しばらくして、私はまだこの問題をより詳細に研究するために時間をかけました、そして、私はあなたと私の観察を共有したいです。
なんで?
この質問は、自尊心のあるプログラマーによって尋ねられます。 2つの異なる言語でプロジェクトを実行することは非常に疑わしい問題であり、アンマネージコードを実装、デバッグ、および維持することは非常に困難です。 ただし、特に重要な領域や負荷の高いアプリケーションでは、より高速に機能する機能を実装する能力のみが既に検討に値します。
別の可能な答え:機能は、損傷のない形ですでに実装されています! すべてを.NETでラップしてそこから使用できる場合、なぜソリューション全体を書き直しますか?
一言で言えば-これは本当に起こります。 そして、私たちは何をどのように見るのかだけです。
歌詞
すべてのコードはVisual Studio Community 2015で作成されました。評価のために、ボード上のi5-3470、12ギガバイトの1333MHzデュアルチャネルRAM、および7200 rpmのハードドライブを備えたワークアンドプレイコンピューターを使用しました。 System.Diagnostics.Stopwatchを使用して測定が行われました。これは、PerformanceCounterの上に実装されているため、DateTimeよりも正確です。 リリースビルドでテストを実行して、実際には少し異なる可能性を排除しました。 .NETフレームワークのバージョンは4.5.2で、C ++プロジェクトは/ TC(Compile as C)フラグを使用してコンパイルされました。
コードが豊富であることを事前に謝罪しますが、それなしでは、私が何を達成したかを正確に理解することは困難です。 あまりにも退屈な、または取るに足らないコードのほとんどをネタバレに取り出し、もう一方を記事から完全に切り取りました(最初はさらに長くなりました)。
関数呼び出し
関数の呼び出し速度の測定から研究を始めることにしました。 これにはいくつかの理由がありました。 まず、まだ関数を呼び出す必要がありますが、同じモジュール内のコードと比較すると、ロードされたdllからの関数はすぐには呼び出されません。 第二に、ほぼ同じ方法で、既存のC#ラッパーのほとんどはアンマネージコードの上に実装されます(たとえば、 sharpgl 、 openal-cs 、
直接測定を開始する前に、測定結果を保存および評価する方法について考える必要があります。 「CSV!」と思い、この形式でデータを保存する簡単なクラスを作成しました。
シンプルなCSV実装
public class CSVReport : IDisposable { int columnsCount; StreamWriter writer; public CSVReport(string path, params string[] header) { columnsCount = header.Length; writer = new StreamWriter(path); writer.Write(header[0]); for (int i = 1; i < header.Length; i++) writer.Write("," + header[i]); writer.Write("\r\n"); } public void Write(params object[] values) { if (values.Length != columnsCount) throw new ArgumentException("Columns count for row didn't match table columns count"); writer.Write(values[0].ToString()); for (int i = 1; i < values.Length; i++) writer.Write("," + values[i].ToString()); writer.Write("\r\n"); } public void Dispose() { writer.Close(); } }
最も機能的なオプションではありませんが、私の目的には十分すぎるでしょう。 そして、テストのために、数値の合計と結果の保存のみを行う簡単なクラスを作成することにしました。 これはどのように見えるかです:
class Summer { public int Sum { get; private set; } public Summer() { Sum = 0; } public void Add(int a) { Sum += a; } public void Reset() { Sum = 0; } }
しかし、これは管理可能なオプションです。 制御不能も必要です。 したがって、テンプレートdllプロジェクトを作成し、そこにファイル(api.hなど)をすぐに追加します。そこにエクスポート定義をプッシュします。
#ifndef _API_H_ #define _API_H_ #define EXPORT __declspec(dllexport) #define STD_API __stdcall #endif
次に、summer.cを配置し、必要なすべての機能を実装します。
#include "api.h" int sum; EXPORT void STD_API summer_init( void ) { sum = 0; } EXPORT void STD_API summer_add( int value ) { sum += value; } EXPORT int STD_API summer_sum( void ) { return sum; }
ここで、この混乱に対するラッパークラスが必要です。
class SummerUnmanaged { const string dllName = @"unmanaged_test.dll"; [DllImport(dllName)] private static extern void summer_init(); [DllImport(dllName)] private static extern void summer_add(int v); [DllImport(dllName)] private static extern int summer_sum(); public int Sum { get { return summer_sum(); } } public SummerUnmanaged() { summer_init(); } public void Add(int a) { summer_add(a); } public void Reset() { summer_init(); } }
結果はまさに私が望んでいたものです。 使用する完全に同一の実装が2つあります。1つはC#で、もう1つはCです。 今、あなたはそれの由来を見ることができます! 1つのクラスと他のクラスのn回の呼び出しの実行時間を測定するコードを記述します。
static void TestCall() { Console.WriteLine("Function calls..."); Stopwatch sw = new Stopwatch(); Summer s_managed = new Summer(); SummerUnmanaged s_unmanaged = new SummerUnmanaged(); Random r = new Random(); int[] data; CSVReport report = new CSVReport("fun_call.csv", "elements", "C# managed", "C unmanaged"); data = new int[1000000]; for (int j = 0; j < 1000000; j++) data[j] = r.Next(-1, 2); // for (int i=0; i<100; i++) { // Console.Write("\r{0}/100", i+1); int length = 10000*i; long managedTime = 0, unmanagedTime = 0; Thread.Sleep(10); s_managed.Reset(); sw.Start(); for (int j = 0; j < length; j++) { s_managed.Add(data[j]); } sw.Stop(); managedTime = sw.ElapsedTicks; sw.Reset(); sw.Start(); for(int j=0; j<length; j++) { s_unmanaged.Add(data[j]); } sw.Stop(); unmanagedTime = sw.ElapsedTicks; report.Write(length, managedTime, unmanagedTime); } report.Dispose(); Console.WriteLine(); }
この関数をメインのどこかで呼び出すだけで、fun_call.csvのレポートを見るだけです。 わかりやすくするために、退屈で乾燥した数字は示しませんが、グラフを描くだけです。 垂直-ティック単位の時間、水平-関数呼び出しの数。
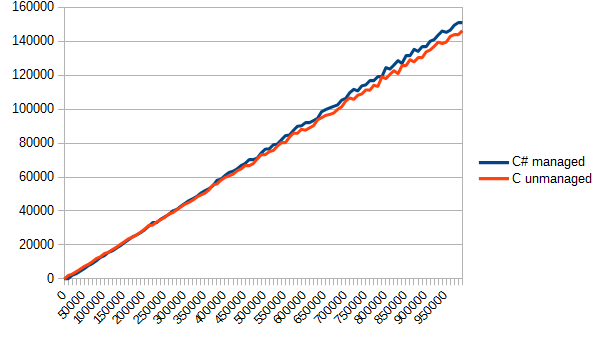
結果は少し驚いた。 このテストでは、C#が明らかにお気に入りでした。 それでも、同じモジュール、およびインライン化する機能...しかし、結果として、両方のオプションはほぼ同じでした。 実際、この場合、このようなコードの分離は意味がありませんでした-彼らは何も勝ちませんでしたが、プロジェクトは複雑でした。
配列
結果への反省はそれほど長くなく、すぐにデータを1つの要素ではなく配列で送信する必要があることに気付きました。 コードをアップグレードします。 機能を追加しましょう:
public void AddMany(int[] data) { int length = data.Length; for (int i = 0; i < length; i++) Sum += i; }
そして、実際には、Cパート:
EXPORT int STD_API summer_add_many( int* data, int length ) { for ( int i = 0; i < length; i++ ) sum += data[ i ]; }
[DllImport(dllName)] private static extern void summer_add_many(int[] data, int length); public void AddMany(int[] data) { summer_add_many(data, data.Length); }
したがって、パフォーマンスを測定する機能を書き直さなければなりませんでした。 スポイラーのフルバージョン、簡単に言うと、n個のランダムな要素の配列を生成し、それらの追加の関数を呼び出します。
新しいパフォーマンス測定機能
static void TestArrays() { Console.WriteLine("Arrays..."); Stopwatch sw = new Stopwatch(); Summer s_managed = new Summer(); SummerUnmanaged s_unmanaged = new SummerUnmanaged(); Random r = new Random(); int[] data; CSVReport report = new CSVReport("arrays.csv", "elements", "C# managed", "C unmanaged"); for (int i = 0; i < 100; i++) { Console.Write("\r{0}/100", i+1); int length = 10000 * i; long managedTime = 0, unmanagedTime = 0; data = new int[length]; for (int j = 0; j < length; j++) // data[j] = r.Next(-1, 2); s_managed.Reset(); sw.Start(); s_managed.AddMany(data); sw.Stop(); managedTime = sw.ElapsedTicks; sw.Reset(); sw.Start(); s_unmanaged.AddMany(data); sw.Stop(); unmanagedTime = sw.ElapsedTicks; report.Write(length, managedTime, unmanagedTime); } report.Dispose(); Console.WriteLine(); }
実行して、レポートを確認します。 ティック単位の垂直静止時間、水平-配列の要素数。
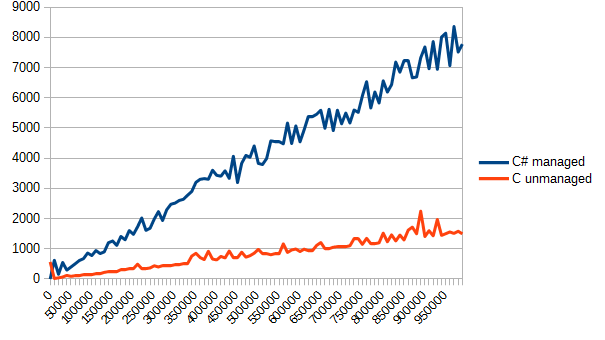
それは肉眼で見ることができます-Cは配列の通常の処理に対処するのがはるかに優れています。 しかし、これは「管理性」の代価です。オーバーフローの場合のマネージコード、配列の範囲外
歌詞
ちなみに、グラフィックがギザギザになった理由について、合理的な結論に達することができませんでした。 GCフェーズまたはその他のプロセスは、おそらくプロセッサ時間を消費しますが、これは正確ではありません。 それにもかかわらず、単純な平均化でも、特定のケースではCが数倍高速であることがわかります。
ファイルを読む
Cでの大量のデータの処理がより高速であることを確認して、ファイルを読み取る必要があると判断しました。 この決定は、コードがどの程度スマートにシステムと通信できるかを確認したいという願望が原因でした。
これらの目的のために、ファイルのスタックを生成しました(もちろん、サイズが直線的に増加します)
ファイルを生成します
static void Generate() { Random r = new Random(); for(int i=0; i<100; i++) { BinaryWriter writer = new BinaryWriter(File.OpenWrite("file" + i.ToString())); for(int j=0; j<200000*i; j++) { writer.Write(r.Next(-1, 2)); } writer.Close(); Console.WriteLine("Generating {0}", i); } }
その結果、最大のファイルは75メガバイトであり、これで十分でした。 テストでは、別のクラスを選択しませんでしたが、
static int FileSum(string path) { BinaryReader br = new BinaryReader(File.OpenRead(path)); int sum = 0; long length = br.BaseStream.Length; while(br.BaseStream.Position != length) { sum += br.ReadInt32(); } br.Close(); return sum; }
コードからわかるように、タスクを次のように設定します。ファイルのすべての整数を合計します。 Cでの対応する実装:
EXPORT int STD_API file_sum( const char* path ) { FILE *f = fopen( path, "rb" ); if ( !f ) return 0; int sum = 0; while ( !feof( f ) ) { int add; fread( &add, sizeof( int ), 1, f ); sum += add; } fclose( f ); return sum; }
今では、すべてのファイルを周期的に読み取り、各実装の速度を測定することが残っています。 測定機能コードは提供せず(自分で作成できます)、視覚的なデモンストレーションに直接進みます。
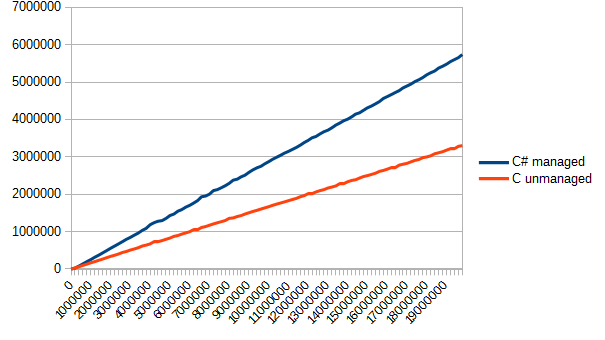
このグラフからわかるように、Cは少し速かった(約1.5倍)。 しかし、ゲインはゲインです。
この瞬間のどこかで、私は少し草原に連れて行かれました(または他のどこか)が、これらの考えを共有することはできません。 私はネタバレに興味を持ち、他のすべての人に私の研究の次の部分に進むように頼みます。
草原
私がファイルを読む時間は私を驚かせました。 経験豊富なプログラマーは、すぐに私のコードの何が問題なのかを言うでしょう-彼はあまりにも頻繁にファイルのデータを求めてシステムにアクセスします。 とても遅いです。 その結果、読み取りアルゴリズムを少し近代化し、ファイルから最大400 KBのデータの強制バッファリングを追加し、すべてを大幅に高速化しました。 CおよびC#コードの対応する変更:
私はこのテストを記事の「基本」に含めたくありませんでしたが、これには理由が1つありました。テストが完全に公平ではないということです。 Cは、何でもどこでも書くことができるので、明らかにこのようなタスクに適していましたが、C#ではすべてをバイト単位で変換する必要がありました。
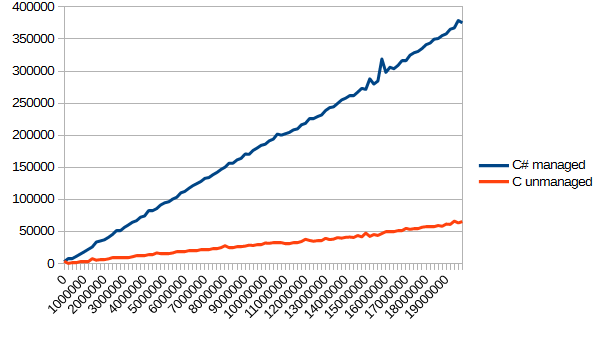
このようなパフォーマンスの違いは、バイトを単語に追加で変換する必要があるためだと考えています。 一般に、このトピックは別の記事に値するものであり、これについても説明します。
long length = br.BaseStream.Length; byte[] buffer = new byte[100000*4]; while(br.BaseStream.Position != length) { int read = br.Read(buffer, 0, 100000*4); for(int i=0; i<read; i+=4) { sum += BitConverter.ToInt32(buffer, i); } }
int sum = 0; int *buffer = malloc( 100000 * sizeof( int ) ); while ( !feof( f ) ) { int read = fread( buffer, sizeof( int ), 100000, f ); for ( int i = 0; i < read; i++ ) { sum += buffer[ i ]; } }
私はこのテストを記事の「基本」に含めたくありませんでしたが、これには理由が1つありました。テストが完全に公平ではないということです。 Cは、何でもどこでも書くことができるので、明らかにこのようなタスクに適していましたが、C#ではすべてをバイト単位で変換する必要がありました。
このようなパフォーマンスの違いは、バイトを単語に追加で変換する必要があるためだと考えています。 一般に、このトピックは別の記事に値するものであり、これについても説明します。
配列が返す
パフォーマンスを測定する次のステップは、より複雑な型を返すことでした。整数と浮動小数点数を通信することは必ずしも便利ではないためです。 したがって、管理されていないメモリ領域を管理されたメモリ領域にキャストできる速度を確認する必要があります。 このために、ファイル全体を読み取り、その内容をバイトの配列として返すという単純なタスクを実装することにしました。
純粋なC#では、このようなタスクは非常に単純ですが、CコードをC#コードに関連付けるには、他に何かをする必要があります。
手始めに、ソリューションはC#にあります
static byte[] FileRead(string path) { BinaryReader br = new BinaryReader(File.OpenRead(path)); byte[] ret = br.ReadBytes((int)br.BaseStream.Length); br.Close(); return ret; }
Cの対応するソリューション:
EXPORT char* STD_API file_read( const char* path, int* read ) { FILE *f = fopen( path, "rb" ); if ( !f ) return 0; fseek( f, 0, SEEK_END ); long length = ftell( f ); fseek( f, 0, SEEK_SET ); read = length; int sum = 0; uint8_t *buffer = malloc( length ); int read_f = fread( buffer, 1, length, f ); fclose( f ); return buffer; }
C#からこのような関数を正常に呼び出すには、この関数を呼び出すラッパーを作成し、アンマネージメモリからマネージメモリにデータをコピーし、アンマネージパーツを解放する必要があります。
static byte[] FileReadUnmanaged(string path) { int length = 0; IntPtr unmanaged = file_read(path, ref length); byte[] managed = new byte[length]; Marshal.Copy(unmanaged, managed, 0, length); Marshal.FreeHGlobal(unmanaged); // ? return managed; }
測定機能では、測定された機能の対応する呼び出しのみが変更されています。 結果は次のようになります。
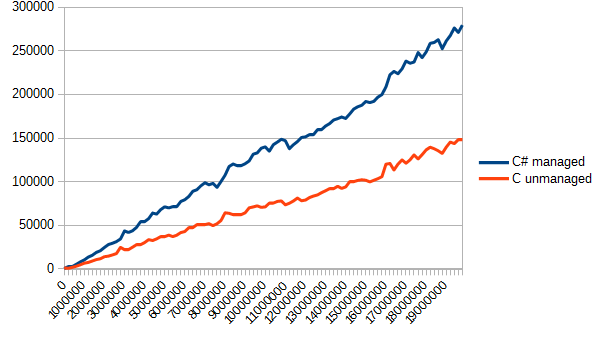
メモリのコピーに時間がかかったとしても、Cが再び先頭に立ち、タスクを約2倍高速に完了しました。 正直なところ、私は他のいくつかの結果を期待していました(2番目のテストのデータを与えられました)。 最も可能性が高いのは、C#で大きなバンドルを使用してもデータの読み取りが非常に遅いという事実です。 Cでは、管理されていないメモリを管理されたメモリにコピーするときに同じ時間が失われます。
歌詞
少し後に、Marshal.Free ...がデバッグアセンブリでクラッシュすることに気付きました。 何がこれを引き起こしたのか理解できませんでしたが、リリースアセンブリではすべてが正常に機能し、フローしませんでした。 ただし、Cライブラリからfreeを呼び出してもほとんど効果がないという最初のテストヒントです。
本当の挑戦
私が実施したすべてのテストの論理的結論は次のとおりです。C#およびCで何らかの本格的なアルゴリズムを実装することです。 パフォーマンス率。
このアルゴリズムでは、32ビット/ピクセルの非圧縮TGAファイルを読み取り、
struct Color { public byte r, g, b, a; }
アルゴリズムの実装は非常に容量が大きく、ほとんど面白くありません。 したがって、興味のない人の目を爽快にさせないように、スポイラーに入れられます。
TGAの読み取りの簡単な実装
そして、Sishnyオプション:
static Color[] TGARead(string path) { byte[] header; BinaryReader br = new BinaryReader(File.OpenRead(path)); header = br.ReadBytes(18); int width = (header[13] << 8) + header[12]; // , short int height = (header[15] << 8) + header[14]; // Little-Endian, byte[] data; data = br.ReadBytes(width * height * 4); Color[] colors = new Color[width * height]; for(int i=0; i<width*height*4; i+=4) { int index = i / 4; colors[index].b = data[i]; colors[index].g = data[i + 1]; colors[index].r = data[i + 2]; colors[index].a = data[i + 3]; } br.Close(); return colors; } static Color[] TGAReadUnmanaged(string path) { int width = 0, height = 0; IntPtr colors = tga_read(path, ref width, ref height); IntPtr save = colors; Color[] ret = new Color[width * height]; for(int i=0; i<width*height; i++) { ret[i] = Marshal.PtrToStructure<Color>(colors); colors += 4; } Marshal.FreeHGlobal(save); return ret; }
そして、Sishnyオプション:
#include "api.h" #include <stdlib.h> #include <stdio.h> // , // 4 typedef struct { char r, g, b, a; } COLOR; // , #pragma pack(push) #pragma pack(1) typedef struct { char idlength; char colourmaptype; char datatypecode; short colourmaporigin; short colourmaplength; char colourmapdepth; short x_origin; short y_origin; short width; short height; char bitsperpixel; char imagedescriptor; } TGAHeader; #pragma pack(pop) EXPORT COLOR* tga_read( const char* path, int* width, int* height ) { TGAHeader header; FILE *f = fopen( path, "rb" ); fread( &header, sizeof( TGAHeader ), 1, f ); COLOR *colors = malloc( sizeof( COLOR ) * header.height * header.width ); fread( colors, sizeof( COLOR ), header.height * header.width, f ); for ( int i = 0; i < header.width * header.height; i++ ) { char t = colors[ i ].r; colors[ i ].r = colors[ i ].b; colors[ i ].b = t; } fclose( f ); return colors; }
今、問題は小さなものに任されています。 単純なTGAイメージを描画し、n回ロードします。 結果は次のようになります(通常どおり垂直に、水平方向-ファイル読み取りの数)。
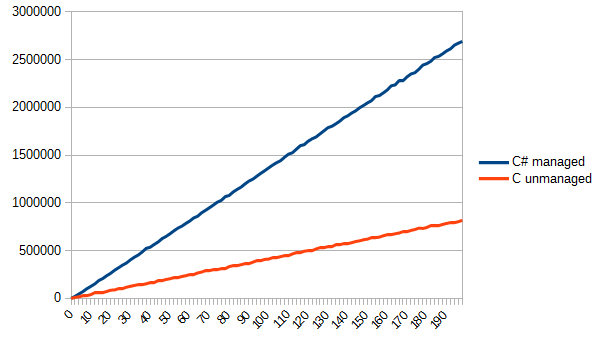
私は彼の好意でCの機能を大胆に使用したことに注意してください。 ファイルから直接構造体に読み込むと、作業がずっと簡単になります(また、構造体が4バイトで整列されていない場合、楽しいデバッグが行われます)。 しかし、私は結果に満足しています。 このような単純なアルゴリズムは、Cで効果的に実装され、C#で効果的に使用されることが判明しました。 したがって、私は最初の質問に対する答えを受け取りました。勝つことは本当に可能ですが、常にではありません。 わずかに勝つこともあれば、まったく勝てないこともあれば、複数回勝つこともあります。
乾燥残渣
一般に、最初に書いたように、何かの実装を別の言語に入れるというアイデア自体は疑わしいです。 最終的に、このコード高速化の方法の使用はかなり見つけることができます。 ファイルを開くとUIがハングし始めたら、ダウンロードを別のバックグラウンドストリームに入れることができます。1秒でもダウンロードしても、誰にとっても深刻な問題は生じません。
したがって、パフォーマンスが本当に必要な場合にのみ歪曲することは価値があり、他の方法では達成できません(そのような場合、通常はすぐにCまたはC ++で記述します)。 または、車輪を再発明するのではなく、使用できる既製のアルゴリズムが既にある場合。
アンマネージdllの単純なラッパーではそれほどパフォーマンスが向上せず、アンマネージ言語のすべての「軽快」は大量のデータを処理する場合にのみ明らかになるので、注意が必要です。 ただし、このようなラッパーの使用は悪化しません。
C#はマネージリソースをアンマネージコードに渡す非常に良い仕事をしますが、逆変換は私たちが望むほど速くは行われません。 したがって、頻繁なデータ変換を回避し、アンマネージコードにアンマネージリソースを保持することが望まれます。 マネージコードでこのデータを編集/読み取る必要がない場合、IntPtrを使用してポインターを保存し、残りの作業を完全にアンマネージコードに転送できます。
もちろん、アンマネージアセンブリへのコードの移植について最終的な決定を下す前に、追加の調査を行うことができます(必要な場合もあります)。 しかし、現在の情報を使用して、そのようなアクションの適切性を判断できます。
そして、それは私にとってすべてです。 最後まで読んでくれてありがとう!