これは、私がどのように最適化に取り組み、最新のx86プロセッサーで最速のサイズ変更を受け取ったかについての一連の記事の続きです。 各記事では、ストーリーの一部を説明しますが、他の人にコードを最適化するようにプッシュしたいと考えています。 前のシリーズ:
→ パート0
→ パート1、一般的な最適化
前回は、アプローチを変更せずに、平均で2.5倍の加速を得ました。 今回は、SIMDアプローチを適用して、さらに3.5倍加速する方法を示します。 もちろん、グラフィックス処理にSIMDを使用することはノウハウではなく、SIMDがこのために発明されたとさえ言えます。 しかし、実際には、画像処理タスクにもそれを使用する開発者はほとんどいません。 たとえば、かなりよく知られている一般的なライブラリImageMagickとLibGDは、SIMDを使用せずに作成されています。 これは、SIMDアプローチが客観的にはより複雑でクロスプラットフォームではないためと、情報がほとんどないためです。 基本を見つけるのは非常に簡単ですが、詳細な資料や実際の問題の分析は十分ではありません。 Stack Overflowのこれから、文字通りすべてのささいなことについて多くの質問があります:データをダウンロードする方法、アンパックする方法、パックする方法。 誰もが自分でコーンを埋めなければならないことがわかります。
SIMDとは
すでに基本に精通している場合は、このセクションをスキップしてください。 SIMDは、単一の命令、複数のデータを表します。 このアプローチにより、複数の同一の操作を1つにまとめることができます。 操作が実行されるデータセットはベクトルと呼ばれます。
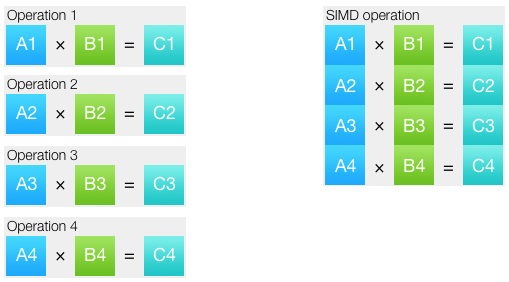
ほとんどの場合、最新のプロセッサでは、SIMD命令は対応するスカラーと同じ数のクロックサイクルで実行されます。 つまり 理論的には、SIMDに切り替えると、使用するデータ型と命令セットに応じて、2、4、8、16、さらには32倍の加速が期待できます。 実際には、それは異なって出てきます。 まず、ベクトル化されたコードでも、コードの一部はスカラーのままです。 第二に、多くの場合、ベクトル演算のために、データを準備する必要があります:アンパックとパック。 原則として、SIMDコードを記述するとき、データのパックとアンパックは最も難しいことです。 第三に、SIMD命令は通常の命令の正確なコピーではありません。一部の操作には問題を適切に解決する特定の命令があり、他のタスクには必要な命令がありません。 たとえば、最小値と最大値を見つけるために、条件付きジャンプなしで動作する個別のSIMD命令があります。 ただし、x86プロセッサには整数ベクトルの除算はありません。
より多くの値がベクトルレジスタに配置されます。 データの種類とレジスタのサイズに依存します。 SSEレジスタは128ビットです。 たとえば、32ビット整数で作業する場合、4つの値が1つのSSEレジスタに収まります。 以下のデータタイプが主に利用可能です:
- 8ビット整数(符号付きまたは符号なし)
- 16ビット整数(符号付きまたは符号なし)
- 32ビット整数(符号付きまたは符号なし)
- 64ビット整数(符号付きまたは符号なし)
- 単精度浮動小数点数、32ビット
- 64ビットの倍精度浮動小数点数
すべてのベクトルレジスタは同じであり、それらがどのタイプのデータであるかを知りません。 解釈は、レジスタで動作する命令のみに依存します。 したがって、ほとんどの命令には、異なるタイプのデータを扱うためのバリエーションがあります。 命令は、1つのタイプのデータを受信し、別のタイプを提供できます。 アセンブラに精通している場合、これは通常のレジスタがどのように機能するかを幾分連想させます。32ビットeax
レジスタに何かを書き込んでから、16ビットax
パーツを操作できます。
適切なコマンド拡張機能の選択
最初のSIMD命令は、Intel Pentium MMXプロセッサに登場しました。 実際にMMX-これはチームの拡大の名前です。 このキットは非常に重要だったため、Intelはそれをプロセッサの名前に取り入れました。 MMXを使用して、2つの画像の混合やスーパーサンプリングなどの簡単なアルゴリズムを書いたことがあります。 Delphiで作成しましたが、MMXを使用するには、下のレベルに移動してアセンブラーで挿入する必要がありました。
それ以来、プロセッサチームと関連する開発ツールの開発についてはあまりフォローしていません。 したがって、最近SIMDを再び取り上げたとき、私はうれしい驚きを覚えました。 いいえ、コンパイラは、多少複雑な場合でもSIMD命令を自動的に適用することはできません。 そして、彼が有能であれば、彼は通常、自分で書いたSIMDコードよりも悪くなります。 しかし一方で、SIMDを使用するには、アセンブラーで記述する必要がなくなり、すべてが特別な関数-組み込み関数で行われます。
ほとんどの場合、各組み込み関数は1つの特定のプロセッサ命令に対応しています。 つまり 記述されたコードは非常に効率的で、ハードウェアに近いものです。 しかし同時に、使い慣れた比較的安全なC構文を使用してコードを記述します。 通常どおり、組み込み関数が定義されているヘッダーファイルをインクルードします。通常は、特殊なデータ型を使用して変数を宣言し、通常の呼び出し関数として定義します。 つまり、通常のコードを記述します。 少し不便ですが、SIMDデータ型では数学演算を使用できないため、すべての計算に組み込み関数を使用する必要があります。 大まかに言うと、 ss0
+ ss1
書くことはできませんadd_float(ss0, ss1)
(関数の名前が発明されました)しかできません。
SIMD拡張機能は多数あります。 基本的に、プロセッサに新しい拡張機能が存在するということは、すべての先行機能が存在することを意味します。 拡張機能の外観の時系列に従って、次の順序で配置されます。
MMX、SSE、SSE2、SSE3、SSSE3、SSE4.1、SSE4.2、AVX、AVX2、AVX-512
ご覧のとおり、このリストは印象的です。 すべてのマシンにすべての拡張機能があるわけではありません。 博物館では、MMXのないライブx86プロセッサのみを見つけることができます。 SSE2は、64ビットプロセッサに必要な拡張機能です。 最近では、ほぼどこにでもあります。 SSE4.2のサポートは、Nehalemアーキテクチャ以降、どのプロセッサでも見つけることができます。 2008年から。 ただし、AVX2は、Haswellコア以降の非予算のIntelプロセッサーでのみ使用できます。 2013年以降、AMDでは2017年にリリースされたRyzenプロセッサーに登場しました。 AVX-512は現在、Intel XeonおよびXeon Phiサーバープロセッサでのみ利用可能です。
命令セットの選択は、コードの記述のパフォーマンスと複雑さ、およびプロセッサのサポートに依存します。 開発者は、異なる命令セットに対してコードの実装を複数作成する場合があります。 SSE4.2とAVX2の2つを選択しました。 私はこのように推論しました:SSE4.2は、少なくともパフォーマンスに関心がある人なら誰でも心配する必要のない基本セットです。たとえば、SSE2にすべてを実装します。 AVX2は、少なくとも3年に1回はハードウェアを変更するのが面倒ではない人向けです。 実装のために選択したものが何であれ、選択された命令セットを備えた市場のプロセッサの数は増加するだけであるため、時間が経つにつれて、選択はより正確になります。
SSE4の実装
最後にコードに戻りましょう。 CでSSE4.2を使用するには、次の3つのヘッダーファイルを接続する必要があります。
#include <emmintrin.h> #include <mmintrin.h> #include <smmintrin.h>
さらに、コンパイラフラグ-msse4
指定する必要があります。 Pythonモジュール(私たちのモジュールなど)の構築について話している場合は、コマンドラインからこのフラグを直接追加して、アセンブリを複雑にしないようにすることができます。
$ CC="ccache cc -msse4" python ./setup.py develop
最も包括的な組み込みリファレンスは、 Intel Intrinsics Guideにあります。 優れた検索とフィルタリングがあり、組み込み関数の説明は、対応する命令、命令の擬似コード、さらには最新世代のIntelプロセッサのクロックサイクルでの実行時間を示します。 参考として、これはユニークなものです。 しかし、このガイドの形式では、どのようなことが起こるべきかについての一般的な状況を把握することはできません。
ベクトル化は、異なるデータに対する同じ操作のみに役立ちます。 この場合、同じアクションが異なる画像チャンネルで実行されます:
for (xx = 0; xx < imOut->xsize; xx++) { ss0 = 0.5; ss1 = 0.5; ss2 = 0.5; for (y = ymin; y < ymax; y++) { ss0 = ss0 + (UINT8) imIn->image[y][xx*4+0] * k[y-ymin]; ss1 = ss1 + (UINT8) imIn->image[y][xx*4+1] * k[y-ymin]; ss2 = ss2 + (UINT8) imIn->image[y][xx*4+2] * k[y-ymin]; } imOut->image[yy][xx*4+0] = clip8(ss0); imOut->image[yy][xx*4+1] = clip8(ss1); imOut->image[yy][xx*4+2] = clip8(ss2); }
垂直方向と水平方向の通過についても同様のコードがあります。 便宜上、両方を別々の関数に配置し、次のシグネチャを持つ2つの関数のフレームワーク内でのみSIMDを使用します。
void ImagingResampleHorizontalConvolution8u( UINT32 *lineOut, UINT32 *lineIn, int xsize, int *xbounds, float *kk, int kmax ); void ImagingResampleVerticalConvolution8u( UINT32 *lineOut, Imaging imIn, int ymin, int ymax, float *k );
覚えているなら、前のパートで、画像の2、3、4チャンネルに対して3つの特別なケースを作成しました。 これは、チャネルを通る内部ループを取り除き、同時に画像にないチャネルに対して不必要な計算を実行しないために必要でした。 SIMDバージョンでは、チャネルごとに実装を共有しません。すべての計算は常に4つのチャネルで実行されます。 各ピクセルは4つの32ビット浮動小数点数で表され、正確に1つのSSEレジスタを占有します。 はい、3チャンネル画像の場合、4つの操作はアイドル状態になり、2チャンネル画像の場合は半分になります。 ただし、有用なデータを使用してSSEレジスタを可能な限り駆動しようとするよりも、これに目をつぶる方が簡単です。
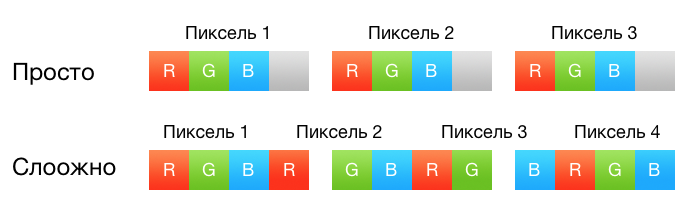
上記のコードをもう一度見てください。 最初の段階では、バッテリーには0.5の一定値が割り当てられますが、これは結果を丸めるために必要です。 関数_mm_set1_*
は、単一の浮動小数点値をレジスタ全体にロードするために使用されます。
__m128 sss = _mm_set1_ps(0.5);
通常、関数名の最後の部分は、機能するデータのタイプを示します。 私たちの場合、それは_ps
であり、パックドシングルを意味します。
さらに、ピクセルを浮動小数点数のベクトルとして使用したい場合は、ピクセルを何らかの方法でこの表現に変換する必要があります。 SSEには、8ビット値を単精度数値に一度に変換する命令はありません。 _mm_cvtepi32_ps
があります。これは、32ビット整数を単精度数値に変換しますが、使用する前に、8ビット数値を32ビット数値にアンパックする必要があります。 これに_mm_cvtepu8_epi32
関数_mm_cvtepu8_epi32
便利です。 彼女は、アドレスをメモリ内の128ビット値に渡す必要があります。
__m128i pix_epi32 = _mm_cvtepu8_epi32(*(__m128i *) &imIn->image32[y][xx]); __m128 pix_ps = _mm_cvtepi32_ps(pix_epi32);
値を読み込むときに明示的に行う必要があるSIMDコードの量に注意してください。 スカラーコードでは、これは存在しません。コンパイラーは、8ビット整数にfloatを乗算するため、最初の整数もfloatに変換する必要があることをコンパイラー自身が理解しています。
1ピクセルのすべてのチャネルの係数は同じであるため、 _mm_set1_ps
が_mm_set1_ps
ます。
__m128 mmk = _mm_set1_ps(k[y - ymin]);
係数をチャネルで乗算し、バッテリーに追加することは残ります。
__m128 mul = _mm_mul_ps(pix_ps, mmk); sss = _mm_add_ps(sss, mul);
現在、 sss
アキュムレータにはピクセルチャネルの値があります。これは実際に範囲[0、255]を超えることができるため、何らかの方法でこれらの値を制限する必要があります。 前の記事のclip8
関数を覚えていますか? 2つの条件付き遷移がありました。 SIMDの場合、プロセッサはすべてのデータに対して同じコマンドを実行する必要があるため、データに応じて条件付きジャンプを使用することはできません。 しかし、実際には_mm_min_epi32
および_mm_max_epi32
があるため、さらに優れてい_mm_max_epi32
。 したがって、値を符号付き32ビット整数に変換し、[0、255]内でそれらをトリミングします。
__m128i mmmax = _mm_set1_epi32(255); __m128i mmmin = _mm_set1_epi32(0); __m128i ssi = _mm_cvtps_epi32(sss); ssi = _mm_max_epi32(mmmin, _mm_min_epi32(mmmax, ssi));
残念ながら、 _mm_cvtepu8_epi32
には逆の命令はありません。したがって、必要なバイトを最初に移動してから、 _mm_cvtsi128_si32
を使用してSSEレジスタを汎用レジスタに変換することより良い方法は_mm_cvtepu8_epi32
ません_mm_cvtsi128_si32
。
__m128i shiftmask = _mm_set_epi8(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,12,8,4,0); lineOut[xx] = _mm_cvtsi128_si32(_mm_shuffle_epi8(ssi, shiftmask));
shiftmask
マスクマスクでは、下位バイトが右に行くことに注意してshiftmask
。 水平パスの場合、すべてがまったく同じで、ピクセルのロード順序のみが変更されます。隣接するピクセルは行からロードされ、隣接する行からはロードされません。
すべての準備ができました。テストを実行して結果を確認します。
Scale 2560×1600 RGB image to 320x200 bil 0,01151 s 355.87 Mpx/s 161.4 % to 320x200 bic 0,02005 s 204.27 Mpx/s 158.7 % to 320x200 lzs 0,03421 s 119.73 Mpx/s 137.2 % to 2048x1280 bil 0,04450 s 92.05 Mpx/s 215.0 % to 2048x1280 bic 0,05951 s 68.83 Mpx/s 198.3 % to 2048x1280 lzs 0,07804 s 52.49 Mpx/s 189.6 % to 5478x3424 bil 0,18615 s 22.00 Mpx/s 215.5 % to 5478x3424 bic 0,24039 s 17.04 Mpx/s 210.5 % to 5478x3424 lzs 0,30674 s 13.35 Mpx/s 196.2 %
コミット8d0412bの結果。
2.5倍から3倍に成長! 3チャンネルのRGB画像でテストしていることを思い出させてください。したがって、この場合の3倍の加速は基準と見なすことができます。
適切な梱包
以前のバージョンは、スカラーコードからコピーされたほぼ1対1でした。 さらに、パックとアンパックのために、SSEの最新バージョンに登場した関数_mm_cvtepu8_epi32
、 _mm_max/min_epi32
、 _mm_shuffle_epi8
。 明らかに、人々は何らかの形でこれらのタスクと以前のバージョンのSSEに対処しました。 実際、 _mm_pack*
および_mm_unpack*
データをパック/アンパックするための一連の関数があります。 ここで解凍があまり役に立たない場合( _mm_cvtepu8_epi32
私たちの目的に適しています)、梱包を大幅に簡素化できます。 値をシフトおよびトリミングするために定数が不要になるように単純化するために(私たちはmmmax
、 mmmin
、およびshiftmask
について話している)。
実際には、パッキング関数_mm_packs _mm_packs*
は、 _mm_packs_epi32
などの名前の文字sで示されるように、飽和状態で実行されます。 飽和とは、変換中に変数の値が新しい型の制限を超えた場合、この型では極端なままになることを意味します。 たとえば、16ビットの符号付き整数から8ビットの符号なしへの変換を行う場合、値257は255に変換され、-3は0に変換されます。パッケージ化関数は同時に値をシフトし、範囲外になることを防ぎます。
__m128i ssi = _mm_cvtps_epi32(sss); ssi = _mm_packs_epi32(ssi, ssi); ssi = _mm_packus_epi16(ssi, ssi); lineOut[xx] = _mm_cvtsi128_si32(ssi);
この最適化は加速を与えませんが、美しく見え、追加の定数を必要としません。 コミットb17cdc9を監視します。
AVXレジスタ
犬がズボンを着ていた場合、彼女はそれをこのようにするのでしょうか、それともそうしますか?
また、レジスタに2倍のデータが含まれていた場合はどうなりますか? AVXの仕組みを知ったとき、すぐにこの写真を思い出しました。 一見、AVXの指示は奇妙で非論理的に見えます。 これは「SSEのように、たった2倍」というだけでなく、ある種のあいまいなロジックを持っています。 すでに使用したのと同じ混合命令を見てください。 SSEバージョンの擬似コードは次のとおりです。
FOR j := 0 to 15 i := j*8 IF b[i+7] == 1 dst[i+7:i] := 0 ELSE index[3:0] := b[i+3:i] dst[i+7:i] := a[index*8+7:index*8] FI ENDFOR
AVXの場合、カウンタは単に15から31に増加するだけであると仮定するのは論理的です。しかし、AVXバージョンの擬似コードは非常に複雑です。
FOR j := 0 to 15 i := j*8 IF b[i+7] == 1 dst[i+7:i] := 0 ELSE index[3:0] := b[i+3:i] dst[i+7:i] := a[index*8+7:index*8] FI IF b[128+i+7] == 1 dst[128+i+7:128+i] := 0 ELSE index[3:0] := b[128+i+3:128+i] dst[128+i+7:128+i] := a[128+index*8+7:128+index*8] FI ENDFOR
AVXはSSEの2倍ではなく、2 SSEです! つまり、AVXレジスタを一対のベクトルとして見る必要があります。 そして、ほとんどのチームのこれらのベクトルは、相互作用しません。 AVXコマンドの擬似コードをもう一度見てください。最初のブロックは下位128ビットでのみ動作し、2番目のブロックは上位128ビットでのみ動作することがはっきりとわかります。 また、上位バイトが下位バイトになるように、またはその逆に混合することはできません。 さらに、この命令では、分離は厳密ではありません。シフトする方法を示すレジスタは、上部と下部を異なる方法でシフトできます。 そして、両方の部分の操作の引数が同じであることがよくあります。 擬似コード_mm256_blend_epi16
例を次に示し_mm256_blend_epi16
。
FOR j := 0 to 15 i := j*16 IF imm8[j%8] dst[i+15:i] := b[i+15:i] ELSE dst[i+15:i] := a[i+15:i] FI ENDFOR dst[MAX:256] := 0
jは15に反復され、マスクは8を法とするバイトimm8[j%8]
から取得されることに注意してください。 つまり レジスタの上部と下部は常に同じマスクを持ちます。 開梱と梱包は依然として多くの問題であり、上部と下部で独立して発生します。
PACK_SATURATED(src[127:0]) { dst[15:0] := Saturate_Int32_To_UnsignedInt16 (src[31:0]) dst[31:16] := Saturate_Int32_To_UnsignedInt16 (src[63:32]) dst[47:32] := Saturate_Int32_To_UnsignedInt16 (src[95:64]) dst[63:48] := Saturate_Int32_To_UnsignedInt16 (src[127:96]) RETURN dst[63:0] } dst[63:0] := PACK_SATURATED(a[127:0]) dst[127:64] := PACK_SATURATED(b[127:0]) dst[191:128] := PACK_SATURATED(a[255:128]) dst[255:192] := PACK_SATURATED(b[255:128]) dst[MAX:256] := 0
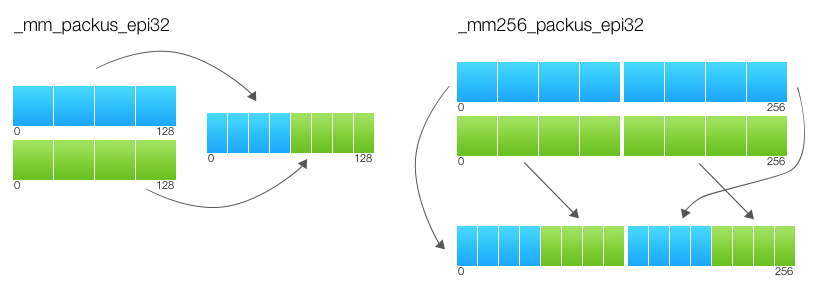
結果の下位ビットは、入力パラメーターの下位ビットのみに基づいて計算されます。 そして、上部のものは上部のものにのみ基づいています。 私はこの規則についての出典で明示的に言及していませんが、その理解によりSSEコードのAVXへの移植が大幅に簡素化されます。
AVXコマンド
AVXコマンド自体とSSEを区別するものがあります。 最初のパートの最後で説明したデータ依存関係の問題を覚えていますか? 彼女はAVXで録音されました。 もちろん、スカラー命令の動作を修正することはすでに不可能ですが、SSEからAVXに切り替えるときに同じ間違いを防ぐことができます。 各AVX命令の擬似コードでは、最後に次の行があります。
dst[MAX:256] := 0
これは、AVXが将来の世代(512ビット以上)のレジスタを使用して既存のコマンドの動作を決定することを意味します。 しかし、それだけではありません。 VEXオペコードシステムは、AVXコマンドのエンコードに使用されます。 AVXには、SEX命令でさえVEXでエンコードする機能が含まれています。 この方法でコーディングされたSSE命令は、最上位ビットがリセットされるという保証も受け取ります。 SSEまたはその逆の後にAVXコマンドを使用すると、約100ティックのペナルティがあると聞いたことがあるかもしれません。 幸いなことに、このペナルティはVEXでエンコードされたSSEコマンドには適用されません。 -mavx
フラグを指定して組み込み関数を使用する-mavx
コンパイラーは新しい形式で命令を生成します。 悪いニュースは、コードが-mavx
でコンパイルされ、SSEコマンドを含むが、AVXコマンドを含まない場合、VEXでエンコードされ、AVXのないプロセッサーでは機能しないことです。 つまり 同じ形式のアセンブリモジュール内で、古い形式のSSE命令とAVX命令を使用することはできません 。
if (is_avx_available()) { resample_avx(); } else { resample_sse(); }
-mavx
フラグがある-mavx
resample_sse()
関数から-mavx
コードはAVXなしではプロセッサで開始されず、このフラグresample_avx()
ないresample_avx()
関数からのコードはコンパイルresample_avx()
ません。
AVX2、垂直通路
これまで、SIMDへの転送は非常に簡単でした。4つの浮動小数点数として表される1つのピクセルが1つのSSE4レジスタに収まるからです。 しかし、AVX2では、一度に8つの浮動小数点値、つまり2ピクセルを処理する必要があります。 しかし、1つのレジスタに取り込むピクセルはどれですか? ここでも、ズボンを着ている犬の写真を挿入したいと思います。 フレームがどのように見えるか、たとえば水平たたみ込みを思い出させてください:
for (xx = 0; xx < xsize; xx++) { xmin = xbounds[xx * 2 + 0]; xmax = xbounds[xx * 2 + 1]; for (x = xmin; x < xmax; x++) { __m128i pix = lineIn[x]; __m128 mmk = k[x - xmin]; // } }
たとえば、ライン内の隣接ピクセルを取得することができます: lineIn[x]
およびlineIn[x + 1]
、これは最も明白なオプションです。 ただし、これらのピクセルに対して、異なる係数( k[x - xmin]
およびk[x - xmin + 1]
)を準備する必要があります。 また、xmaxからxminまでの距離は奇数になる可能性があり、最後のピクセルを計算するには、SSEコードとAVXコードを組み合わせる必要があります。
隣接する行でピクセルを取得できます: lineIn1[x]
およびlineIn2[x]
。 ただし、ピクセルを別々にロードおよびアンロードする必要があるため、あまり便利ではありません。
実際、どの方法にもいくつかの長所と短所があります。 率直に言って、水平通路をAVX2に転送することはあまり便利ではありません。 もう一つは垂直です! 彼を見て:
for (xx = 0; xx < imIn->xsize; xx++) { for (y = ymin; y < ymax; y++) { __m128i pix = image32[y][xx]; __m128 mmk = k[y - ymin]; // } }
ラインimage32[y][xx]
およびimage32[y][xx + 1]
の隣接ピクセルを取得でき、それらは同じ係数を持ちます。 内部サイクルが完了すると、バッテリーは隣接する2つのピクセルの結果になります;パックすることも難しくありません。 つまり、すべての__m128
プレフィックスを__m256
に、 _mm_
を_mm256_
変更するだけで、コードを書き換えることができます。 本当に異なるのは、最後に_mm256_castsi256_si128
および_mm_storel_epi64
を使用することだけです。 1つはnoopで、型キャストだけです。 そして、2番目は64ビット値をレジスタからメモリに保存します。
Scale 2560×1600 RGB image to 320x200 bil 0.01162 s 352.37 Mpx/s -0,9 % to 320x200 bic 0.02085 s 196.41 Mpx/s -3,8 % to 320x200 lzs 0.03247 s 126.16 Mpx/s 5,4 % to 2048x1280 bil 0.03992 s 102.61 Mpx/s 11,5 % to 2048x1280 bic 0.05086 s 80.53 Mpx/s 17,0 % to 2048x1280 lzs 0.06563 s 62.41 Mpx/s 18,9 % to 5478x3424 bil 0.15232 s 26.89 Mpx/s 22,2 % to 5478x3424 bic 0.19810 s 20.68 Mpx/s 21,3 % to 5478x3424 lzs 0.23601 s 17.36 Mpx/s 30,0 %
コミット86fe8a2の結果。
初めてパフォーマンスがわずかに低下しました。 これは測定エラーではありません。なぜなら 結果は非常に安定しています。 後でその理由を説明します。 それまでの間、ゲインは主に増加であり、画像の大幅な減少ではないことは明らかです。 推測するのは難しいことではありませんが、これは垂直方向の通過が水平方向の通過の後に行われ、最終画像のサイズが大きくなると効果が大きくなるために起こります。 一般的に、この状況は非常にポジティブです。
AVX2水平パス
水平方向のパスの場合、2つの隣接するピクセルを連続して取得する方が便利です。 次に、それらのために異なる係数を準備する必要があります。
__m256 mmk = _mm256_set1_ps(k[x - xmin]); mmk = _mm256_insertf128_ps(mmk, _mm_set1_ps(k[x - xmin + 1]), 1);
最後に、256ビットレジスタの上部の結果を下部の結果に追加する必要があります。
__m128 sss = _mm_add_ps( _mm256_castps256_ps128(sss256), _mm256_extractf128_ps(sss256, 1));
Scale 2560×1600 RGB image to 320x200 bil 0,00918 s 446.18 Mpx/s 26,6 % to 320x200 bic 0,01490 s 274.90 Mpx/s 39,9 % to 320x200 lzs 0,02287 s 179.08 Mpx/s 42,0 % to 2048x1280 bil 0,04186 s 97.85 Mpx/s -4,6 % to 2048x1280 bic 0,05029 s 81.44 Mpx/s 1,1 % to 2048x1280 lzs 0,06178 s 66.30 Mpx/s 6,2 % to 5478x3424 bil 0,16219 s 25.25 Mpx/s -6,1 % to 5478x3424 bic 0,19996 s 20.48 Mpx/s -0,9 % to 5478x3424 lzs 0,23377 s 17.52 Mpx/s 1,0 %
コミットfd82859の結果。
ここでも、以前のバージョンと比較して一部のサイズでわずかな損失が見られます。 しかし、両方の最適化を合計すると、6〜50%増加しました。 平均して、AVX2バージョンはSSE4バージョンより25%高速です。
それはたくさんですか、それとも少しですか? もちろん、新しい一連の指示からさらに多くを取得したいと思います。 , 100% , 50% . , , .
, . , . Intel Core i5-4258U. , , .
, : . i5-4258U 2.4 2.9 . — , . — , . , . , , , . Intel Power Gadget . , SSE4- 2.9 . AVX2-, 2.75 . AVX2-, 2.6 . つまり , AVX2-, . AVX2- , - . AVX2 . 何が言えますか? , AVX2 .
, Xeon E5-2680 v2 ( Haswell, ) — AVX2- , , .