)を行うと、メモリー割り当てが簡単にボトルネックになる可能性があるため、JVM開発者はバンプポインターを使用して以前のアイデアを開発しました:各スレッドには、それだけに属する大きなメモリチャンクが割り当てられます。 そのようなバッファ内の割り当ては、可能な限りポインタの同じ増分で発生します(ただし、すでにローカルで、同期は行われていません)。現在の領域が終了するたびに新しい領域が要求されます。 この領域は、 スレッドローカル割り当てバッファと呼ばれます 。 ヒープ領域が最初のレベルにあり、現在のスレッドが2番目のTLABにある、一種の階層的なバンプポインターが判明します。 一部のユーザーはそこで停止できず 、バッファー内のバッファーを階層的にスタックすることもできません 。

ほとんどの場合、割り当ては非常に高速で、わずか数命令で実行され、次のようになります。
start = currentThread.tlabTop; end = start + sizeof(Object.class); if (end > currentThread.tlabEnd) { goto slow_path; } currentThread.setTlabTop(end); callConstructor(start, end);
あまりにも良さそうなので、PrintAssemblyを使用して、 java.lang.Object
を作成するメソッドがどのようにコンパイルされるかを見てみましょう 。
; Hotspot machinery skipped mov 0x60(%r15),%rax ; start = tlabTop lea 0x10(%rax),%rdi ; end = start + sizeof(Object) cmp 0x70(%r15),%rdi ; if (end > tlabEnd) ja 0x00000001032b22b5 ; goto slow_path mov %rdi,0x60(%r15) ; tlabTop = end ; Object initialization skipped
%r15
レジスタには常にVMスレッドへのポインターが含まれるという秘密の知識があります(叙情的な逸脱:この不変式により、スレッドローカルとThread.currentThread()
非常に高速に動作します)。期待していた。 同時に、JITコンパイラーが呼び出しメソッドに割り当てを直接挿入したことに注意してください。
このようにして、JVMは(ガベージコレクションを考慮せずに)ほとんど無料で、1ダースの命令に対して新しいオブジェクトを作成し、メモリのクリアとデフラグの責任をGCに移します。 良いボーナスは、割り当てられたデータの行のローカリティです。これは、古典的なアロケーターでは保証できない場合があります。 そのような局所性が典型的なアプリケーションのパフォーマンスに与える影響についての全体的な研究があります。 スポイラーアラート :GCの負荷が増加しているにもかかわらず、すべてが少し速くなります。
何が起こっているかに対するTLABサイズの影響
TLABのサイズはどのくらいですか? 最初の近似として、バッファサイズが小さいほど、メモリの割り当てがスローブランチを通過する頻度が高くなるため、TLABをより多く実行する必要があると想定するのが合理的です。
ただし、別の問題があります。 内部フラグメンテーションです。
TLABのサイズが2メガバイトで、eden領域(TLABの割り当て元)が500メガバイトを占有し、アプリケーションに50ストリームがある状況を考えます。 ヒープ内の新しいTLABの場所がなくなると、TLABを使い果たす最初のスレッドがガベージコレクションをトリガーします。 TLABが±均一に満たされると仮定すると(実際のアプリケーションではそうではないかもしれません)、平均して、残りのTLABは約半分になります。 つまり、別の0.5 * 50 * 2 == 50
メガバイトの未割り当てメモリ( 0.5 * 50 * 2 == 50
10%)がある場合、ガベージコレクションが開始されます。 うまく動作しません。メモリのかなりの部分はまだ空いていますが、GCはまだ呼び出されています。

TLABのサイズまたはスレッドの数を増やし続けると、メモリ損失が線形的に増加し、TLABは割り当てを高速化しますが、アプリケーション全体の速度が低下し、再びガベージコレクターに負担がかかることがわかります。
TLABにまだ場所があるが、新しいオブジェクトが大きすぎる場合はどうでしょうか? 古いバッファを捨てて新しいバッファを割り当てると、断片化が増加するだけですが、そのような状況で常にedenでオブジェクトを直接作成すると、アプリケーションの動作が遅くなりますか?
一般に、何をすべきかは明確ではありません。 神秘的な定数をハードコーディングして(ヒューリスティックインライン化のために行われたように)、開発者にサイズを与え、アプリケーションごとに個別に(信じられないほど便利に)カスタマイズすることができます。
どうする?
定数を選択することはありがたい仕事ですが、Sunのエンジニアは絶望せず、逆に行きました:サイズを指定する代わりに、断片化の割合が示されます-迅速な割り当てのために犠牲にする準備ができているヒープの一部であり、JVMはそれを何らかの方法で把握します。 TLABWasteTargetPercent
パラメーターがこれを担当し、デフォルトは1%です。
スレッドによるメモリ割り当ての均一性に関する同じ仮説を使用して、単純な方程式tlab_size * threads_count * 1/2 = eden_size * waste_percent
ます。
edenの10%を寄付する準備ができている場合、スレッドは50個あり、edenは500メガバイトを占有します。ガベージコレクションの開始時に、半分空のTLABで50メガバイトを解放できます。つまり、この例では、TLABのサイズは2メガバイトになります。
このアプローチには重大な欠落があります。すべてのスレッドが等しく割り当てられるという仮定が使用されますが、これはほとんど常に真実ではありません。 最も激しいストリームの割り当て率に数値を調整することは望ましくありません;また、私は彼らのより遅い同僚(例えば、スケジュールされた労働者)を怒らせたくありません。 さらに、典型的なアプリケーションでは(たとえば、お気に入りのアプリサーバーのトレッドミルに)数百のスレッドがあり、深刻な負荷なしに新しいオブジェクトを作成するスレッドはごくわずかです。これも何らかの形で考慮する必要があります。 「TLABのサイズの10%を割り当てる必要があり、9%だけが無料の場合はどうすればよいですか?」という質問を思い出すと、それは完全に自明ではなくなります。
ブログで推測したり覗いたりするには詳細が多すぎるので、今度はすべてが実際にどのように機能するかを調べましょう。ホットスポットのソースコードを見てみましょう。
jdk9ウィザードを使用しました。ここにCMakeLists.txtがあります。これを使用して、旅行を繰り返したい場合にCLionが動作します。
ウサギの穴を倒す
関心のあるファイルは、最初のgrepから見つけられ 、 threadLocalAllocBuffer.cppと呼ばれます 。これは、バッファーの構造を記述しています。 クラスはバッファを記述するという事実にもかかわらず、スレッドごとに1回作成され、新しいTLABが割り当てられるときに再利用されると同時に、TLABの使用に関するさまざまな統計がそこに格納されます。
JITコンパイラーを理解するには、JITコンパイラーのように考える必要があります。 したがって、初期初期化をすぐにスキップし、新しいスレッド用のバッファーを作成してデフォルト値を計算し、各アセンブリの最後にすべてのスレッドに対して呼び出されるresize
メソッドを調べます。
void ThreadLocalAllocBuffer::resize() { // ... size_t alloc =_allocation_fraction.average() * (Universe::heap()->tlab_capacity(myThread()) / HeapWordSize); size_t new_size = alloc / _target_refills; // ... }
うん! 各スレッドについて、その割り当ての強度が追跡され、その割り当てと定数_target_refills
(「2つのアセンブリ間でスレッドに要求するTLABの数」として慎重に署名されます)に応じて、新しいサイズが計算されます。
_target_refills
一度初期化されます:
// Assuming each thread's active tlab is, on average, 1/2 full at a GC _target_refills = 100 / (2 * TLABWasteTargetPercent);
これはまさに上記で仮定した仮説ですが、TLABのサイズの代わりに、ストリームの新しいTLABのリクエスト数が計算されます。 アセンブリ時にすべてのスレッドが最大x%
空きメモリを持つためには、各スレッドのTLABサイズが合計メモリの2x%
である必要があります。これは通常、アセンブリ間で割り当てられます。 1
を2x
すると、必要な数のクエリだけが得られます。
スレッド割り当て共有は、いつか更新する必要があります。 各ガベージコレクションの開始時に、すべてのフローの統計が更新されます。これは、 accumulate_statistics
メソッドにあります。
- スレッドがTLABを少なくとも1回更新したかどうかを確認します。 何もしない(または少なくとも割り当てない)スレッドのサイズを再計算する必要はありません。
- 計算でのフルGCまたは病理学的ケース(たとえば、
System.gc()
明示的な呼び出しSystem.gc()
の影響を回避するために、edenの半分が使用されたかどうかを確認します。 - 最後に、edenの何パーセントがストリームを使用したかを考慮し、割り当てのシェアを更新します。
- スレッドがどのようにTLABを使用したか、割り当てられた方法と量、およびメモリが無駄になった量の統計を更新します。
アセンブリの頻度と、ガベージコレクターの不整合とストリームの要求に関連するさまざまな割り当てパターンに起因するさまざまな不安定な影響を回避するために、割り当てのシェアは単なる数字ではなく、最後のN個のアセンブリの平均を維持する指数加重移動平均です。 JVMにはすべての独自のキーがあり、この場所も例外ではありませんTLABAllocationWeight
フラグは、平均値が古い値をどれだけ早く忘れるかを制御します(誰かがこのフラグの値を変更したいわけではありません)。
結果
受け取った情報は、TLABのサイズに関する質問に答えるのに十分です。
- JVMは、断片化に使用できるメモリ量を認識しています。 この値から、スレッドがガベージコレクション間で要求するTLABの数が計算されます。
- JVMは、各スレッドが使用するメモリ量を監視し、これらの値を平滑化します。
- 各スレッドは、使用するメモリに比例してTLABのサイズを受け取ります。 これにより、スレッド間の不均等な割り当ての問題が解決され、平均してすべてが迅速に割り当てられますが、メモリをほとんど消費しません。

アプリケーションに100個のスレッドがあり、そのうち3個がマイトとメインでユーザーのリクエストを処理し、タイマーの2個が何らかの補助アクティビティに関与し、他のすべてがアイドル状態の場合、スレッドの最初のグループは大きなTLABを受け取り、2番目は非常に小さく、残りはすべてデフォルト値になります。 そして、最良の部分は、すべてのスレッドの「遅い」割り当て(TLAB要求)の数が同じであることです。
C1での割り当て
TLABのサイズが整理されました。 遠くまで行かないように、ソースをより深く掘り下げて、TLABが高速、低速、本当に低速のときに際立っていることを確認してください。
ここでは、1つのクラスだけでは対応できず、 new
演算子が何にコンパイルされるかを調べる必要があります。 外傷性の脳損傷を回避するために、クライアントコンパイラ(C1)のコードを見てみましょう:サーバーコンパイラよりもはるかにシンプルで理解しやすく、世界の全体像をよく説明しています。Javaのnew
ものは非常に人気があるため、十分な最適化が行われています。
C1_MacroAssembler::allocate_object
でのオブジェクトの割り当てと初期化を記述するC1_MacroAssembler::allocate_object
、メモリをすばやく割り当てることができなかったときに実行されるRuntime1::generate_code_for
2つのメソッドに興味があります。
オブジェクトを常に迅速に作成できるかどうかを確認するのは興味深いことです。「使用法を見つける」チェーンは、 instanceKlass.hppのこのコメントにつながります 。
// This bit is initialized in classFileParser.cpp. // It is false under any of the following conditions: // - the class is abstract (including any interface) // - the class has a finalizer (if !RegisterFinalizersAtInit) // - the class size is larger than FastAllocateSizeLimit // - the class is java/lang/Class, which cannot be allocated directly bool can_be_fastpath_allocated() const { return !layout_helper_needs_slow_path(layout_helper()); }
このことから、非常に大きなオブジェクト(デフォルトでは128キロバイトを超える)とファイナライズ可能なクラスが、JVMで常に遅い呼び出しを行うことが明らかになります。 (なぞなぞ-抽象クラスはどこと関係があるのでしょうか?)
このメモを取り、割り当てプロセスに戻ります。
tlab_allocate-オブジェクトをすばやく割り当てようとする試み。PrintAssemblyを見たときにすでに見たコードとまったく同じです。 判明した場合、これで割り当てを終了し、オブジェクトの初期化に進みます。
tlab_refill-新しいTLABの割り当てを試みます。 興味深いチェックを使用して、このメソッドは、新しいTLABを割り当てる(古いTLABを破棄する)か、オブジェクトをedenに直接割り当てて古いTLABを残すかを決定します。
// Retain tlab and allocate object in shared space if // the amount free in the tlab is too large to discard. cmpptr(t1, Address(thread_reg, in_bytes(JavaThread::tlab_refill_waste_limit_offset()))); jcc(Assembler::lessEqual, discard_tlab);
tlab_refill_waste_limit
は、TLABのサイズにのみ責任があり、1つのオブジェクトを割り当てるために犠牲にする準備ができていません。 デフォルト値は現在のTLABサイズの1.5%
です(もちろん、これにはTLABRefillWasteFraction
パラメーターがあります。これは突然 64の値を持ち、値自体は現在のTLABサイズをこのパラメーターの値で割ったものと見なされます)。 この制限は、失敗したケースでの低下を避けるために、遅い割り当てごとに引き上げられ、各GCサイクルの終わりにリセットされます。 1つ少ない質問。
- eden_allocate -edenでメモリ(オブジェクトまたはTLAB)を割り当てようとします。 この場所はTLABでの割り当てに非常に似ています:場所があるかどうかを確認し、ある場合は、
lock cmpxchg
命令を使用してアトミックにメモリを取得し、ない場合は低速パスに進みます。 edenでの割り当ては待機フリーではありません。2つのスレッドが同時にedenで何かを割り当てようとすると、何らかの確率でそのうちの1つが失敗し、もう一度繰り返す必要があります。
JVMアップコール
edenでメモリを割り当てることができなかった場合、JVMで呼び出しが行われ、 InstanceKlass::allocate_instance
つながります。 呼び出し自体の前に、多くの補助的な作業が実行されます-GCの特別な構造が設定され、 呼び出し規約に対応するために必要なフレームが作成されるため、操作は速くありません。
たくさんのコードがあり、表面的な説明は1つしかできないので、だれも退屈させないために、おおよその作業スキームのみを示します。
- 最初に、JVMは現在のガベージコレクターの特定のインターフェイスを介してメモリを割り当てようとします。 上記と同じ一連の呼び出しが行われます。最初にTLABから割り当てを試行し、次にヒープからTLABを割り当ててオブジェクトを作成します。
- 失敗した場合、ガベージコレクションが呼び出されます。 GCオーバーヘッド制限がどこかを超えたため、さまざまなGC通知、ログ、および割り当てに関係しないその他のチェックが同じ場所のどこかに関係しています。
- ガベージコレクションが役に立たない場合は、旧世代に直接割り当てようとします(ここで、動作は選択したGCアルゴリズムに依存します)。失敗した場合は、別のアセンブリとオブジェクト作成の試行が発生します。
OutOfMemoryError
。 - オブジェクトが正常に作成されると、それが時間、ファイナライズ可能かどうかがチェックされ、そうであれば、登録されます。これは、
Finalizer#register
メソッドの呼び出しで構成されます(なぜこのクラスが標準ライブラリにあるのか疑問に思っていましたが、明示的に使用されていませんか?)。 メソッド自体は、かなり前に明示的に作成されました。ファイナライザオブジェクトが作成され、グローバル(原文のまま)ロックの下で、リンクリストに追加されます(オブジェクトはその後、ファイナライズおよび収集されます)。 これは、JVMでの無条件呼び出しと(部分的に)「本当に必要な場合でもfinalizeメソッドを使用しない」というアドバイスによって正当化されます。
その結果、割り当てに関するほとんどすべてがわかりました。オブジェクトはすぐに割り当てられ、TLABはすぐにいっぱいになり、オブジェクトはedenですぐに割り当てられ、一部はJVMで急いで呼び出されます。
遅い割り当ての監視
メモリの割り当て方法はわかりましたが、この情報をどうするかはまだありません。
上記のどこかで、すべての統計(遅い割り当て、リフィルの平均数、割り当てフローの数、内部フラグメンテーションによる損失)がどこかに記録されると書きました。
 - — perf data, hsperfdata, jcmd
- — perf data, hsperfdata, jcmd sun.jvmstat.monitor
API.
, Oracle JDK, JFR ( API, OpenJDK), -.
? , Twitter JVM team, , .
Prefetch
, - prefetch', .
Prefetch — , , , , ( ) , . Prefetch , , , , (, ) , , .
ホットスポットでは、プリフェッチはC2固有の最適化であるため、C1コードでは言及されていません。最適化の構成は次のとおりです。TLABでの割り当て中に、割り当てられたオブジェクトのすぐ後ろにあるキャッシュメモリにロードする命令が生成されます。 Javaアプリケーションは平均して1つまたは複数の割り当てを行うため、後続の割り当てのためにメモリをプリロードすることは非常に良い考えのようです。

prefetch' , AllocatePrefetchStyle
: prefetch , , , . AllocatePrefetchInstr
, prefetch : L1- (, - ), L3 : , .ad .
, JVM-, SPECjbb- Java - , ( , , , ).
, , . C1-, ARM — , .
C1_MacroAssembler::initialize_object
:
. — mark word ,
, identity hashcode ( biased locking) , klass pointer, — , metaspace,java.lang.Class
.
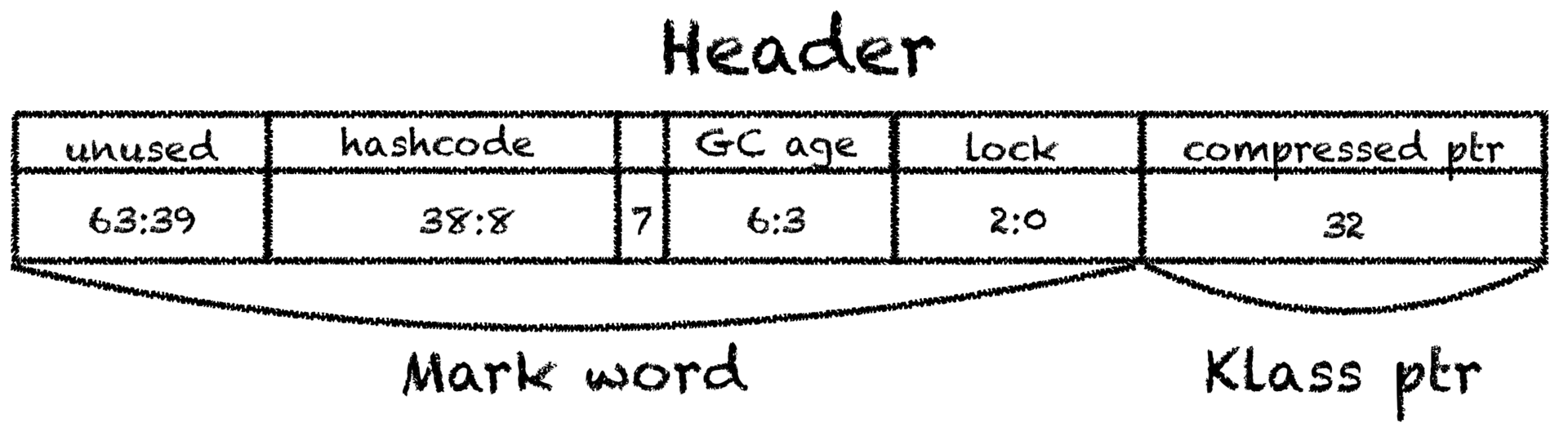
32 64. , 12 ( , 16).
,
ZeroTLAB
. :
, , . C2- , . .
- StoreStore ( gvsmirnov ), (, ) , .
// StoreStore barrier required after complete initialization // (headers + content zeroing), before the object may escape. membar(MacroAssembler::StoreStore, tmp1);
これは、オブジェクトの安全でない公開に必要です:コードにエラーがあり、オブジェクトがレースを通じて公開されている場合、フィールドのデフォルト値またはコンストラクターが出力したものを表示することを期待します(言語仕様はこれを保証します) 、しかし薄気味悪いわけではなく、仮想マシンは正しいヘッダーを見ることを期待しています。x86には強力なメモリモデルがあり、この命令は必要ありません。そのため、ARMを検討しました。
実践的にチェック
上記のコードのバグに注意してください。私はそれが正しいことを証明しただけで、試したことはありません。
これまでのところ、すべてが素晴らしく見えます。ソースで十分に幸運であり、いくつかの面白い瞬間を発見しましたが、コンパイラが実際に何をするのか分からないかもしれません。
PrintAssembly
new Long(1023)
:
0x0000000105eb7b3e: mov 0x60(%r15),%rax 0x0000000105eb7b42: mov %rax,%r10 0x0000000105eb7b45: add $0x18,%r10 ; 24 : 8 , ; 4 , ; 4 , ; 8 long 0x0000000105eb7b49: cmp 0x70(%r15),%r10 0x0000000105eb7b4d: jae 0x0000000105eb7bb5 0x0000000105eb7b4f: mov %r10,0x60(%r15) 0x0000000105eb7b53: prefetchnta 0xc0(%r10) ; prefetch 0x0000000105eb7b5b: movq $0x1,(%rax) ; 0x0000000105eb7b62: movl $0xf80022ab,0x8(%rax) ; Long 0x0000000105eb7b69: mov %r12d,0xc(%rax) 0x0000000105eb7b6d: movq $0x3ff,0x10(%rax) ; 1023
, , .
, :
- TLAB'.
- TLAB' , eden' TLAB, eden', .
- eden' , .
- , .
- , OOM.
- .
: , prefetch TLAB' -.
実験
, , . , java.lang.Object
, JVM.
Java 1.8.0_121, Debian 3.16, Intel Xeon X5675. — , — .

:
- , ,
new
. , : - (,Blackhole#consumeCPU
), , . - prefetch . JVM , -, . , .
- TLAB' : — JIT -> JVM, , .
finalize
, eden' finalizable-:

!
おわりに
JVMは、新しいオブジェクトをできる限り迅速かつ簡単に作成するために多くのことを行い、TLABが提供する主要なメカニズムです。TLAB自体は、ガベージコレクタとの緊密な協力のおかげでのみ可能になりました。メモリを解放する責任をそれに移して、割り当てはほとんど自由になりました。
この知識は適用可能ですか?たぶん、とにかく、どのような場合でも、楽器がどのように内部に配置され、どのようなアイデアを使用しているかを理解することは常に役に立ちます。
レビューのためにapanginとgvsmirnovに感謝します。それなしでは、あいまいな言葉遣い、コードのリスト、うわさで満たされた記事の真ん中に到達する前に退屈で死んでしまいます。