前回の記事、 パート1、概要で 、分散データ構造(以下RSDと呼びます)が必要な理由について説明し、 Apache Ignite分散キャッシュが提供するいくつかのオプションを検討しました。
今日は、特定のRSDの実装の詳細についてお話しするとともに、分散キャッシュに関する小規模な教育プログラムを実施します。
だから:

そもそも、少なくともApache Igniteの場合、RSDはゼロから実装されているのではなく、分散キャッシュ上のアドオンです。
分散キャッシュは、情報が複数のサーバーに保存されるデータストレージシステムですが、同時に全データへのアクセスがすぐに提供されます。
この種のシステムの主な利点は、その能力です 詰め込む 特定のドライブまたはサーバー全体のボリュームによって制限される、大量のデータを断片に分割せずに保存します。
ほとんどの場合、このようなシステムでは、分散ストレージシステムに新しいサーバーを追加して、ストレージを動的に増やすことができます。
データのバランスをとるだけでなく、クラスタートポロジの変更(サーバーの追加と削除)を可能にするために、データのパーティション化(パーティション化)の原則が使用されます。
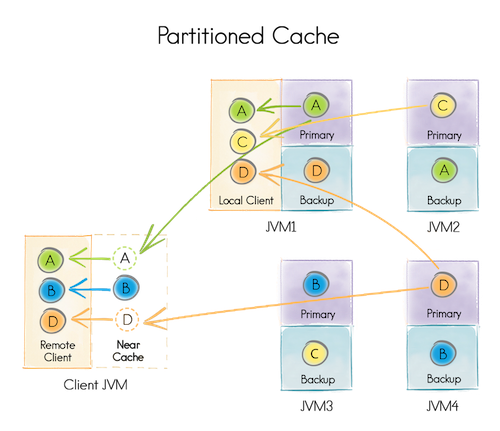
分散キャッシュを作成する場合、パーティションの数が示されます。データは、1024などに分割されます。データを追加する場合、ストレージを担当するパーティションは、たとえばキーハッシュによって選択されます。 キャッシュの構成に応じて、各パーティションを1つまたは複数のサーバーに保存できます。 特定のトポロジ(サーバーのセット)ごとに、パーティションが格納されるサーバーは、事前に決定されたアルゴリズムに従って計算されます。
たとえば、キャッシュを開始するとき、次のことを示します。
- パーティションは4 [A、B、C、D]になります
- 各パーティションは2台のサーバーに保存されます(つまり、それぞれに1つのバックアップがあります)
4つのデータノード[JVM 1-4](データストレージを担当)と1つのクライアントノード[クライアントJVM](データへのアクセスを提供する責任のみ)を実行します。
4つのデータノードのそれぞれは、クライアントノードとして使用できます(つまり、すべてのデータへのアクセスを提供します)。 たとえば、JVM 1はパーティションA、C、Dのデータを取得できましたが、ローカルにはA(プライマリ)とD(バックアップ)しかありません。
特定のパーティションの分散キャッシュのデータノードは、プライマリまたはバックアップにすることも、パーティションをまったく含めないこともできます。
プライマリノードは、パーティション内の要求を処理し、必要に応じて結果をバックアップノードに複製するという点で、バックアップとは異なります。
プライマリノードに障害が発生した場合、バックアップノードの1つがプライマリになります。
プライマリノードに障害が発生した場合、バックアップノードがないと、パーティションは失われたと見なされます。
一部の分散キャッシュは、他のノードにあるデータをローカルにキャッシュする機能を提供します。 たとえば、クライアントJVMはパーティションBをローカルにキャッシュし、変更されるまで追加データを要求しません。
分散キャッシュは、パーティション分割とレプリケート分割に分けられます。
違いは、パーティションキャッシュがクラスター内のパーティションの1つ(または1つ+ Nバックアップ)のインスタンスを格納するのに対して、レプリケートは各データノードにパーティションのインスタンスを1つ格納することです。

パーティション化されたキャッシュを使用して、ボリュームが個々のサーバーの能力を超えるデータを保存し、複製されたデータを「どこでも」同じデータを保存することは理にかなっています。
理解の良い例は、 従業員と 組織の組み合わせです。 多くの従業員がおり、頻繁に変更するため、パーティション化されたキャッシュに保存することをお勧めします。 組織は少数であり、ほとんど変更されないため、レプリケートされたキャッシュに保存することは理にかなっています。
それでは、実装の詳細に移りましょう。
RSDの動作を保証するために、2つのキャッシュが使用されます。1つは複製、もう1つはパーティションです。
レプリケートされたキャッシュ-この場合、システムキャッシュ( ignite-sys-cache
)であり、とりわけ、システムに登録されたRSDに関する情報を保存します。
Partitioned-cache( ignite-atomics-sys-cache
)は、RSDの操作に必要なデータとそのステータスを保存します。
そのため、ほとんどのRSDは次のように作成されます。
- トランザクションが開始されます。
-
ignite-sys-cache
で、DATA_STRUCTURES_KEY
キーを使用して、Map<_, DataStructureInfo>
を取得し(必要に応じて作成)、説明付きの新しい要素(たとえばIgniteAtomicReference
)をIgniteAtomicReference
。 -
ignite-atomics-sys-cache
では、以前に追加されたDataStructureInfo
のキーにより、RSDの状態を担当する要素が追加されます。 - トランザクションがコミットされます。
RSDを作成する最初の要求は新しいインスタンスを作成し、後続の要求は以前に作成されたインスタンスを受け取ります。
IgniteAtomicReferenceおよびIgniteAtomicLong( 簡単な紹介 )
両方のタイプの3番目の初期化ステップは、タイプGridCacheAtomicReferenceValue
またはGridCacheAtomicLongValue
オブジェクトをignite-atomics-sys-cache
GridCacheAtomicLongValue
ignite-atomics-sys-cache
に追加することです。
両方のクラスには、単一のval
フィールドが含まれます。
したがって、 IgniteAtomicReference
への変更:
// , . ref.compareAndSet(expVal, newVal);
...これは、次のprocess
メソッドコードでEntryProcessor
を開始しています。
EntryProcessorは、キャッシュ内のオブジェクトに対して複雑な操作をアトミックに実行できる関数です。
process
メソッドはMutableEntry (キャッシュ内のオブジェクト)を受け入れ、その値を変更できます。
EntryProcessorは、実際には、単一キートランザクションの代替手段です(トランザクションとして実装されることもあります)。
その結果、キャッシュ内の1つのオブジェクトで単位時間あたり1つのEntryProcessor
のみが実行されることが保証されます。
Boolean process(MutableEntry<GridCacheInternalKey, GridCacheAtomicReferenceValue<T>> e, Object... args) { GridCacheAtomicReferenceValue<T> val = e.getValue(); T curVal = val.get(); // expVal newVal — // ref.compareAndSet(expVal, newVal); if (F.eq(expVal, curVal)) { e.setValue(new GridCacheAtomicReferenceValue<T>(newVal)); return true; } return false; }
IgniteAtomicLong
はIgniteAtomicLong
事実上の拡張であるため、そのcompareAndSet
メソッドcompareAndSet
同様の方法compareAndSet
実装されます。
incrementAndGet
メソッドには期待値のチェックはありませんが、単純に追加します。
Long process(MutableEntry<GridCacheInternalKey, GridCacheAtomicLongValue> e, Object... args) { GridCacheAtomicLongValue val = e.getValue(); long newVal = val.get() + 1; e.setValue(new GridCacheAtomicLongValue(newVal)); return newVal; }
IgniteAtomicSequence( 簡単な紹介 )
IgniteAtomicSequence
各インスタンスを作成する場合...
// IgniteAtomicSequence. final IgniteAtomicSequence seq = ignite.atomicSequence("seqName", 0, true);
...彼には識別子のプールが割り当てられています。
// try (GridNearTxLocal tx = CU.txStartInternal(ctx, seqView, PESSIMISTIC, REPEATABLE_READ)) { GridCacheAtomicSequenceValue seqVal = cast(dsView.get(key), GridCacheAtomicSequenceValue.class); // locCntr = seqVal.get(); // upBound = locCntr + off; seqVal.set(upBound + 1); // GridCacheAtomicSequenceValue dsView.put(key, seqVal); // tx.commit();
したがって、課題...
seq.incrementAndGet();
...値カウンタの上限に達するまで、ローカルカウンタを単純にインクリメントします。
境界に達すると、 IgniteAtomicSequence
新しいインスタンスを作成するときと同様に、識別子の新しいプールが割り当てられます。
IgniteCountDownLatch( 簡単な紹介 )
カウンターデクリメント:
latch.countDown();
...は次のように実装されます。
// try (GridNearTxLocal tx = CU.txStartInternal(ctx, latchView, PESSIMISTIC, REPEATABLE_READ)) { GridCacheCountDownLatchValue latchVal = latchView.get(key); int retVal; if (val > 0) { // retVal = latchVal.get() - val; if (retVal < 0) retVal = 0; } else retVal = 0; latchVal.set(retVal); // latchView.put(key, latchVal); // tx.commit(); return retVal; }
カウンターが0に減少するのを待っています...
latch.await();
...は、 連続クエリメカニズムを通じて実装されます。つまり、キャッシュ内のGridCacheCountDownLatchValue
がIgniteCountDownLatch
れるたびに、 GridCacheCountDownLatchValue
すべてのインスタンスにこれらの変更IgniteCountDownLatch
通知されます。
IgniteCountDownLatch
各インスタンスにはローカルインスタンスがあります。
/** Internal latch (transient). */ private CountDownLatch internalLatch;
各通知は、 internalLatch
を現在の値までデクリメントします。 したがって、 latch.await()
は非常に簡単に実装されます。
if (internalLatch.getCount() > 0) internalLatch.await();
IgniteSemaphore( 簡単な紹介 )
許可の取得...
semaphore.acquire();
...次のように発生します。
// for (;;) { int expVal = getState(); int newVal = expVal - acquires; try (GridNearTxLocal tx = CU.txStartInternal(ctx, semView, PESSIMISTIC, REPEATABLE_READ)) { GridCacheSemaphoreState val = semView.get(key); boolean retVal = val.getCount() == expVal; if (retVal) { // . // - node, // . { UUID nodeID = ctx.localNodeId(); Map<UUID, Integer> map = val.getWaiters(); int waitingCnt = expVal - newVal; if (map.containsKey(nodeID)) waitingCnt += map.get(nodeID); map.put(nodeID, waitingCnt); val.setWaiters(map); } // val.setCount(newVal); semView.put(key, val); tx.commit(); } return retVal; } }
返品承認...
semaphore.release();
...新しい値が現在の値より大きいことを除いて、同じように発生します。
int newVal = cur + releases;
IgniteQueue( 簡単な紹介 )
他のIgniteQueue
とは異なり、 IgniteQueue
はignite-atomics-sys-cache
IgniteQueue
ignite-atomics-sys-cache
使用しません。 使用されるキャッシュは、 colCfg
パラメーターによって説明されます。
// IgniteQueue. IgniteQueue<String> queue = ignite.queue("queueName", 0, colCfg);
指定されたアトミックモード (TRANSACTIONAL、ATOMIC)に応じて、さまざまなIgniteQueue
オプションを取得できます。
queue = new GridCacheQueueProxy(cctx, cctx.atomic() ? new GridAtomicCacheQueueImpl<>(name, hdr, cctx) : new GridTransactionalCacheQueueImpl<>(name, hdr, cctx));
どちらの場合も、 IgniteQueue
の状態はIgniteQueue
監視されます:
class GridCacheQueueHeader{ private long head; private long tail; private int cap; ...
AddProcessor
、アイテムを追加するために使用されます...
Long process(MutableEntry<GridCacheQueueHeaderKey, GridCacheQueueHeader> e, Object... args) { GridCacheQueueHeader hdr = e.getValue(); boolean rmvd = queueRemoved(hdr, id); if (rmvd || !spaceAvailable(hdr, size)) return rmvd ? QUEUE_REMOVED_IDX : null; GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(), hdr.capacity(), hdr.collocated(), hdr.head(), hdr.tail() + size, // hdr.removedIndexes()); e.setValue(newHdr); return hdr.tail(); }
...これは、基本的にポインタをキューの末尾に移動するだけです。
その後...
// , // hdr.tail() QueueItemKey key = itemKey(idx);
...新しいアイテムがキューに追加されます。
cache.getAndPut(key, item);
要素は同じ方法で削除されますが、ポインターはtail
ではなくhead
変わります...
GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(), hdr.capacity(), hdr.collocated(), hdr.head() + 1, // hdr.tail(), null);
...アイテムが削除されます。
Long idx = transformHeader(new PollProcessor(id)); QueueItemKey key = itemKey(idx); T data = (T)cache.getAndRemove(key);
GridAtomicCacheQueueImpl
とGridTransactionalCacheQueueImpl
の違いはGridAtomicCacheQueueImpl
GridTransactionalCacheQueueImpl
です。
要素を追加すると、
GridAtomicCacheQueueImpl
まずhdr.tail()
アトミックにインクリメントし、次に受信したインデックスによって要素をキャッシュに追加します。
-
GridTransactionalCacheQueueImpl
は、単一のトランザクションで両方のアクションを実行します。
その結果、 GridAtomicCacheQueueImpl
は高速になりますが、データの整合性に問題がある可能性があります。キューのサイズに関する情報とデータ自体が同時に格納されていない場合、同時に減算されない可能性があります。
poll
メソッド内では、キューに新しい要素が含まれていることがわかりますが、要素自体は存在しません。 これは非常にまれですが、まだ可能です。
この問題は、値のタイムアウトによって解決されます。
long stop = U.currentTimeMillis() + RETRY_TIMEOUT; while (U.currentTimeMillis() < stop) { data = (T)cache.getAndRemove(key); if (data != null) return data; }
5秒のタイムアウトでは不十分で、キュー内のデータが失われる実際のケースがありました。
結論の代わりに
分散キャッシュは、実際には、クラスターに統合された多くのコンピューターのフレームワーク内のConcurrentHashMapであることに注意してください。
分散キャッシュを使用して、多くの重要で複雑な、しかし信頼できるシステムを実装できます。
特定の実装例は、分散データ構造ですが、一般に、膨大な量のデータをリアルタイムで保存および処理するために使用され、新しいノードを追加するだけでボリュームまたは処理速度が向上する可能性があります。