プログラミングマシンを手に入れるために、貧しい初心者には1つの興味深いタスクが求められました。それは、モンテカルロ法を使用してツリーを検索するプログラムを書くことです。
もちろん、それはすべてインターネット上の情報を見つけることから始まりました。 偉大で強力なロシア語には、アルゴリズムの本質を口頭で説明するHabrからの記事と、Goとコンピューターをプレイする問題にリダイレクトするWikipediaからの記事だけがありました。 私にとって、これはすでに良いスタートです。 私は完全性のために英語でグーグルで検索し、アルゴリズムも口頭で説明されている英語版ウィキペディアの記事を見つけました。
理論のビット
ツリーを検索するためのモンテカルロ法は、人工知能のゲームで長い間使用されてきました。 アルゴリズムのタスクは、最も成功するシナリオを選択することです。 ツリーは、ムーブとポインターに加えて、プレイされたゲームの数と勝ったゲームの数がある構造です。 これら2つのパラメーターに基づいて、メソッドは次のステップを選択します。 次の図は、アルゴリズムの動作を示しています。
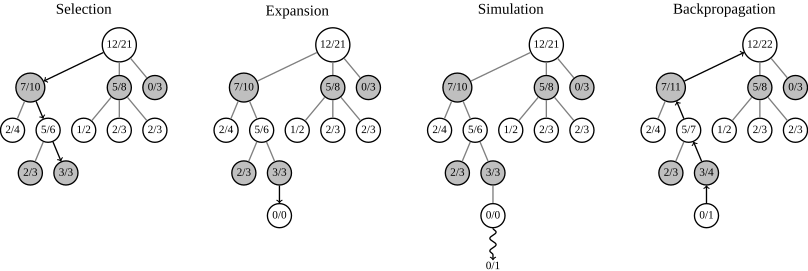
ステップ1:選択-選択。 このステップで、アルゴリズムは相手の動きを選択します。 そのような移動が存在する場合はそれを選択し、存在しない場合は追加します。
ステップ2:拡張。 対戦相手の動きがある選択されたノードに、独自の動きがあり結果がゼロのノードを追加します。
ステップ3:シミュレーション-シミュレーション。 競技場の現在の状態から他の誰かの勝利までゲームをプレイします。 ここから、最初の動き(つまり、私たちの動き)と結果のみを取得します。
ステップ4:バックプロパゲーション。 シミュレーションの結果を現在からルートに配布します。 すべての親ノードに、プレイしたゲームの数に1を追加し、勝者ノードにつまずいた場合、そのようなノードで勝ったゲームの数に1を追加します。
その結果、このようなアルゴリズムを備えたボットは、勝つための動きをします。
実際、アルゴリズムはそれほど複雑ではありません。 むしろ体積。
実装
ゲームTic Tac Toeのボットとしてアルゴリズムを実装することにしました。 ゲームはシンプルで完璧です。 しかし、悪魔は詳細にあります...
問題は、実際のプレーヤーなしでシミュレーションステップでゲームをプレイする必要があることです。 もちろん、このようなシミュレーションでアルゴリズムにランダムな動きをさせることもできましたが、意味のある動作が必要でした。
次に、2つのことしかわからない単純なボットが作成されました。プレーヤーを妨害し、ランダムな動きをするためです。 これは、シミュレーションするのに十分すぎるほどでした。
他のすべての人と同様に、アルゴリズムを備えたボットは、フィールドの現在の状態、最後の動きからのフィールドの状態、独自の動きのツリー、およびこのツリーで現在選択されているノードに関する情報を持ちました。 そもそも、新しい敵の動きを見つけるでしょう。
// 0. add node with new move. bool exist = false; int enemyx = -1, enemyy = -1; this->FindNewStep ( __field, enemyx, enemyy ); for ( MCBTreeNode * node : this->mCurrent->Nodes ) { if ( node->MoveX == enemyx && node->MoveY == enemyy ) { exist = true; this->mCurrent = node; } } if ( !exist ) { MCBTreeNode * enemymove = new MCBTreeNode; enemymove->Parent = this->mCurrent; enemymove->MoveX = enemyx; enemymove->MoveY = enemyy; enemymove->Player = (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS; this->mCurrent->Nodes.push_back ( enemymove ); this->mCurrent = enemymove; }
ご覧のように、ツリー内にそのような敵の動きがある場合、それを選択します。 そうでない場合は追加します。
// 1. selection // select node with more wins. MCBTreeNode * bestnode = this->mCurrent; for ( MCBTreeNode * node : this->mCurrent->Nodes ) { if ( node->Wins > bestnode->Wins ) bestnode = node; }
ここで選択します。
// 2. expanding // create new node. MCBTreeNode * newnode = new MCBTreeNode; newnode->Parent = bestnode; newnode->Player = this->mFigure; this->mCurrent->Nodes.push_back ( newnode );
ツリーを展開します。
// 3. simulation // simulate game. TTTGame::Field field; for ( int y = 0; y < TTT_FIELDSIZE; y++ ) for ( int x = 0; x < TTT_FIELDSIZE; x++ ) field[y][x] = __field[y][x]; Player * bot1 = new Bot (); bot1->SetFigure ( (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS ); Player * bot2 = new Bot (); bot2->SetFigure ( this->mFigure ); Player * current = bot2; while ( TTTGame::IsPlayable ( field ) ) { current->MakeMove ( field ); if ( newnode->MoveX == -1 && newnode->MoveY == -1 ) this->FindNewStep ( field, newnode->MoveX, newnode->MoveY ); if ( current == bot1 ) current = bot2; else current = bot1; }
ボット間でゲームをプレイしましょう。 ここで少し説明する必要があると思います。フィールドの現在の状態がコピーされ、ボットがこのコピーでプレイし、2番目のボットが最初に移動し、最初の動きを記憶します。
// 4. backpropagation. int winner = TTTGame::CheckWin ( field ); MCBTreeNode * currentnode = newnode; while ( currentnode != nullptr ) { currentnode->Attempts++; if ( currentnode->Player == winner ) currentnode->Wins++; currentnode = currentnode->Parent; }
そして最後:結果を得て、それをツリーに広げます。
// make move... this->mCurrent = newnode; TTTGame::MakeMove ( __field, this->mFigure, mCurrent->MoveX, mCurrent->MoveY );
最後に、移動を行い、2番目のステップからの新しいノードを現在のノードとして配置します。
おわりに
ご覧のとおり、アルゴリズムはそれほど怖くなく複雑ではありません。 もちろん、私の実装は理想とはほど遠いですが、本質と実用的なアプリケーションを示しています。
すべてに良い。