
Splunkは、ほぼすべてのソースからログを収集し、分析レポート、ダッシュボード、組み込みの検索クエリ言語SPLに基づいたアラートを構築できるという事実に加えて、 以前の記事で書いたように、Splunkにはまだ無料のアドオンとアプリケーションの非常に大きなデータベースがあります。
今日は、ユーザー、アプリケーションの観点から最も人気のあるものの1つ、Splunk Machine Learning Toolkitを見ていきます。
Splunk Machine Learning Toolkitは、Splunk固有のタスクとデータタイプに特化されていることをすぐに言わなければなりません。 教師なしで学習アルゴリズムのみをサポートし、非常に具体的なアプリケーションを備えています。
Splunkは主にマシンデータに焦点を当てているため、Machine Learning Toolkitで実装されるケースはこの特異性を対象としています。 次に、各ケースを詳細に調べますが、最初にインストールについて簡単に説明します。
入手先
アプリケーション自体はSplunkbaseから無料でダウンロードできますが、すべての機械学習アルゴリズムはPythonを搭載しているため、インストール前にPython for Scientific Computingアドオンをインストールする必要があります。これは無料で簡単かつ迅速にインストールできます。 すべての手順はこちらです。
アプリケーションの可能性
このアプリケーションのSplunkは、基本的な統計アルゴリズムで機械学習機能を使用する6つのケースを実装しました。
1.数値フィールドを予測する
このモジュールは、このイベントの他のフィールドの値の組み合わせに基づいて、数値フィールドの値を予測します。
例:
会社内のさまざまな情報システム(CRM、CloudDrive、WebMail、リモートアクセスなど)を使用しているユーザー数に関するデータが毎日あります。
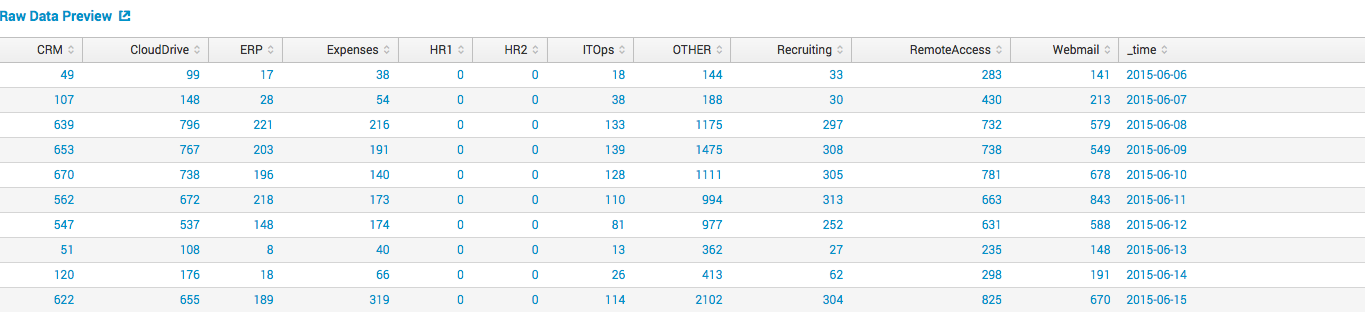
Splunkは、このすべてのデータを図のように簡単に収集して整理できます。 他のフィールド(CRM、CloudDrive、HR1、WebMail)のデータに基づいてVPNユーザーの数を予測したいため、線形回帰に基づいてモデルを構築できます。
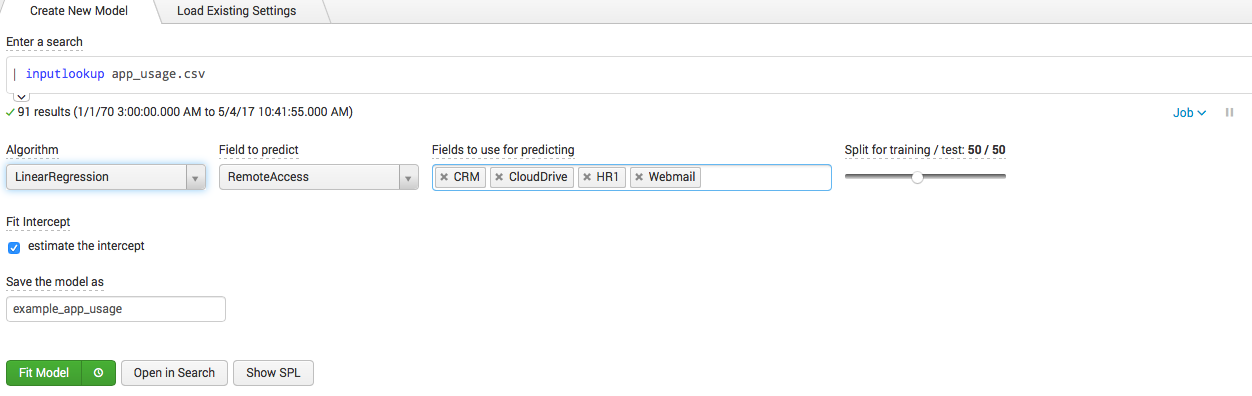
依存フィールドとアルゴリズム自体を変更できることは明らかです。 線形回帰に加えて、より一般的なアルゴリズムがいくつかあります。
次に、モデルを押して、すべての計算をテーブル形式として取得します。
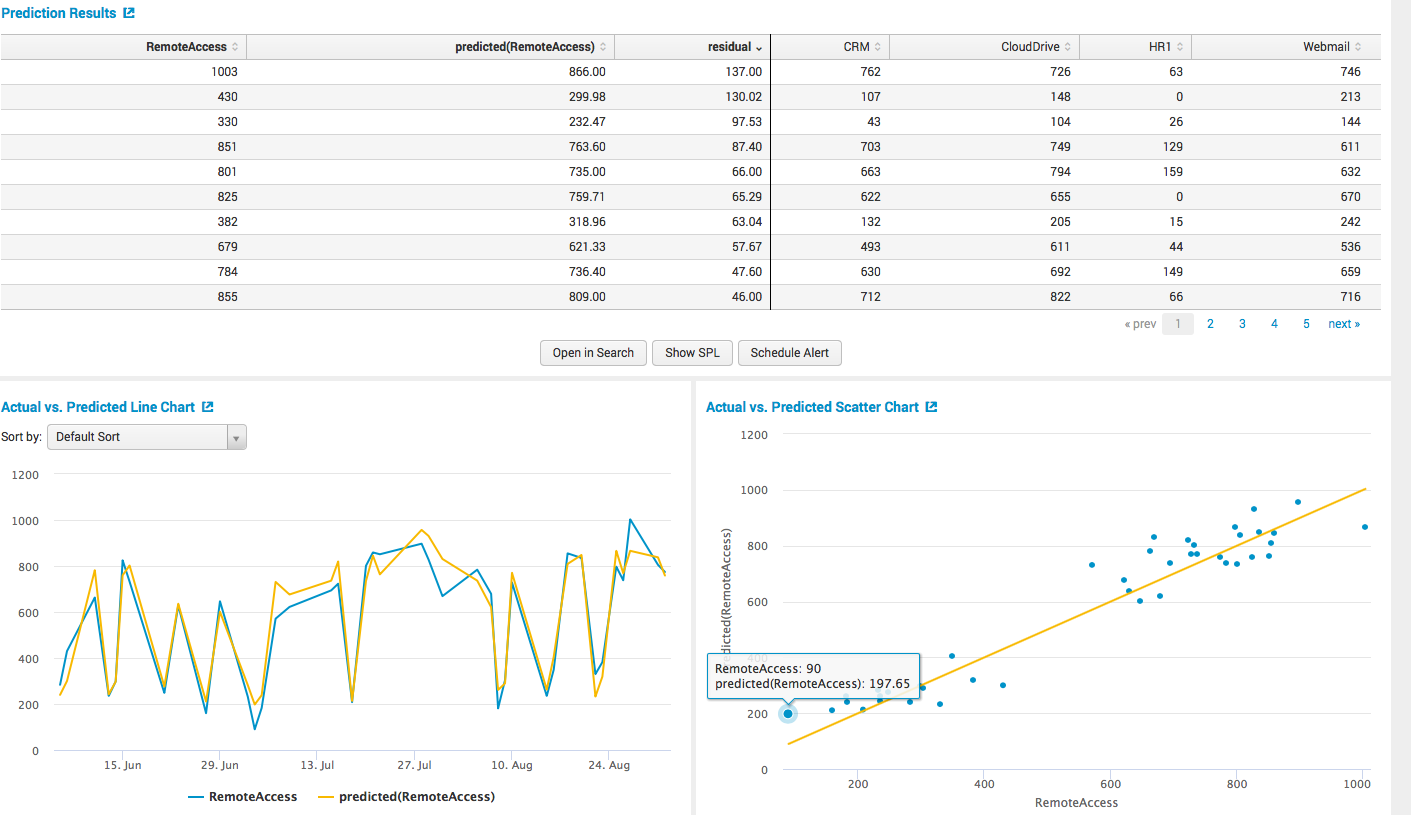
グラフィカルに。
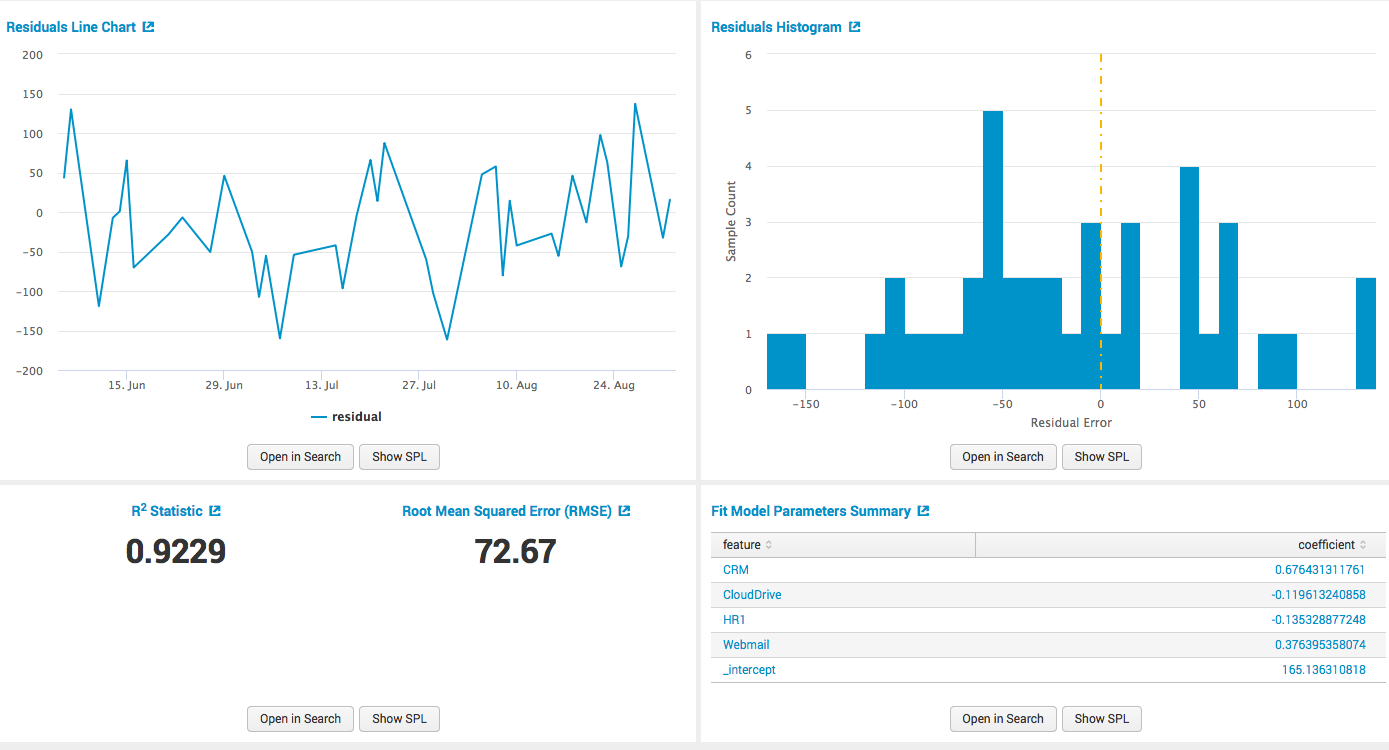
さらに、モデルを作成するときに、その結果を他のクエリに適用したり、ダッシュボドラに配置したり、アラートを作成したりできます。
2.数値の外れ値を検出する
このモジュールは、このフィールドの以前のデータに基づいて異常値を検出します。
例:
10分ごとのクライアントリクエストに対する最大サーバー応答時間に関するデータがあり、Splunkは1つまたは複数のサーバーから簡単に収集し、タブレットの形式で表示します。
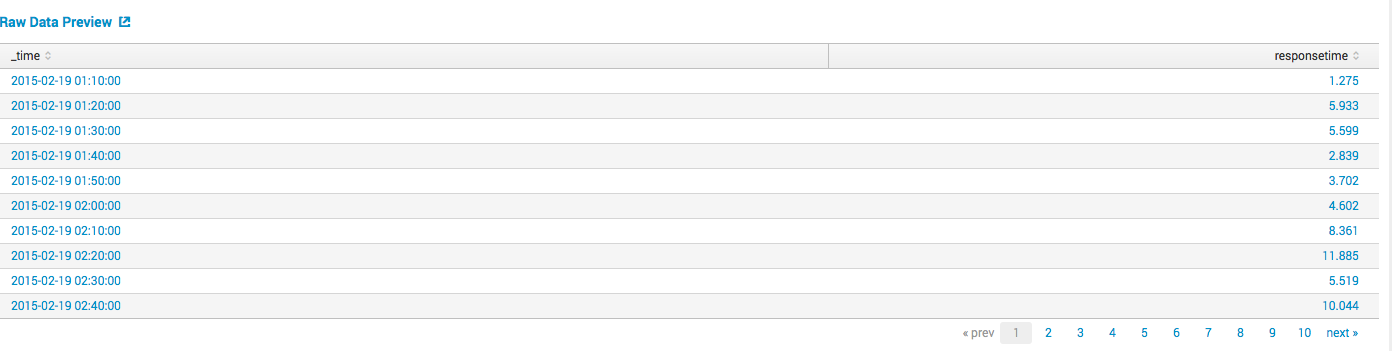
異常、つまり、履歴データに基づいて応答時間が非常に長い、または非常に速いイベントを見つけたいと考えています。 Splunkは、異常を検出するための3つの変動の尺度を提供します(SD-標準偏差、IQR-四分位範囲、狂った中央値絶対偏差)。 標準偏差に基づいてモデルを作成します。

次に、結果を取得します。
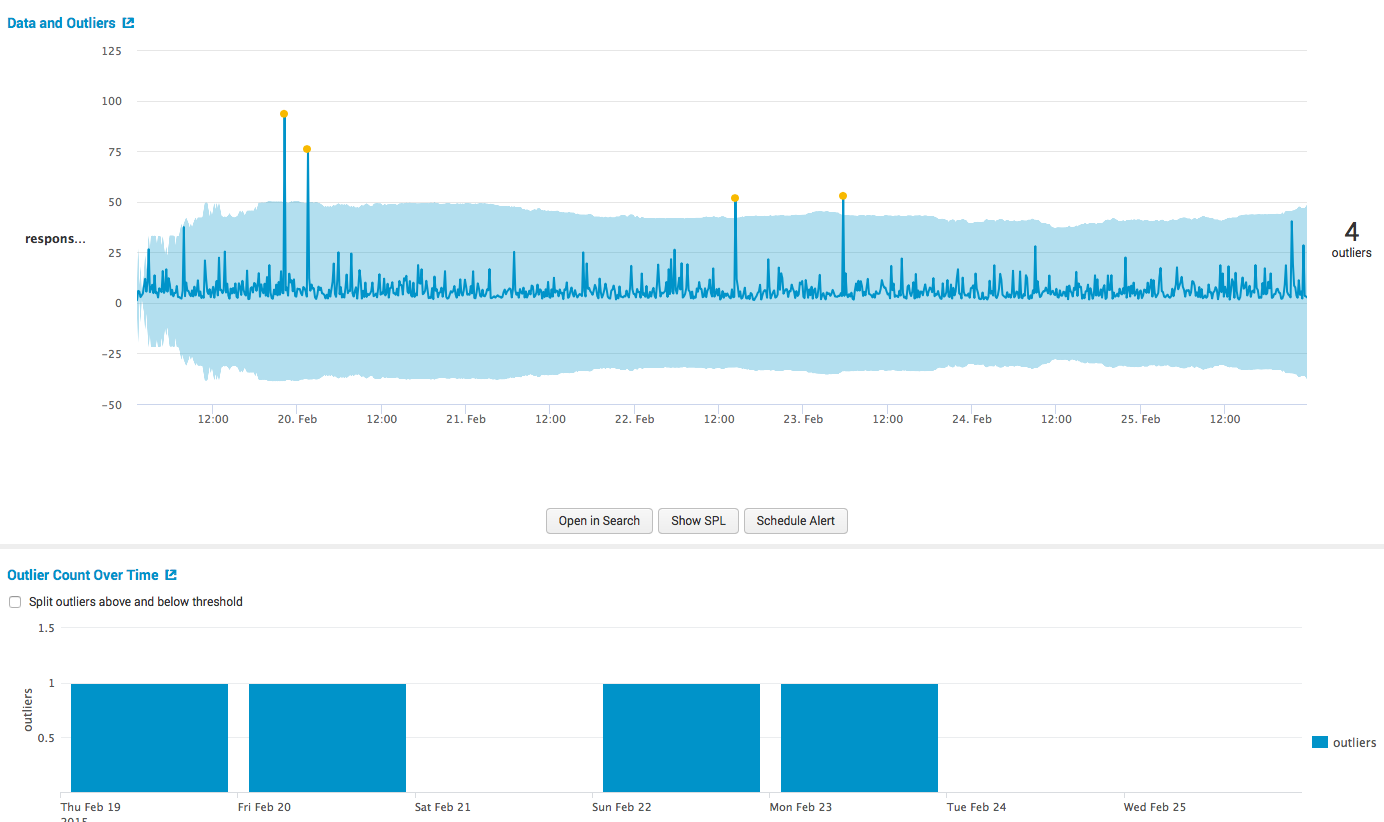
そして、表形式とグラフィカル形式の両方での主要な計算。
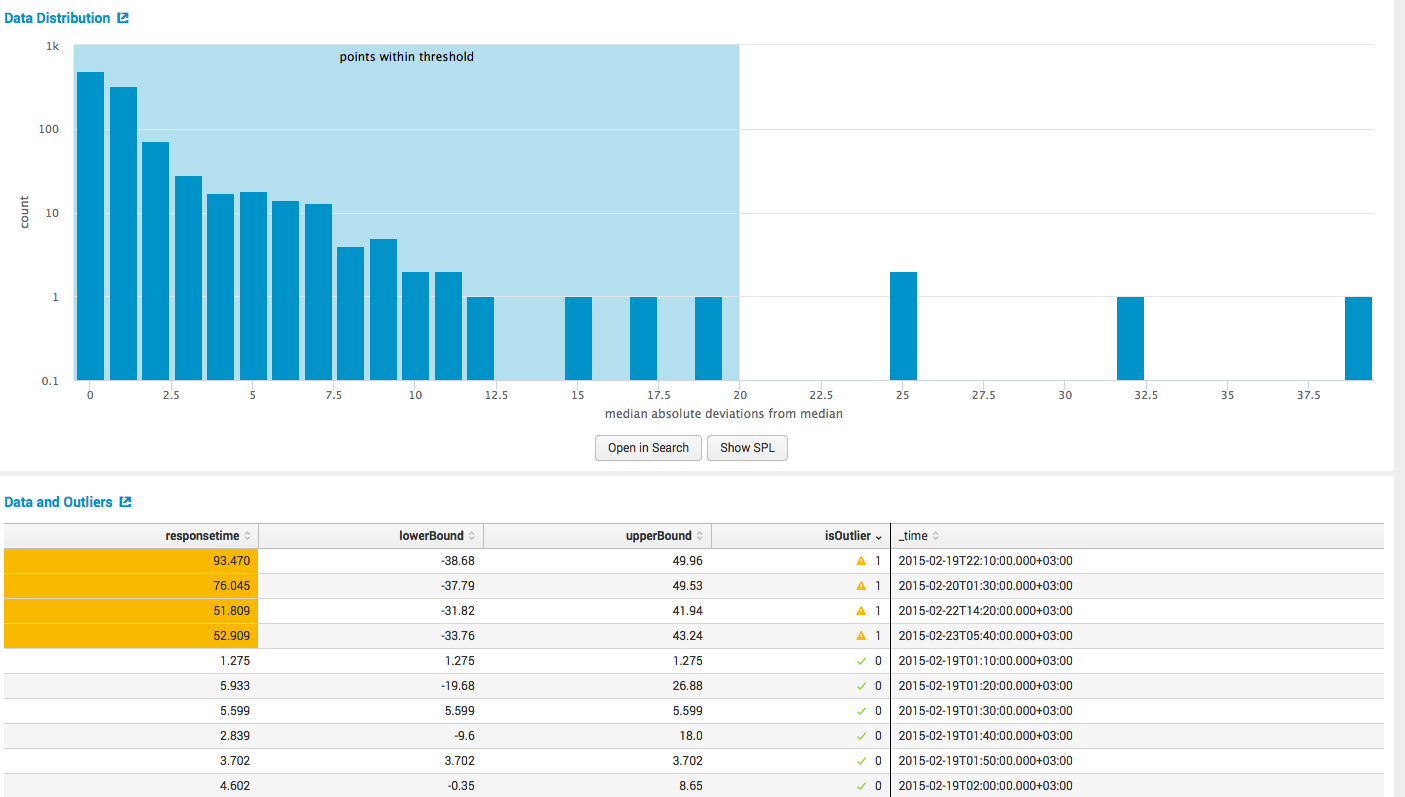
3.予測時系列
このモジュールは、時系列を予測するように設計されています。つまり、過去のデータに基づいて将来のデータを予測します。
主なアルゴリズムは次のとおりです。
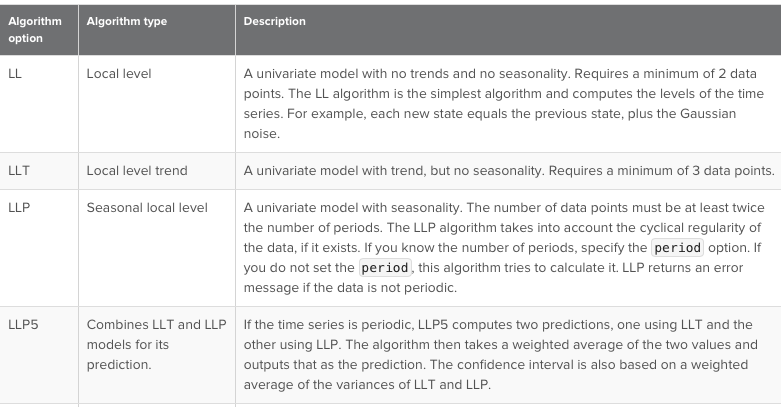
例:
ユーザー、サーバー、またはゲートウェイによって転送されたトラフィックの量に関するデータがあります。実際、どこでもかまいません。
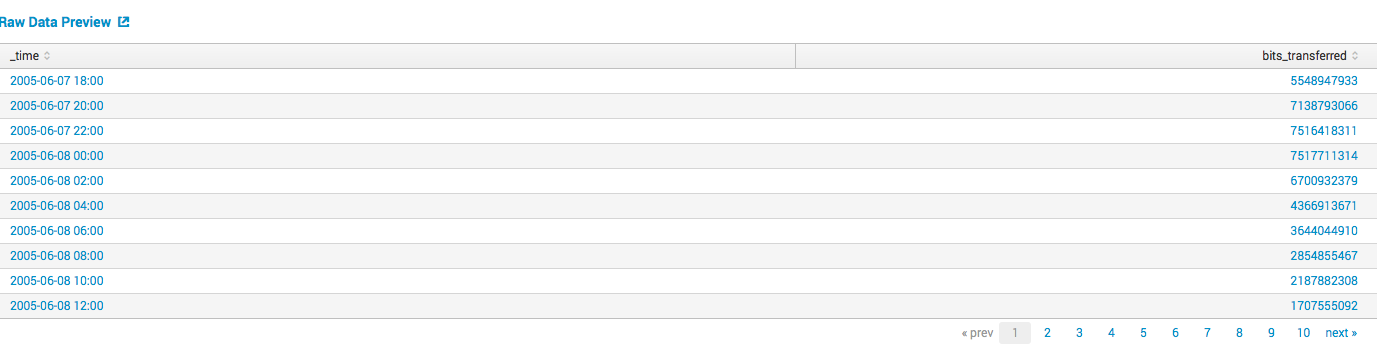
将来のトラフィック量を予測したいと思います。
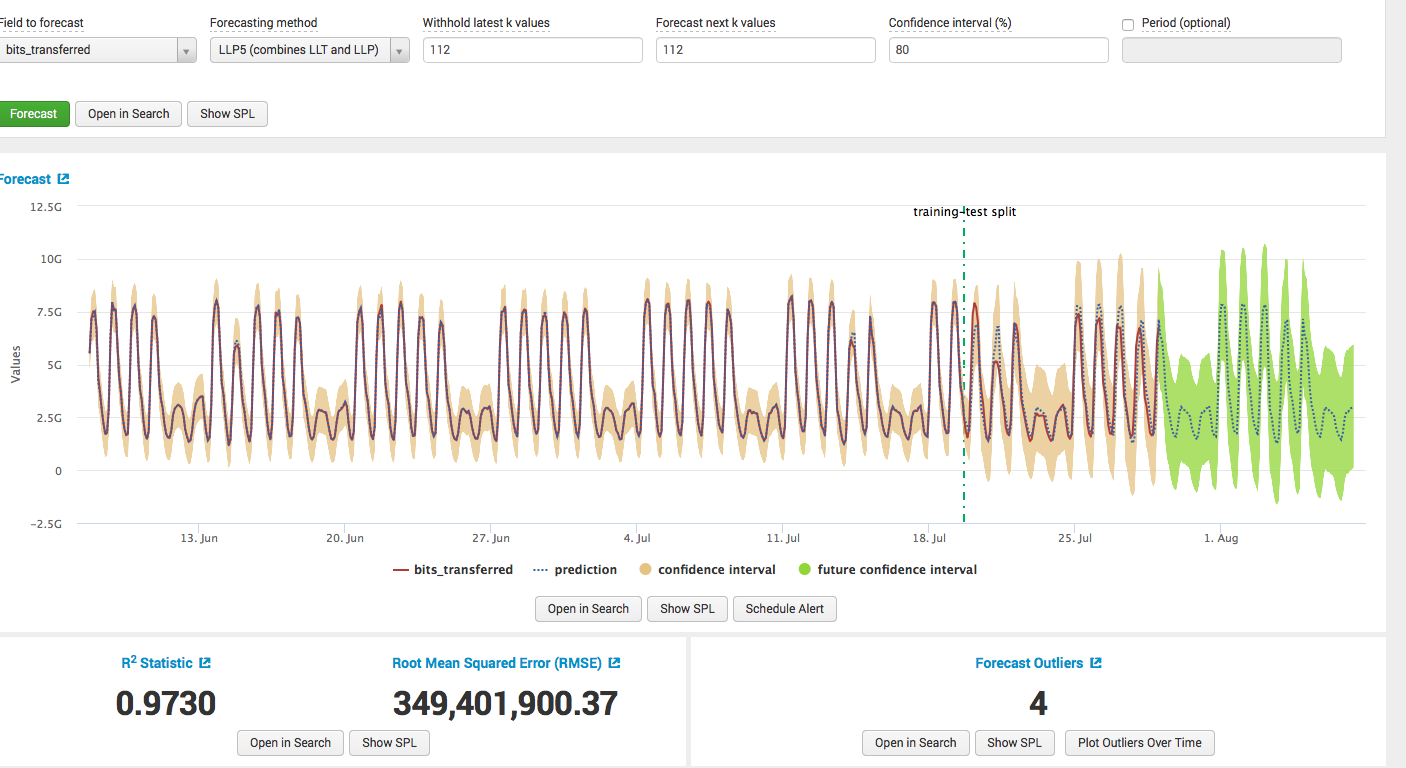
モデルを作成します。アルゴリズムを選択し、トレーニングセットを選択し、予測の値の数を選択し、モデルの品質に関する計算で結果を取得します。
4.カテゴリーフィールドの予測
このモジュールは、カテゴリカル、つまりこのイベントの他のフィールドに基づいた定性変数を予測するように設計されています。
主なアルゴリズムは次のとおりです( ここで説明します )。
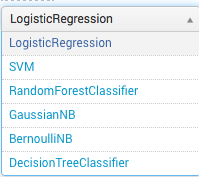
例:
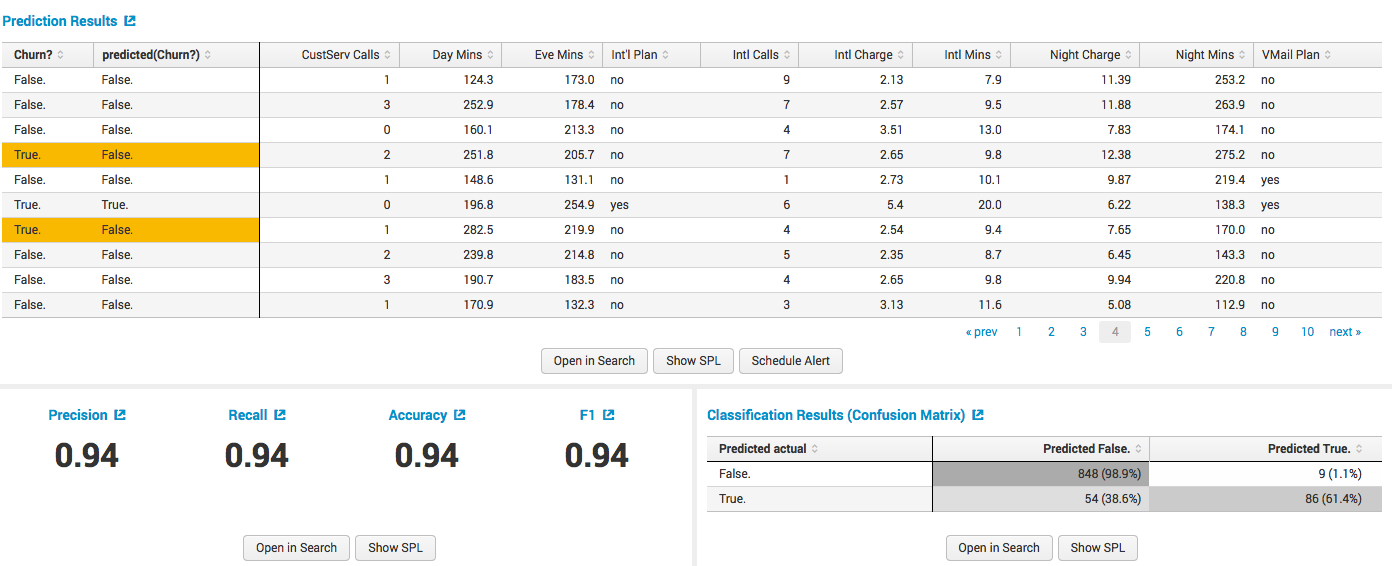
顧客情報(内線と外線の通話数、コスト、夜間通話、特別料金など)を含む通信事業者データがあります。 このデータの主なものは、 チャーンフィールドですか? それは、クライアントが私たちを去った、または留まったことを示しています。 これが、上記のフィールドに基づいて予測したいものです。

モデルを作成します。アルゴリズムを選択し、従属変数、トレーニングサンプルのサイズ、およびアルゴリズムに応じて他の可能なパラメーターを選択します。

モデルの品質に関するデータを含むトレーニング結果を受け取ります。
5.カテゴリー外れ値の検出
このモジュールは、イベントのフィールド値の分析に基づいて異常を検索するように設計されています 。異常を判断するためのアルゴリズムはこちらです。
例:
スーパーマーケットでの購入に関する情報を含むデータがあり、異常なトランザクションを見つけたいと考えています。
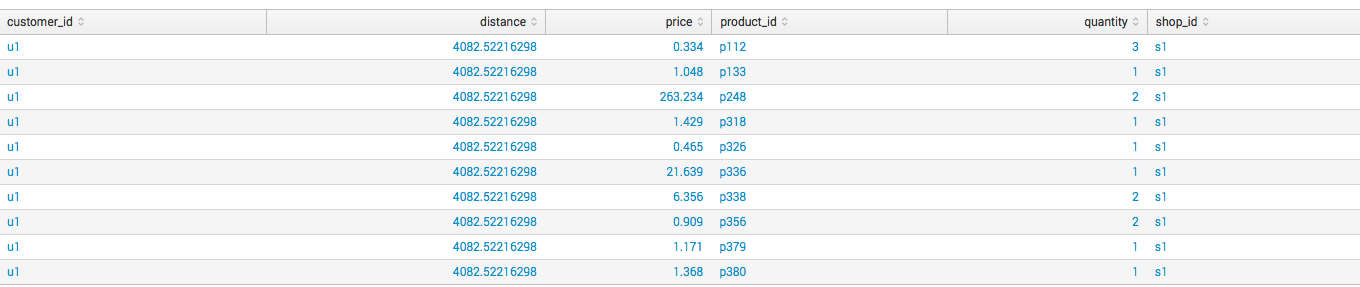
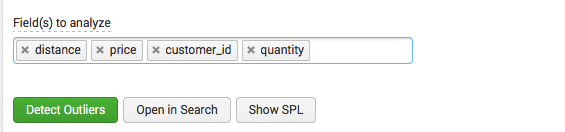
異常を特定するフィールドを選択します。
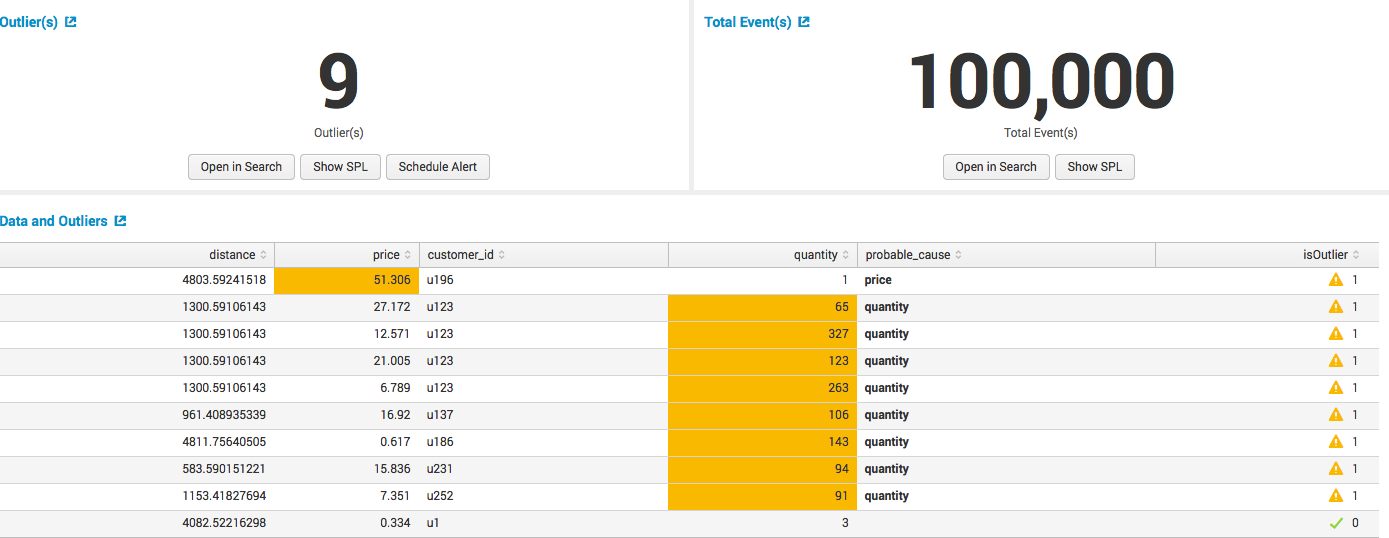
見つかった異常で結果を取得します。
6.数値イベントのクラスター化
イベントのクラスタリングを可能にするモジュール。 使用頻度の観点から、おそらく最も弱いモジュールです。
例:
さまざまな情報システムを使用しているユーザー数に関する例1のデータがあります。 それらをクラスター化するように定義したいと思います。
モデル:クラスタリングのフィールドを選択し、それらを正規化し、アルゴリズムと依存フィールドを選択し、クラスターの数も示します。
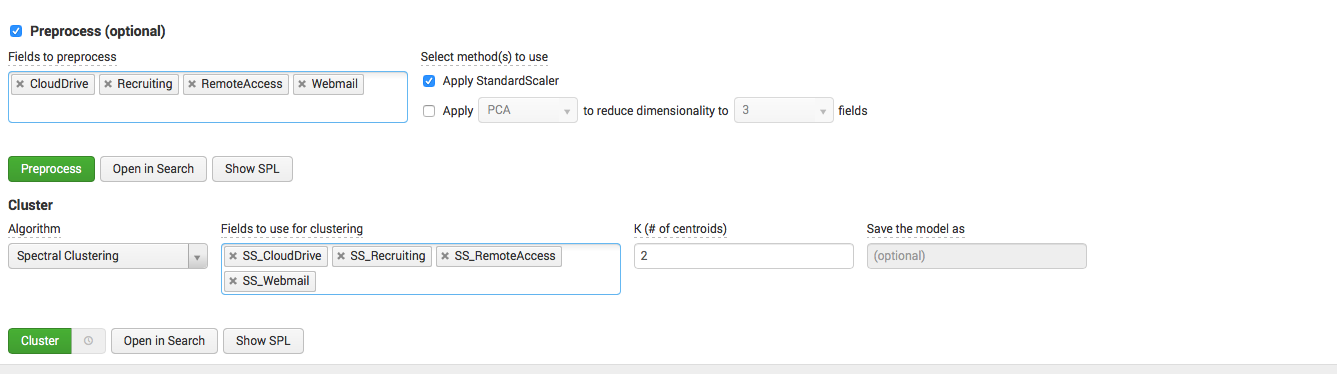
何が起こったのか見てみましょう:
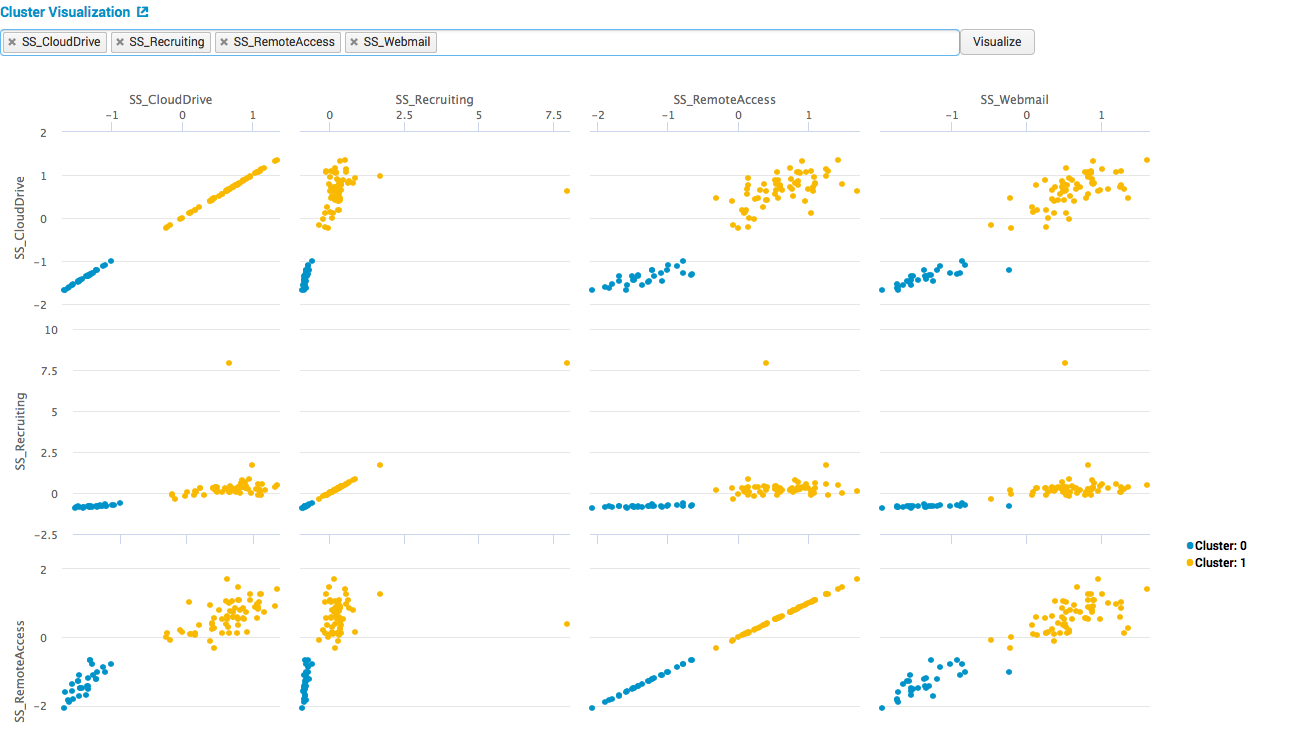
写真では2つの明確なクラスターが表示されていますが、結果を解釈すると、最初のクラスターは平日であり、選択したシステムには多くのユーザーがいて、2番目は週末であり、ユーザーはほとんどいないことがわかります。
このモジュールの弱点は、モデル作成の品質に関するメトリックがないことにもあります。
まとめ
- Splunkは、さまざまなシステムの膨大な数のログから各モデルの入り口に入るこれらすべてのプレートを作成するという点で非常に優れており、実際にはそれほど単純ではありません(収集、保存、処理)
- 迅速な統計分析、つまり基本的な機械学習操作が必要な場合-どこに行く必要もありません
- これは最終結果ではなく、別のワークフロー、たとえばアラート、またはダッシュボードへの移動があります
- SplunkにはオープンAPIがあり、十分なアルゴリズムがない場合は、オープンPythonライブラリからそれらを読み込むことができます。その方法に関する情報はこちら
- Splunkは、たとえば同じAPIを使用して、結果を送信することもできます。