空白
次のルールを受け入れます。
- エージェントは最初に「クロス」をプレイします。
- エージェントは、最大の価値を持つ決定のみを行います。
- 5%の確率で、エージェントは調査の決定を行います。
- エージェントに勝った場合にのみ、彼は報酬を受け取ります。
次のステップは、エージェントの値関数を準備することです。 私たちの場合、値関数はゲームの状態のテーブルになり、0から1の値は、ある状態が別の状態よりも「良い」ことを示します。 最初に、すべての勝ちの組み合わせ(行、列、または対角線上の3つのクロス)が1に等しい確率を与えるようにテーブルに設定します。同様に、3つのゼロを持つすべての状態は0です。
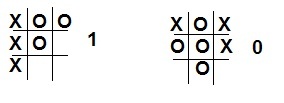
確率表の準備を単純化するために、合計で
39=19683
状態。 もちろん、これらの組み合わせの半分は不可能ですが、目的のためにコードを最適化する理由はありませんでした。
確率表初期化コード
float V[19683]; //------- void setV(int a1,int a2,int a3,int b1,int b2,int b3,int c1,int c2,int c3,float v) { int num; num = ((((((((a1*3)+a2)*3+a3)*3+b1)*3+b2)*3+b3)*3+c1)*3+c2)*3+c3; V[num] = v; } //------- for (int i1=0;i1<3;i1++) for (int i2=0;i2<3;i2++) for (int i3=0;i3<3;i3++) for (int i4=0;i4<3;i4++) for (int i5=0;i5<3;i5++) for (int i6=0;i6<3;i6++) for (int i7=0;i7<3;i7++) for (int i8=0;i8<3;i8++) for (int i9=0;i9<3;i9++) { setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0.5); if (i1==i2 && i2==i3 && i3==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i4==i5 && i5==i6 && i6==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i7==i8 && i8==i9 && i9==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i1==i5 && i5==i9 && i9==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i7==i5 && i5==i3 && i3==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i1==i4 && i4==i7 && i7==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i2==i5 && i5==i8 && i8==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i3==i6 && i6==i9 && i9==1) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,1); if (i1==i2 && i2==i3 && i3==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i4==i5 && i5==i6 && i6==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i7==i8 && i8==i9 && i9==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i1==i5 && i5==i9 && i9==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i7==i5 && i5==i3 && i3==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i1==i4 && i4==i7 && i7==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i2==i5 && i5==i8 && i8==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); if (i3==i6 && i6==i9 && i9==2) setV(i1,i2,i3,i4,i5,i6,i7,i8,i9,0); }
ゲームの進行
対戦相手は、それに応じて、ゼロのためにプレーし、定期的に屈服する人になります。 ゲーム中、その状態の値に変化があります。 エージェントのアクションを正しく評価するには、選択した状態のシーケンスを記録し、ゲームの終了時にそれらを再計算する必要があります。 V(s)の値を計算する式は次のとおりです。
V(s)=V(s)+A∗[V(s′)−V(s)] 、
ここで、Aは学習速度に影響するステップサイズです。 V(s ')-ゲーム終了時のアクションの値(1-勝った場合は0、それ以外の場合)。
ステップサイズは、相手の戦略が変更されるかどうかに影響します。 戦略のばらつきを考慮する必要がある場合は、ステップサイズを一定のままにする必要があります。 それ以外の場合、ステップがゼロに減少すると、エージェントはトレーニングを停止します。
プロービングムーブ(高い値を持たない)を使用すると、他のムーブの高い値のために達成されなかった状態を確認でき、戦略をより良い方向に変更するわずかな機会を与えます。
エージェントストローク選択コード
void stepAI(void) { int flag; c_var=0; for (int i=0;i<19683;i++) { flag=0; readMap(i); for (int j=1; j<10;j++) if (rm[j]!=m[j]) if ((m[j]==0) && (rm[j]==1)) flag++; else flag+=2; if (flag==1) { var[c_var]=i; c_var++; } } float v_max; int v_num_max; if (random(100)<5) v_num_max=random(c_var); else { v_max = V[var[0]]; v_num_max = 0; if (c_var>1) for (int i=1;i<c_var;i++) if (V[var[i]]>v_max) v_num_max = i; } steps++; steps_m[steps]=var[v_num_max]; readMap(var[v_num_max]); for (int i=1;i<10;i++) m[i]=rm[i]; paintMap(); }
上記のコードでは、可能な移動の選択が行われます(要素がフィールドの現在の状態と同一であり、別のクロスがある状態)。 次に、取得された状態から、任意の動き(5%の確率)または「貪欲な」動き(最大値)のいずれかが選択されます。 選択の最後に、この動きは行われた動きの別の配列に記録されます。
すでに述べたように、ゲームの終わりに、行われた動きの価値の再計算が行われます。
値の再計算
void learnAI(int res) { for (int i=0;i<steps;i++) V[steps_m[i]] += A * (res - V[steps_m[i]]); A -= 0.01; }
まとめ
→ C ++ Builder 6のプログラムとプロジェクト
この例では、強化学習の1つの側面について簡単に説明しました。 エージェントが通常環境に接触する場合、この例では、相手のプレイヤーとトレーニングが行われました。 この例は非常に単純ですが、他の例でのこの方法は実際よりも非常に制限されるように思われるかもしれません。
中古文学
強化学習/ R.S.サットン、E.G。バルト-モスクワ:BINOM。 知識研究所、2014