
ストレージシステム(DSS)のパフォーマンスを向上させ、待ち時間を短縮する1つの方法は、着信トラフィックを分析するアルゴリズムを使用することです。
一方では、ストレージシステムへの要求はユーザーに大きく依存しているため、ほとんど予測できませんが、実際にはそうではありません。
ほとんどすべての人の朝は同じです。私たちは起きて、服を着て、洗って、朝食をとり、仕事に行きます。 就業日は、職業によって異なりますが、誰にとっても異なります。 また、ストレージの負荷は毎日同じですが、稼働日はストレージの使用場所とその典型的なワークロードによって異なります。
私たちのアイデアをよりよく視覚化するために、ニコライ・ノソフに関する子どもたちの物語のキャラクターの画像を使用しました。 この記事では、主人公はDunno(ランダムな読み)とZnayka(シーケンシャルな読み)になります。

ランダム読み取り(ランダム読み取り)-Dunno 誰もダンノに対処したくない。 彼の行動は論理に反します。 C-Minerなどのメモリからのプロアクティブサンプリングの高度なアルゴリズムなど、一部のアルゴリズムは依然としてその動作を予測しようとしますが、これについては後で詳しく説明します。 これらは機械学習アルゴリズムです。つまり、ストレージリソースを要求し、常に成功するとは限りませんが、プロセッサの計算能力の途方もない発展により、今後ますます使用されます。
Dunnoだけがストレージに来る場合、SSDベースのストレージ(オールフラッシュストレージ)が最適なソリューションになります。

シーケンシャル読み取り(シーケンシャル読み取り)-Znayka 。 厳格で退屈で予測可能。 この動作のおかげで、彼はストレージの親友と考えることができます。 Znaykaでうまく機能する先読みアルゴリズムがあり、必要なデータを事前にRAMに入れて、リクエストのレイテンシを最小化します。
ブレンダー効果
一貫した読み取りは予測可能ですが、読者は反対するかもしれません。「しかし、ブレンダー効果についてはどうですか<pic。 1>、これはトラフィックの混合の結果として連続したリクエストをランダムにしますか? ''
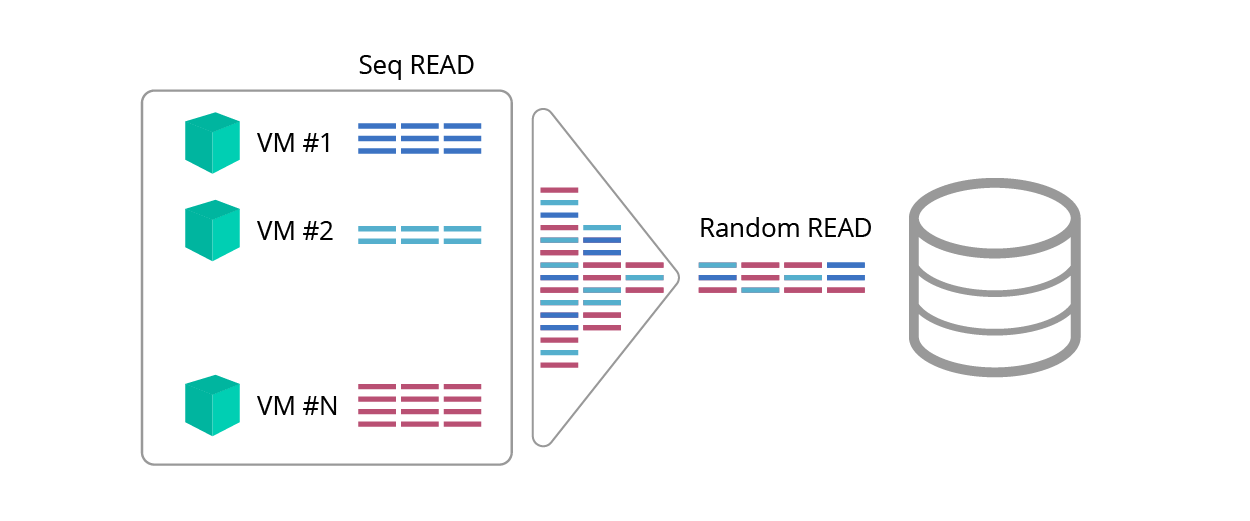
図 1.ブレンダー効果
このような混乱の結果、Znaykaは本当にDunnoになりますか?

Znaykaの助けには、先読みアルゴリズムと、さまざまなタイプの要求を識別できる検出器があります。
先読み
アクセス時間を短縮し、スループットを向上させるように設計された主な最適化方法の1つは、先読み技術の使用です。 このテクノロジーにより、すでに要求されたデータに基づいて、次に要求されるデータを予測し、このデータにアクセスする前に、低速のストレージメディア(たとえば、ハードドライブ)から高速(たとえば、RAMおよびソリッドステートドライブ)に転送できます(図2)。
ほとんどの場合、先読みは順次操作に使用されます。
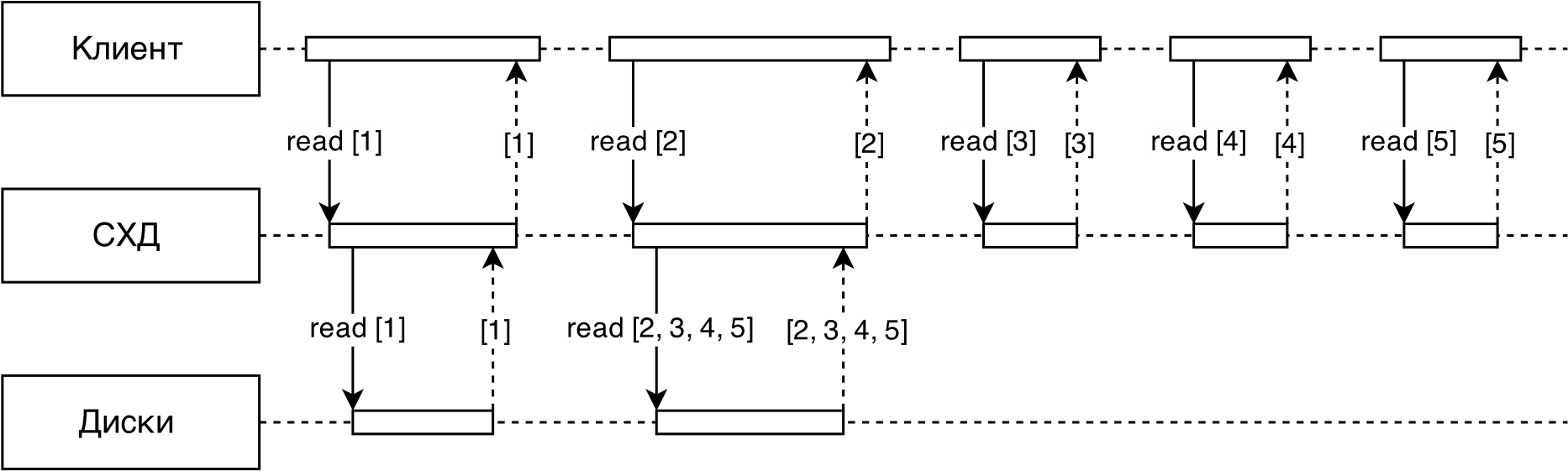
図 2.先読み
先読みアルゴリズムの作業は、通常2つの段階に分けられます。
- すべての要求のストリーム内の順次読み取り要求の検出。
- 先にデータを読み取る必要性について判断し、ボリュームを読み取ります。
RAIDIXでの検出器の実装
RAIDIXの順読みアルゴリズムは、接続されたアドレス空間の間隔に対応する範囲の概念に基づいています。
範囲はペアで示されます( )、リクエストのアドレスと長さに対応し、 。 それらはランダムに分割され、その長さは特定のしきい値よりも短く、連続しています。 同時に追跡 ランダム範囲以上 連続。
検出アルゴリズムは次のように機能します。
1.着信読み取り要求ごとに、最も近い範囲がstrideRange radiusで検索されます。
1.1。 何も見つからなかった場合、リクエストの特性に対応するアドレスと長さで新しいランダム範囲が作成されます。 この場合、既存の範囲の1つをLRUに置き換えることができます。
1.2。 範囲が1つある場合は、間隔が延長されてクエリが追加されます。 ランダム範囲はシリアル範囲に変換できます。
1.3。 2つの範囲(左と右)がある場合、それらは1つに結合されます。 この操作の結果の範囲もシリアルに変換できます。
2.要求がシーケンシャル範囲にある場合、この範囲に対して先読みを実行できます。
先読みオプションは、流量とブロックサイズによって異なる場合があります。
図3は、RAIDIXに実装されている適応先読みアルゴリズムを模式的に示しています。

図3 先読みスキーム
クライアントからストレージシステムへのすべてのリクエストは最初にディテクターに送られ、そのタスクはシーケンシャルストリームを分離することです(シーケンシャルリクエストとランダムリクエストを区別するため)。
さらに、各連続ストリームについて、その速度が決定されます とサイズ -ストリーム内のリクエストの平均サイズ(通常、ストリーム内のすべてのリクエストは同じサイズです)。
各スレッドは先読みオプションにマップされます。 。
したがって、先読みアルゴリズムを使用すると、「I / Oブレンダー」効果に対処でき、シーケンシャルリクエストに対しては、RAMのパラメーターに匹敵するスループットとレイテンシを保証します。
したがって、ZnaykaはDunnoを打ち負かす!

ランダム読み取りパフォーマンス
ランダム読み取りのパフォーマンスを向上させるにはどうすればよいですか?
これらの目的のために、VintikとShpuntikの開発者は、より高速なメディア、つまりSSDとハイブリッドソリューション(ティアリングまたはSSDキャッシュ)の使用を提案しています。

ランダムクエリアクセラレータ-C-Miner先読みアルゴリズムも使用できます。
これらすべての方法の主なタスクは、Dunnoを「高速」な車に乗せることです:-)問題は、車を運転できるようにする必要があることであり、Dunnoは予測不可能です。

Cマイナー
ランダムクエリの先読みに使用される最も興味深いアルゴリズムの1つは、シーケンシャルに要求されたデータブロックのアドレス間の相関の検索に基づくC-Minerです。
このアルゴリズムは、対応するファイルを読み取る前またはDBMSインデックス内のレコードを見つける前にファイルシステムメタデータを要求するなど、要求間の意味関係を検出します。
C-Minerの作業は、次の手順で構成されています。
- I / O要求アドレスシーケンスでは、一定のサイズのウィンドウに制限された短いサブシーケンスが繰り返し検出されます。
- 取得されたサブシーケンスからサフィックスが抽出され、出現頻度に従って結合されます。
- 抽出されたサフィックスとサフィックスチェーンに基づいて、{a→b、a→c、b→c、ab→c}の形式のルールが生成されます。このルールは、相関領域からのアドレス要求が先行するデータブロックを記述します。
- 結果のルールは、信頼性に従ってランク付けされます。
C-Minerアルゴリズムは、データがほとんど更新されないストレージシステムに適していますが、小さなバッチで要求されることがよくあります。 このようなユースケースを使用すると、長期間有効期限が切れないルールセットを作成でき、最初のクエリ(ルールが作成される前に出現した)の実行を遅くすることもありません。
従来の実装では、多くの場合、信頼性の低いルールが多く発生します。 この点で、先読みアルゴリズムはランダムクエリではかなり不十分です。 最も一般的なクエリは、SSDやNVMEディスクなどの生産性の高いドライブに当てはまるハイブリッドソリューションを使用する方がはるかに効率的です。
SSDキャッシュまたはSSDピアリング?
どちらのテクノロジーを選択するのがよいかという疑問が生じます:SSDキャッシュまたはSSDピアリング? ワークロードの詳細な分析は、この質問に答えるのに役立ちます。
SSDキャッシュの概要を図4に示します。ここで、要求はまずRAMに送られ、次に要求の種類に応じて、SSDキャッシュまたはメインメモリに強制的に入れられます。
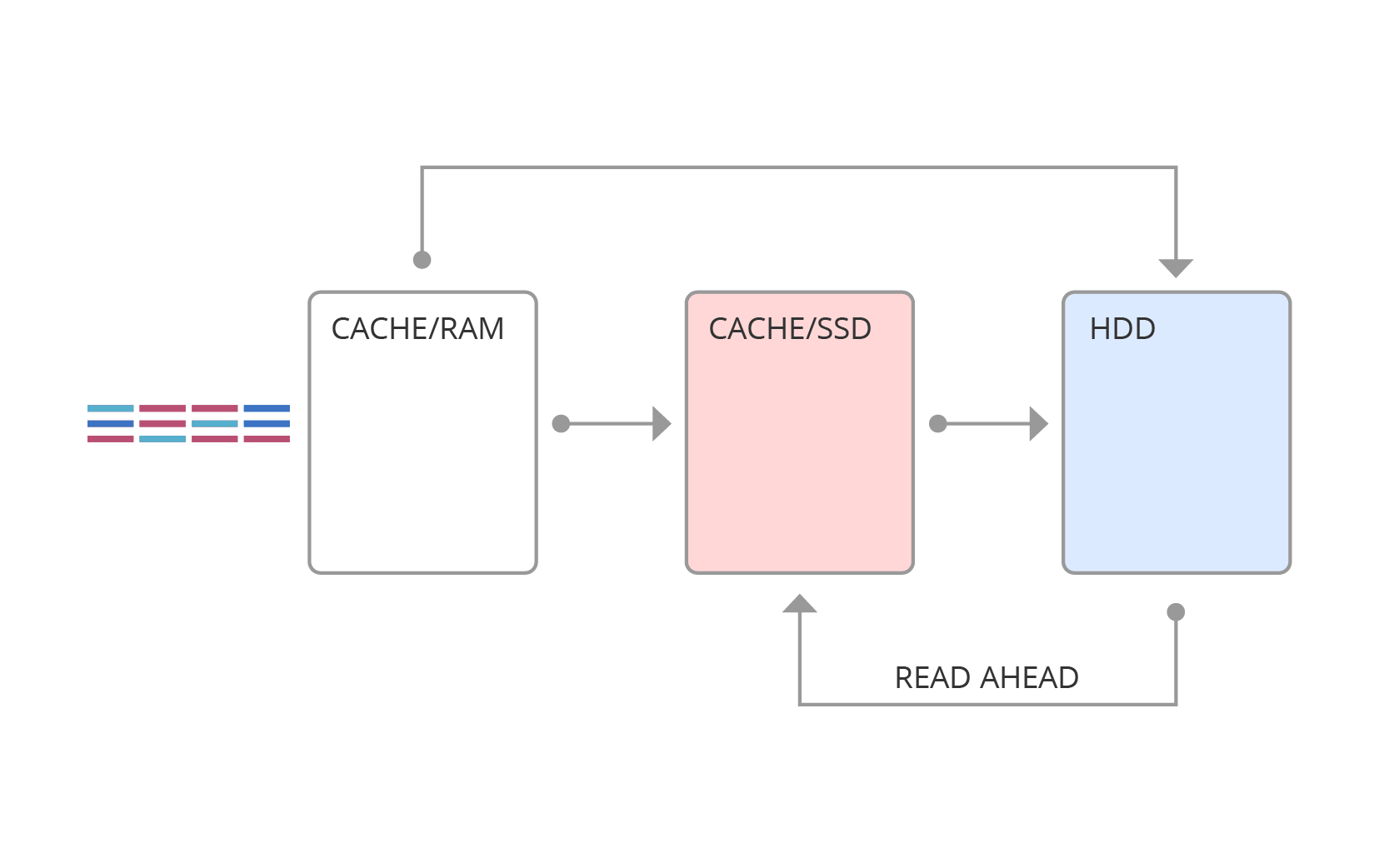
図 4. SSDキャッシュ
SSDティアリングの構造は異なります(図5)。 疲れている場合、ホットエリアの統計が保持され、一定の時間に、ホットデータがより高速なメディアに転送されます。

図 5. SSDの破損
SSDキャッシュとSSDティアリングの主な違いは、「ホット」データがキャッシュとディスクの両方に保存されるSSDキャッシュとは異なり、ティアリングのデータが複製されないことです。
次の表は、特定のソリューションの選択基準を示しています。
| 引き裂き | キャッシュ | |
|---|---|---|
| 調査方法 | 将来価値の予測 | データ内の地域の特定 |
| 仕事量 | 予測可能。 弱い変化 | 動的、予測不能。 即時の反応が必要 |
| データ | 複製されない(ディスク) | 複製(バッファー) |
| データ移行 | オフラインアルゴリズム、再配置ウィンドウ。 データを移動するための時間パラメータがあります | オンラインアルゴリズム。データはすぐにプッシュされ、キャッシュされます。 |
| 研究方法 | 回帰モデル、予測モデル、長期記憶 | 短期記憶、変位アルゴリズム |
| 相互作用 | HDD SSD | RAM-SSD、先読みアルゴリズムを介してSSDとやり取り |
| ブロックする | 大(例:256 MB) | 小さい(例:64 KB) |
| アルゴリズム | 転送時間とメモリアドレスの統計的特性に応じた機能 | キャッシュワイプおよびフィルアルゴリズム |
| 読み取り/書き込み | ランダム読み取り | 書き込みを含む、シーケンシャル読み取りを除くすべてのリクエスト(ほとんどの場合) |
| モットー | 難しいほど良い | シンプルなほど良い |
| 目的のデータを転送するための手動モード | 可能です | 不可能-キャッシュロジックに反する |
ハイブリッドソリューションの核心は、何らかの形で将来の負荷を予測することです。 引き裂きでは、過去から未来を予測しようとしています。SSDキャッシュでは、最近のクエリと頻度の高いクエリを使用する可能性は、長期間使用した頻度の低いクエリよりも高いと考えています。 いずれにしても、アルゴリズムの基礎は「過去の」負荷の研究です。 たとえば、新しいアプリケーションが動作し始めるなど、負荷の性質が変化した場合、アルゴリズムが変化に適応するのに時間がかかります。
ダンノは、ハイブリッドソリューションが未知の新しい地域でうまく管理されていないことを責めるべきではありません(彼はそのような性格を持っています-ランダムです)!

しかし、正しい「予測」を使用しても、ハイブリッドソリューションのパフォーマンスは低くなります(SSDが提供できる最大パフォーマンスよりも大幅に低くなります)。
なんで? 答えは以下です。
SSDキャッシュから予想されるIOPSはいくつですか?
2TBのSSDキャッシュがあり、キャッシュされたボリュームのサイズが10TBだとします。 一部のプロセスは、均一な分布でボリューム全体をランダムに読み取ることがわかっています。 また、SSDキャッシュから200 Kの速度でIOPSを読み取り、3 K IOPSのキャッシュされていない領域から読み取ることができることもわかっています。 キャッシュがすでにいっぱいで、読み取り可能な10の2 TBが含まれているとします。 どのくらいのIOPSを受け取りますか? 明らかな答えが思い浮かびます:200K * 0.2 + 3K * 0.8 = 42.4K。 しかし、本当に簡単なのでしょうか?
少し数学を適用して、それを理解してみましょう。 私たちの計算は実際の実践からいくらか逸脱していますが、評価目的には完全に受け入れられます。
だの:
読み取りデータ(または要求)のx%がSSDキャッシュにある(処理される)ようにします。
SSDキャッシュはu IOPSの速度でリクエストを処理すると考えています。 また、HDDへのリクエストはv IOPSで処理されます。
解決策:
まず、iodepth(要求キューの深さ)= 1の場合を考えます。
1の読み取りスペース全体のサイズを取得します。キャッシュ内の(処理される)データ(要求)の割合はx / 100になります。
1秒で処理する クエリ。 その後、それらの キャッシュで処理され、残りは HDDに移動します。 これは、均一な分布で読み取りが行われるという事実のためです。
取る SSDに送られたリクエストに費やした合計時間ですが、 HDDへのリクエストに費やされた時間。
今は1秒しか考慮していないので、 (秒)。
次の等式(1)があります。 。 単位の使用:IOPS *秒+ IOPS *秒= IO。
また、次のものもあります(2)。 。 エクスプレスI: 。
(2)Iから得られた(1)を代入します。 。 エクスプレス 与えられた 。
知ってる その後、私たちは知っていると 。
時代を手に入れた そして 、今では(1)でそれらを置き換えることができます: 。
平等を単純化する: 。
いいね! これで、iodepth = 1でのIOPSの数がわかりました。
iodepth> 1の場合はどうなりますか? これらの計算は不正確になりますが、かなり正確ではありません。 それぞれがiodepth = 1である、または異なる方法を考えるいくつかの並列フローを検討することができますが、十分なテスト期間で、これらの不正確さは滑らかになり、画像はiodepth = 1と同じになります。結果は依然として実際の画像を反映します。
そこで、「IOPSの数は?」という質問に答えて、次の式を適用します。
一般化
しかし、均一な分布ではなく、生活に近い分布がある場合はどうでしょうか?
たとえば、パレート分布を考えます(80/20ルール-要求の80%が「最もホットな」データの20%に送られます)。
この場合、スペースのサイズとSSDのサイズに依存しないため、結果の式も機能します。 SSDで処理されるリクエスト(この場合、リクエスト!)の何%を知ることだけが重要です。
SSDキャッシュのサイズが合計読み取りスペースの20%であり、これらの最もホットなデータの20%が含まれている場合、要求の80%がSSDに送られます。 次に、式I(80、200000、3000)≈14150 IOPSに従います。 はい、おそらくあなたが思ったよりも少ないでしょう。
u = 200000、v = 3000のI(x)をプロットしてみましょう。
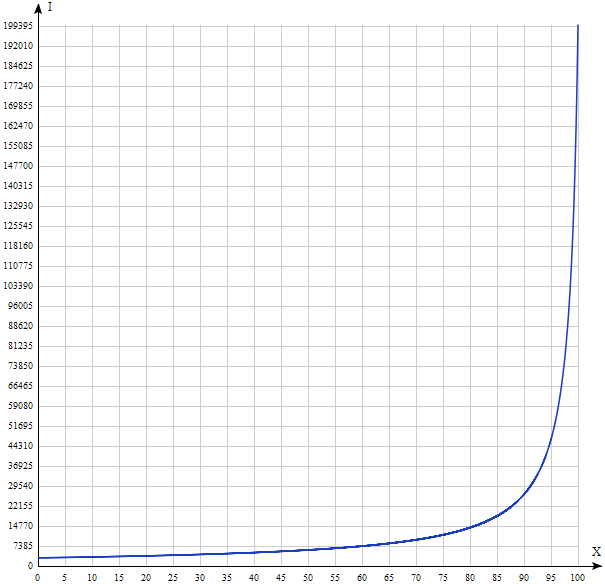
結果は直感的なものとは大きく異なります。 したがって、高速車にキーをダンノに引き渡すと、システムのパフォーマンスが常に向上するとは限りません。 上記のグラフからわかるように、オールフラッシュソリューション(すべてのドライブがソリッドステートである場合)のみが、SSDドライブから最大限に「絞り出された」ランダム読み取りを実際に加速できます。 それは、Dunnoではなく、もちろん、データストレージシステムの開発者ではなく、単純な数学のせいです。