この投稿では、ディープニューラルネットワークの学習プロセスを高速化しながら予測の精度を高める方法について、最近公開された2つのアイデアの概要を説明します。 (異なる著者によって)提案された方法は互いに直交しており、一緒に別々に使用できます。 ここで提案する方法は、理解と実装が簡単です。 実際、元の出版物へのリンク:
1.ショットのアンサンブル:1つの価格で多くのモデル
モデルの定期的なアンサンブル
アンサンブルは、予測を取得するために集合的に使用されるモデルのグループです。 アイデアは簡単です。異なるハイパーパラメーターで複数のモデルをトレーニングし、テスト時にそれらの予測を平均します。 この手法により、予測精度が大幅に向上します;機械学習コンテストのほとんどの勝者は、アンサンブルを使用
それで問題は何ですか?
Nモデルのトレーニングには、1つのモデルのトレーニングのN倍の時間が必要です。
力学SGD
確率的勾配降下(SGD)は、貪欲なアルゴリズムです。 パラメーター空間で最大の勾配の方向に移動します。 同時に、重要なパラメーターが1つあります。それは学習速度です。 学習速度が速すぎる場合、SGDはパラメーター超平面(最小)のレリーフにある狭いくぼみを無視し、溝を通るタンクのようにそれらを飛び越えます。 一方、学習速度が遅い場合、SGDはローカルミニマムの1つになり、そこから抜け出すことはできません。
ただし、学習速度を上げることにより、SGDをローカルミニマムから引き出すことができます。
手を見て......
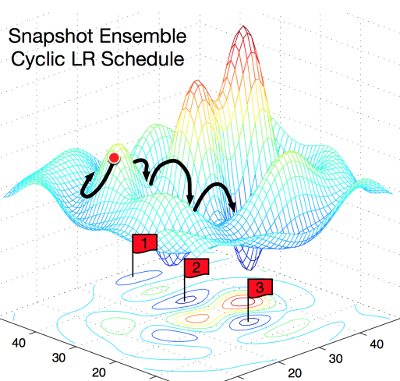
この記事の著者は、この制御されたSGDパラメーターを使用して、極小値にロールインし、そこから終了します。 異なる極小値は、テスト中に同じ割合のエラーを与えることができますが、各極小値の特定のエラーは異なります!
この図は、概念を非常に明確に示しています。 左は、通常のSGDがどのように機能するかを示しており、ローカルミニマムを見つけようとしています。 右:SGDは最初のローカルミニマムに分類され、トレーニング済みモデルのスナップショットが取得され、ローカルミニマムからSGDが選択され、次のモデルが検索されます。 そのため、エラーの割合は同じですが、エラー特性が異なる3つの極小値を取得します。

アンサンブルの構成要素は何ですか?
著者は、局所予測の特性を活用して、モデル予測に関するさまざまな「視点」を反映しています。 SGDがローカルミニマムに達するたびに、モデルのスナップショットが保存されます。テスト中、モデルのスナップショットはアンサンブルになります。
サイクリックコサインアニーリング
自動意思決定、ローカルミニマムに突入するタイミング、および終了するタイミングについて、著者は学習速度をアニーリングする機能を使用します。

式は扱いにくいように見えますが、実際には非常に単純です。 著者は単調減少関数を使用しています。 アルファは学習速度の新しい価値です。 アルファゼロは以前の値です。 Tは、使用する予定の反復の合計数です(バッチサイズX元号数)。 M-受け取りたいモデルの写真の数(アンサンブルサイズ)。
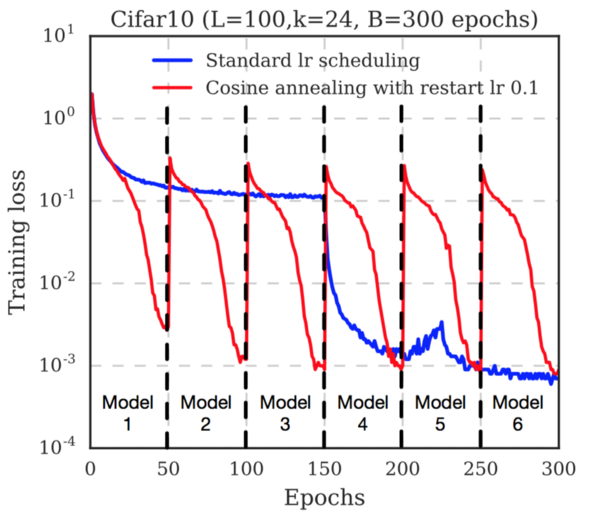
各ショットが保存される前に、損失関数がどれほど速く減少するかに注目してください。 これは、学習率が絶えず低下しているためです。 画像を保存した後、学習速度が復元されます(作成者はレベル0.1を使用します)。 これにより、局所最小値から勾配降下の軌跡が取得され、新しい最小値の検索が開始されます。
おわりに
著者は、いくつかのデータセット(Cifar 10、Cifar 100、SVHN、Tiny IMageNet)およびいくつかの一般的なニューラルネットワークアーキテクチャ(ResNet-110、Wide-ResNet-32、DenseNet-40、DenseNet-100)のテスト結果を提示します。 すべての場合において、提案された方法で訓練された集団は、エラーの割合が最も低いことを示しました。
したがって、モデルをトレーニングするときに追加の計算コストなしで精度の向上を得るための有用な戦略が提案されます。 TやMなどのさまざまなパラメーターのパフォーマンスへの影響については、元の記事を参照してください。
2.フリーズ:レイヤーを順番にフリーズして学習を加速します
この記事の著者は、予測の精度を損なうことなくレイヤーをフリーズすることで学習が加速することを実証しました。
レイヤーフリーズとはどういう意味ですか?
レイヤーをフリーズすると、トレーニング中のレイヤーの重みの変化を防ぎます。 この手法は、別のデータセットでトレーニングされた基本モデルが凍結されている場合、転移学習でよく使用されます。
凍結はモデルの速度にどのように影響しますか?
レイヤーの重み係数を変更しない場合は、このレイヤーを逆方向に通過することを完全に排除できます。 これにより、計算プロセスが大幅に高速化されます。 たとえば、モデル内のレイヤーの半分が固定されている場合、モデルをトレーニングするには計算の半分が必要になります。
一方、まだモデルをトレーニングする必要があるため、レイヤーを早く凍結すると、モデルは不正確な予測を行います。
目新しさとは何ですか?
著者は、可能な限り早い段階でレイヤーを1つずつフリーズする方法を示し、バックパッセージを排除してトレーニング時間を最適化しました。 最初は、モデルは通常どおり完全にトレーニングされています。 数回の反復の後、モデルの最初のレイヤーが凍結され、残りのレイヤーのトレーニングが続行されます。 さらに数回繰り返した後、次のレイヤーが凍結されます。
(再び)アニーリングトレーニング速度
著者は、アニーリングトレーニングレートを使用しました。 アプローチの重要な違い:学習率はモデル全体ではなく、 レイヤーごとに異なります。 次の式を使用しました。

ここで、alphaは学習速度、tは反復数、iはモデルの層数です。
モデルの最初のレイヤーが最初に凍結されるため、そのトレーニングはサイクル数が最も少ないことに注意してください。 これを補うために、著者は各層の初期学習係数をスケーリングしました:

その結果、著者は、予測の精度を低下させることなく 、3%の精度低下、または15%の加速により、学習の20%の加速を達成しました。
ただし、提案された方法は、レイヤースキップを使用しないモデル(VGG-16など)ではうまく機能しません。 このようなネットワークでは、加速も予測の精度への影響も見られませんでした。