Apache Igniteは、1つ以上の地理的に分散したクラスター内で弾性的にスケーリングし、ノードを動的に追加または削除するときに柔軟なシャーディングと自動リバランスを提供し、ネイティブAPIまたは従来のSQLを使用してデータおよび計算への透過的かつ高速なアクセスを提供します。
バージョン2.0では、多くの事柄が「内部」で大幅に作り直されました。その結果、いくつかの重要な機能変更を実装する可能性がありました。その一部はすでに顕著で、一部は次のバージョンで登場します
今後、Apache Igniteに関連する2つのイベントを実施します。それらの詳細については、記事の最後に記載されています。

新しいストレージアーキテクチャ
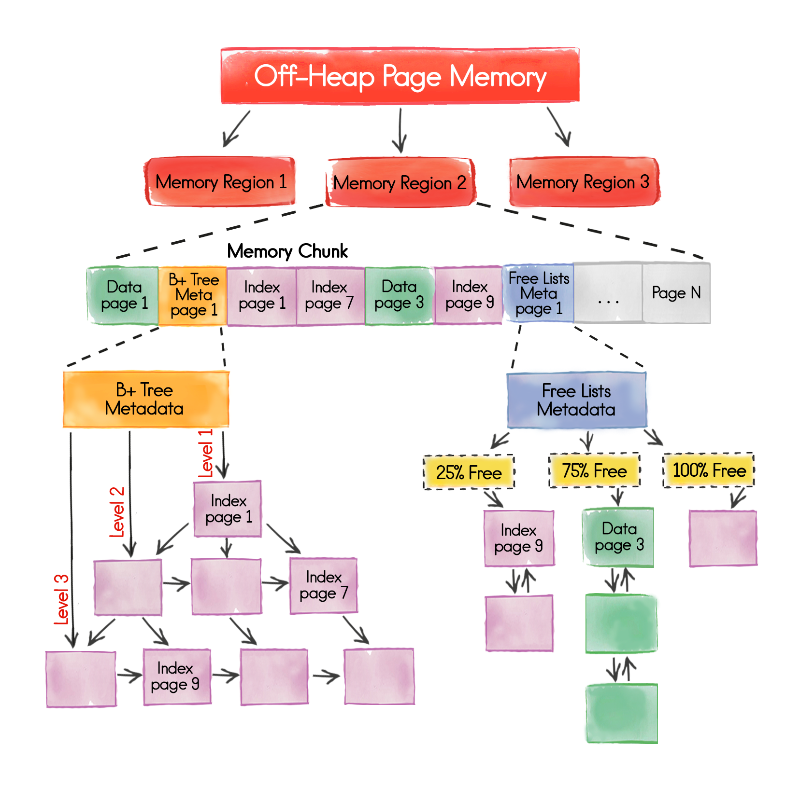
デフォルトでは、Apache Igniteはランダムアクセスメモリで動作し、データを分散形式で保存し、そこで計算を実行します。 バージョン2.0の主要な革新の1つは、ページメモリと呼ばれる完全に再設計されたメモリアーキテクチャです。 これは非常に重要です。
データストレージへの新しいアプローチは、古いものよりもはるかに複雑で思慮深く、メモリの断片化の問題を回避し、SQLの処理を大幅に高速化し、システムの機能に対するGCの一時停止の影響を最小限に抑えることができます。 さらに、新しいアーキテクチャにより、RAMとディスクの両方でシームレスに作業できます。 バージョン2.0では、この機能はまだありませんが、近い将来、この分野の開発計画についてさらに学習することが可能になります。
新しいアーキテクチャは、下図の一般的な用語と、ドキュメントの特別なセクションにあります 。
機械学習
Apache Igniteの目標は、開発者が非常に軽い(高速な分散キャッシュが必要)から非常に重い(I地球のさまざまな場所にあるデータセンターに保存されているビッグデータの分散リアルタイムHTAP計算が必要であり、Cassandra、Spark、Hadoopなどと統合したいと考えています。
残念なことに、Apache Igniteには、最新のITの最もホットな分野の1つである機械学習のコンポーネントが多数ありませんでした。 ここまで。
Apache Ignite 2.0は、分散コンピューティングに適合した基本的な機械学習代数のサポートを追加します。 私たちは、非常に低レベルのツールを提供しているが、そこで止まらないことを理解しています。 将来のバージョンでは、この基本代数は、基本的な機械学習アルゴリズムの分散実装(回帰、分類木など)を構築する基礎になります。
それまでの間、 GitHubの例を読んで、現在の製品を手で感じてみてください。
データ定義言語
このリリース以降、Apache Igniteは初期DDLサポートをDMLに追加しました。 これで、古典的なSQL構文を使用して、クラスターノードの動作を中断することなく、インデックスを作成し、重要なことに変更できます。 これは、ユーザーが求めている最も予想される機能の1つです。 そして、これはほんの始まりです! 将来のリリースでは、CREATE TABLE、ALTER TABLEなどを含む、より多くのDDL操作が表示されます。 現在の機能の詳細については、ドキュメントをご覧ください。
また、変更の中で
- Ignite.NET:Ignite.NETのプラグインシステムサポート 。
- Ignite.C ++:クラスターでのC ++コードのリモート呼び出し 。これまでのバージョンでは、連続クエリでのみ。
- Spring Dataとの統合により 、Apache Igniteの実装が容易になり、アプリケーションを構築するための共通のフレームワークで使いやすくなります。
- RocketMQとの統合 。
- Hibernate 5 L2キャッシュのサポート。
- などなど
ウェビナーとMeetup
Apache Ignite 2.0のリリースを記念して、2つのイベントを開催する予定です。
- 6月7日のウェビナーでは、バージョン2.0のイノベーションについて英語で説明します。
-近い将来にモスクワで開催されるIgnition.meetup()(別途発表予定)、ロシア語での経験の交換、質問、プラットフォームでのソリューション構築の実際の事例を聞くことが可能になります